22.10.31.🎗️
머신러닝 기초에 대해 배우는 중.
회귀 평가 지표와 하이퍼파라미터 튜닝의 기초적인 내용들을 다루었다.
알고리즘 평가 지표
회귀의 평가 방법
MAE(Mean Absolute Error)
오차 절대값의 평균. 가장 직관적인 지표이다.
MSE같은 경우, 오차에 제곱을 시키기 때문에, 절대값 1 이하의 작은 값이나 아주 큰 값 등 이상치에 대해 민감하나, MAE는 상대적으로 이상치에 강건하여 변동성이 큰 지표와 작은 지표를 같이 예측할 시 유용하다.
mae = abs(y_train - y_predict).mean()
# 또는
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_train, y_predict)MAPE(Mean Percentage Absolute Error)
오차가 해당 값의 몇 %나 되는지의 절대값 평균. ((실제값 - 예측값) / 실제값) 의 절대값에 대한 평균이다.
mape = abs((y_train - y_predict) / y_train).mean()MSE(Mean Squared Error)
오차 제곱의 평균. 앞에서 언급했듯이 이상치에 민감하다.
MAE와 비교하였을 때엔 미분 가능하다는 차이가 존재한다.
계산 방식이 잔차의 분산이라고 생각할 수 있다.
mse = ((y_train - y_predict) ** 2).mean()
# 또는
from sklearn.metrics import mean_squared_error
mean_squared_error(y_train, y_predict)
RMSE(Root Meat Squared Error)
오차 제곱의 평균에 루트를 씌운 값. 루트를 씌웠기 때문에, MSE에 비해 오차에 덜 민감하다고 할 수 있다.
MAE는 오차의 절댓값의 평균이기 때문에, 모든 오차에 가중치 없이 그대로가 반영된다고 볼 수 있으나, RMSE는 MSE, 즉 오차를 제곱한 값들을 이용했기 때문에, 큰 오차와 작은 오차에 다른 가중치가 반영되었다고 볼 수 있다.
결론적으로, MAE에 비해서는 오차에 민감하나, MSE에 비해서는 덜 민감하다.
RMSE = np.sqrt(mse)R2
1 - RSS/TSS
RSS란, 잔차 제곱의 합이다.
TSS란, 데이터의 평균 값과 실제 값의 차이 제곱의 합이다.
R2는 회귀 모델의 설명력을 표현하는 지표로, 1에 가까울수록 높은 성능이다.
from sklearn.metrics import r2_score
r2_score(y_test, y_predict)결국, 데이터와 모델에 따라 그때그때 필요한 회귀 판단 지표를 선택하거나 직접 제작하여 사용해야 할 것이다.
분류의 평가 지표
- accuracy
- precision
- recall
- ROC/AUC
- F1-score
- logloss
등이 있다.
주요 평가지표들을 한번에 살펴보기 위해 다음 코드를 사용할 수 있다.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict_clf))train,test 데이터 만들기
train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)- feature와 label로 나누어져 있는 데이터 셋을 학습용과 평가용 데이터로 나누어주는 함수.
- test_size 또는 train_size를 통해 나누어줄 비율을 정한다. test_size의 기본값은 0.25이다.
- shuffle 를 통해 데이터를 나누어주기 전 랜덤하게 섞어줄 것인지를 정한다.
- stratify 를 통해 층화 표집(특정 변수의 여러 클래스의 비율을 동일하게 나누어 주는 것)할 변수를 정한다. (예를 들어 stratify = y이고, y가 0와 1로 이루어진 변수라면, train set에서와 test set에서 0 : 1의 비율은 유사하다.)
하이퍼 파라미터 튜닝
- 머신러닝 모델을 생성할때, Hyper parameter를 어떻게 설정하느냐에 따라 모델의 성능이 매우 달라진다.
- 그동안은 그냥 손으로 바꾸어보며 성능을 측정했지만, 이제는 grid search와 random search를 사용하여 하이퍼파라미터 튜닝을 하는 방법을 알아본다.
- 두 방법 모두 기본적으로는, 하이퍼파라미터들의 조합에 대해 교차검증(CV)를 통해 검증을 해보며 최고 점수가 나오는 하이퍼파라미터를 알아내는 방법이다.
- 다만 그 조합이, 주어진 모든 파라미터 후보군에 대한 조합인지, 그 중 랜덤한 일부에 대한 조합인지가 다르다.
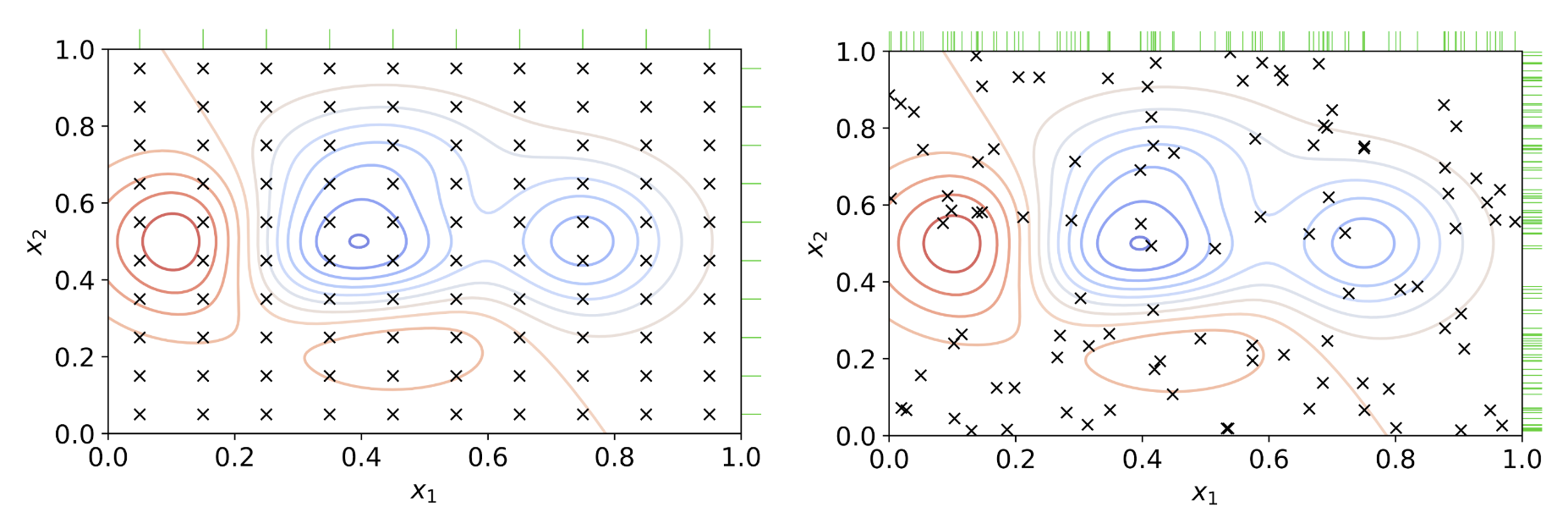
위 이미지 중, 왼쪽이 grid search를 이용한 것, 오른쪽이 random search를 이용한 것이라고 볼 수 있다. 출처 : 위키백과
GridSearchCV()
- 모델의 하이퍼파라미터 후보군들을 완전 탐색하여 최선의 하이퍼파라미터를 결정하는 방법.
- 검증하고 싶은 하이퍼 파라미터의 수치를 모두 조합해 검증하므로, 내가 원하는 범위에 대해 정확하게 비교하고 분석하는 것이 가능하다.
- 그러나, 모든 범위를 탐색하므로 시간이 오래걸리고, 내가 원하는 범위에 최적의 하이퍼파라미터 값이 없을 경우, 이를 찾아낼 수 없다는 단점이 있다. 따라서 범위를 잘 설정해 줘야한다.
- 여기서 범위라 함은, 연속적인 것이 아니라 이산적인 것이다. 아래 코드에서 보다시피 parameters로 주어지는 것이 바로 범위이다.
- paramter 인자로는 key - value 형식으로 파라미터 - 범위가 지정된 딕셔너리를 사용한다.
- 뒤에 CV가 붙어있듯이, cv값을 주어 몇개의 fold 로 교차 검증을 진행할지를 정한다.
- 그러면 총 검증 횟수는 cv 값 * paramter의 범위의 크기가 되겠다.
- 먼저 모델과 파라미터를 인자로 받아 GridSearchCV를 선언한 후, 이를 train data를 통해 학습시키는 형식으로 진행한다.
GridSearchCV를 통해 하이퍼파라미터 튜닝 후 확인할 수 있는 정보들은 다음과 같다.
- cvresults : 검증 결과를 담고 있는 리포트. key - value 형식으로 되어있으며, dataframe으로 변환하여 보면 좋다. 파라미터에 따른 순위 등이 나와있다.
- bestestimator, bestparams : 가장 좋은 성능을 낸 estimator(모델), paramter를 알려준다.
- bestscore : 최고 점수를 알려준다.
사이킷런을 이용한 코드는 다음과 같다.
max_depth = list(range(3,12,2))
max_features = [0.3, 0.5, 0.7, 0.8, 0.9]
parameters = {'max_depth' : max_depth, 'max_features' : max_features}
from sklearn.model_selection import GridSearchCV
clf = GridSearchCV(model, parameters)
clf.fit(X_train, y_train)
clf.best_estimator_
pd.DataFrame(clf.cv_results_).sort_values('rank_test_score')RandomizedSearchCV()
- random search는 grid search와 다르게, 주어진 모든 파라미터 후보군이 아니라, 후보군의 조합 중 랜덤한 몇개만 탐색하는 방식이다.
- 이때, 파라미터 후보군 자체를 범위만 주어지고 랜덤하게 정해지도록 하여 (np.random.randint 또는 np.random.uniform 등 이용) 활용한다.
- 랜덤하게 일부만 탐색하여 확인하기에 속도가 빠르다는 장점이 있고, 그리드 서치에서 정해진 후보군에 최적값이 없을 수 있다는 단점을 극복한다.
- 그러나, 하이퍼파라미터의 랜덤한 조합들 중에 최적의 조합이 있다는 보장이 없다.
- 랜덤 서치는 주로 넓은 범위에서 시작하여, 각 파라미터별로 성능이 잘 나오는 쪽으로 범위를 좁혀가며 다시 랜덤 서치를 진행하는 등의 방법으로 활용한다.
사이킷 런에서의 사용에 대해서 살펴보자.
- n_iter의 존재가 GridSearch와의 차이점이다. 이는 살펴볼 조합의 개수를 의미한다. 예를 들어 n_iter가 10이라면, 가능한 조합 중 임의로 10개의 조합만 살펴보는 것이다.
- 또 하나의 차이점은, paramters 대신 param_distributions가 사용된다는 점이 있다.
- GridSearchCV와 마찬가지로 cv, scoring(평가 지표), n_jobs, verbose 등 역시 존재한다.
코드는 다음과 같다.
from sklearn.model_selection import RandomizedSearchCV
param_distributions = {'max_depth' : np.random.randint(3,20,10), 'max_features' : np.random.uniform(0.5,1,10)}
clfr = RandomizedSearchCV(model, param_distributions= param_distributions, random_state= 42, n_jobs = -1, n_iter = 10, verbose = 3)
clfr.fit(X_train, y_train)
clfr.best_estimator_
clfr.best_params_
clfr.best_score_
pd.DataFrame(clfr.cv_results_).nsmallest(5,'rank_test_score')- 추가
더 찾아보다가, RandomizedSearchCV의 params_distribution에 매개변수를 샘플링할 수 있는 확률 분포를 인자로 주어도 된다는 것을 봤다. 진짠가?
param_distributions : dict or list of dicts
Dictionary with parameters names (str) as keys and distributions or lists of parameters to try. Distributions must provide a rvs method for sampling (such as those from scipy.stats.distributions). If a list is given, it is sampled uniformly. If a list of dicts is given, first a dict is sampled uniformly, and then a parameter is sampled using that dict as above.
그러네. 우리는 랜덤하게 추출해낸 값들의 list(array)를 인자로 줬지만, rvs 메소드가 존재하여 sampling 할 수 있는 scipy의 확률 분포를 인자로 줘도 된다고 나와있다. 두 방법 다 가능하다는 것을 알았다!
기타
seaborn에서 subplot 그리기
- Facetgrid 가 아닌, plt.subplots()를 이용하여 서브플롯 그리기!
fig, axes = plt.subplots(nrows = 1, ncols = 2, figsize = (12,4))
sns.countplot(x = y_train, ax = axes[0]).set_title('train')
sns.countplot(x = y_test, ax = axes[1]).set_title('test')위와 같이 사용할 수 있다!
np.random.uniform
넘파이에서 제공하는 균등 분포 함수로, 최소값, 최대값, 데이터 개수의 인자를 주면 해당 값을 균등히 나누어 array를 만들어준다.
pandas - aggregation
.agg({'column' : 'func', 'column' : 'func'})와 같이 사용하여 각 컬럼들에 다른 여러 함수를 적용해 줄 수도 있다...!
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사님의 자료를 참고하였으며, 일부 인용하고 있습니다.
더 공부해볼 것
- 어제 들은 유튜브 예습강의에서, 강사님은 하이퍼파라미터 튜닝 방법 중 베이지안 최적화를 가장 많이 사용한다고 하셨는데, 좀 찾아봐야겠다.
- 집중하자 집중..!
