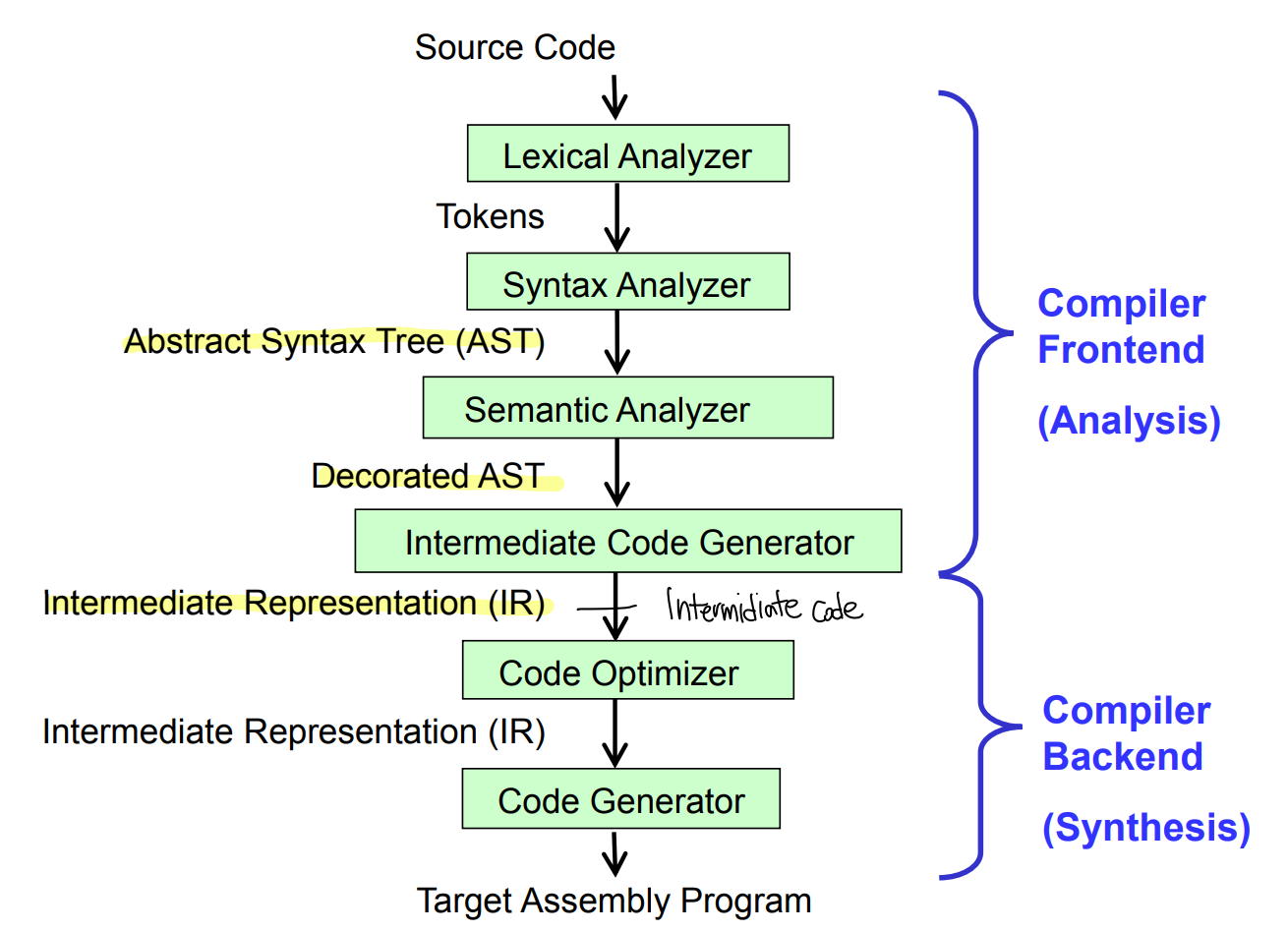
Introduction
Syntax Analyser
- 소스코드의 구조 파악
- AST를 만들어낸다.
예시
- 101 + 1 은 문법적으로 옳은 표현이다.
Sementic Analyser
- AST에 Tree traversal를 동반해 의미와 맥락을 파악한다.
- EX. 정수-실수의 타입 변환이 필요한경우 이를 실행한다.
예시
- 101 + 1은
- 2진수 연산이라 가정할 시 101 + 1 = 110
- 10진수 연산이라 가정할 시 101 + 1 = 102
- 문자열 연산이라 가정할 시 101 + 1 = 1011
- 이 된다.
Sementic Analysis
- 프로그램의 구조와 의미를 파악한다.
목적
- Context-sensitive 한 정보에 대한 분석을 마친다.
- IR ( Intermediate Representation / 중간 코드 ) 혹은 타겟 코드의 생성을 시작한다.
Context Sensitive Information
주어진 ID가 변수인지 함수인지 배열인지 패키지인지 확인하기
주어진 변수가 사용하기 전에 선언 되었는지
사용한 변수가 어디에 선언된 변수인지
표현식이 Type-consistent 한지?
- EX. 2 + "String"
배열의 차원이 일치하는지
- EX. a[1] or a[0][1]
배열 접근시 Index가 벗어나지는 않는지?
함수 호출시 argument의 타입과 갯수가 올바른지?
loop안에 break나 continue가 들어가 있는지?
- 다른데 있으면 에러가 나야 한다.
모든 context-sensitive한 요구사항들은 CFG로 표현하는것이 불가능하다!
일부 경우는 컴파일때 체그하는것이 불가능할수 있다.
- 런타임 당시 체크를 한다.
Static sementics
- 컴파일 당시 확인을 한다.
- 타입체크
- 함수호출시 Argument 갯수 및 타입
- ID를 적절한 맥락에 사용하였는지
Dynamic sementics
- 작동 당시 확인을 한다.
- 배열의 index가 넘어섰는지
- 수리적 계산에 문제가 있는지 ( 오버플로우, 0으로 나누기 )
- 올바르지 않은 객체에 대한 역참조
- 선언되지 않은 변수에 대한 사용
- 몇몇 언어의 경우 assert와 같은 code를 injection 해서 검사한다...
- Dynamically typed programming language의 경우 런타임에 타입 검사를 한다.
- EX. 파이썬
- 타입이 올바르지 않을시 Exception이 발생한다.
Information flow
AST를 DFS / Left->Right 방식으로 순회해 확인하고 정보를 전달한다.
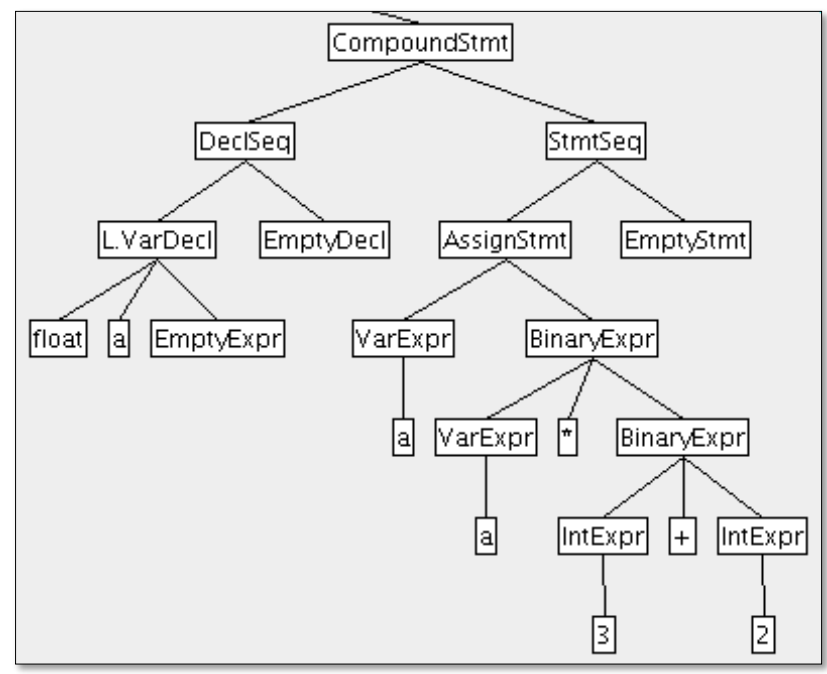
- 위와 같은 AST에 대해 첫번째로 순회하는것은 왼쪽의 L.VarDecl이 된다
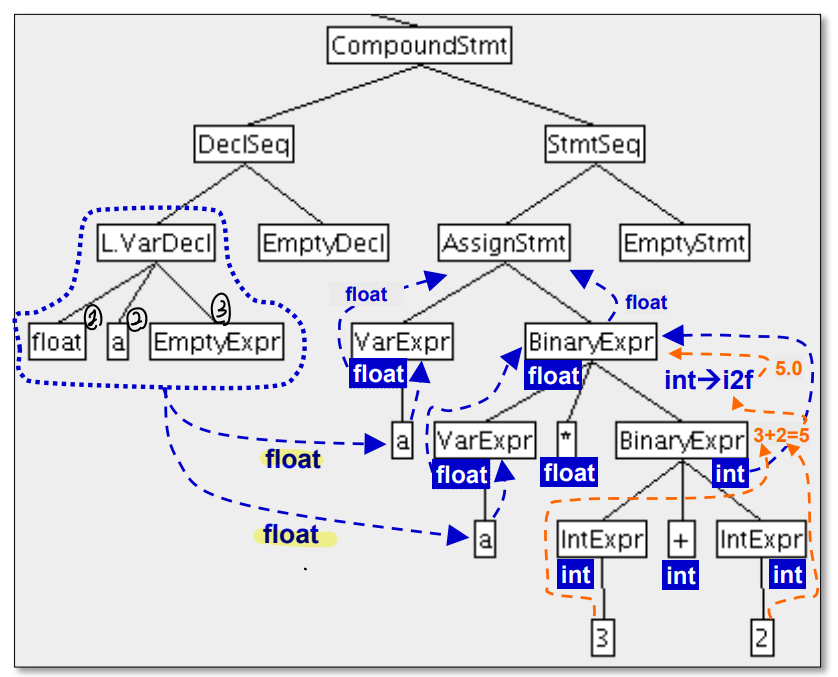
- 찾아진 a에 대해 이는 float 변수형이라 의미를 부여하고 다른쪽에 있는 a에도 의미를 Propagate한다.

- 이는 위와 같은 코드를 통해 이루어진다.
- visit : 해당 노드의 방문
- traverse : 재귀적 호출
- 즉 해당 노드 방문 > 해당 노드의 자식을 순회 > 다시 해당 노드 방문
Block
- 선언을 포함하는 언어의 구조
예시
- 소스코드
- 프로시저, 함수
- Compound Statement ( Ex. 중괄호로 싸여진 부분 )

- 블록 안에 블록에 있어도 되는 언어를 우리는 Block Structured Language라고 부른다.
- EX. Ada, Pascal
- C언어는 특이하게 함수 안에 함수를 내장할수 없다.
Scope
- 선언의 Scope는 프로그램에서 선언한 것이 사용 가능한 부분을 의미한다.
Defining occuerence
- 함수 혹은 변수의 선언
Applied occuerence
- 함수 혹은 변수의 사용
Scope rule
- 함수 혹은 변수를 사용할때 사용할 것을 찾는 규칙
- 함수의 선언
- 선언된 함수는 선언 직후부터 파일의 끝까지 Scope에 해당한다.
- 블록 내부의 변수 선언
- 선언된 순간부터 블록의 끝까지가 Scope에 해당한다.
- 패러미터 내의 변수
- 함수의 body 전체가 Scope에 해당한다.
- 내장함수
- 소스코드 전체가 Scope에 해당한다.
- 단일 블록 내부에 같은 ID가 2개 이상 선언될수 없다
- ID 사용시 가장 가까운데서 선언된 것을 사용한다
- 점차 바깥 블록으로 탐색해 나가며 찾는다.
예시

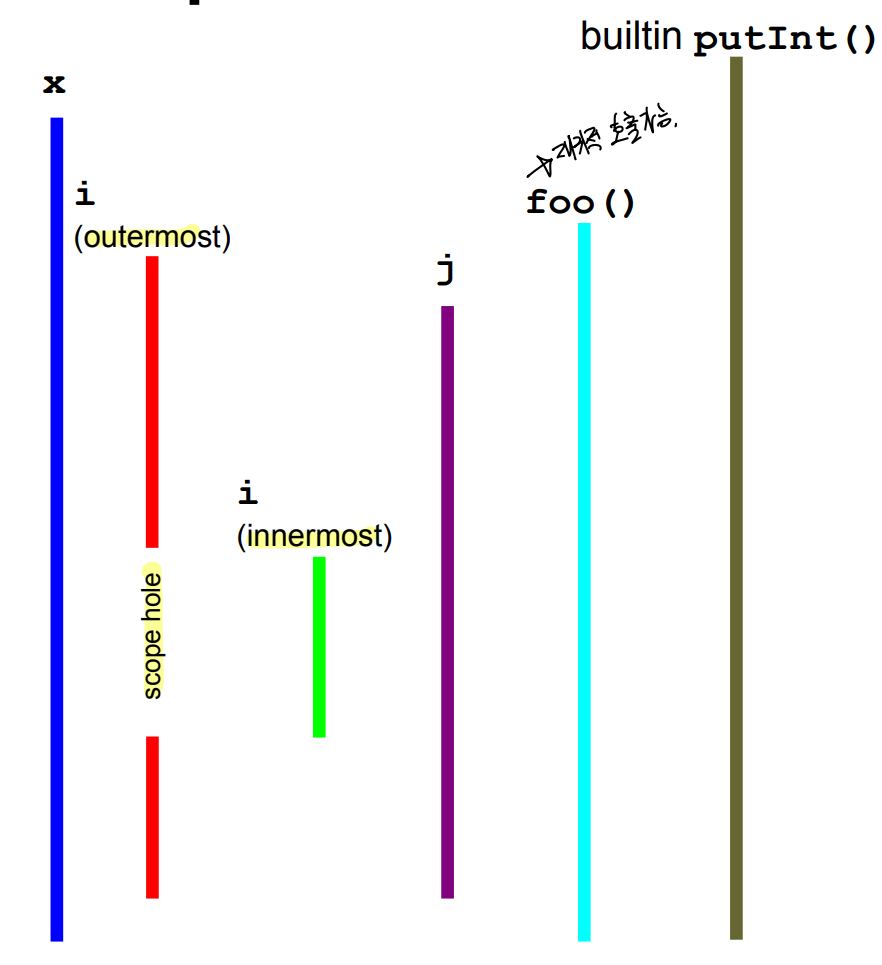
7. 이로 인해 바깥에 선언된 변수가 사용되지 못하는 구간을 scope hole이라 명명한다.
Implication for MiniC
- 아래 소스코드는 문법적(Syntatically) 으로 옳으나, 맥락적(Sementically) 옳지 않다.
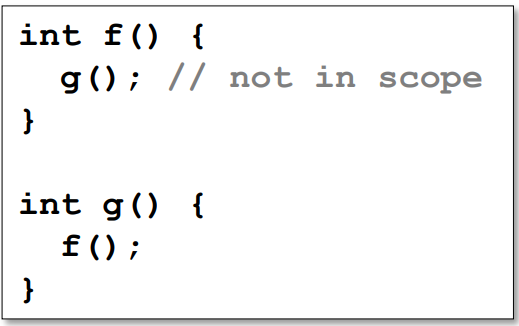
- g 함수가 선언되지 이전에 사용되었기 때문이다, 즉 스코프 안에 없는 상태로 사용되었기 때문이다.
- 이를 해결하기 위해서 주로 코드의 앞에 int g(); 와 같이 function prototype을 선언해준다.
Scope level in Block structured language
- 스코프 레벨은 스코프가 내장된-깊이(Nesting-depth) 와 연관되어 있다.
일반적 scope level
- 최외곽 블록 ( 소스코드 ) 의 경우 Lv.1
- 블록이 다른 블록에 Enclosing 될 때마다 레벨이 증가한다.
- 내장 함수의 경우 언어에 따라 Lv.0 이거나 Lv.1 이다.
MiniC에서의 scope level
- 모든 함수와 전역변수는 Lv.1
- 블록이 다른 블록에 Enclosing 될 때마다 레벨이 증가한다.
- 모든 내장함수는 Lv.1
- 내장함수의 이름은 사용자 함수 또는 전역 변수의 이름으로 선언될수 없다.
- 파이썬의 경우는 가능하다!
MiniC 에서의 예시
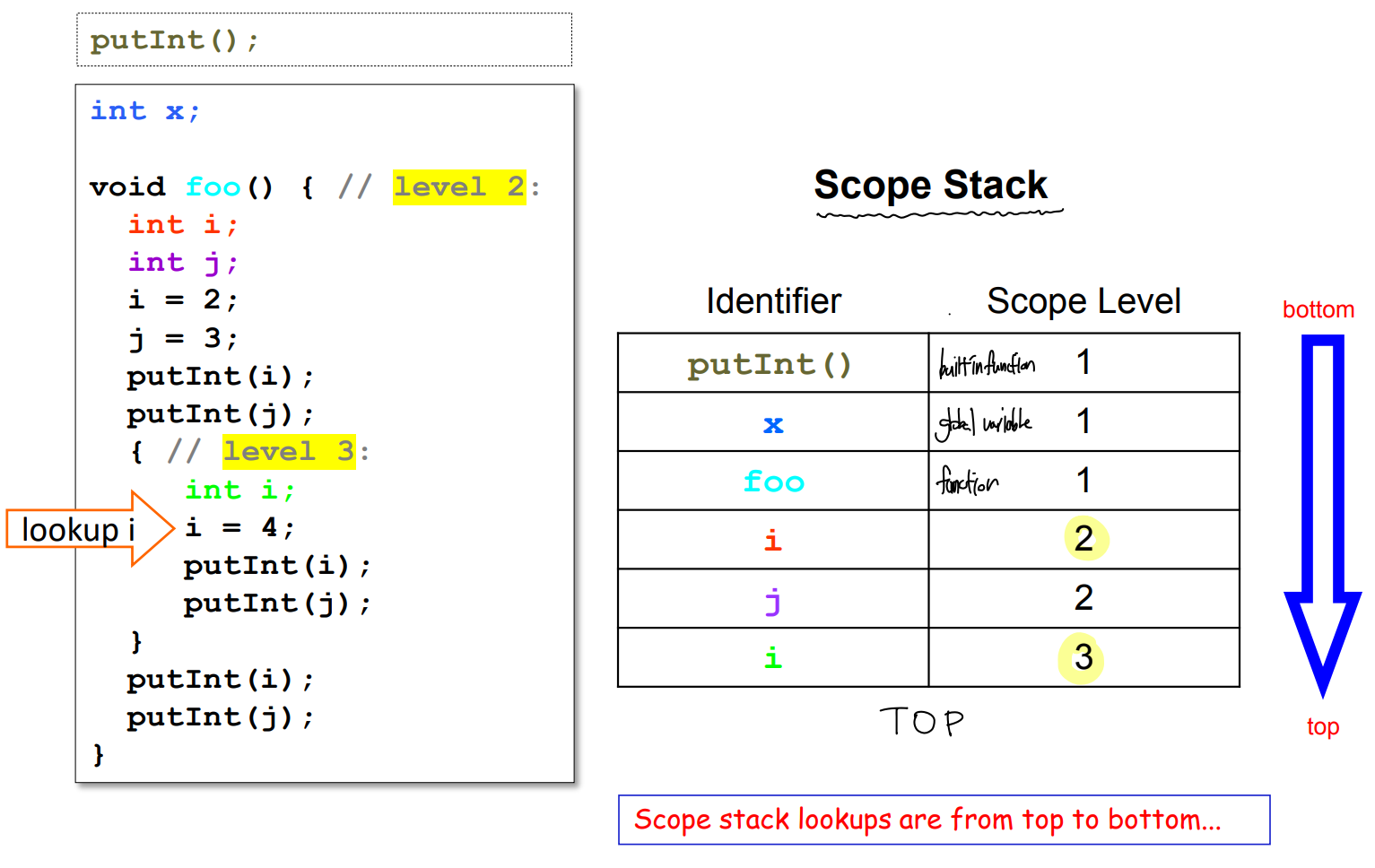
Identification / 식별
- ID가 사용되었을때, 이의 선언을 찾아 나가는 과정
- 선언이 존재하지 않으면 에러를 Report 한다.
Attribute of Identifier
Variable
- 변수의 타입
Function
- 함수의 리턴타입
- 함수의 패러미터 타입 및 갯수 ( Signature of the function )
DeclAST

Identification 절차
Processing declarations : 선언에 대한 처리 과정
- ScopeStack.openScope() 를 블록의 시작에 호출한다. - Defining occuerence
- ScopeStack.closeScope() 를 블록의 끝에 호출한다.
- ScopeStack.enter() 는 선언의 ID와 선언에 대한 포인터를 스코프 스택에 Push 한다.
Processing occuerence - ID AST 노드를 decorating
- ScopeStack.retrieve(ID) - Applied occuerence
- 스코프 스택에서 ID의 innermost declaration에 대한 포인터를 가져온다.
- 위 포인터는 AST 노드의 declAST 필드에 저장된다.
- declAST는 스코프 스택에서 매칭되는 선언이 발견되지 않으면 NULL로 설정된다.
- 에러 report 에 사용되게 된다.
MiniC 에서의 사용
- 먼저 내장된 9개의 함수를 ScopeStack에 미리 지정할 필요가 있다.
- ID와 Attribute 를 모두 지정해야 한다!
- Scope level은 1
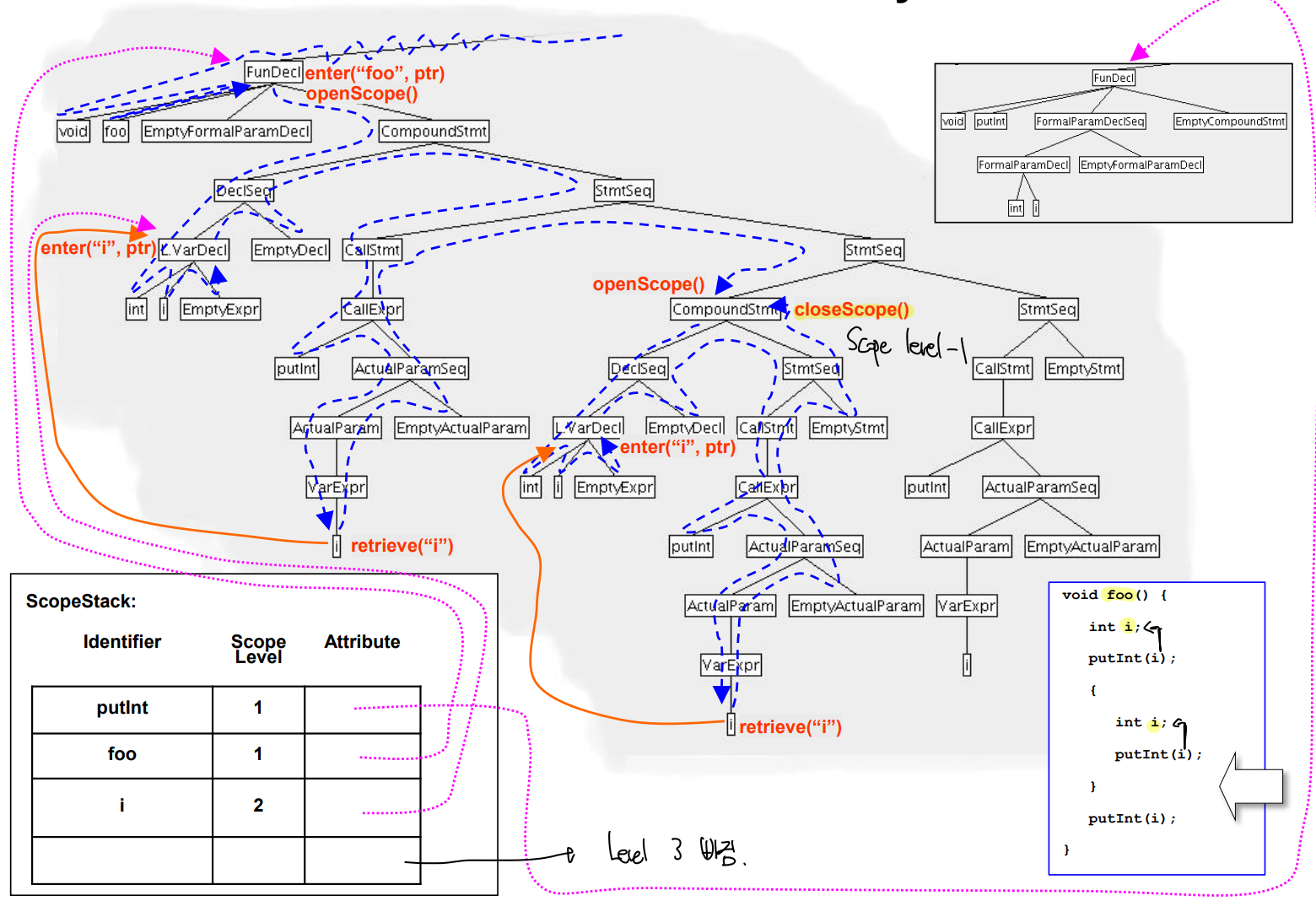
예시

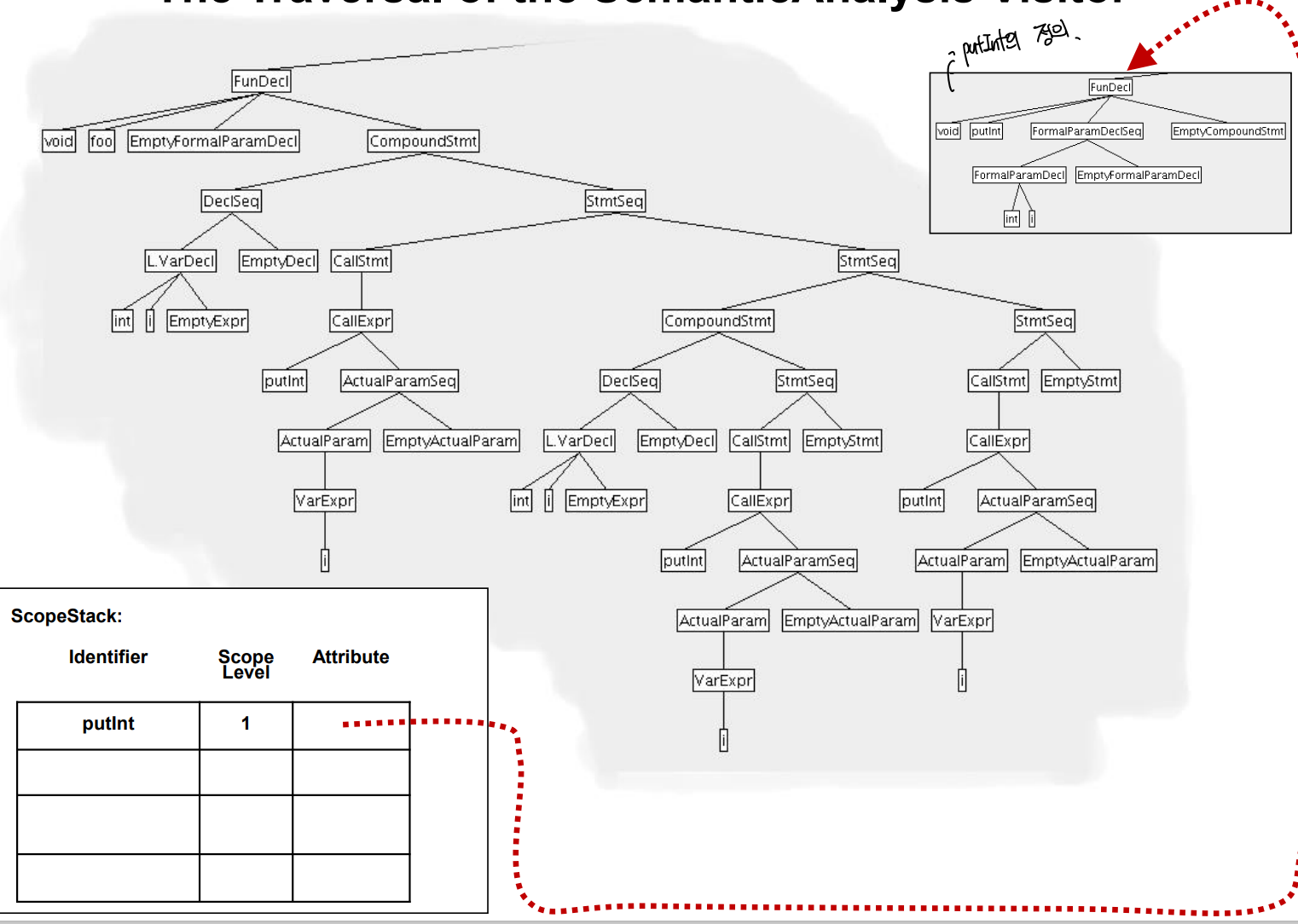
- 내장함수가 정의된 모습
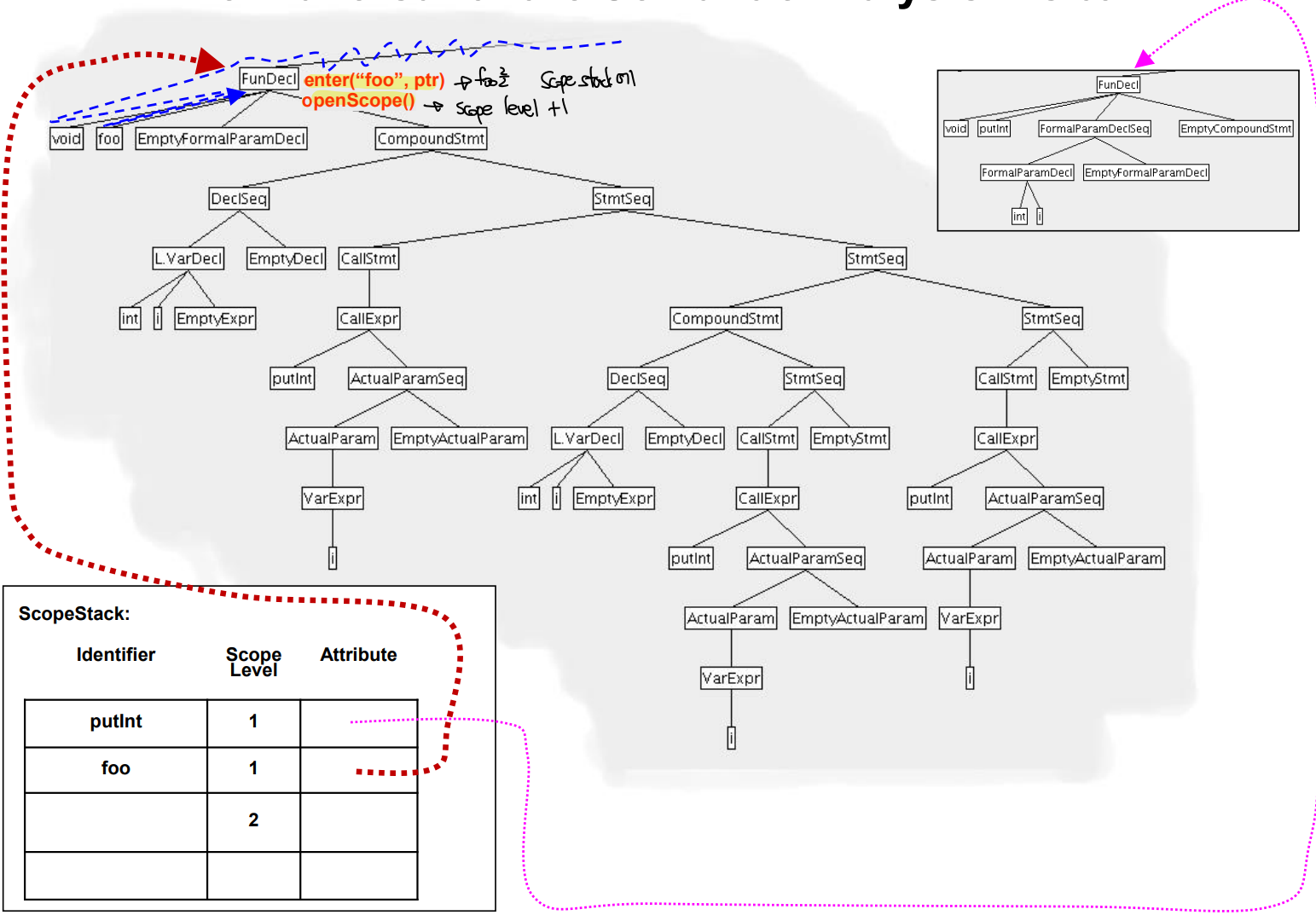
- ScopeStack 에 넣고나서 Compound statement에 진입하기에 Scope level을 1 올린다.
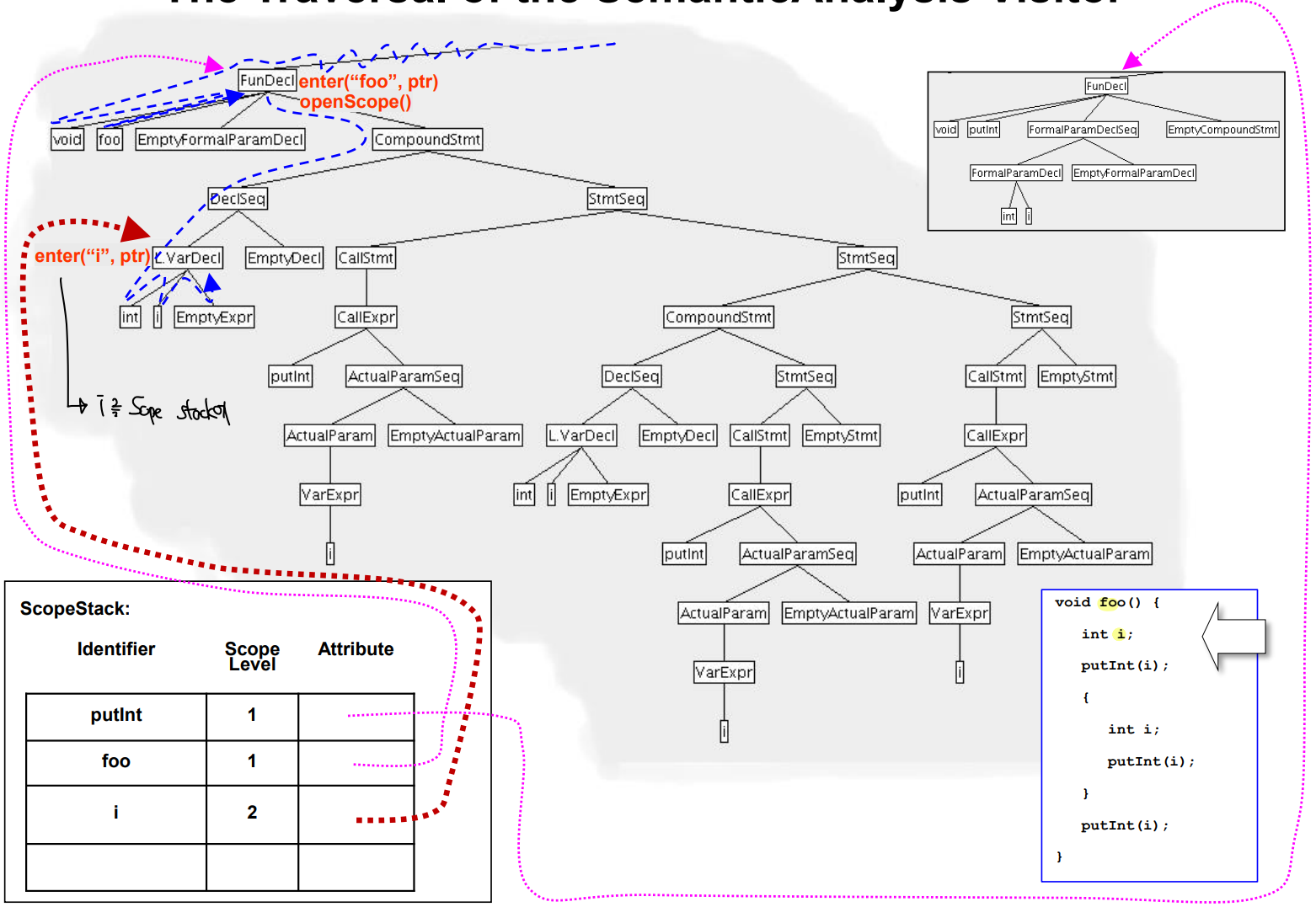
- 새로 선언된 i를 Scope Stack에 넣는다.
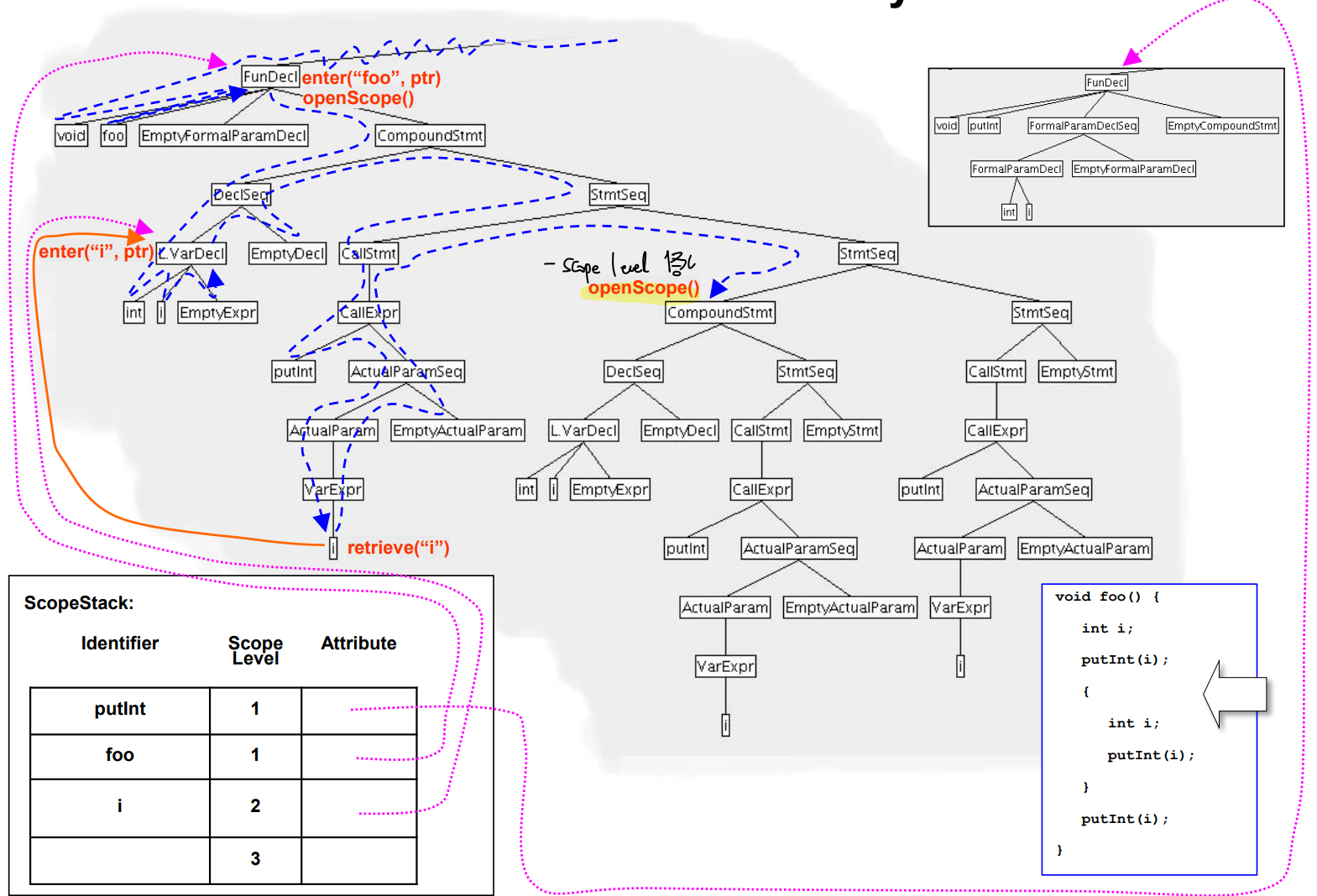
- 다른 Compond statement에 진입해 Scope level을 1 올린다.
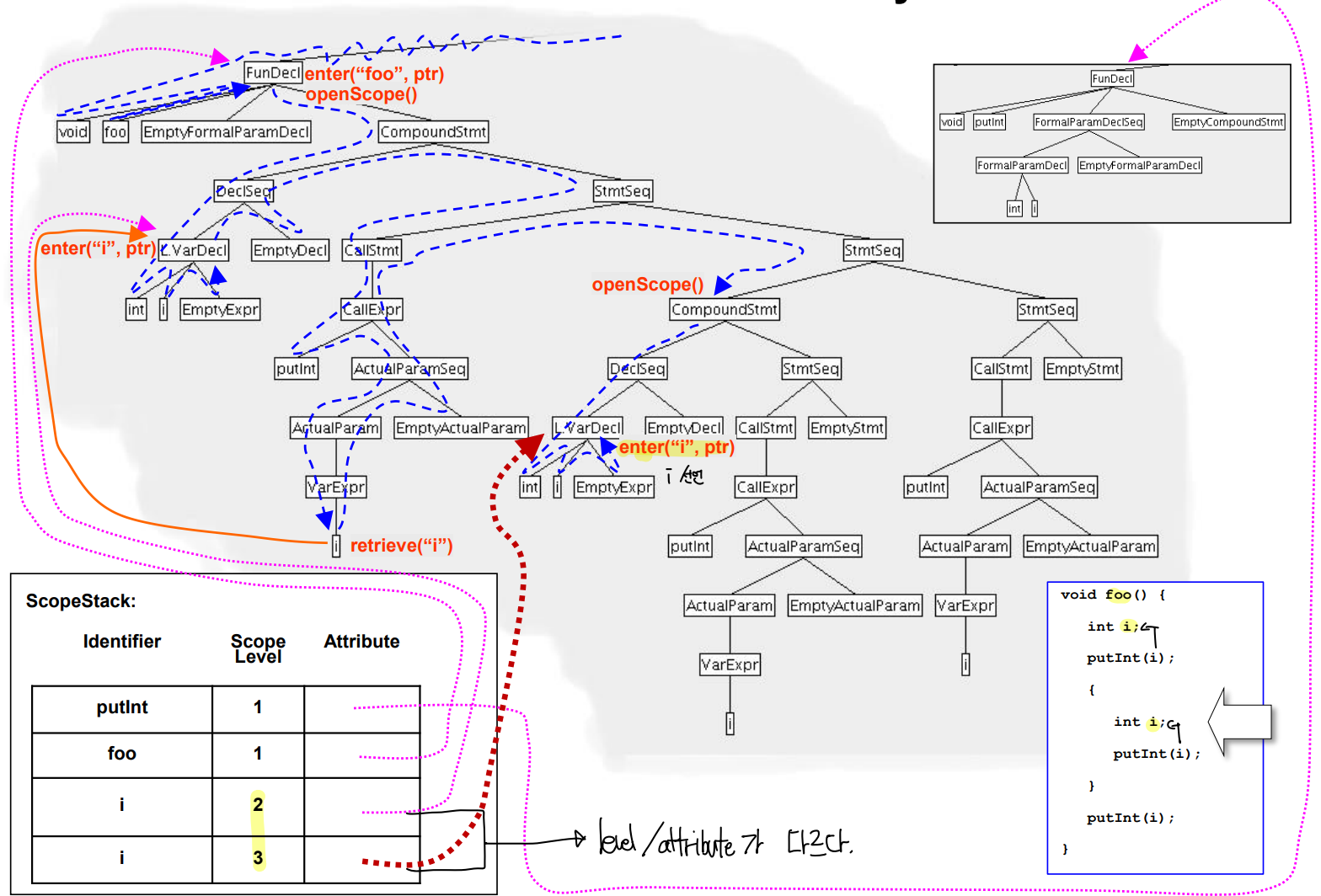
- 다른 블록의 변수 i를 Scope Stack에 넣는다.
- 앞의 i는 level 2, 뒤의 i는 level 3에 속한다.
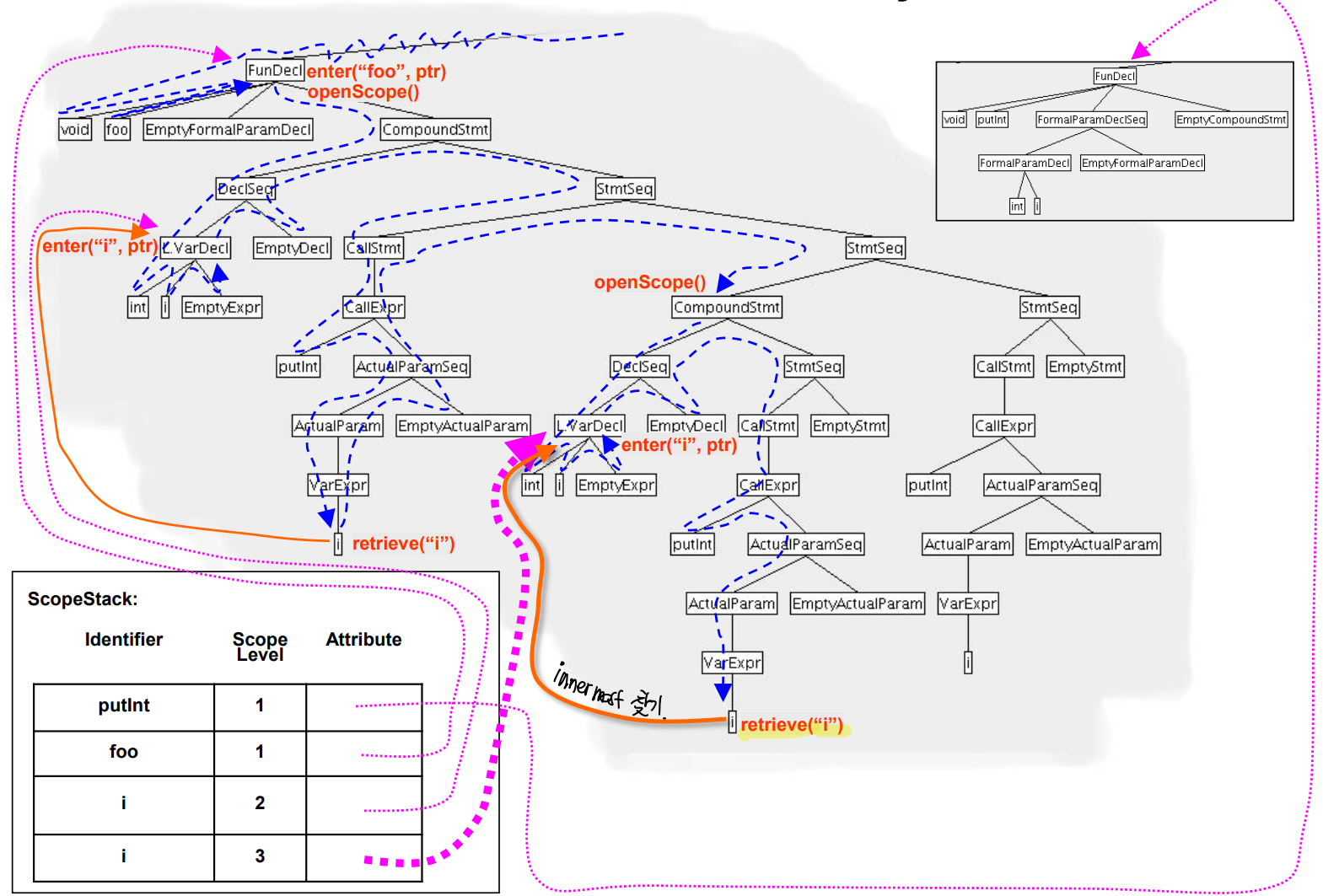
- innermost 한 i의 위치를 찾는다, 해당 경우 level 3의 i가 가장 가까운 경우라 이를 가져온다.
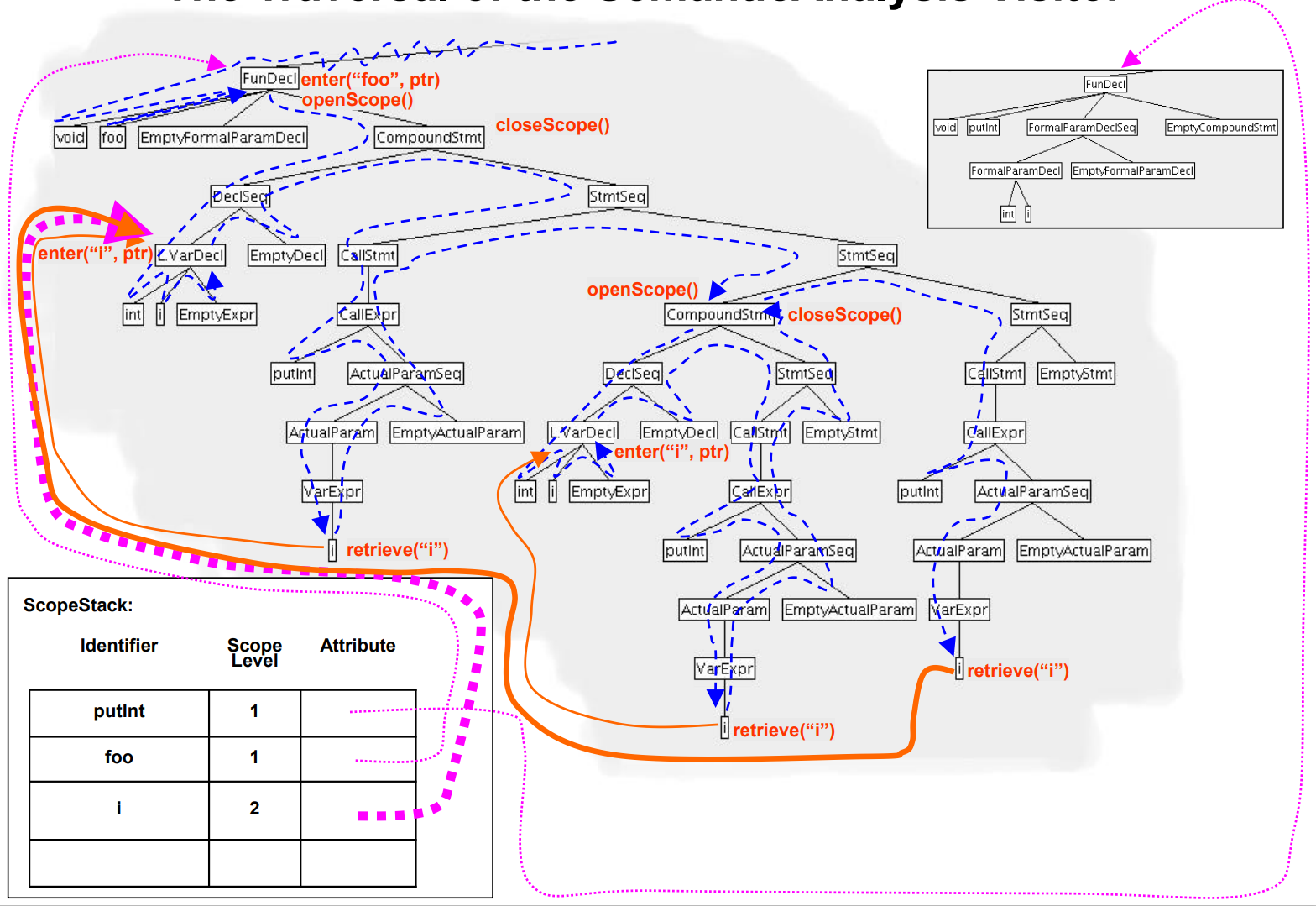
- Compound Statement 가 끝나 Scope level을 1 줄인다
- 이 경우 끝난 Statement에 속하던 Defining occuerence 들은 ScopeStack에서 전부 pop 한다.
- 다음에 다시 i를 불러오려면 마지막 남은 i를 가져온다.
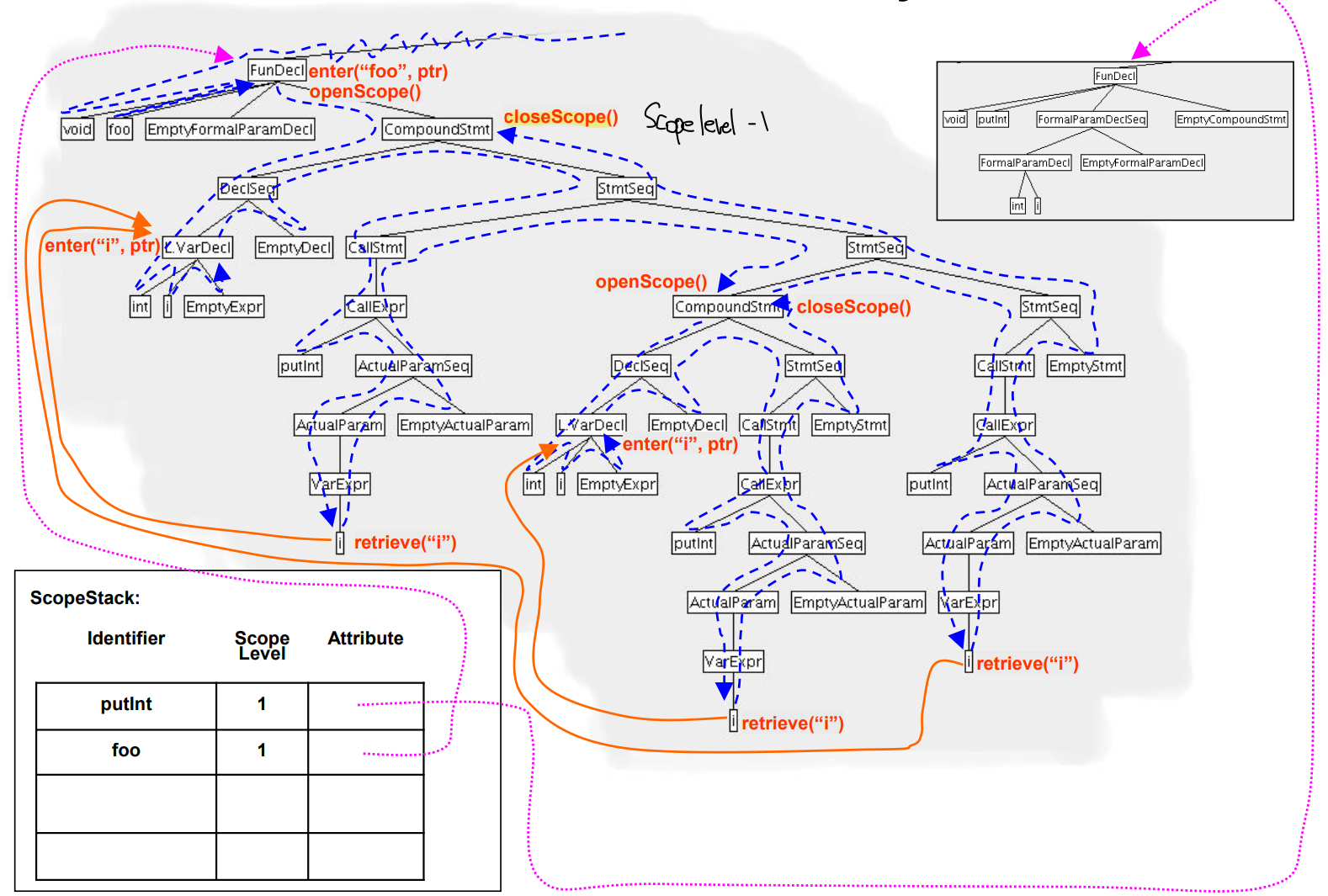
- 최종적으로 모든 Compound Statemet의 실행이 끝났다.
타입 체크
데이터 타입
- 허용되는 타입과 연산자의 집합으로 이루어진다.
예시 : int
- 허용되는 값의 범위:
- 허용되는 연산
- +, -, *, / : int X int → int
- +,- : int → int
- 결과가 다른 타입이 나올수도 있다.
- <, <=, >, >=, !=, == : int X int → bool
여기서 X는 해당 자리에 왼쪽의 Operator 가 들어간다는 의미이다.
- <, <=, >, >=, !=, == : int X int → bool
MiniC
- MiniC는 정적 타입 검사를 한다.
- 모든 타입 검사가 컴파일 당시 진행된다.
Type rule
- 타입의 값과 연산이 유효한지 확인하기 위한 규칙
- the rules to determine the type of each language construct and decide whether the type is valid.
Expr.java

- Expression 이 어떤 type인지를 적어 놓는다.
Type coercions
- + 연산자의 경우 아래의 두 연산이 가능하다.
- "+": int x int → int
- "+": float x float → float
- + 는 두 argument type에 대해 오버로딩 된 상황이다.
- 두 피연산자가 integer 인지 float 인지에 따라 정해진 연산을 하게 된다.
Type coercion
- 이는 위의 규칙을 약간 느슨하게 한 것이다.
- 변환 가능한 타입 또한 연산에서 받아주게 된다.
예시
- int i; float f; f = i;
- float 변수에 int 변수를 대입하려는 경우이다.
- 기본적으로 이는 type rule에는 위배된다 ( 연산자가 적혀있지 않음 )
- 허나 MiniC에서는 이를 허용한다.
- int를 float 으로 컴파일러가 형 변환 함으로 동작한다.
- 이를 묵시적 타입 변환 ( Implicit Type conversion ) 혹은 Type coercion 이라 부른다.
Implicit Type Conversion
-
int > float 이나 float > int 를 선택해야 할 경우 주로 int > float 으로 이루어진다.
- 데이터의 손실이 적기 때문이다.
- 3.3 > 3 보다 3 > 3.0 이 데이터 손실이 적다.
-
대입연산의 경우 대입되는 타입으로 바뀌게 된다.
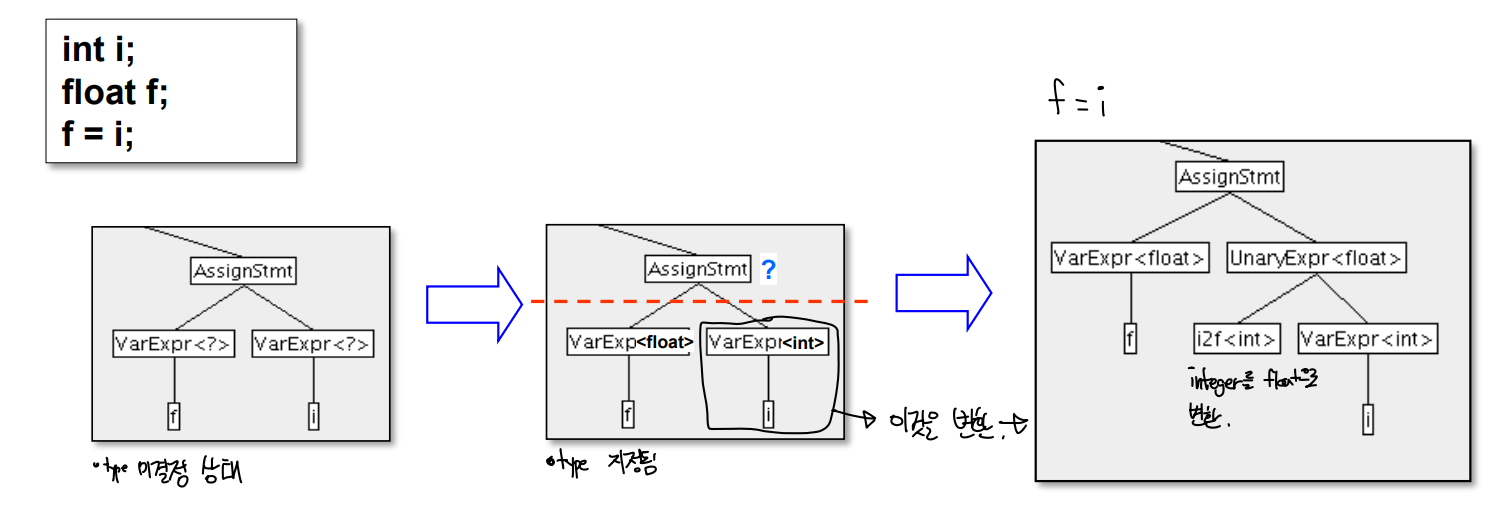
-
좌측의 float에 우측의 int가 대입되기 위해 float이 int가 되는 unary expression node인 i2f가 삽입된다.
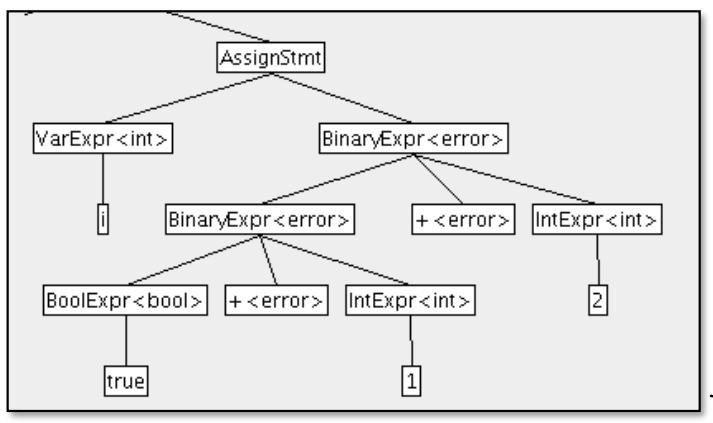
error == stdEnvironment.errorType
Error detection
- type rule에 따라 에러를 찾아내는것
Reporting
- 에러 메시지를 출력하는것
Recovery
- 타입 에러를 확인 후 타입 검사를 이어 나가는것
타입이 잘못될 경우 StdEnvironment.errorType 타입으로 지정됩니다.
연달아 에러메시지가 나는것을 방지하기 위해 expression의 operand가 하나라도 StdEnvironment.errorType일시 에러를 리포트 하지 않습니다.
Attribute grammar
- CFG를 확장해 프로그램을 분석한다.
구조
- 문법과 문백을 이어주게 된다.
- 각각의 grammar production 은 attribute 의 value를 수정하는 sementic rule을 포함한다.
- terminal / nonterminal 은 attribute 를 가진다.
- attribute 는 terminal / non-terminal 과 연관된 정보를 가지고 있다.
종류
Synthesized attributes
- Bottom-up 으로 흐르는 파싱 트리
- 자식에서 연산되어 위로 올라간다.
- 자식에서 "Synthesized/합성" 된다.
- 자식들의 Attribute들로 attribute를 생성하는 일종의 함수.
- Ex. Parent.att = f(ChildA.att, ChildB.att, ChildC.att)
Inherited attributes
- Top-down 으로 흐르는 파싱 트리
- 부모 혹은 자매에서 값을 가져와 연산하게 된다.
- 부모 혹은 자매로부터 "Inherited/상속" 받는다.
- 부모의 Attribute나 자매의 Attribute 로 attribute를 생성하는 함수
- Ex. ChildA.attr = f(Parent.attr)
작성법
- 기존 CFG
- A ::= BC
- Attribution Grammar
- A.X := B.X
- 오른쪽에서 왼쪽으로 대입되는 것이다.
예시
1. 괄호의 예시
- 괄호를 감싼 횟수를 val attribute로 저장한다.

2. 리터럴 계산의 예시
- INT / FLOAT / Division 이 있는 문법의 예시를 들때,
- 아래와 같은 Grammar는 모호하다.

그래서
- 5 / 2 / 2.0 의 경우 1.25 일지 1일지 결정하기 어렵다.
해결법은?
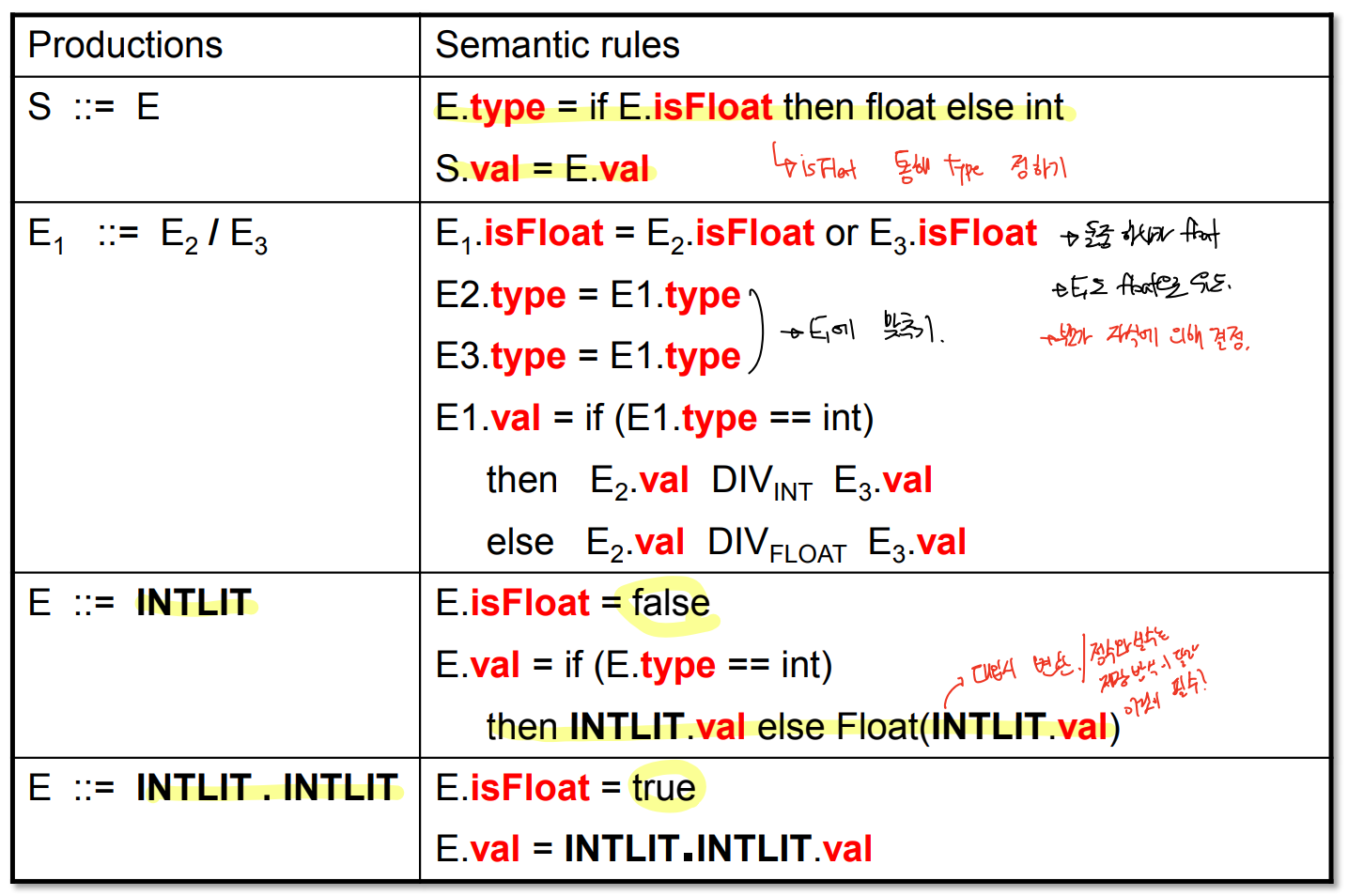
- 위와 같은 Attribute grammar 를 적용한다.
- 여기엔 크게 4가지의 분류가 있는데 이는 각각 아래와 같다.
- > 최종 연산 결과가 S로 저장되는것
- > 연산이 이루어지는것
- > 정수 리터럴이 E에 들어가는 경우
- > 실수 리터럴이 E에 들어가는 경우
- 또한 위 문법에서 각각의 단어는 아래의 의미를 가진다.
- type : 실질적인 타입
- isFloat : 값이 실수를 가질이 안 가질지
- val : 저장된 값
- 이는 특정한 순서를 통해 진행되는데, 순서는 아래와 같다.
1. Synthesized grammar : isFloat 계산
- 먼저 isFloat 을 Synthesized attribute 로서 계산하게 된다.
- bottom-up
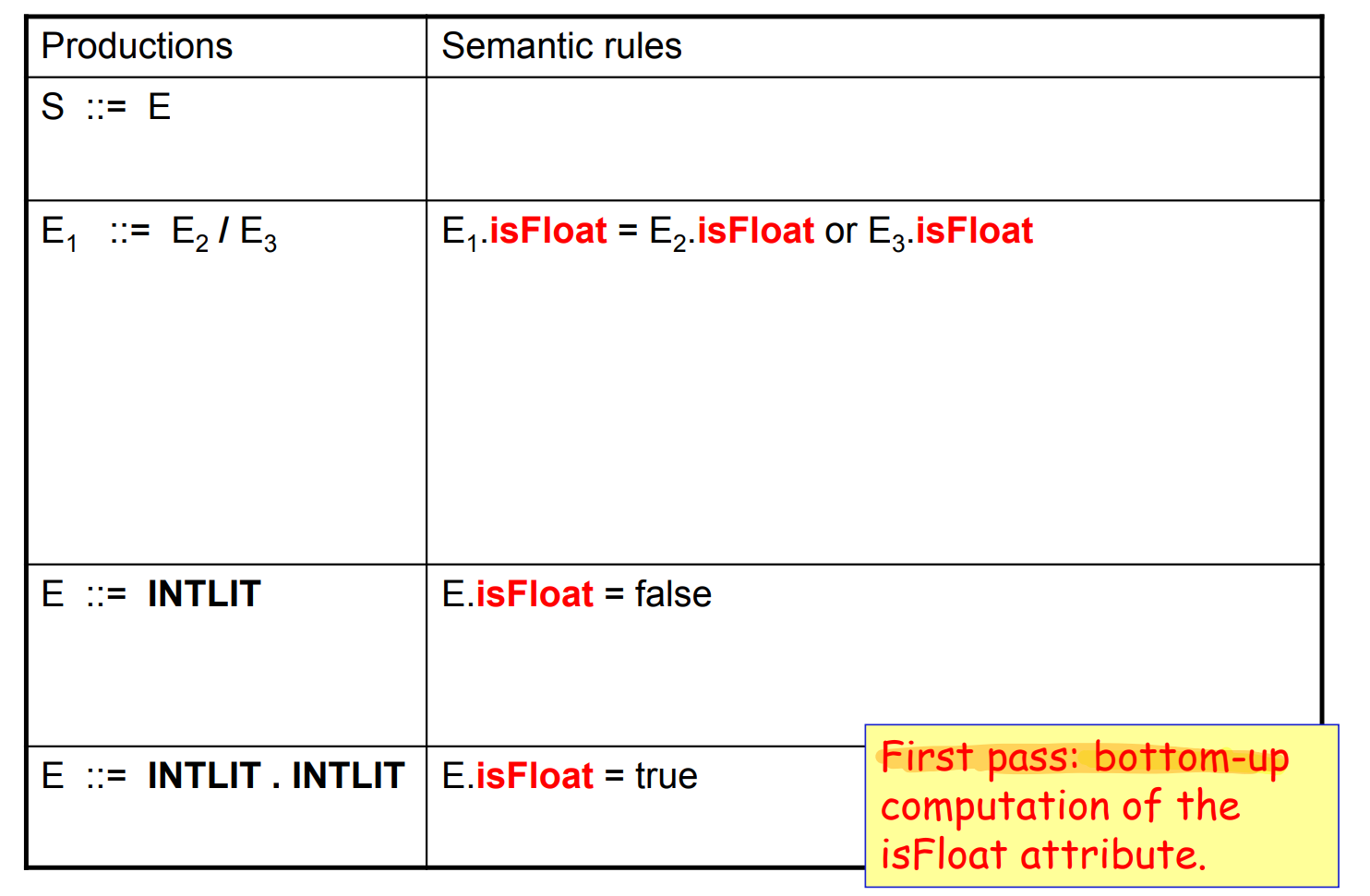
- 위 연산들을
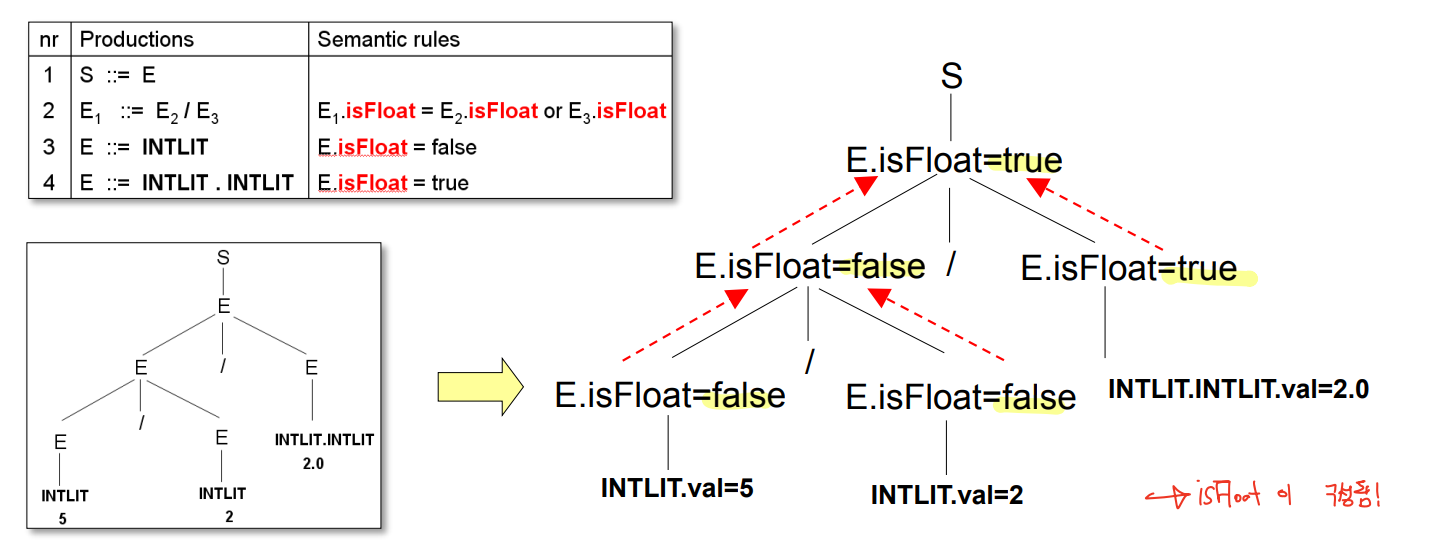
- 이런식으로 아래에서 위로 올라가며 연산한다.
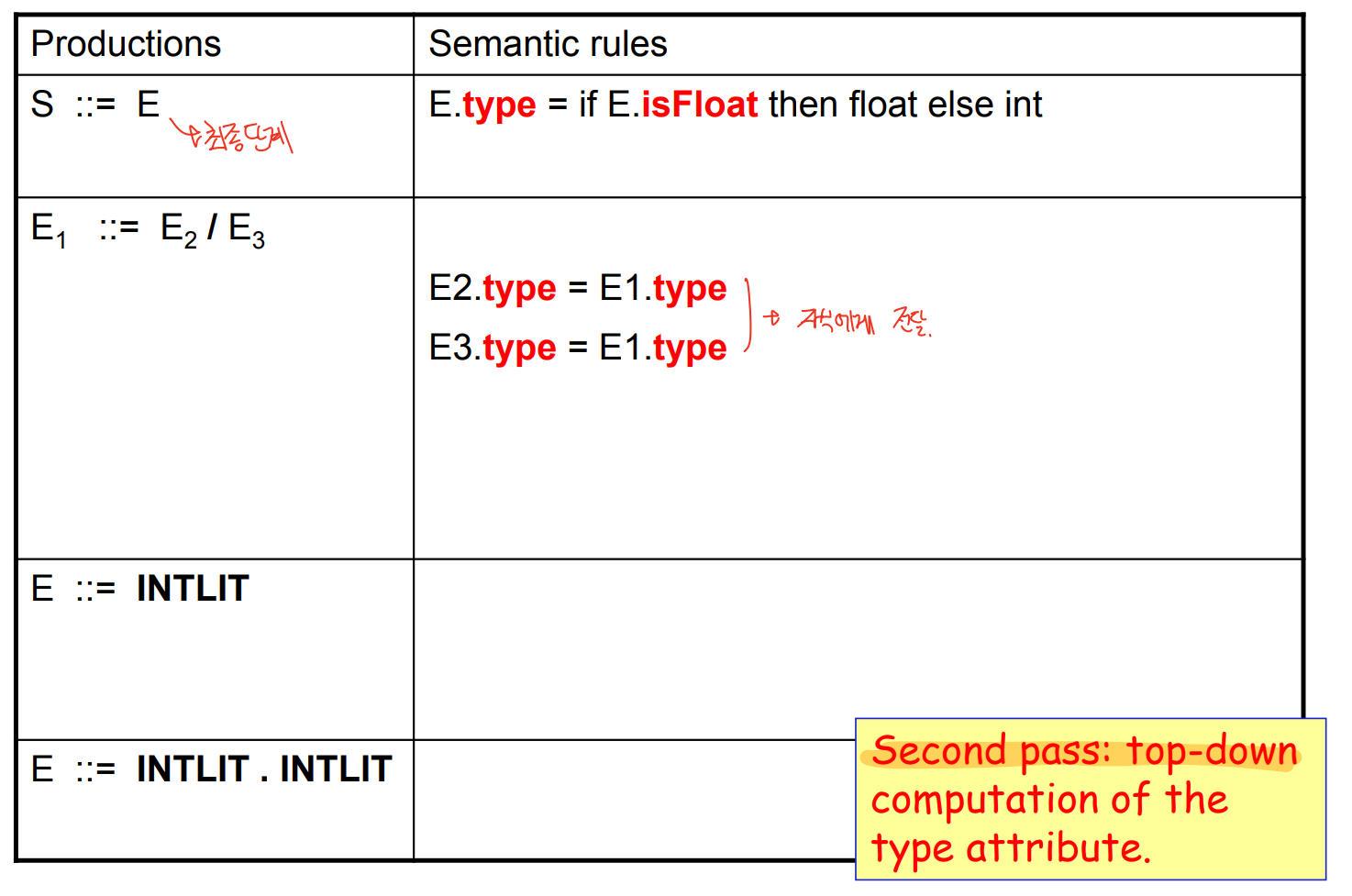
2. Inherited grammar : type 계산
- 계산된 isFloat을 통해 type을 찾는다.
- 부모의 type을 그대로 물려받게 된다.
- 고로 Inherited grammar ( Top-down ) 이다.
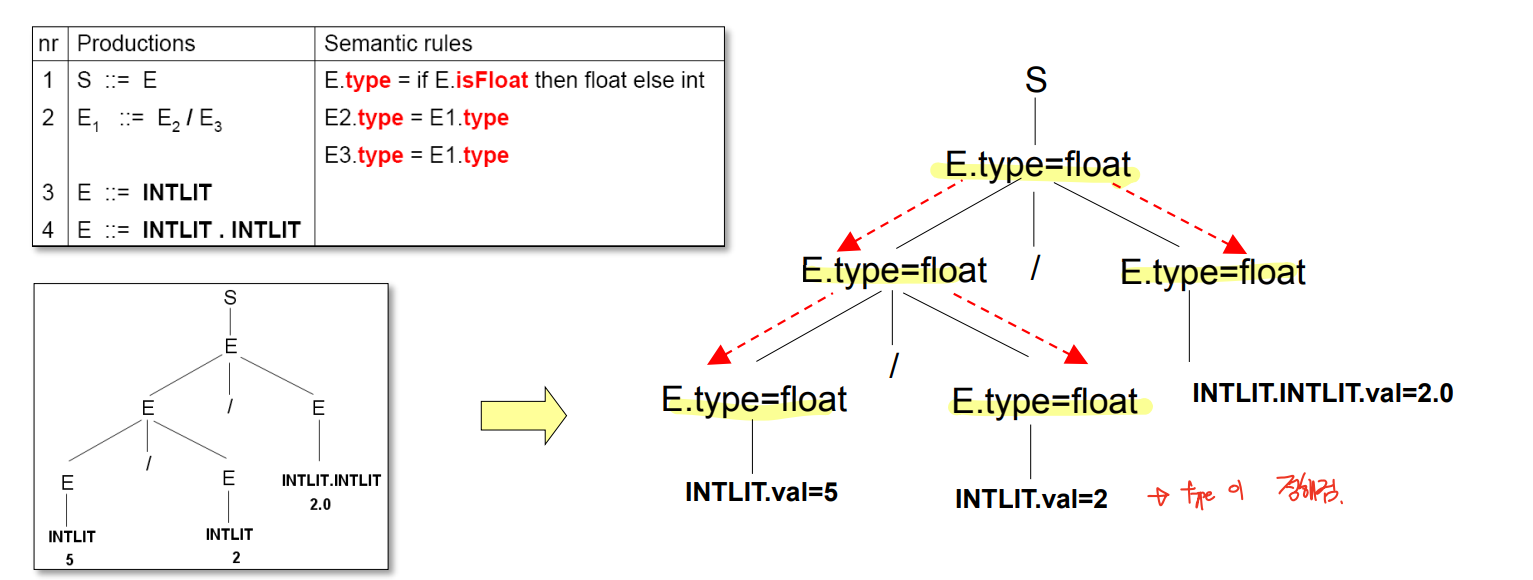
3. Synthesized grammar : value 계산
- type이 정해져 드디어 계산이 가능해진다.
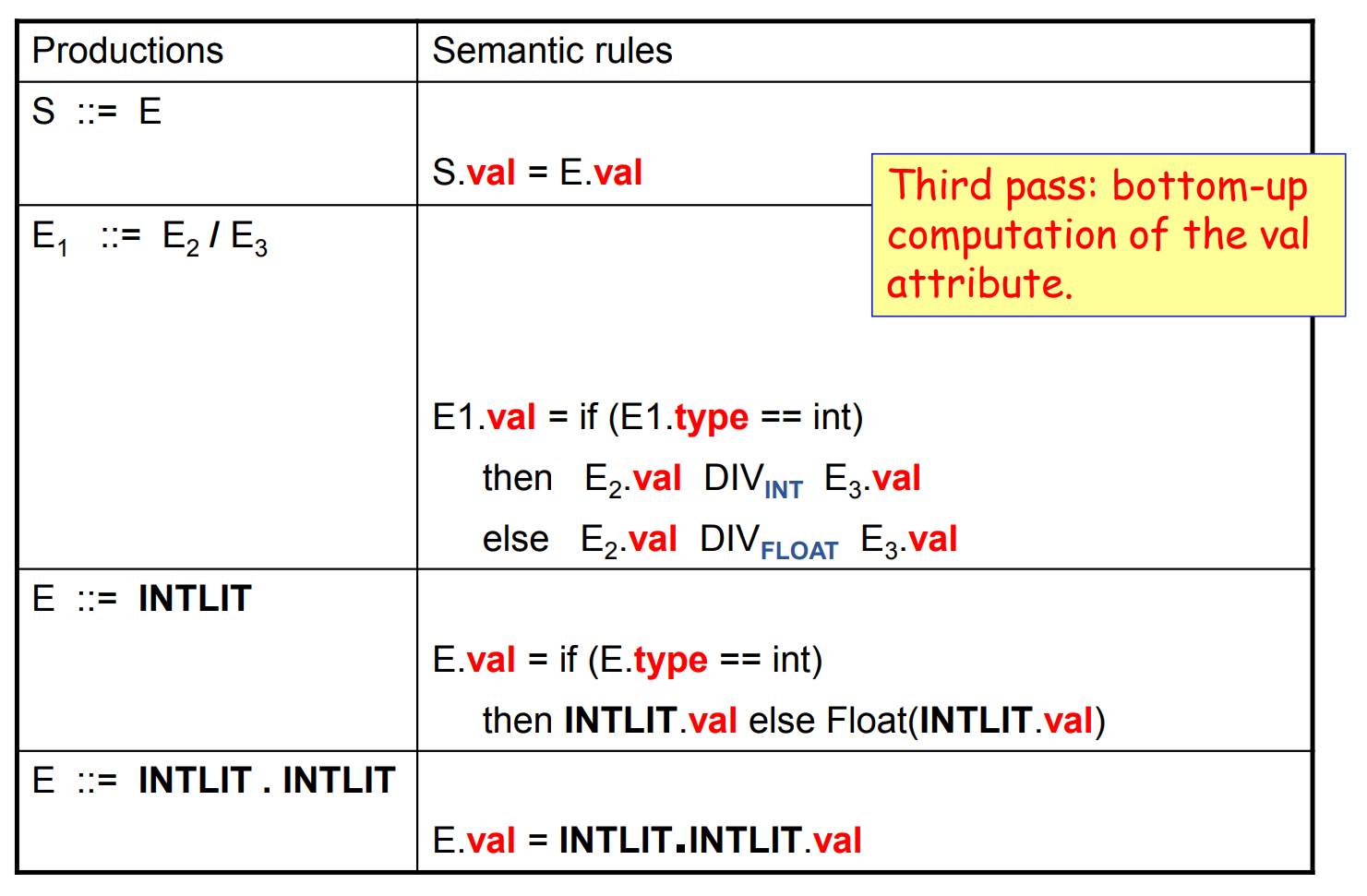
- INTLIT을 FLOAT에 대입시 변환해야 한다는것만 주의하고 bottom-up으로 계산한다.
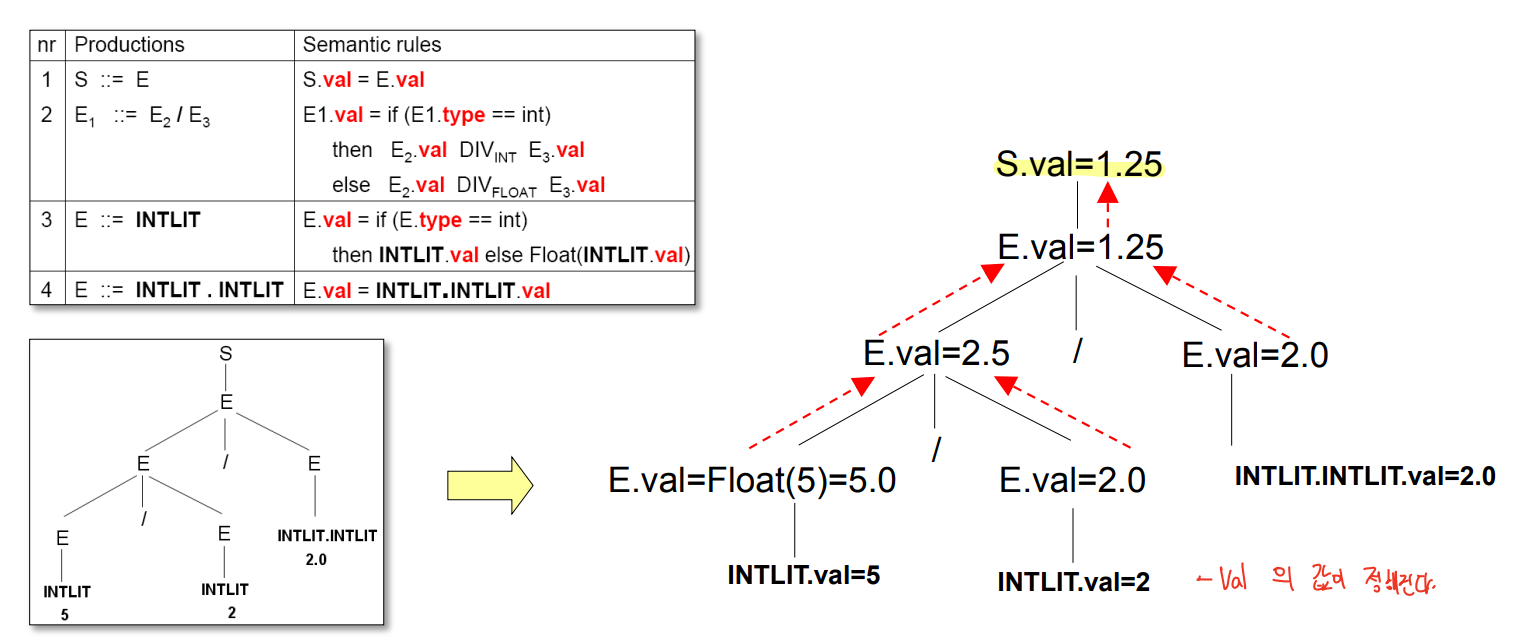
중요한 포인트
- INTLIT.val 과 INTLIT.INTLIT.val 은 스캐너 단계에서 계산된다.
- Intrinsic synthesized attribute 라 불린다.
- isFloat > Type > Value 순서로 찾아나가야 된다, 이 순서로 의존관계가 성립된다.
결과
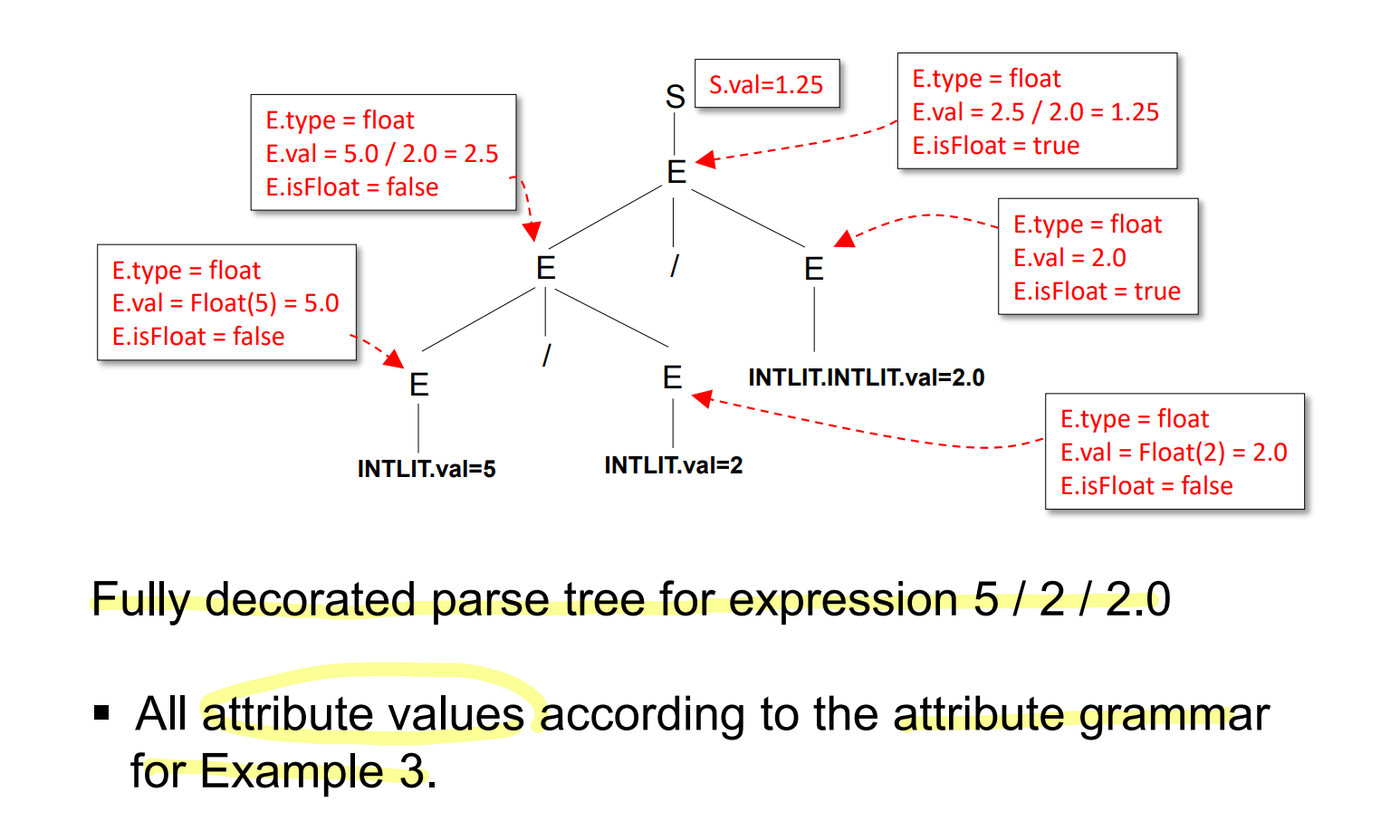
결론
- Symentic analysis 를 통해 Code generation 단계에서 fadd / iadd 중 무엇을 쓸지 등을 정할수 있다.
- 프로그래밍 언어의 규칙을 강제할수 있다.
- EX. 배열의 인덱스는 정수만 가능하다.
Attribute 계산하기
Tree walker
- 트리를 순회하며 Symentic rule들을 동작시킨다.
- 의존성 고리가 생길수도 있다, 즉 비 순환적 Attribute grammar에만 가능하다.
- isFloat > type > isValue 에서 isFloat이 isValue에 의존성이 생기는 경우 불가능
- 의존성 검사가 어려워 실질적으로 활용하기 어렵다 ( 지수 시간이 걸림 )
Rule-based grammar
- 트리를 사용한다.
- 모든 컴파일러/문법에 대해 작동한다.
- Visitor pattern을 사용한다.
Non-circular grammar evaluation


- visit : 해당 노드에서 해야 할 일을 처리한다.
- 첫 visit : preorder
- 마지막 visit : postorder
- traverse : 해당 노드로 진입한다.
- inorder
Visitor design pattern
- AST 생성 완료 이후..
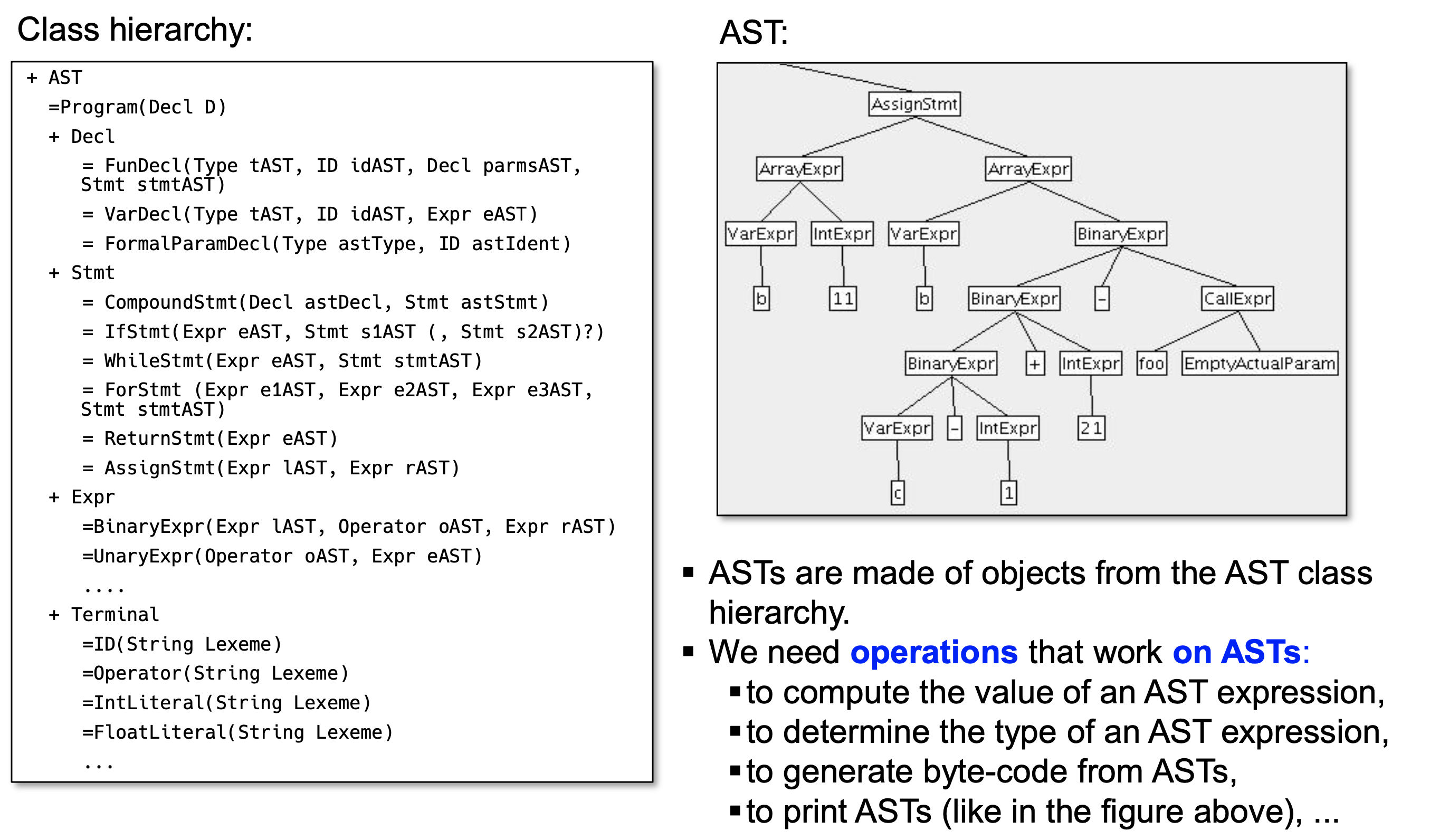
Operation - Expression 의 값을 계산해야 한다.
- Type을 확인해주어야 한다.
- AST를 통해 바이트코드를 생성해야 한다.
AST 에 Operation을 적용하는 방법
- Visitor design pattern 을 사용한다.
예시

- 자바 인터페이스를 사용하는 방식
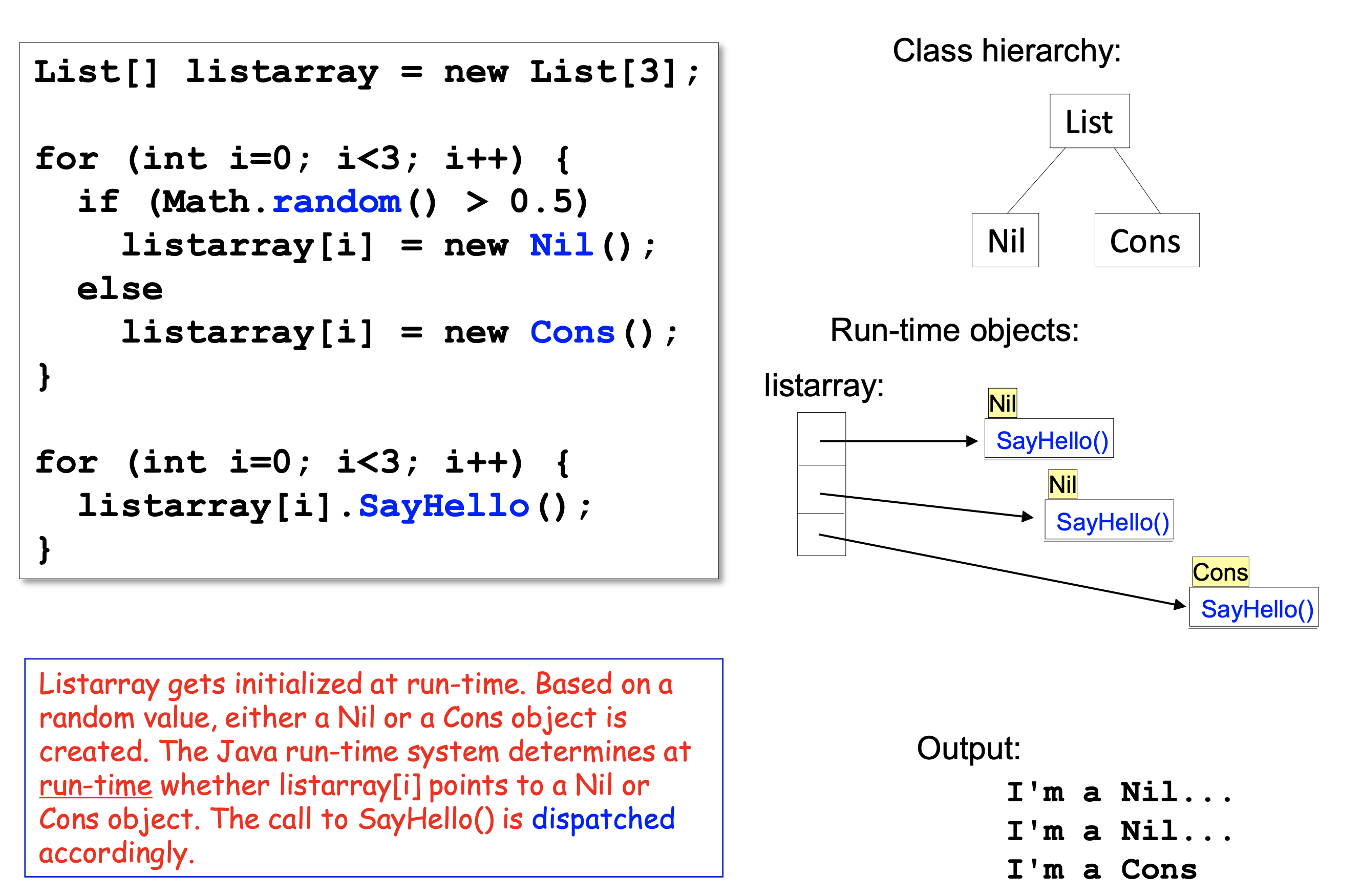
- 배열에 랜덤하게 생성하고 불러온다.
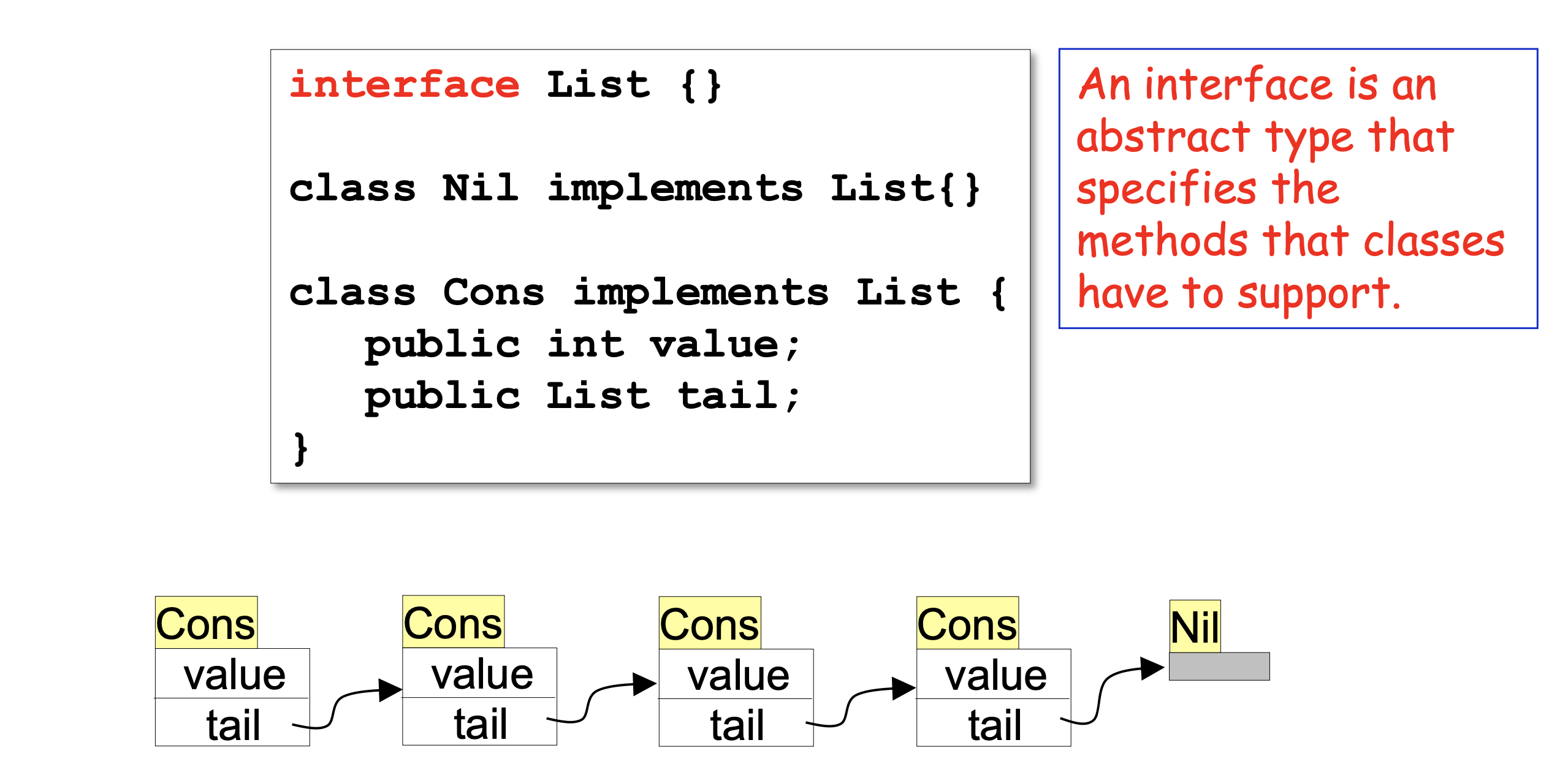
- 연결 리스트로 만들었을떄
- Nil은 값을 가지고 있지 않다.
모든 리스트의 값을 더하는 sum을 구현할때
- instanceof 를 사용해서 진행할수도 있다.
- L을 직접 Cons로 Type conversion을 해서 값을 가져와야 한다.
- 클래스를 확장하기 어렵다, 직접 다 추가해주어야 한다.

List 인터페이스에 sum 함수의 원형이 있으면

- 인터페이스를 implement한 모든 클래스에 sum을 구현해야 한다.


- 사용시는 아래와 같이 사용한다.
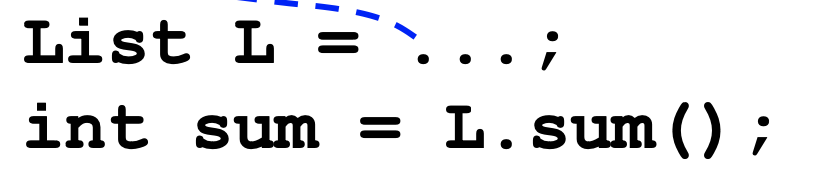
- 여전히 많은 클래스를 수정해야 해서 대규모 프로젝트에 어울리지 않는다.
Visitor 패턴
- 클래스 구조와 Visitor로 분리한다.
- visit은 내부적으로 타입을 통한 오버로딩을 한다.

- Nil과 Cons에 accept를 구현한다.
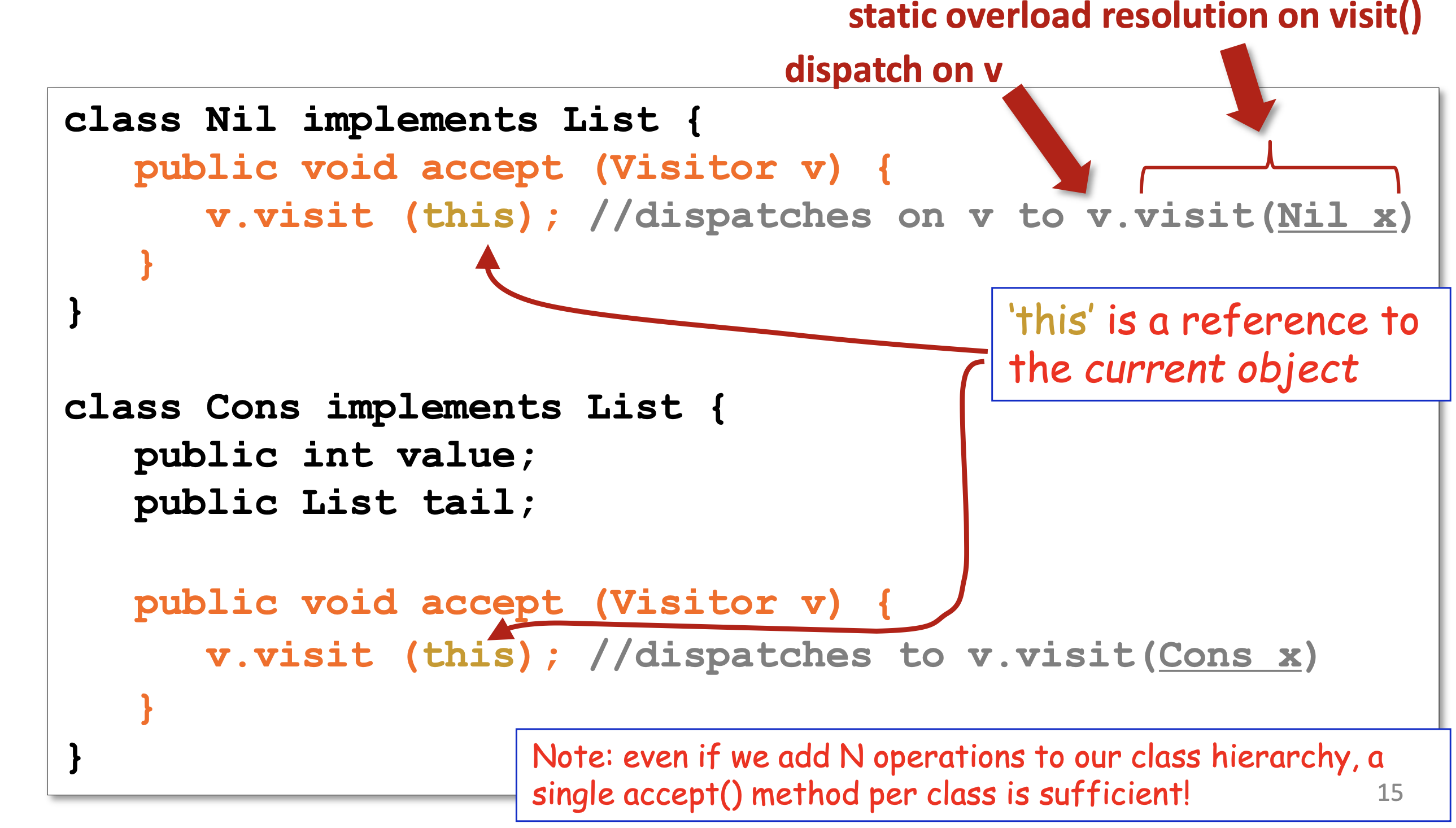
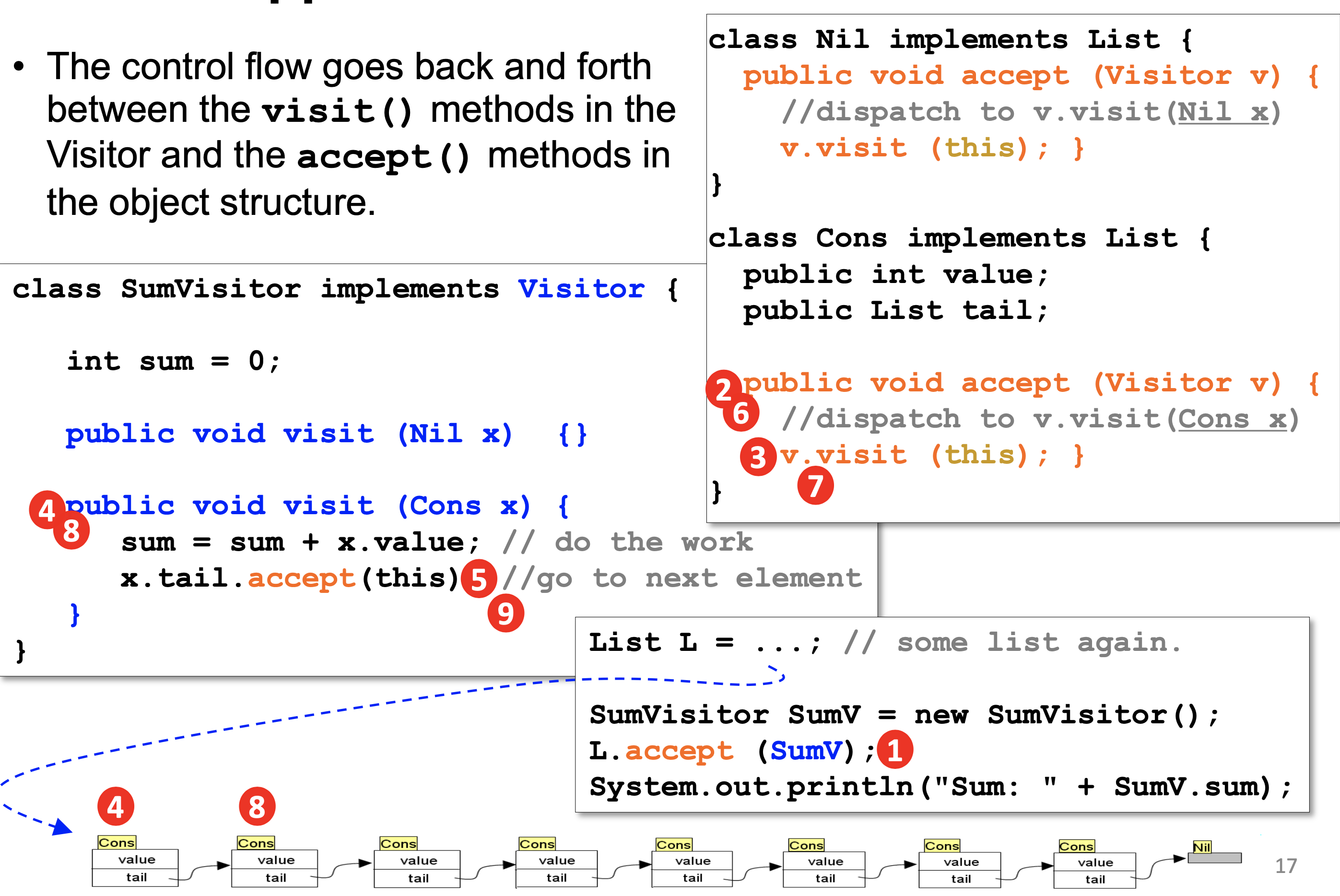
- sum을 구하기 위한 sumVisitor를 구현한다.
- Cons 와 Nil 이 들어올 경우를 둘 다 고려해야 한다.
- 결과는 결국 SumVisitor에 저장된다.

만능 컴덕후 겸 번지 팬