
1. More complex SQL Retrieval Queries
1-1. More Complex SQL Retrieval Queries
- Additional feature allow users to specify more complex and interesting retrievals from database
- Neted queires (중첩 질의)
- 외부 질의 + 내부 질의
- Joined tables (Natural Join)
- Outer Joins in the FROM clause
- Views (Derived Tables), Assertions, Triggers
- Aggregate functions (집계 함수)
- Grouping이 필요하다.
- Grouping
- Including online analytical processing operations
1-2. Comparisons Involving NULL and Three-Valued Logic
- SQL은 THREE-VALUED logic을 사용한다.
- NULL을 처리하기 위해 사용
- The result of evaluating an expression falls in
TRUE,FALSE,UNKNOWN
- NULL값 간의 비교는 불가능하다.
- [EXAMPLE] NULL = NULL < 불가능
- 만약 비교하교 싶다면 IS NULL or IS NOT NULL을 사용해야 한다.
- Logical connectives (truth table) in the three-valued logic

If문은 two-valued를 가진다.
TRUEorFALSE
- SQL은 attribute의 NULL 여부를
IS NULL로 판단한다.

- Super_ssn의 값이 NULL인 tuple을 listing
- Super_ssn의 값이 TRUE인 경우(존재하는 경우) 전체 값은 FALSE
- NULL인지 아닌지를 확인하고 싶으면,
WHERE Super_ssn IS NOT NULL
1-3. Nested Queries
-
Views를 사용하여 query 단순화가 가능해진다.
-
Outer query는
WHERE절 내에 완전한 select-from-where block을 가진 subquery or inner query를 가진다.
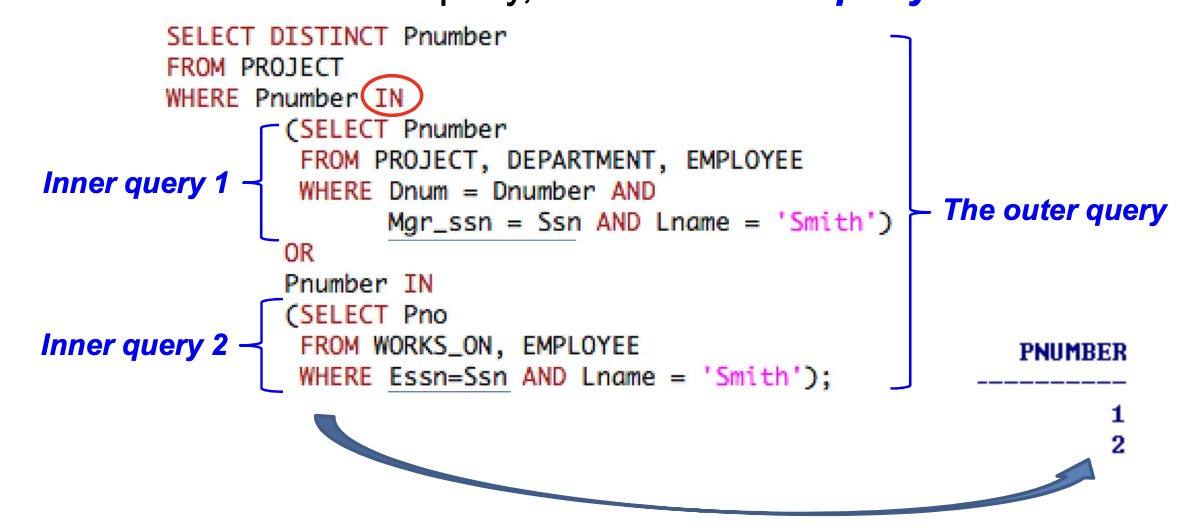
-
WHERE Pnumber IN안에 Inner query 집합들의 결과로 evaluate된다.
Set/multiset Comparison Operator : IN
v: 비교하고자 하는 개별 ValueV: 여러 개의 Value를 포함하는 집합 또는 다중 집합으로, 여러 값을 나타내는 요소를 포함할 수 있다.v IN V: values의 set(or multiset)인 V와 valuev를 비교V안에v가 있는 경우, TRUE
- Tuples of valuse를 통해 (그룹화) 하나의 튜플로 나타내는 방식
- 값을 튜플로 나타내거나 비교할 때 ()를 사용하여 값을 그룹화하고 튜플로 처리할 수 있다.
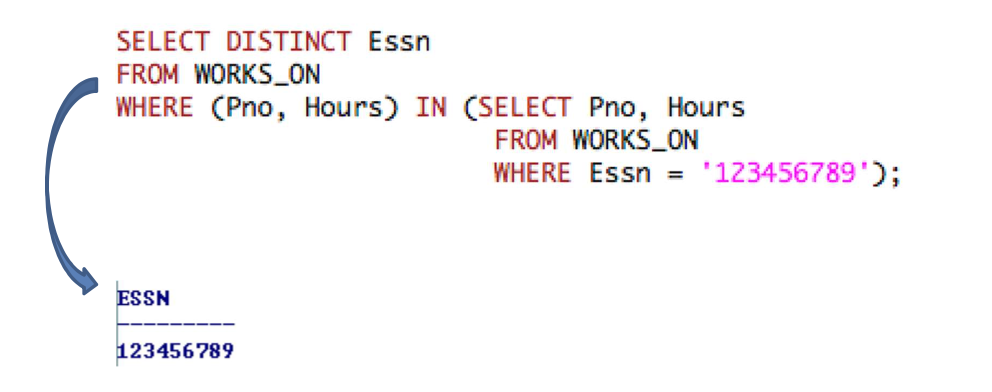
Nested Queries(Cont'd)
- single value
v를 비교하기 위해 다른 비교 연산자를 사용할 수 있다.ALL: nested query로부터 얻은 모든 values와 비교
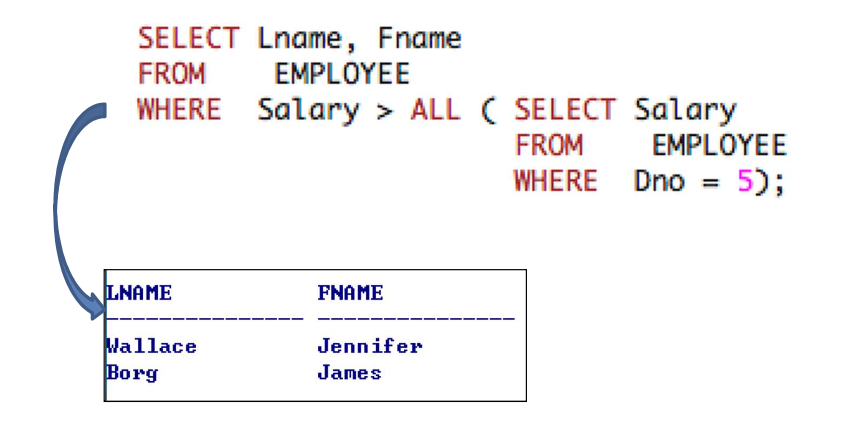
- SQL query에서 잠재적인 에러와 모호성을 예방하기 위해 aliases 생성
- [EXAMPLE] “Retrieve the name of each employee who
1) Has a dependent with the same first name,
and 2) Is the same gender as that of the employee.
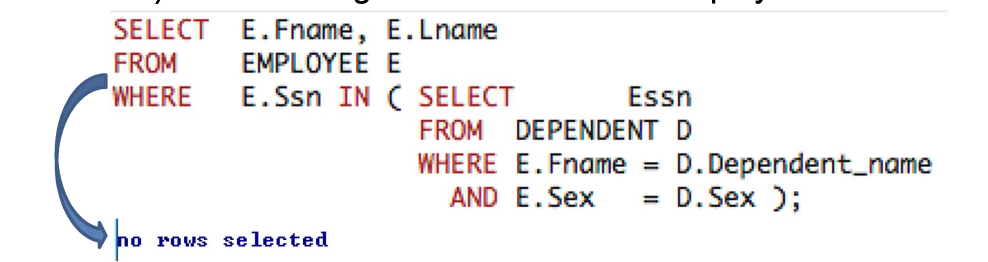
- [EXAMPLE] “Retrieve the name of each employee who
- Outer query tuple이 inner query에 적용된다.
- Called a correlated nested query (상호 연관된 중첩 질의)
- Outer query의 각 tuple과 한 번씩 비교
- Outer query tuple과 inner query tuple이 서로 연관
- ->
JOIN
- ->
- '=', 'IN'을 사용하는 Nested query는
JOINcondition을 사용하는 single query로 재 작성이 가능하다.- [EXAMPLE] THe previous query can be written in the following

- [EXAMPLE] THe previous query can be written in the following
1-5. The (NOT) EXISTS Functions in SQL for Correlating Queries
- (NOT) EXISTS function
- 중첩된 nested query의 결과가
'not empty'인지'empty'인지 check한다. - (NOT) EXISTS function은 중첩된 nested query와 함께 사용될 수 있다.
TRUEorFALSE을 RETURN 값으로 가진다.
-EXISTS
- 결과 생성이 가능하면 TRUE, 가능하지 않다면 FALSE
-NOT EXISTS
- 결과 생성이 가능하면 FALSE, 가능하지 않다면 TRUE
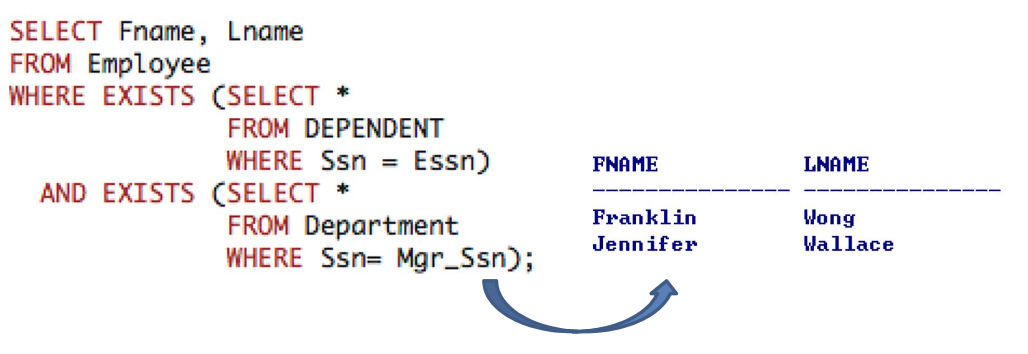
- 중첩된 nested query의 결과가
1-6. User of NOT EXISTS
- 모든 universal quantifier effect를 위해, SQL에서 이중 부정을 사용
- "...하지 않은 튜플들은 존재하지 않는다. -> ...한 튜플들만 존재한다."
- “Retrieve the name of employees working on “ALL” projects controlled by Dno = 5.”

WHERE 절
- 첫 번째
SELECT: 5번 부서가 관리하는 전체 PROJECT의 Pnumber를 return
- → {1,2,3}
- 두 번째
SELECT: EMPLOYEE가 참여하는 PROJECT의 Pno를 return
- → {1,2}
- {1,2,3}
MINUS{1,2} = {3}NOT EXISTS(3) => FALSE- 어떠한 tuple도 선택되지 않는다.
- 위의 query는 two-level nesting을 이용한 더 복잡한 방법으로 재작성될 수 있다.

1-7. Explicit Sets and Renaming in SQL
- Values의 explicit set은
WHERE절에서 사용될 수 있다.

WHERE PNO IN (1,2,3);==WHERE (PNO = 1) or (PNO = 2) or (PNO = 3);
- Arribute renaming
AS를 사용해서 attribute name을 변경할 수 있다.

1-8. Joined Tables in SQL and Inner Joins
- Joined Tables
- Concept : 사용자는 query의
JOINoperation을 사용하여 얻은 table을 ``FROM```절에서 사용할 수 있다.
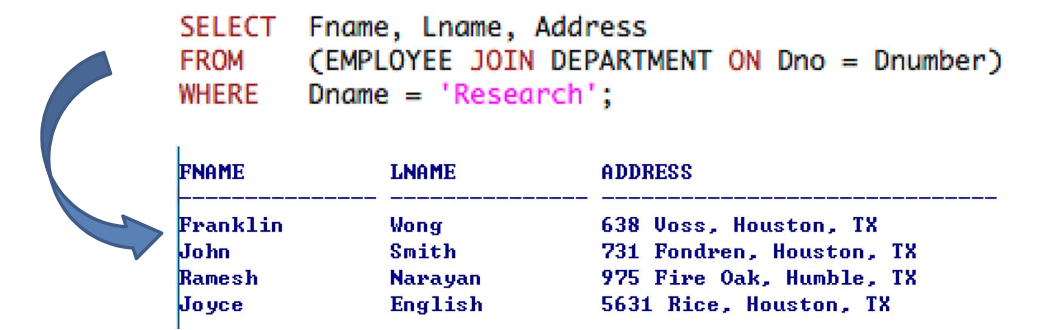
- Concept : 사용자는 query의
- single joined table에 포함되며, 이러한 join은
inner join이라 부르고 이는 tuple matching에 사용된다.
2. Different Types in JOIN
2-1. Different Types of JOINed Tables in SQL
Users Can specify different types of join
- Natural JOIN
INNER JOIN의 가장 대표적이다.- R (LEFT TABLE) ⋈ S (RIGHT TABLE),
JOIN조건을 명시하지 않는다. - 두 테이블 R and S간의 조인 연산은 이름이 같은 속성 쌍에 대한 암시적
EQUIJOIN(동증 조인 조건)을 생성하는 것과 동일하다.

CREATE TABLE DEPT AS- query의 결과를 table화 하겠다.
DUNBER as Dno- Natural join을 하기 위해 renaming
- Natural join을 하기 위해 renaming
- INNER JOIN (vs. OUTER JOIN)
- joined table에서의 default type
- 두 개 이상의 테이블을 조인할 때 사용되며, 조인 연산을 수행하는 두 테이블 사이에서 일치하는 행만 반환된다.
- 즉, 일치하는 튜플만 결과에 포함되며, 다른 테이블에서 일치하지 않는 튜플은 결과에 표시되지 않는다.
- non-matching tuples를 확인하고 싶은 경우는 OUTER JOIN 사용
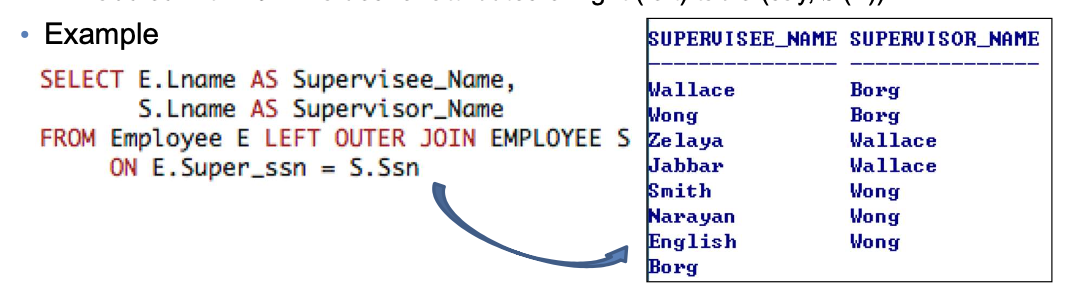
- LEFT(RIGHT) OUTER JOIN
- left(right) table에 있는 모든 tuple이 무조건 결과에 포함된다.
- matching tuple이 없는 경우, right(left) table의 attribute의 value에
NULL을 삽입
- FULL OUTER JOIN
- LEFT and RIGHT OUTER JOIN의 RESULT를 결합
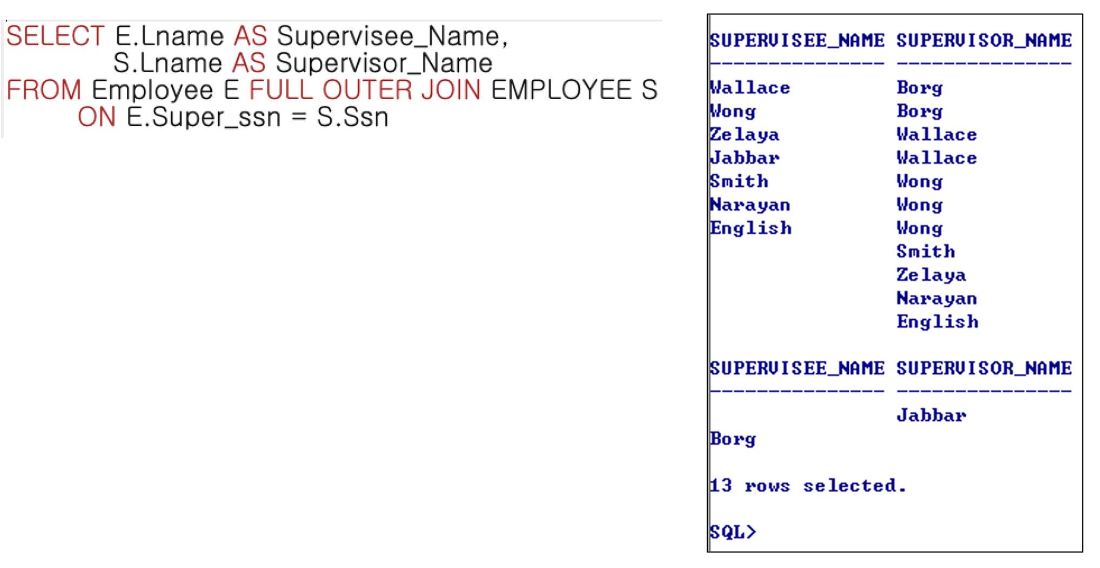
- LEFT and RIGHT OUTER JOIN의 RESULT를 결합
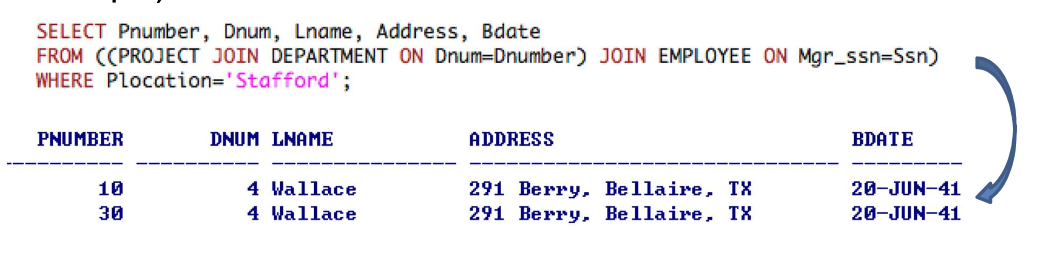
2-2. Multiway JOIN in the FROM clause
- "multiway" join은 JOIN specifications를 nesting하는 것으로 기술할 수 있다.
- [EXAMPLE]
2-3. Aggregate Functions in SQL
- Multiple tuples로부터 요약한 정보(통계, 요약, ...)을 single tuple에 group 단위로 가져오고 싶을 때 사용한다.
- Built in aggregate functions
COUNT,SUM,MAX,MIN,MEDIAN,AVG
- 일반적으로,
GROUP BY를 통해 Grouping한다.- summarizing 하기 전에 tuple의 subgroups를 만들어야 함
- 전체 그룹을 선택하기 위해(조건을 적용하기 위해),
HAVING을 사용한다. - Aggregate functions는
SELECT절이나HAVING절을 사용될 수 있다. - [EXAMPLE]

COUNT는 NULL 값에 대한 counting을 하지 않기 때문에 결과가 다른 것을 알 수 있다.
2-4. Grouping : The GROUP BY
-
tuples의 하위 집합으로의 *Partition relation
- grouping attributes을 기반으로 그들 중 같은 value를 가진 것을 선택
- 그러한 group에 독립적으로 function을 적용
-
Group ByClause- grouping attribute를 명시한다.
- grouping attribute는
SELECT절에 반드시 있어야 한다.
-
[EXAMPLE] Dno 값이 같은 tuple들로 grouping을 수행
- Dno가 select 절에 포함되어있는 것을 볼 수있다.
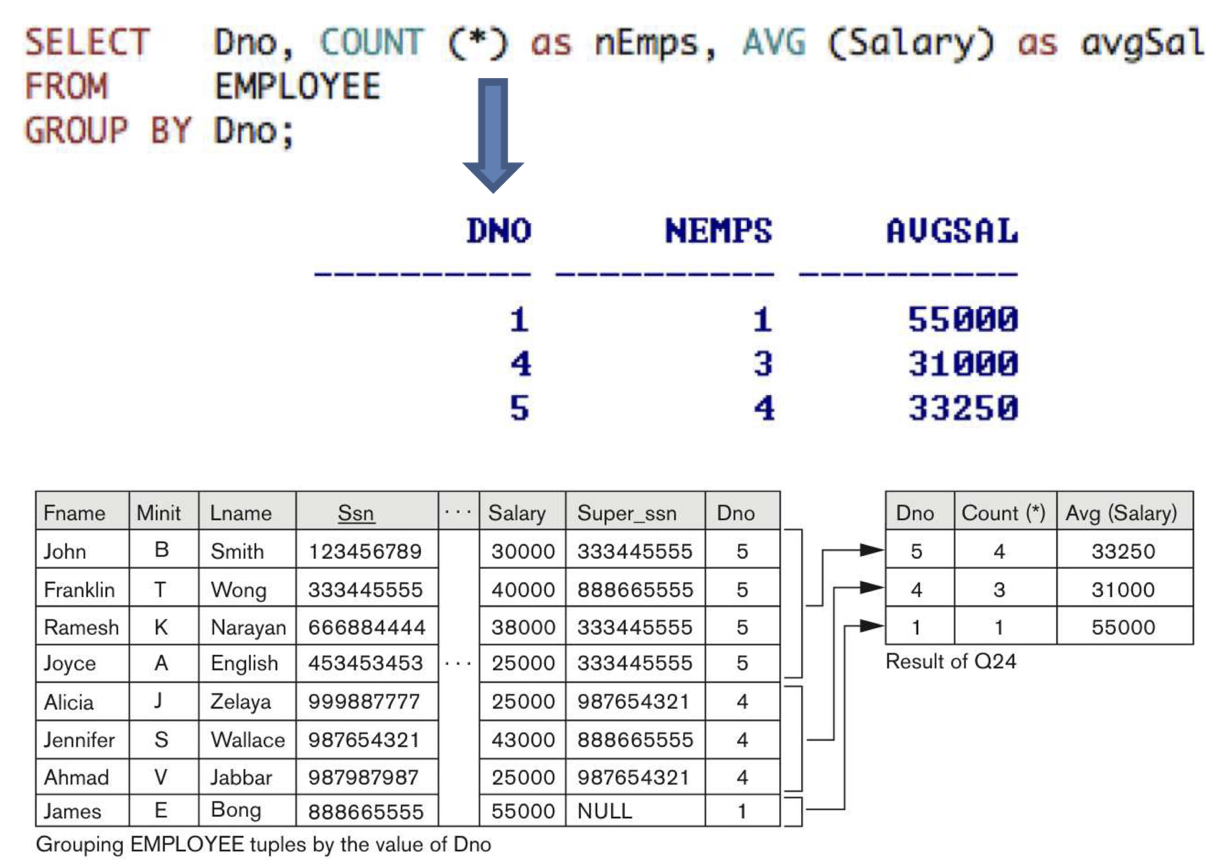
- Dno가 select 절에 포함되어있는 것을 볼 수있다.
-
JOIN의 결과에도 적용되어질 수 있다.- JOIN 결과에서 그룹화된 데이터를 생성하고 집계 함수를 사용하여 요약 정보를 얻을 수 있다.

- JOIN 결과에서 그룹화된 데이터를 생성하고 집계 함수를 사용하여 요약 정보를 얻을 수 있다.
GROUP BY사용 시, attributes의 기술 순서가 중요하다.
ORDER BY의 default는 오름차순이다.
2-5. Grouping : The GROUP BY Clause
HAVING Clause
- 전체 GROUP을 select하거나 reject하는 조건을 제공한다.
HAVINGClause의 위치는GROUP BY뒤에 위치한다.- [EXMAPLE]
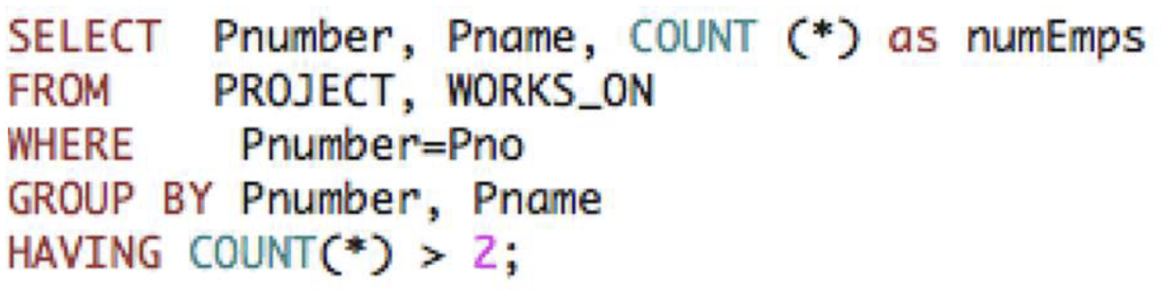
HAVING 절에 의해 선택되지 않은 Groups
Count가 2보다 크지 않다.
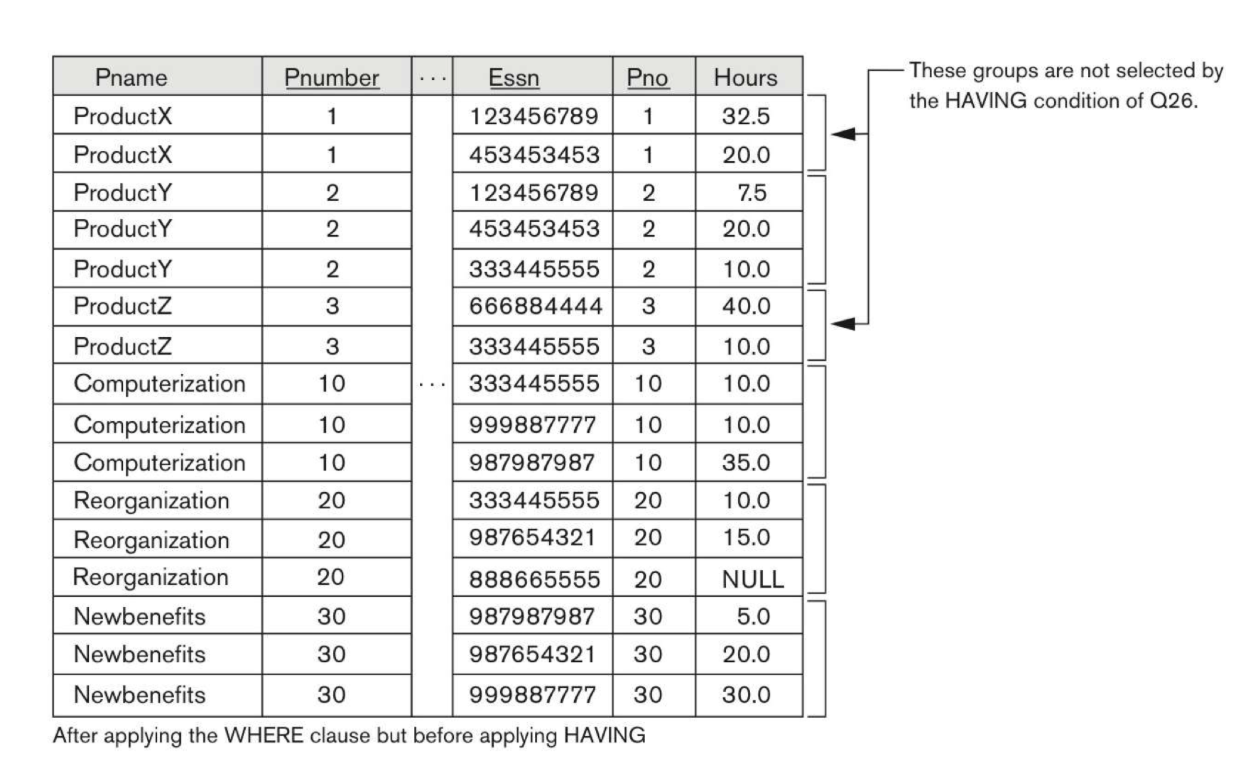
Result
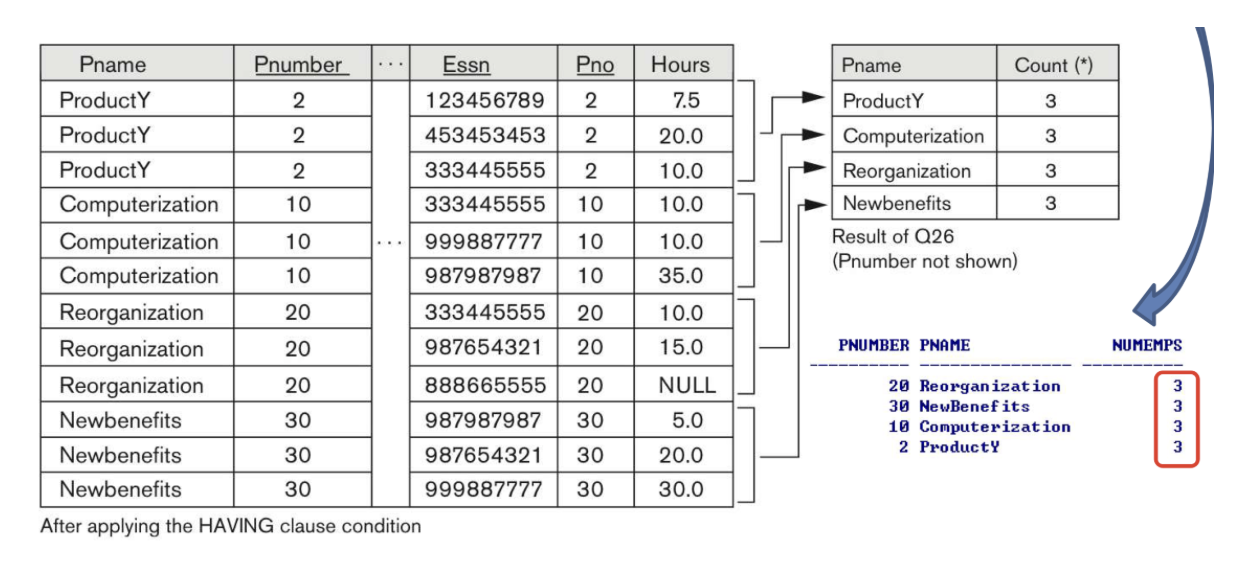
- [EXAMPLE]
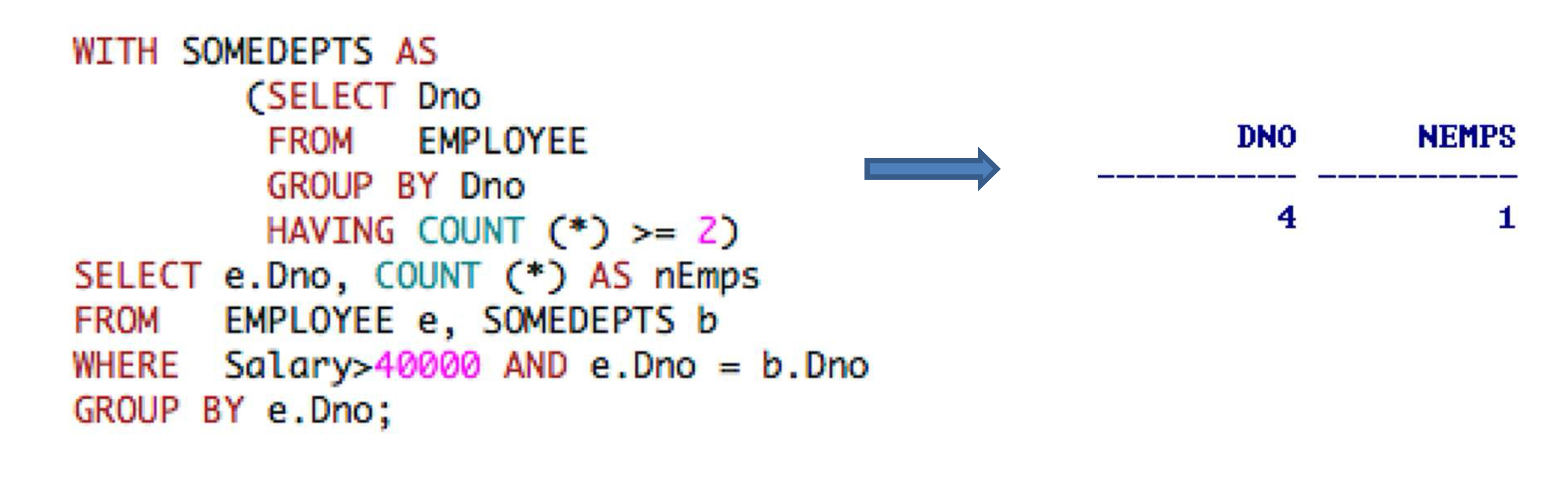
- “For each department with >= 2 employees, retrieve the department number and the number of its employee who’re earning > $40,000.

- “For each department with >= 2 employees, retrieve the department number and the number of its employee who’re earning > $40,000.
2-6. Grouping : The GROUP BY Clause with ROLLUP, CUBE, and TOP-N Clause
2-6-1. ROLLUP
- 데이터 집계를 수행할 때, 필요한 수준에서 중간 결과 또는 부분합계(subtotals)를 생성
- 소그룹간의 합계 계산
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY ROLLUP(상품ID, 월);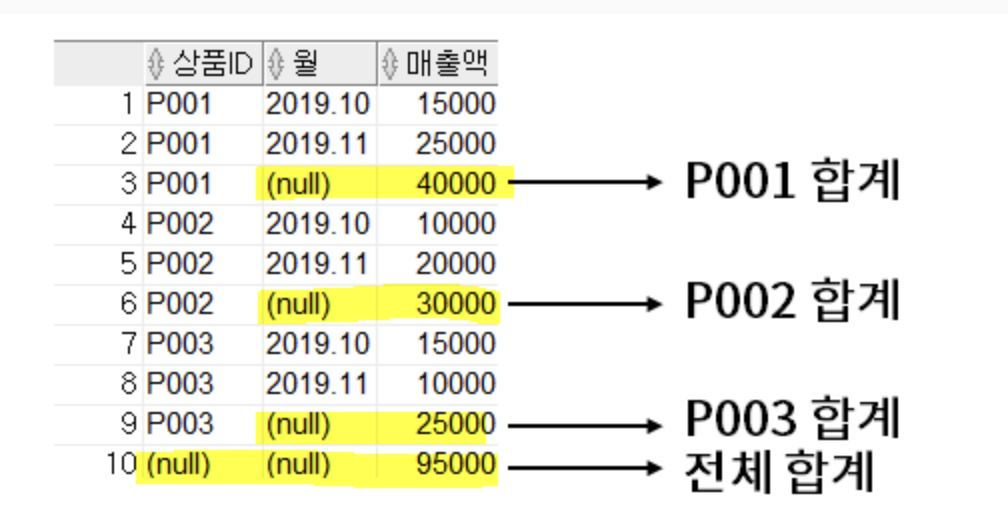
2-6-2. CUBE
- Data set이 여러 요소의 집합으로 이루어져 있다.
- 데이터를 분류하거나 그룹화하는 데 사용
- 각 조합에 대해 해당 조합에 해당하는 데이터의 소계를 계산
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY CUBE(상품ID, 월);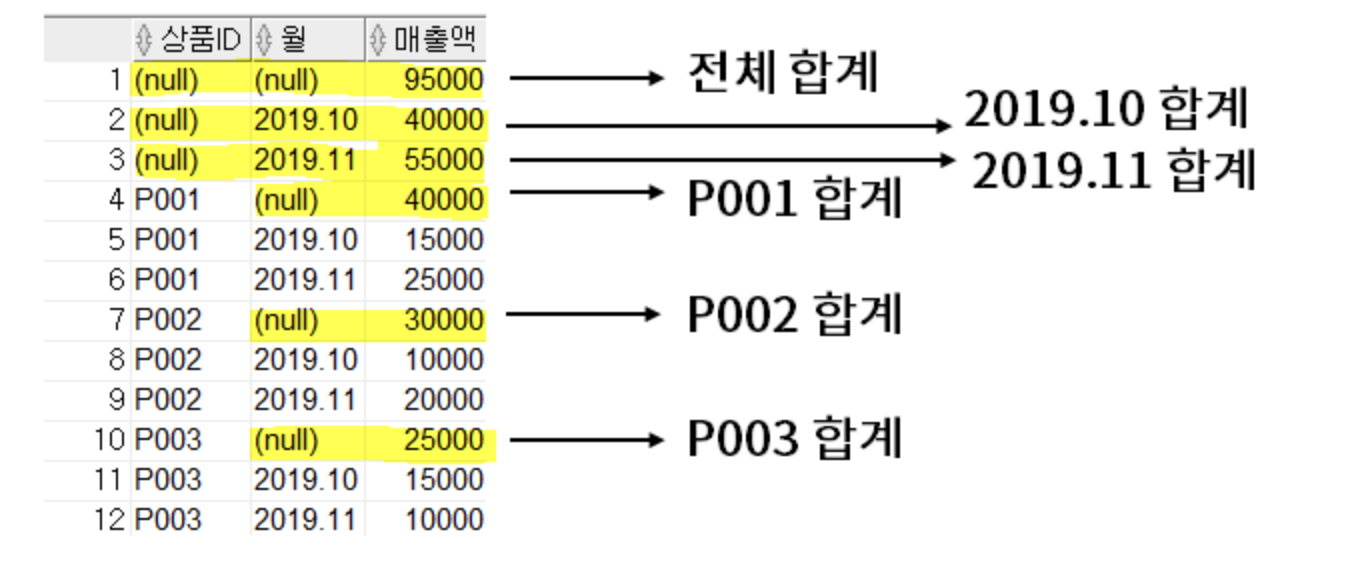
2-6-3. TOP-N
- 상위 N개의 데이터를 추출하는 쿼리
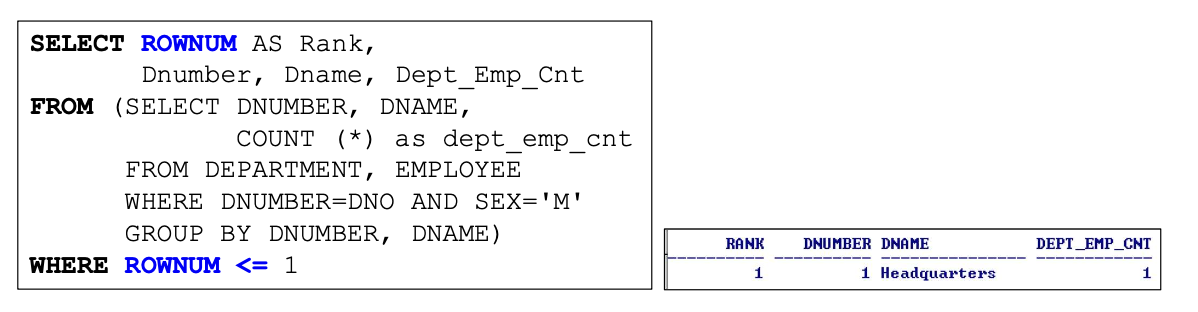
2-7. WITH Clause
- 오직 특정 쿼리에서만 사용될 (임시) 테이블을 정의할 수 있도록 한다.
- 임시 뷰(View)를 생성하고 즉서 쿼리를 사용할 수 있도록 하여 편의성을 제공한다.
- 이를 Inline view라고 함
- 2 - 5에 있는 두 번째 [EXAMPLE]을
WITH을 사용하여 다시 작성하면 다음과 같다.
2-8. Use of CASE Clause
- Value가 특정 조건에 따라 다른 경우에 사용한다.
- SQL 쿼리의 어떤 부분이든 value가 존재할 것으로 예상된다면 사용할 수 있다.
- Tuple에 대한 querying, inserting, updating에 적용 가능하다.

2-9. Recursive Queries in SQL
- 동일한 table에서 같은 유형의 튜플 간의 관계에 대해 반복적으로 연산을 수행하는 것
- [EXAMPLE] EMPLOYEE의 Super_ssn(FK)의 Relationship
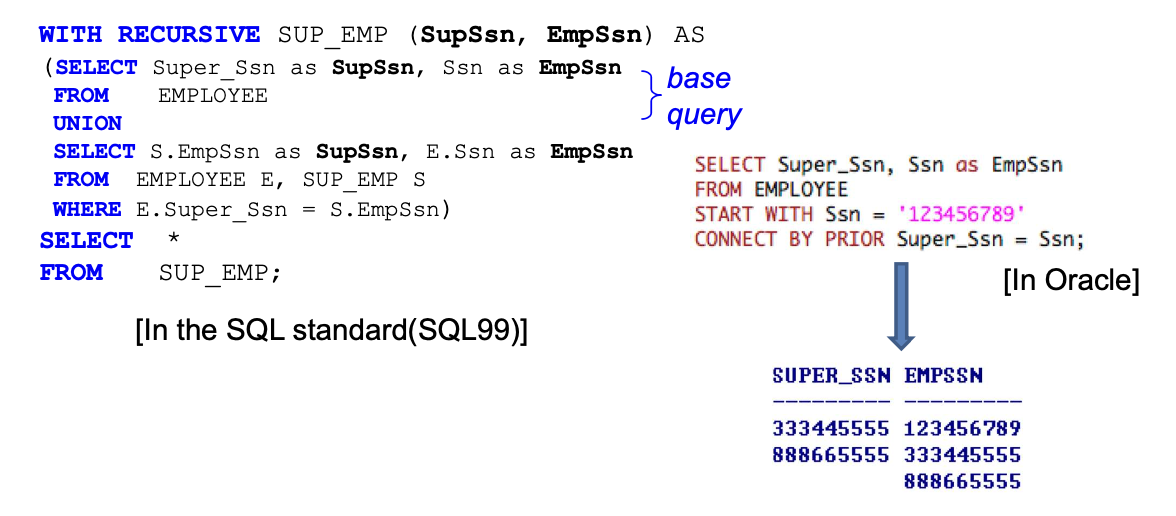
- [EXAMPLE] EMPLOYEE의 Super_ssn(FK)의 Relationship
- SUP_EMP에 대해 result tuples가 반복적으로 population된다..
START WITH: reculsive query를 시작할 attribute valueCONNECT BY PRIOR: 시작 tuple에서부터 해당 조건을 만족하는 tuple을 탐색
2-10. Reminder: EXPANDED Block Structure of SQL Queries

Reference
Database System Concepts | Abraham Silberschatz
데이터베이스 시스템 7th edition
https://for-my-wealthy-life.tistory.com/44

반갑습니다.