협업 필터링
- 협동하여 필터링 한다
- 많은 사람의 의견으로 더 나은 추천을 한다
- 종합적으로 분석한 추천 가능
집단 지성
- 개인보다 단체 또는 그룹의 선택 취향 의존
- 여러 사람의 의견 종합적 반영
협업 필터링이란?
- 유저 A, B모두 같은 아이템에 비해 비슷한 평가
- 유저 A가 다른 아이템에 비슷한 호감
- A,B 유저 성향 비슷할 것이므로 다른 아이템을 유저 B에게 추천
이웃기반 협업 필터링 (메모리 기반 협업 필터링)
- User-item간의 평점 등 주어진 데이터로 새로운 아이템 예측
- 특징
- 구현 간단
- Model-based CF에 비해 계산량 적다
- 새로운 user, item이 추가되더라도 비교적 안정적
유저기반 협업 필터링
- 두 사용자가 얼마나 유사한 항목을 좋아했는지 바탕으로 추천
- 취향이 비슷한 사용자끼리의 데이터를 바탕으로 추천 - 플랫폼에서 유저가 많은 부분을 차지하는 시스템에 적용하기 적절한 알고리즘
- SNS의 친구 추천 등에서 활용
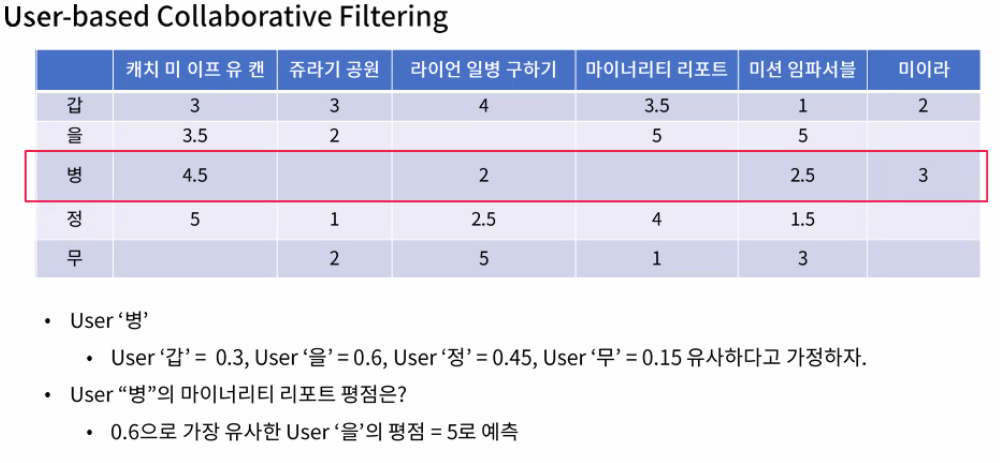
'병'이 '을'과 유사하다고 판단 '을'이 마이너리티 리포트에서 5점을 매겼기에 '병'도 5점이라고 예측
아이템 기반 협업 필터링
- 아이템과 아이템 사이의 유사도 계산
- 과거 아이템 선호도 데이터를 기반으로 선호 연관성이 높은 다른 아이템 추천
- 컨텐츠기반 추천시스템과 차이점: 여러 사용자의 과거 선호도 데이터로 연관성 높은 아이템을 찾고, 해당 아이템을 사용자에게 추천

유저 기반 vs 아이템 기반

자카드 유사도

분모는 A집합과 B집합 원소의 유니크한 개수- 7
분자 A 집합과 B집합의 교집합 - 2
자카드 유사도 = 2/7
피어슨 유사도 (피어슨 상관계수)
분모 : x에 대한 표준편차 * y에 대한 표준편차
분자 : x, y 공분산
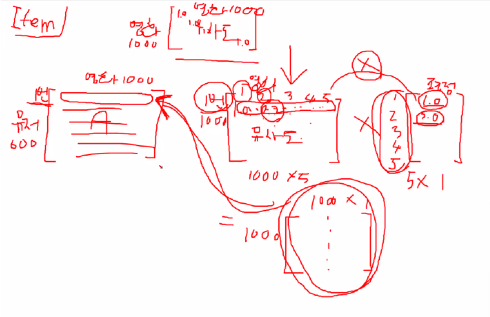
item base
행 : 1번~1000번 영화와
열: 1번 유저가 본 5개의 영화 유사도
영화 마다 평점 행렬 (5x1 행렬)
1번 사용자가 천개의 영화에 대해 몇점을 매길지
1번 사용자가 영화 천개에 대한 평점 예측 행렬
최종적으로 1000개 영화에 대해 1번 유저에 대한 영화 뿐만아니라 600 번 유저까지의 평점 예측
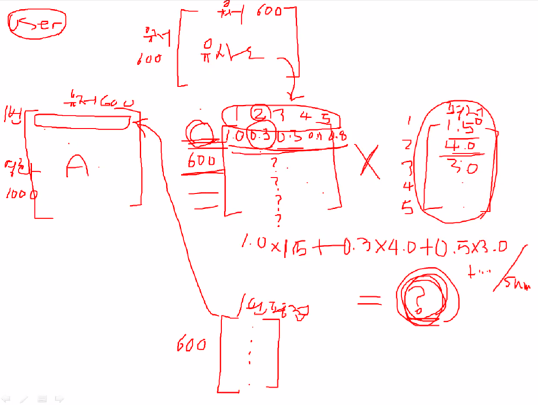
user base
갖고있는행렬 - 유저600명 x 유저600명 유사도
A행렬 : 예측하고자 하는 것 - 영화 1000개에 대한 유저600명의 평점
1번 영화에 대해 유저들의 평점을 예측해보기
1번 영화를 본 유저들의 정보만 가져오기 (5명)
그 5명이 모든 유저들과 어떤 유사도를 갖는지
(600x5)
1번~5번 유저들이 1번 영화에 대해 평점 어떻게 매겼는지
(5x1)
위 두개를 곱하고 /5 하면 (600x1) 행렬 생성
600명에 대한 1번 영화의 평점이 나옴
최종 A행렬에 한줄로 들어감
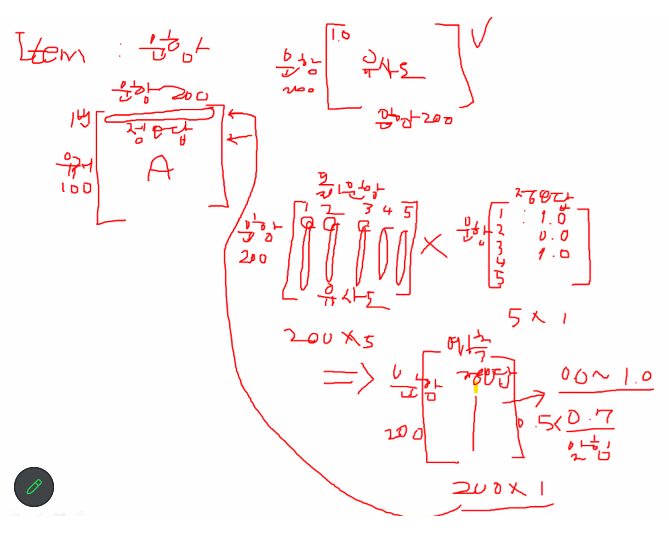
문항 정오답 예측
갖고 있는 정보 : 문항 200개에 대한 유사도
유저 100 x 문항 200 정오답 A
우선 위 행렬에서 유저 1번에 대한 정오답 예측하기
문항 200개와 유저 1번에 문항 5개 유사도 * 문항별 정오답

모델기반 협업 필터링
- 머신러닝을 가장 잘 활용한 추천 알고리즘의 일종
- 주어진 데이터를 활용하여 모델 학습
- 학습과정에서 모델이 테이터를 배워서 데이터 정보를 압축한다. (이웃기반 협업 필터링과 가장 큰 차이점: 학습을 한다) - 데이터 크기 또는 데이터의 특징을 동적으로 활용 가능하다.
모델기반 협업 필터링 장점
- 추천 모델(알고리즘)의 크기
- 수많은 데이터로 구성된 행렬보다 압축된 형태
- 추천 모델의 학습과 예측 속도
- 데이터 전처리 및 학습 과정으로 미리 모델 준비함으로 준비된 모델로 예측
- 추천모델 (알고리즘)의 과적합 방지
- 데이터를 다양하게 학습할 수 있으며, 새로운 추천을 할 가능성이 있다.
- Sparse data
- 유저-아이템 간 데이터 중 사용 가능한 데이터는 전체 데이터 중 비율이 작다
- 유저-아이템 간 데이터에서 표시되지 않은 항목은 새로운 추천을 하기 어렵다 (cold-start)
- Limited Coverage
- 공통의 유저 또는 아이템이 선택된 데이터 확보하기 어렵다
- 이웃기반 협업 필터링의 특성 중 '이웃'의 효과를 보기 어렵다.

한걸음씩 배워나갑니다