22.10.25.
오랜만에 velog 작성! 공부하기가 싫다. 피곤하다! 그래도 해야지! 밀린 velog는 언젠가...!
그동안 미드프로젝트를 진행했고, 미드프로젝트를 마무리 한 후 이제 머신러닝 수업에 들어갔다.
미드프로젝트 끝낼 때, 와 드디어 끝이구나 했는데, 끝은 무슨 이제 시작이었다! 다시 시작해보자. 파이팅!
어제 사실 머신러닝 첫 수업을 했었다. 내용은 머신러닝을 위해 사용하는 다양한 프레임워크에 대한 소개!
그리고 앞으로의 학습 방향! 등 이었다. 오늘부터 본격적으로 머신러닝 수업을 시작했다.
머신러닝 개요
- 인공지능 > 머신러닝 > 딥러닝
- 머신러닝은 지도학습(Supervised learning), 비지도학습(Unsupervised learning), 강화학습(Reinforcement learning)로 나뉜다.
- 머신러닝의 세부 분야는 다음과 같이 표로 나누어 기억하면 좋다고 하셨다.
| 범주형 | 수치형 | |
|---|---|---|
| 지도학습 | 분류 | 회귀 |
| 비지도학습 | 군집화 | 차원축소 |
scikit-learn
- 우리가 머신러닝을 구현할때 가장 많이 사용할 라이브러리
- 6가지의 대표 기능을 수행할 수 있다.
- 분류(classification) : 지도학습
- 회귀(Regression) : 지도학습
- 군집화(Clustering) : 비지도학습
- 차원축소(Dimensionality reduction) : 비지도학습
- 모델 선택 및 평가(model selection) : 모델의 매개변수를 조정하여 모델을 선택한다.
- 전처리(Preprocessing) : 데이터를 전처리하는데 활용한다.
머신러닝 알고리즘
-
머신러닝의 다양한 분야 중 특히 scikit-learn 의 개발자는 classification과 regression을 머신러닝의 주요 분야로 생각한다고 하여, 사이킷런에는 분류와 회귀가 잘 되어 있다고 한다.
-
머신러닝에는 다양한 알고리즘을 적용할 수 있다.
-
지도학습 알고리즘으로는 선형회귀, 정규화, 로지스틱 회귀, 서포트 벡터 머신, 나이브 베이즈 분류, 랜덤 포레스트, 신경망, k-최근접 이웃 알고리즘 등이 있다.
-
해당 알고리즘들은 분류 또는 회귀, 혹은 둘 모두에 적용할 수 있다.
-
특히, 로지스틱 회귀의 경우 회귀가 아닌 분류에 사용하는 알고리즘을 기억하자.
-
비지도학습 알고리즘으로는 주성분 분석, 잠재 의미 분석, 음수 미포함 행렬 분해, k-평균 알고리즘, 가우시안 혼합 모델 등이 있다고 한다... 아직 뭔지 하나도 모르겠지만, 차차 공부해나가자!
머신러닝의 과정
-
데이터 전처리
데이터 전처리는 필수적이다. 여태까지 배운바와 같이 EDA를 하며 전처리를 진행하기도 하고, 특히 머신러닝을 위해서는 Normalization, Scaling, Imputation(결측치 채우기), Encoding 등의 전처리를 진행하면 좋다. outlier도 판단하여 사용할지 말지 경정해야한다.
사이킷런의 알고리즘들은 결측치가 있다면 오류를 반환하기 때문에 imputation은 필수라고 한다. -
머신러닝의 과정(지도학습)
오늘 수업 중 가장 중요했던 내용! 머신러닝, 그 중에서도 지도학습의 과정을 기억하자.
- 데이터를 train set과 test set으로 나누고, train set을 Model 에 fit 시킨다.
- test set과 model을 이용해 Prediction을 해보고, Evaluation을 진행한다.
일단 끝! 데이터를 나누고, 학습시키고, 평가하면 된다.
이를 위해 코드에서 등장할 다양한 용어들을 살펴보자.
- feature_names, label_name : 머신러닝에서는 각각의 column들을 feature라고 한다. 지도학습의 경우, 데이터셋 내에 feature와 label(정답이 되는 값)이 함께 존재하기 때문에, 먼저 feature와 label을 구분해준다.
- (X_train, y_train), (X_test,y_test) : train set 과 test set으로 나눈 데이터. X는 feature이고, y는 label이다.
- model : 머신러닝에 사용할 알고리즘.
- model.fit(X_train, y_train) : train set을 입력으로 주어 모델을 학습시킨다.
- model.predict(X_test) : test set에 대해 모델을 사용해 예측한다.
- score : 모델의 성능을 나타내는 지표, 다양한 방법으로 구할 수 있다. (직접 계산, metrics의 알고리즘 사용, model.score 사용)
그럼 이제 지도학습의 알고리즘 중 하나인 Decision Tree 알고리즘을 알아보자.
Decision Tree
- Decision tree(결정 트리 학습법) : 결정 트리를 사용해서 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 학습법. 예측 모델링 방법 중의 하나이다. 흠...? 그러니까, 회귀 또는 분류 등의 머신러닝을 Tree를 통해 나타내는 방법인 것 같다.
위키백과 - 결정트리
각 노드가 질문의 형태를 이루고 있고, 그 질문의 답변에 따라서 데이터가 나누어지면 그게 바로 decision tree model 이다. 맨 처음의 노드가 root node, 중간은 intermediate node, 마지막은 terminal node 또는 leaf node라고 한단다. 결정 트리 내의 모든 노드에는 입력속성(클래스)가 일대일로 대응되며 각 노드에는 속성이 가질 수 있는 값이 표시, leaf node에는 클래스 또는 클래스의 확률 분포가 표시된다. 결정트리의 학습은 주어진 데이터를 적절한 분할 기준에 따라 부분집합들로 나누어 가는 과정을 통해 이루어진다.
결정 트리 분석법은 분류 트리, 회귀 트리로 나눌 수 있는데, 분류 트리의 경우 목표 변수가 유한한 값을 가지며, 회귀 트리의 경우 무한한 값을 가진다. 이렇듯 분류 및 회귀 트리를 일컬어 CART라고 한다.
- 결정 트리 학습법의 장점
- 결과를 해석하고 이해하기 쉽다.
- 자료를 가공할 필요가 거의 없다.
- 수치 자료와 범주 자료 모두에 적용할 수 있다.
- 화이트박스 모델을 사용한다.
- 안정적이다.
- 대규모의 데이터 셋에서도 합리적인 시간 내에 잘 동작한다.
실습 내용
당뇨를 예측하는 분석 모델 만들기.
DecisionTreeClassifier 이용, pima-indians-diabetes-database 이용.
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_diabetes.html
-
데이터 EDA
EDA부터 진행하여 데이터를 파악한다! describe 해보고 특이한 점 찾아보고, hist를 통해 수치형 변수의 전체 분포도 파악해본다.
특이한 점이 있으면 시각화를 해 어떤 양상을 띄고 있는지 파악도 해본다. -
Feature Engineering
feature를 적당히 조작하여 머신러닝에 더 적합한 형태로 만들 수 있다.
예를 들면, EDA 결과 임신 횟수라는 feature가 6을 넘어간다면, 당뇨일 가능성이 아주 커진다는 것을 발견하였고, 이에 수치형 변수인 임신횟수를, 6을 넘는지 안넘는지에 대한 범주형 변수 형태로 Encoding 해볼 수 있다.
df['Pregnancies_high'] = df['Pregnancies'] > 6이와 같은 feature engineering은 꼭 해야하는 것도, 성능의 향상을 보장하는 것도 아니다. 단지 이런 방향의 조작도 가능하다는 것을 생각하고 있으면 된다.
결측치를 다루는 것 역시 feature engineering에 해당한다고 볼 수 있다. 예를 들면 이 데이터 중 Insulin feature는 결측치 값들을 모두 0으로 포함하고 있었다. 이는 데이터의 해석에 큰 영향을 끼치기에, 결측치를 다른 값으로 채워주도록 하였다.(당뇨병인지, 아닌지로 구분한 각 그룹의 인슐린 평균값)
Insulin_mean = df.groupby('Outcome')['Insulin_nan'].mean()
df['Insulin_fill'] = df['Insulin_nan']
df.loc[(df['Insulin_nan'].isnull()) & (df['Outcome']==0), 'Insulin_fill'] = Insulin_mean[0]
df.loc[(df['Insulin_nan'].isnull()) & (df['Outcome']==1), 'Insulin_fill'] = Insulin_mean[1]음 여기서 엄청 오래걸렸다! 이런 코드로 진행해보려 했는데, 어디가 틀린건지 한참 찾았다...
df.loc[df['Outcome']== 0, 'Insulin_fill3'] = df['Insulin_nan'].fillna(Insulin_mean[0])
df['Insulin_fill3'] = df['Insulin_fill3'].fillna(Insulin_mean[1])한참 걸려서야 찾았다..... outcome이 0인 애들만 골라내어 fiilna를 해준 값을 컬럼 전체에 할당하면, fillna 함수를 적용한 결과물에는 outcome == 1인 행들이 존재하지가 않기 때문에, outcome이 1인 행들은 NaN이 된다. 따라서 이런 코드로 쓰려면 아래와 같이 작성해야 했다.
df['Insulin_fill3'] = df['Insulin_nan']
df.loc[df['Outcome']== 0, 'Insulin_fill3'] = df.loc[df['Outcome']== 0, 'Insulin_fill3'].fillna(Insulin_mean[0])
df['Insulin_fill3'] = df['Insulin_fill3'].fillna(Insulin_mean[1])- 학습, 예측 데이터셋 나누기
split_count = int(df.shape[0] * 0.8)
train = df[:split_count]
test = df[split_count:]8 : 2의 비율로 train set과 test set을 나누었다.
- feature와 label 나누기
feature_names = df.columns.tolist()
feature_names.remove('Outcome')
label_name = "Outcome"
X_train = train[feature_names]
X_test = test[feature_names]
y_train = train[label_name]
y_test = test[label_name]앞에서 언급했듯이, feature_names와 label name 을 이용해 데이터셋을 잘 나눈다.
- 머신러닝 알고리즘 가져오기.
scikit-learn의 DecisionTreeClassifier() 모델을 가져온다.
from sklearn.tree import DecisionTreeClassifier()
model = DecisionTreeClassifier(random_state = 42)model을 선언할때, 다양한 인자들(hyper parameter라고 한다. 여기서는 criterion, max_depth, max_features, min_samples_split 등)을 설정해줄 수 있다. 이는 모델의 성능에 큰 영향을 끼친다.
예를 들어, max_depth가 너무 적다면 underfitting(과소적합)이, 너무 크다면 overfittin(과대적합)이 발생할 수 있다.
- 학습(fitting)
model.fit(X_train, y_train)- 예측(Predict)
y_predict = model.predict(X_test)- 평가
세 가지 방법을 사용할 수 있다.
먼저 직접 계산하는 방법이다. 예측값과 정답이 같은 비율을 구한다.
(y_predict == y_test).mean()두번째는, 미리 구현된 알고리즘을 사용하는 방법이다.
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)세번째는, model의 score를 사용하는 방법이다.
model.score(X_test, y_test)이렇게 세 가지 방법으로 모델을 평가할 수 있다!
- 트리 알고리즘 분석하기
decision tree 알고리즘의 경우, 이를 시각화하여 분석해볼 수 있다. (white box model 이다.)
sklearn의 plot_tree를 사용해 시각화를 진행하면 된다.
from sklearn.tree import plot_tree
plt.figure(figsize = (20,20))
ptree = plot_tree(model, max_depth = 6, feature_names = feature_names, filled = True, fontsize = 10)
plt.show()결과물
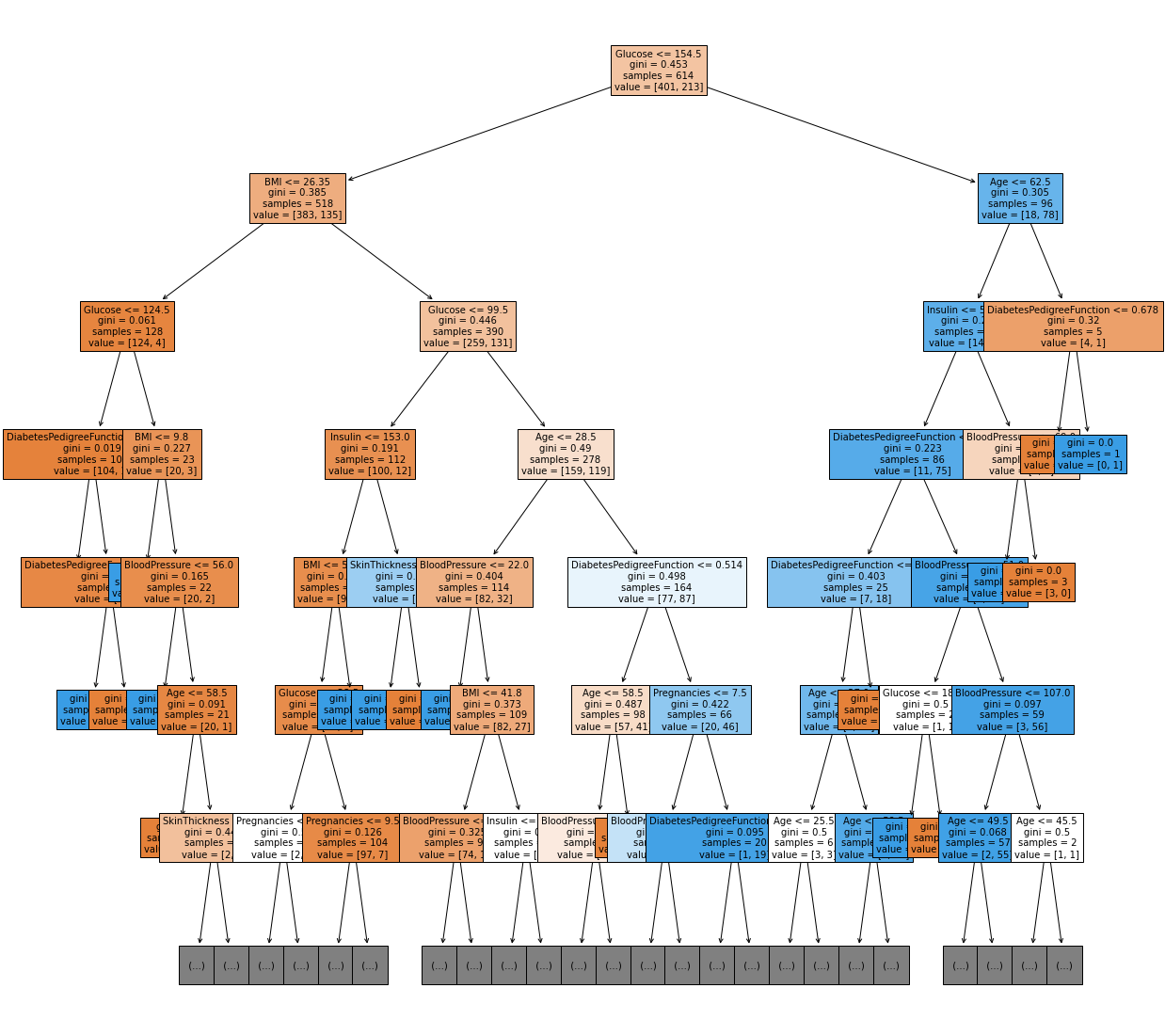
- 피쳐의 중요도 시각화하기
각 feature의 중요도 역시 추출하여 시각화 해볼 수 있다.
model.feature_importances_
sns.barplot(x = model. feature_importances_, y = model.feature_names_in_)더 공부해볼 것
- 이론적인 내용들을 더 공부해봐야할 것 같다...
- DecisionTreeClassifier()와 plot_tree에 대해 문서를 읽어봐야겠다.
- 집중력을 기르자!
