Basic Concepts
Motivation : 멀티 프로그래밍 및 멀티 테스킹으로 얻은 CPU 활용률을 최대화하기 위함
- 프로세스 간에 (CPU를 포함하는) 리소스를 공유한다
CPU-IO Burst Cycle
- 프로세스 실행은 CPU 실행과 I/O 대기의 주기(cycle)로 구성된다.
- 첫번째 및 마지막 burst는 CPU burst이다.
프로세스의 타입
- I/O-bound 프로세스
- 많은 짧은 CPU burst로 구성
- CPU-bound 프로세스
- 적고 긴 CPU burst로 구성
- CPU burst 다음에 I/O burst가 뒤따른다.
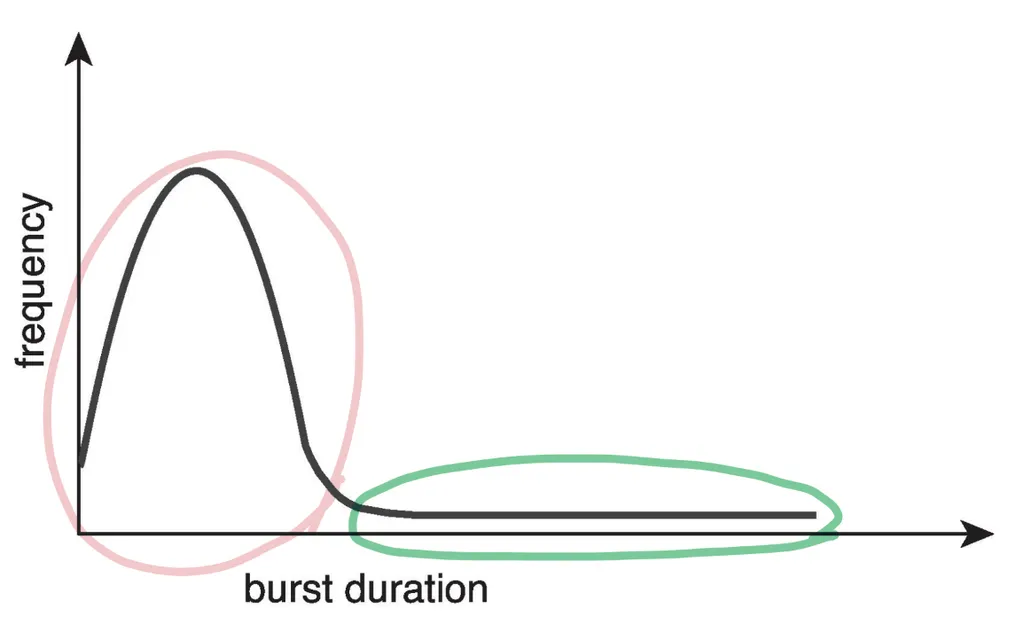
Histogram of CPU-burst Time
CPU burst의 분배가 주요 관심사이다.
- 짧은 burst 수가 많다 (I/O-bound 프로세스)
- 긴 burst 수가 적다 (CPU-bound 프로세스)
CPU Scheduler
= short term scheduler
cpu 스케줄러는 ready queue에 있는 프로세스 중에서 선택하고 그 중 하나를 선택해 CPU를 할당한다.
ready queue 구현
- FIFO queue, priority queue, a tree, 또는 단순히 순서화된 linked list
- 각 프로세스는 PCB로 표시된다
When Scheduling Occurs?
- running → waiting 상태로 전환 ex) I/O request, wait() 호출 (invocation)
- running → ready 상태로 전환 ex) interrupt
- waiting → ready 상태로 전환 ex) I/O 완료
- 종료 상태 (terminates)
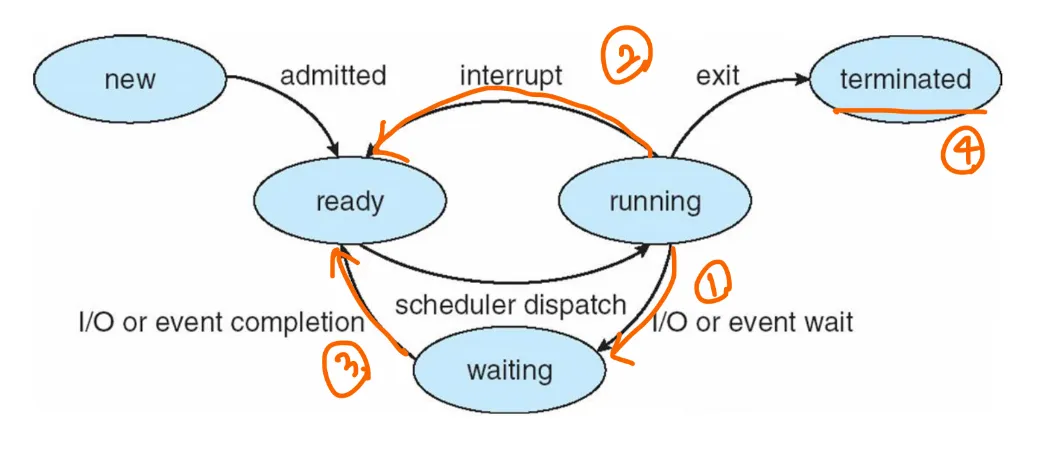
1,4번의 경우, 선택의 여지가 없다.(→ 하나의 프로세스를 선택할 필요가 없다!) Nonpreemtive(비선점)
실행을 위해 새로운 프로세스가 반드시 선택되어야 한다.
2,4번의 경우, 선택의 여지가 있다. preemptive(선점)
Preemptive Scheduling
- 비선점(or cooperative) 스케줄링
- 스케줄링이 1,4번 상황에서만 발생한다.
- 실행 중인 프로세스가 중단되지 않는다.
- 선점 스케줄링
- 1,2,3,4번에서 다 발생할 수 있다.
- 프로세스가 실행 중인 동안 스케줄링이 발생할 수 있다. interrupt, 프로세스가 높은 우선순위로 처리
- H/W 지원 및 공유 데이터 처리가 필요하다.
- 선점 스케줄링은 여러 프로세스 간에 데이터를 공유할 때 race condition을 초래할 수 있다.
Dispatcher
Dispatcher 모듈은 단기 스케줄러에 의해 선택된 프로세스에 대한 CPU 제어를 제공한다.
이는 다음과 같은 작업을 포함한다
- 한 프로세스에서 다른 프로세스로 컨텍스트 전환
- user mode로 전환
- 프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동
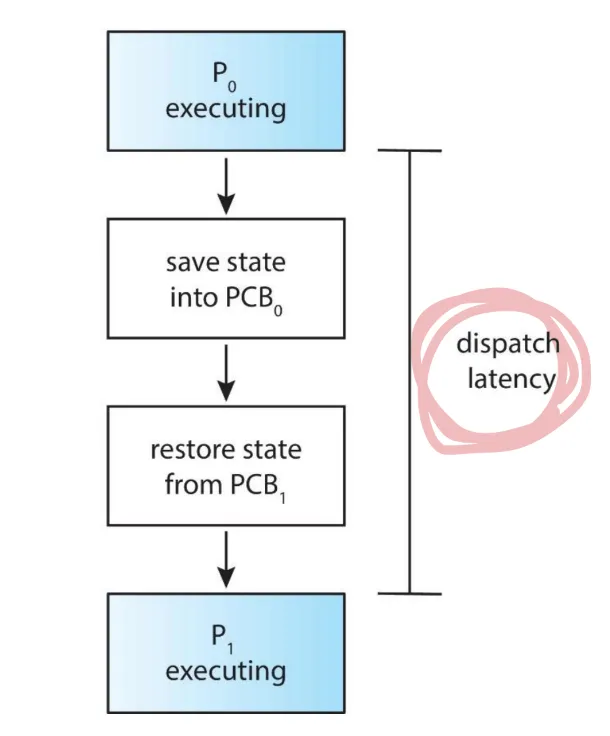
context switch가 하고 CPU는 아무것도 안함
Dispatch latency(디스패치 지연) 은 디스패치가 한 프로세스를 중지하고 다른 실행을 시작하는 데 걸리는 시간을 의미한다.
Scheduling Criteria
스케줄링 기준
서로 다른 CPU 스케줄링 알고리즘들은 다른 특성을 가진다.
- CPU 이용률 (CPU utilization) : CPU를 가능한 바쁘게 유지시키는 것
- 처리량 (throughput) : 시간당 실행을 완료하는 프로세스 개수
- 총 처리 시간 (turnaround time) : 프로세스 제출부터 완료까지의 간격.
ready queue에서 대기한 시간, CPU에서 실행하는 시간, I/O를 수행하는 시간의 합계.
- 대기 시간 (wating time) : ready queue에서 대기한 시간의 합계
- 응답 시간 (response time) : 요청이 제출된 후 첫 번째 응답이 시작될 때까지 소요된 시간. 즉 응답이 시작되는 데까지 걸리는 시간
→ 각 기준의 중요도는 시스템에 따라 다르다.
최적화를 위한 조치
- 평균 / 최소값 / 최대값
- variance
Scheduling Algorithms
- First-come, first-served(FCFS) scheduling
- Shortest-job-first (SJF) scheduling
- Priority scheduling
- Round-robin scheduling
- Multilevel queue scheduling
- Multiple feedback-queue scheduling
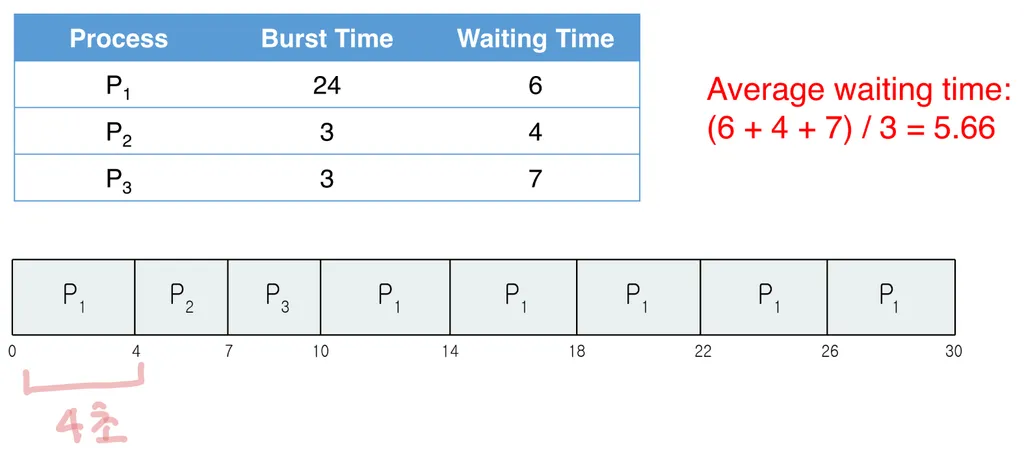
1. First-come, first-served(FCFS) scheduling
프로세스가 먼저 요청받은 CPU를 먼저 처리한다.
- non-preemptive scheduling (비선점 스케줄링)
- 가장 간단한 스케줄링 방법
가끔씩 평균 대기 시간이 길다.
- CPU, I/O 활용성이 비효율적이다. 예) 3개의 프로세스를 요청받을 때 아래와 같다.

입력받은 순서대로 하면 평균대기시간이 “17초”이지만, P2, P3, P1 순서대로 바꾼다면 대기시간은 “3초”로 줄어든다.2. Shortest-job-first (SJF) scheduling
다음 CPU Burst 시간이 가장 작은 것부터 순서대로 처리한다.
예) 4개의 프로세스를 요청받을 때 아래와 같다.

- SJF 알고리듬은 대기 시간을 최소화하는 데에 최적화(optimal) 알고리듬이다.
- 문제점 : 다음 CPU burst의 길이를 알기 힘들다.
history로부터 다음 CPU burst 예측하기
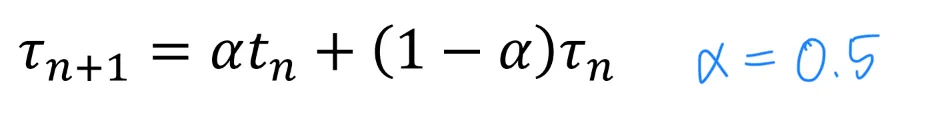
usually, = 0.5
예)
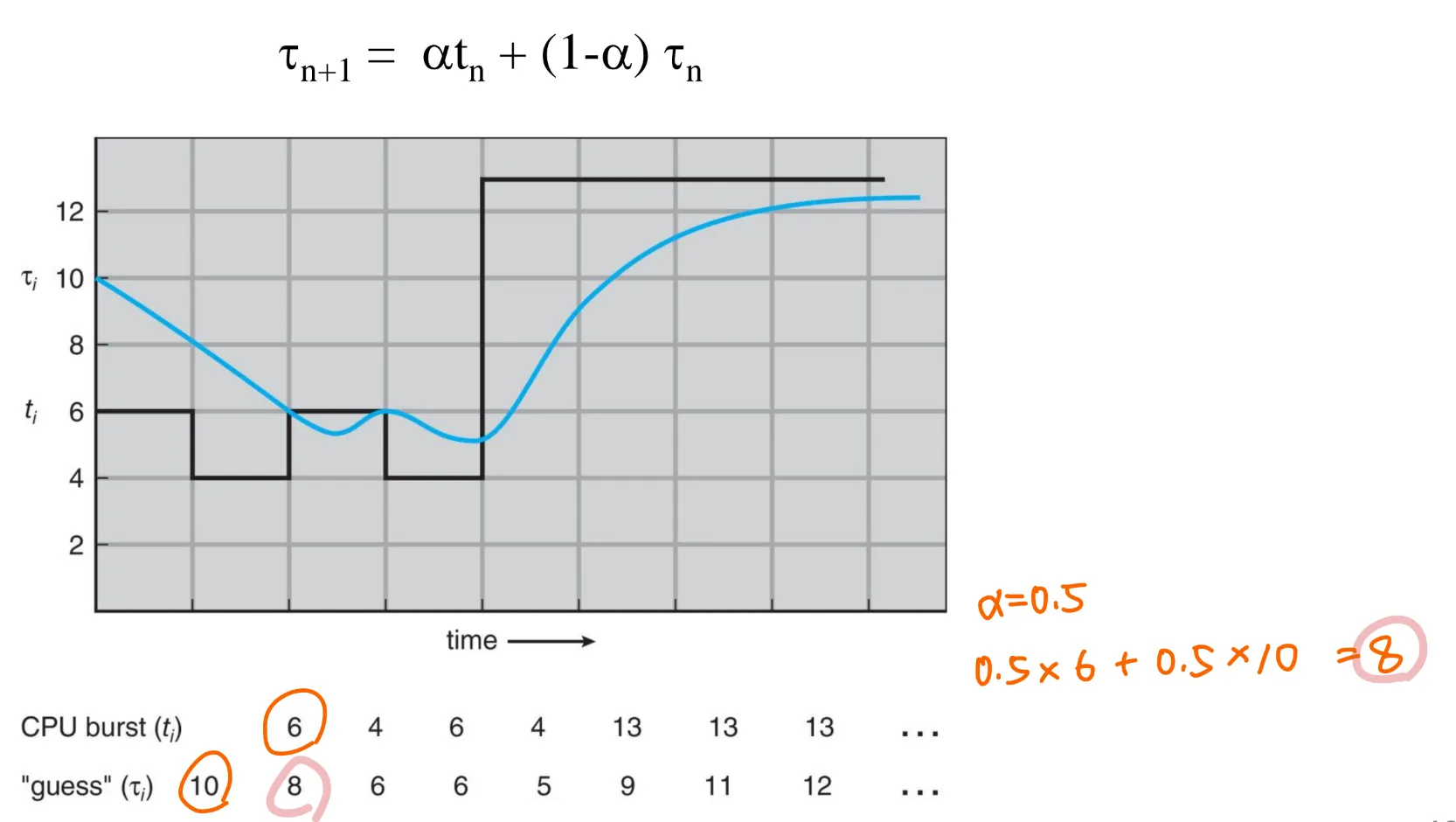
SJF - preemptive version

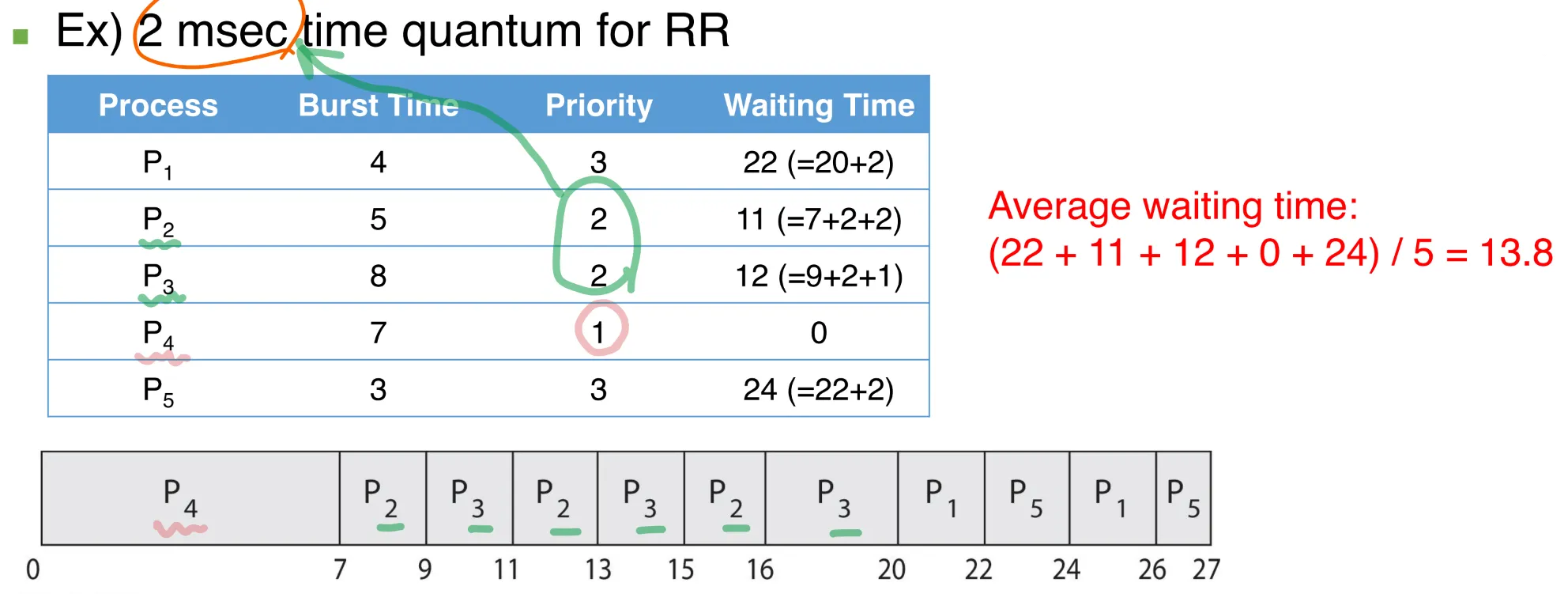
3. Round-Robin Scheduling
FCFS와 비슷하지만, Priprity는 preemptive 이다.
- 시간 공유 시스템으로 설계되었다
- CPU시간이 time quantum(or time slice)로 나눠진다
- ready queue는 circular queue로서 다뤄진다.
- CPU 스케줄러는 ready queue를 돌아다니며 CPU 시간을 최대 1 quantum까지 할당한다.
예) time quantum = 4일 때
RR스케줄링은 거의 time quantum의 크기에 달려있다.
- time quantum이 작을 때 : 프로세서 공유
- time quantum이 클 때 : FCFS
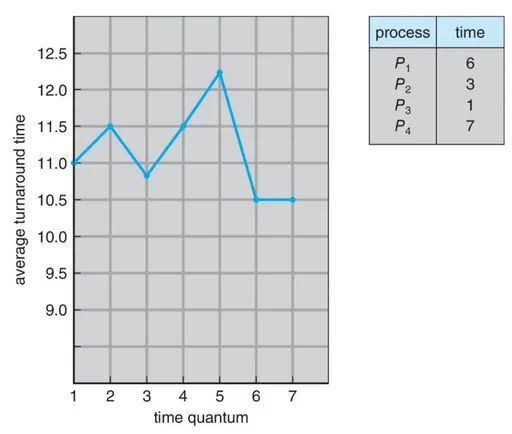
처리시간(turnaround time)은 거의 time quantum의 크기에 달려있다.
- 평균 처리시간은 time quantum의 크기에 비례하지도 반비례하지도 않는다
- 대부분의 프로세스가 한번의 time quantum 내에 CPU burst를 완료하면, 평균 처리시간이 향상된다
- 하지만 너무 긴 time quantum은 바람직하지 않다
- thumb 법칙 : CPU burst의 80%는 time quantum보다 짧아야한다
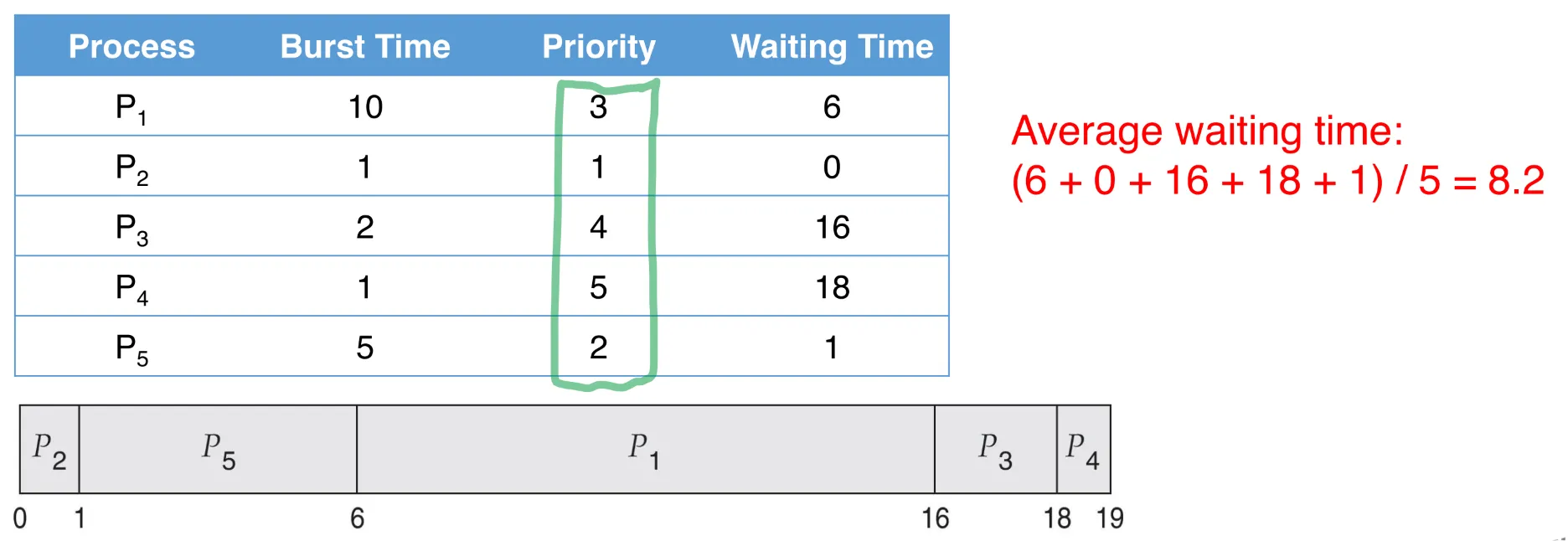
4. Priority scheduling
CPU는 최고 우선순위의 프로세스부터 할당받는다.
- 프로세스는 저마다의 우선순위를 갖고, 낮은 숫자일수록 높은 우선순위이다.
- 우선순위가 같다면 - FCFS 예)
내부 및 외부에서 우선순위를 할당할 수 있다.
- 내부 : 층정가능한 양 또는 품질로 결정 ex)시간 제한, 메모리 요구
- 외부 : 중요도, 정책적인 요인
Priority 스케줄링은 preemptive / non-preemptive 둘 다 될 수 있다.
문제점 : 우선순위가 낮은 프로세스의 무기한 차단(Indefinite blocking = starvation)
→ 해결 : aging (오랜 시간 대기하는 프로세스의 우선순위를 점진적으로 높임)
RR로 Priority 스케줄링 하기
- 우선순위가 같을 때, RR 사용
5. Multilevel queue scheduling
다른 그룹으로 프로세스를 분류하고 다른 스케줄링을 적용한다.
- 메모리 요구사항, 우선순위, 프로세스 타입에 따라..?
ready queue를 몇개의 분리된 queue로 분할한다
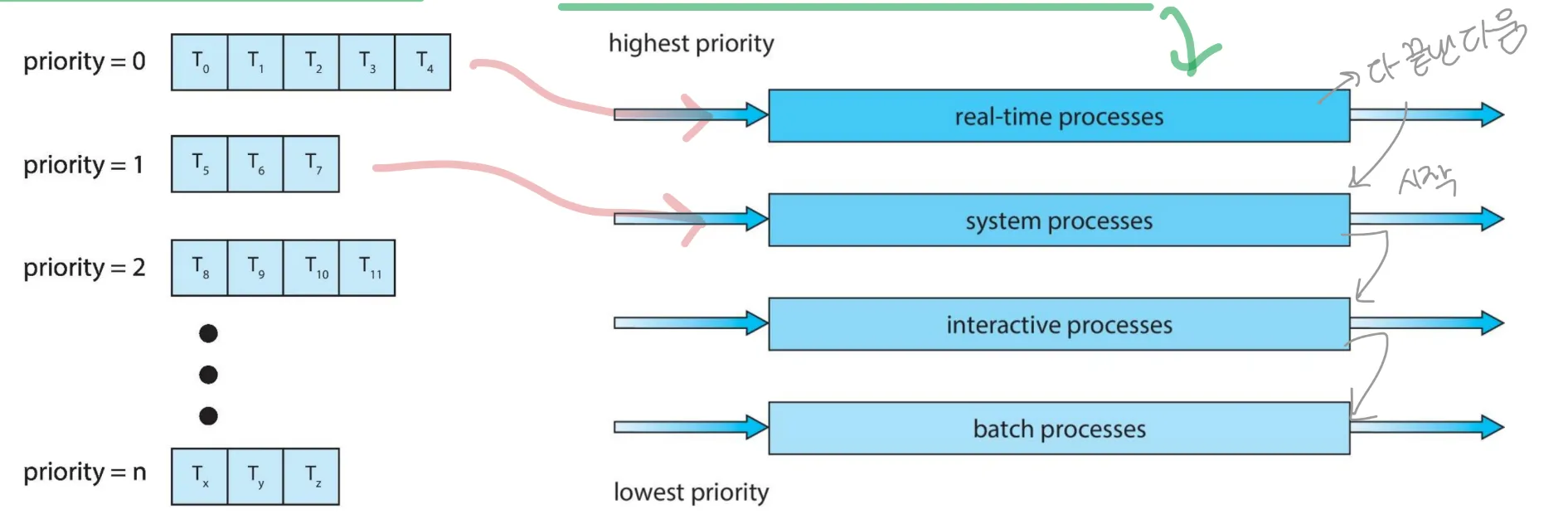
각 queue에는 고유한 스케줄링 알고리듬이 있다.
queue(대기열)간 스케줄링
- 고정된 priority preemptive 스케줄링
- 하위 priority queue의 프로세스는 상위 priority queue가 모두 비어있는 경우에만 실행할 수 있다
- queue 간의 Time-slice
- foreground queue (대화형 프로세스) : CPU 시간의 80%가 RR을 위한 것이다
- background queue (batch 프로세스) : CPU 시간의 20%가 FCFS을 위한 것이다
6. Multiple feedback-queue scheduling
multilevel queue 스케줄링이랑 비슷하지만, 프로세스가 queue들 사이에서 이동할 수 있다.
idea : CPU burst의 특징에 따라 프로세스를 분류한다.
- 만약 프로세스가 너무 많은 CPU 시간을 사용하면, 하위 priority queue로 그 프로세스를 옮긴다
- I/O bound, interactive 프로세스는 우선 순위가 높은 대기열(higher priority queue)에 있다
???????????????????
Thread Scheduling
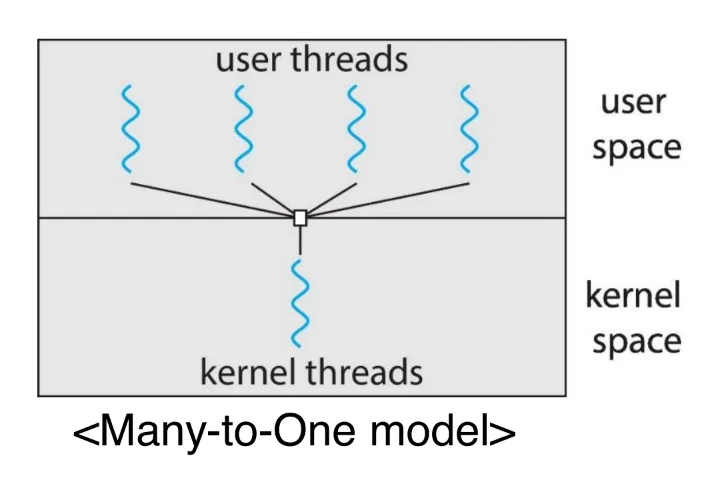
현대 대부분의 운영체제에서, 운영체제가 스케줄링하는 것은 프로세스가 아니라 kernel-level 스레드이다.
User-level 스레드는 스레드 라이브러리가 관리한다.
CPU를 실행하기 위해서는, user-level 스레드가 궁극적으로 관련된 kernel-level 스레드에 매핑되어야 한다.
- 이 매핑은 간접적일 수 있고, lightweight 프로세스(LWP)를 사용할 수 있다.
Contention Scope
Process-contention scope(PCS)
- user 스레드 간의 LWP 경쟁
- many-to-one 모델 or many-to-many 모델
- 우선순위 기준 (프로그래머가 설정한)
System-contention scope (SCS)
- kernel 스레드 간의 CPU 경쟁
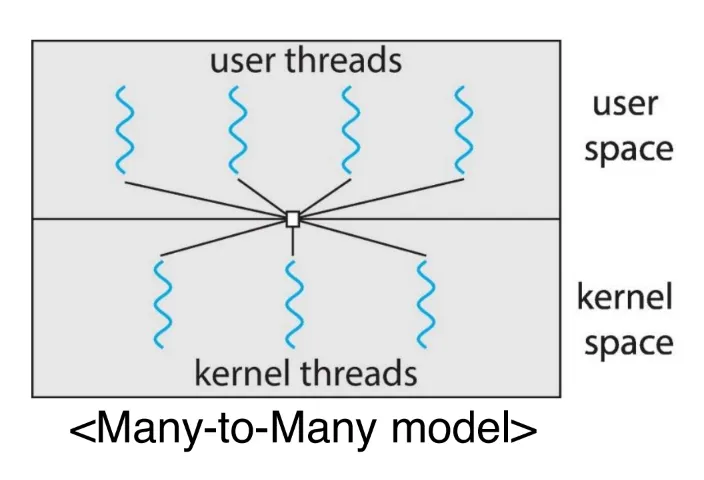
Scheduler Activation and LWP
LWP를 통한 user/kernel 스레드 사이의 연결
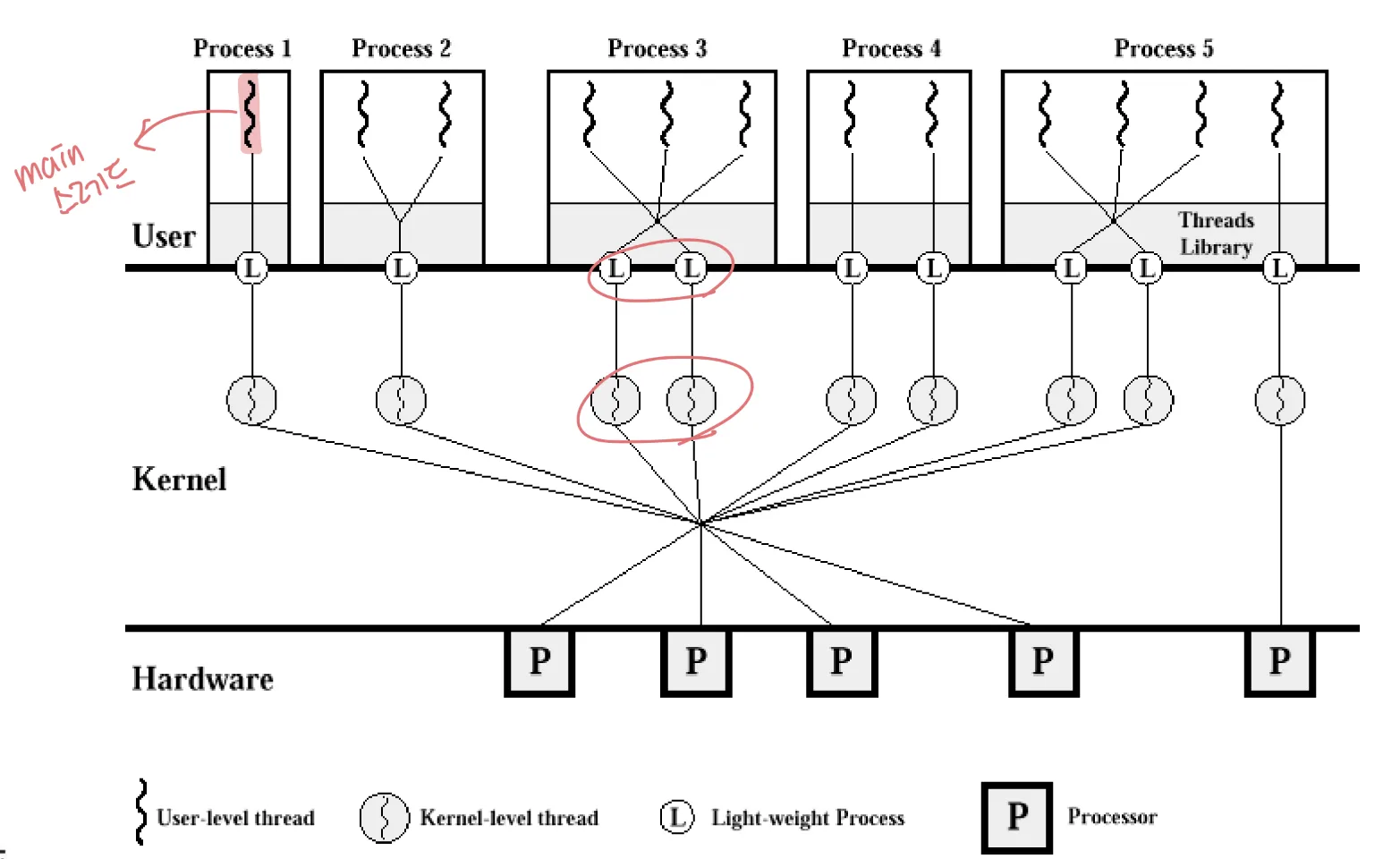
Pthread Scheduling
Pthread로 스레드를 생성할 때, 우리는 PCS 또는 SCS를 지정할 수 있다.
- PCS : PTHREAD_SCOPE_PROCESS
- many-to-one 에서는 PCS만 가능하다
- SCS : PTHREAD_SCOPE_SYSTEM
- one-to-one 에서는 SCS만 가능하다
- 참고 : 특정 시스템에서는, 특정 값만 허용된다
- 리눅스와 맥OS 시스템에서는 SCS만 허용된다
관련 기능
pthread_attr_setscope(pthread_attr_t *attr, int scope)pthread_attr_getscope(pthread_attr_t *attr, int *scope)
Multiple-Processor Scheduling
CPU 스케줄링은 multiple CPU일 때 더 복잡해진다.
multiple-processor 스케줄링에는 일반적인 최적의 해결책이 존재하지 않는다.
multiprocess는 다음 구조를 의미한다.
-
Multicore CPUs
-
Multithreaded cores
-
NUMA systems [*ch.1]![]
-
Heterogeneous multiprocessing
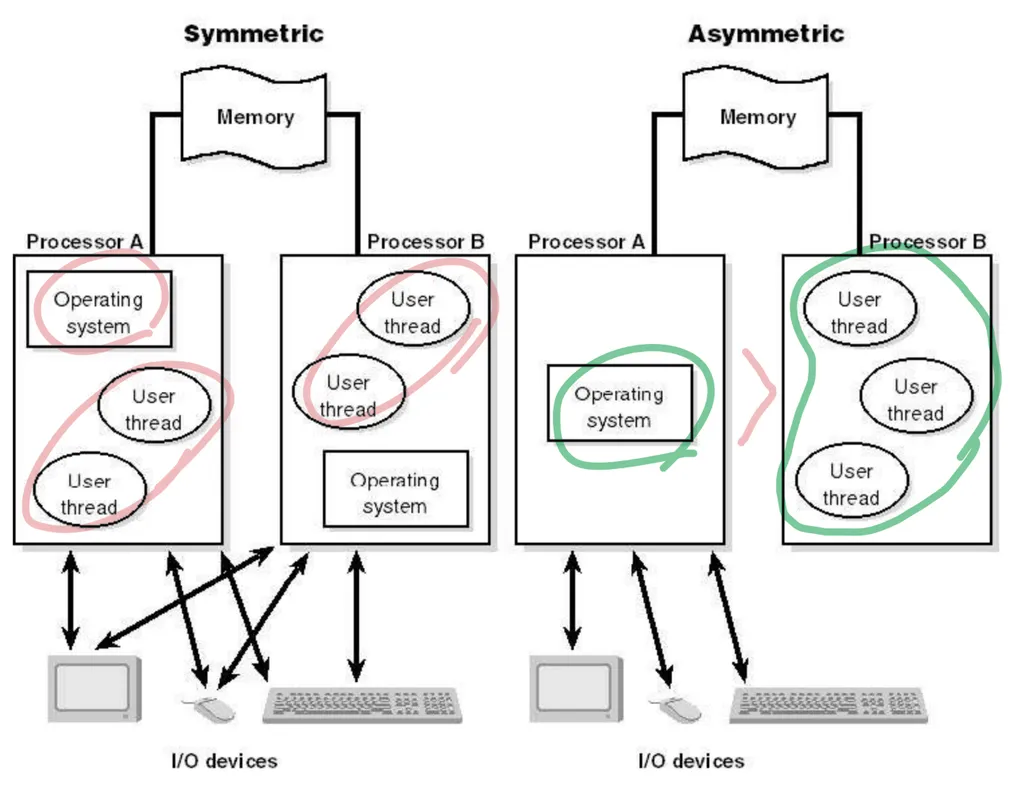
Asymmetric Multiprocessing 비대칭:
하나의 프로세서가 모든 스케줄링을 결정, I/O 처리 및 시스템 활동을 처리하는 것이다.
다른 프로세서는 user thread만 실행
Symmetric multiprocessing (SMP) 대칭 멀티프로세싱 :
각 프로세서는 자기 스스로 스케줄링한다.
각 스케줄러가 ready queue를 확인하고 실행할 스레드를 선택한다.
이후 스레드 스케줄링하려고 구조화할 때 다음 두 가지 방법으로 구조화한다.
1) 모든 스레드가 동일한 ready queue를 사용
2) 각각의 프로세서가 자신만의 개인 스레드 queue를 가진다.
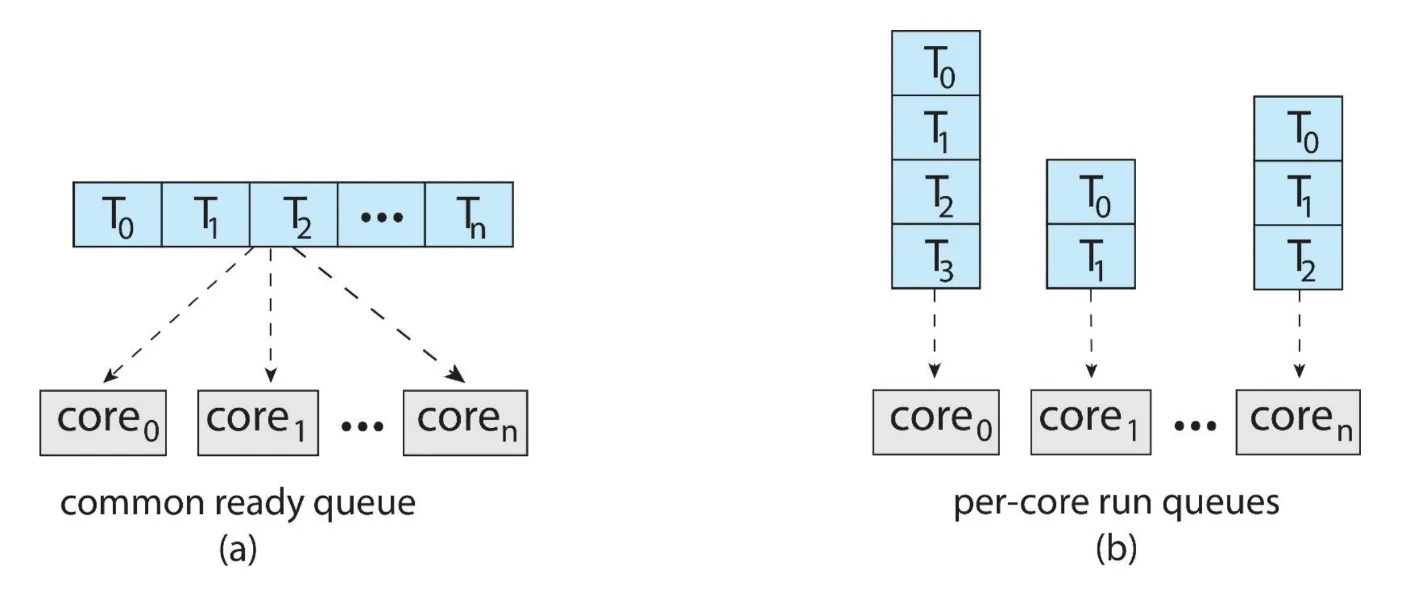
**figure 5.11** Organization of ready queues 사실상 모든 현대 OS가 SMP를 지원하므로 이후의 CPU 스케줄링 알고리즘은 전부 SMP 체제에서 발생하는 것들이다.
Multicore Processors
: 동일한 물리적 chip에 multicore processor cores
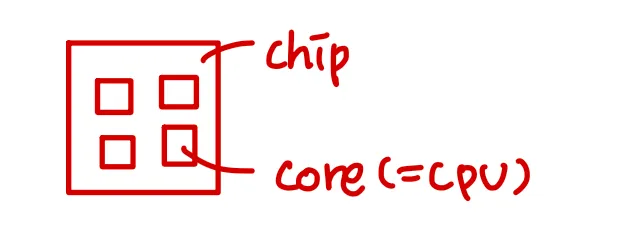
Multicore processor 구조
- 최근 트렌드 (더 빠르고 더 적은 전력을 소모하기 때문)
각 프로세스 시스템이 physical chip을 가지고 있는 것보다
스케줄링 이슈(multicore processor의)
다양한 이유로, 메모리에 접근할 때, 데이터를 이용할 수 있도록 기다리는 데 상당한 시간이 걸린다. ⇒ Memory stall (메모리 지연)
memory stall의 경우, 프로세스는 대기하는데 자기 시간의 50%를 사용하게 된다.
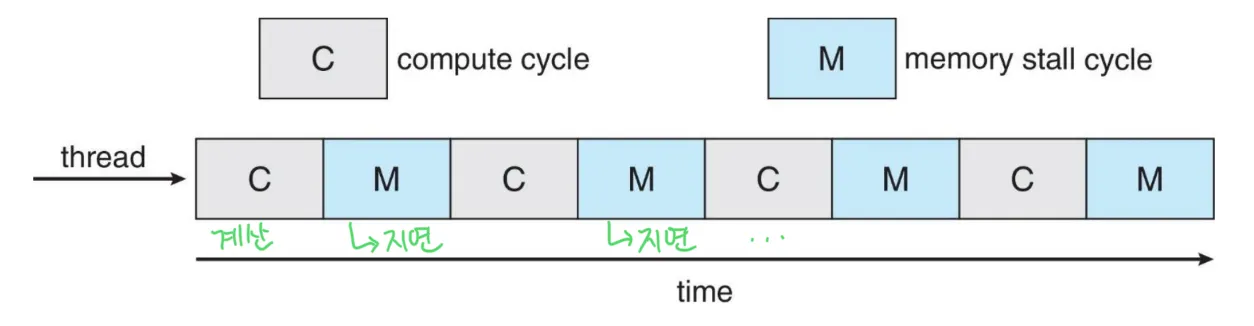
해결방법 : Multithreaded processor cores
Multithreaded Multicore System
: multi-core processor에서 발생하는 memory stall 문제를 해결하는 방법
-
두개 이상의 하드웨어 스레드가 각 코어에 할당된다.
-
한개의 스레드가 memory stall되면, 다른 스레드로 switch한다.
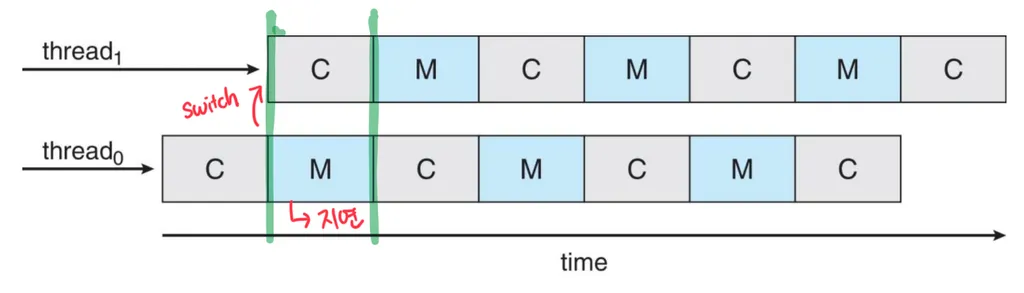
multithreaded processor cores
Chip-multithreading (CMT)
각 코어에 여러개의 하드웨어 스레드를 할당한다.
인텔은 하이퍼 스레딩 hyper threading(동시 멀티스레딩 simultaneous multithreading : SMT)이라는 용어로 여러 하드웨어 스레드를 한 프로세서 코어에 할당한다.
ex) 코어 당 2개의 하드웨어 스레드를 갖는 quad-core system가 있다.
OS의 입장에서는 논리CPU가 8개인 것이다.
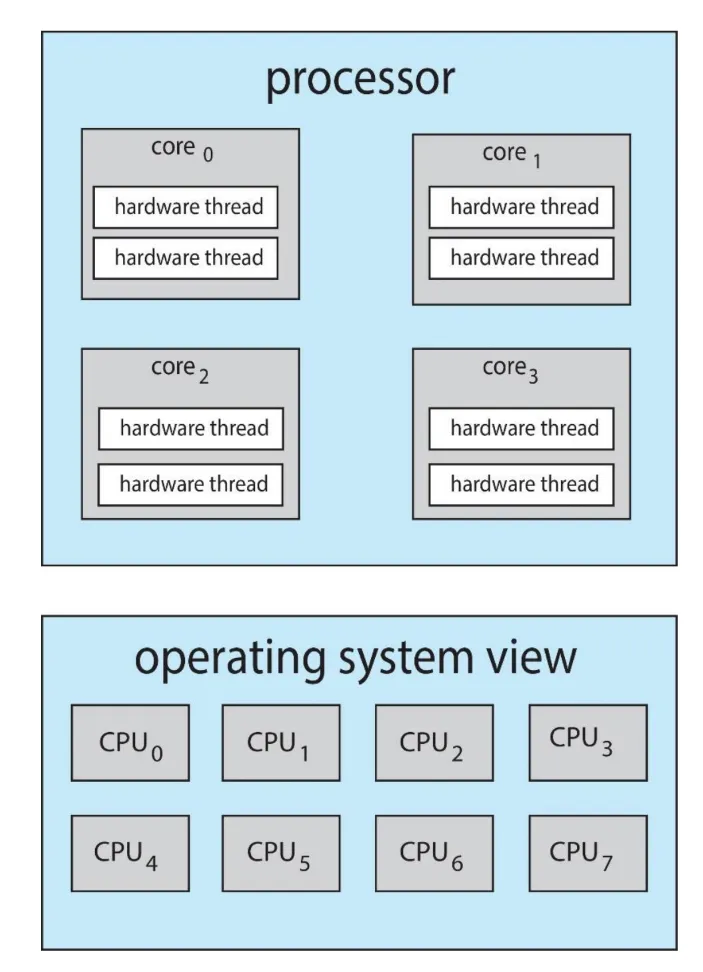
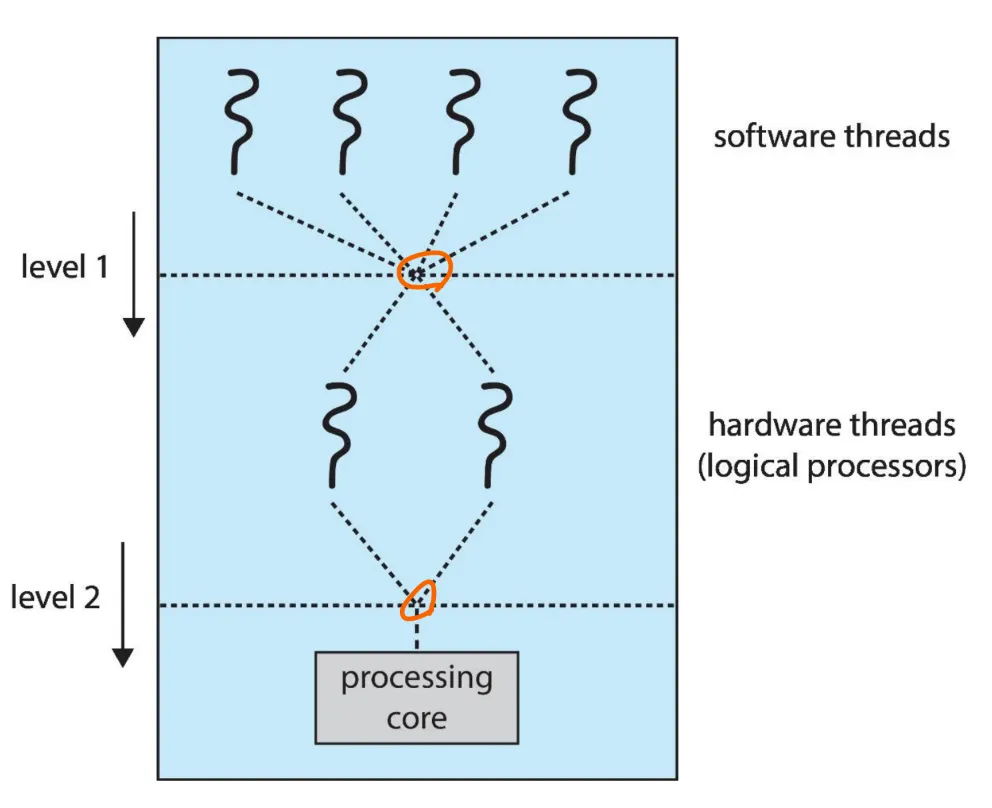
Two levels of scheduling
multithreaded multicore system에서는 두 레벨의 스케줄링이 필요하다.
Lv.1
: 논리 CPU에서 어떤 소프트웨어 스레드를 실행할지 OS가 결정하는 스케줄링
Lv.2
: 코어가 물리적 코어에서 어떤 하드웨어 스레드를 실행시킬지 결정하는 스케줄링
Load Balancing
: 모든 프로세서에 workload가 고르게(evenly) 분산되도록 시도한다.
-
각 프로세서에 own ready queue가 있는 시스템에 필요(대부분의 최신 OS에 해당)
일반적으로 크게 두 가지 방법이 있다.
-
Push migration
: 주기적인 작업은 각 프로세서의 load on(작업 부하)를 확인한다.
만약 불균형이 발견되면, 과부하된 CPU에서 다른 CPU로 스레드를 보낸다.
-
Pull migration
: 유휴(idle) 프로세서가 바쁜 프로세서에서 대기중인 작업을 가져온다.☝️push, pull 이동(migration)은 병렬적으로 구현가능하다.
→ 리눅스 CFS, ULE 스케줄러 (?)
Processor Affinity
한 프로세서에서 다른 프로세서로 프로세스를 이동할 때 생기는 overhead
-
캐시의 내용이 무효화되고 다시 채워져야 한다.
-
Processor affinity (프로세서 선호도)
: 오버헤드를 피하기위해 동일한 프로세서에서 프로세스가 실행되도록 유지하는 것
- Sort affinity : OS는 동일한 프로세서에서 프로세스를 계속 실행하려고 하지만 프로세스는 프로세서 간에 이동될 수 있다.
- Hard affinity : 프로세스가 다른 프로세서로 이동되는 것을 방지할 수 있다.
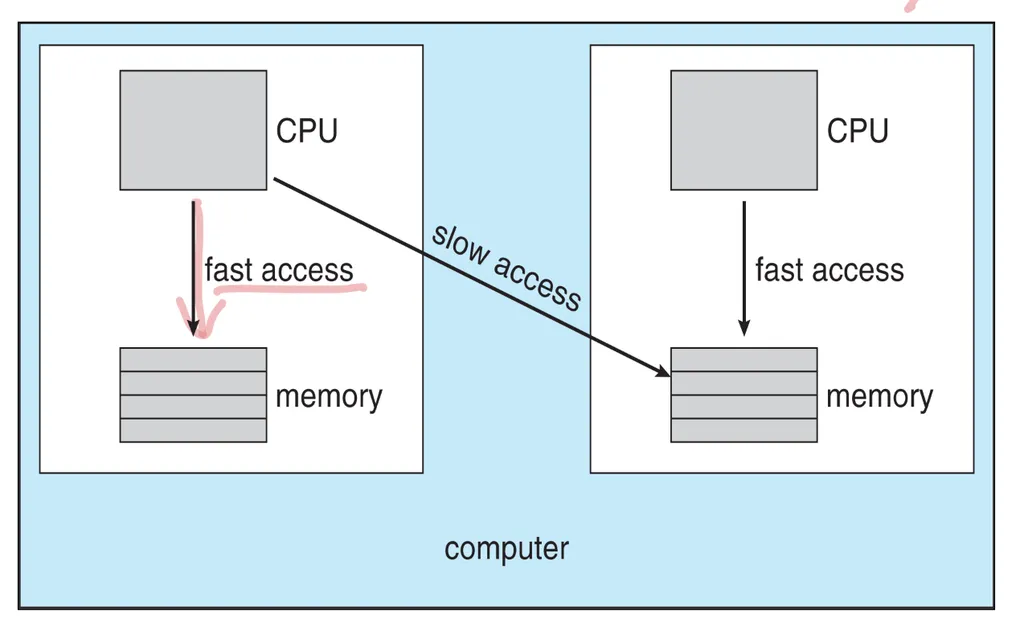
NUMA(non-Uniform Memory Access)와 CPU 스케줄링
- NUMA체제에서 CPU 간 상호연결해서 서로 같은 메모리 공간을 사용하더라도 당연히 남의 메모리보다는 자기 메모리 접근이 더 빠르다.
Real-Time CPU Scheduling
Real-time Operating Systems (RTOS)
- OS는 real-time system을 제공하도록 설계되었다
Soft real-time system
- 중요한 실시간 프로세스가 언제 예약될지에 대한 보장이 없다
- 프로세스가 중요하지 않은 프로세스보다 우선시되도록 보장한다
Hard real-time system
- 작업을 마감일까지 제공(serviced)되야한다
- 기한이 지난 후의 서비스는 서비스가 전혀 없는 것과 같다
Minimizing Latency
대부분의 실시간 시스템은 event-driven system이다.
- 이벤트가 발생하면 시스템은 가능한 한 신속하게 대응하고 서비스해야 한다
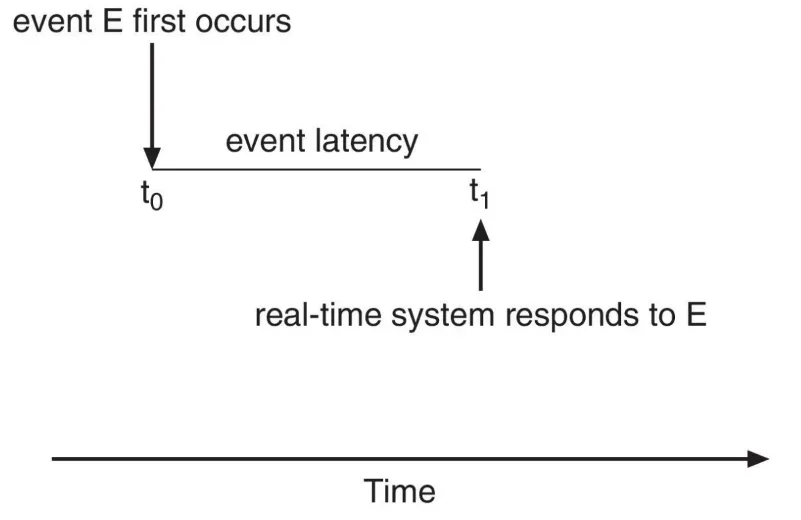
Event latency
: 이벤트가 발생한 후 서비스될 때까지 걸리는 시간
ex) interrupt latency, dispatch latency
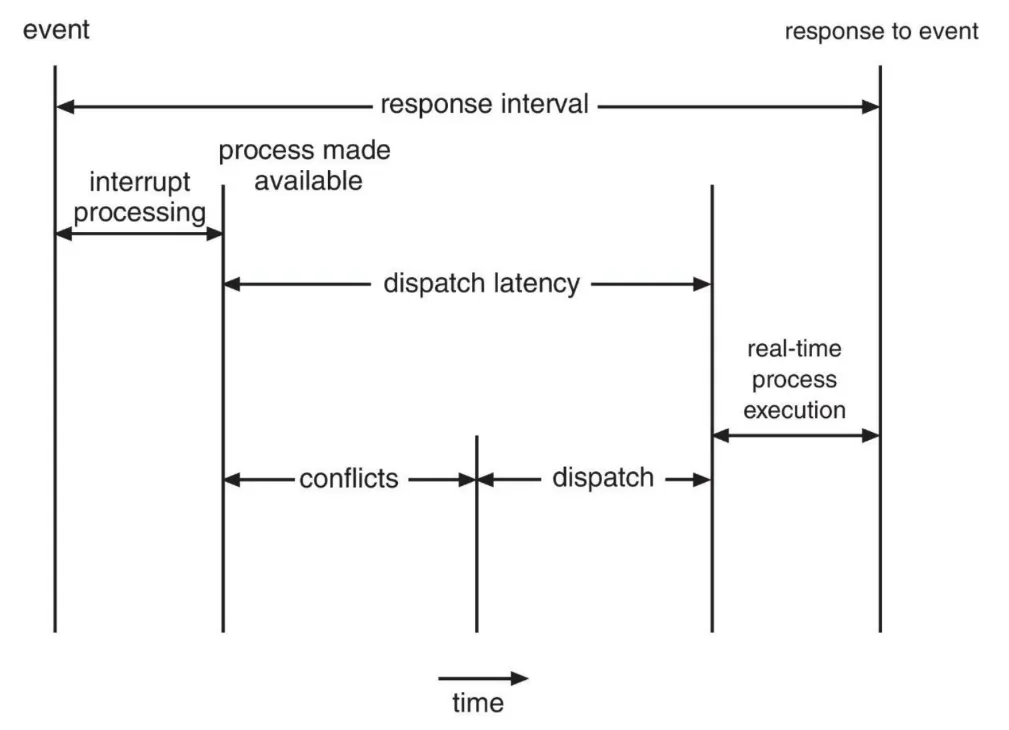
Interrupt Latency
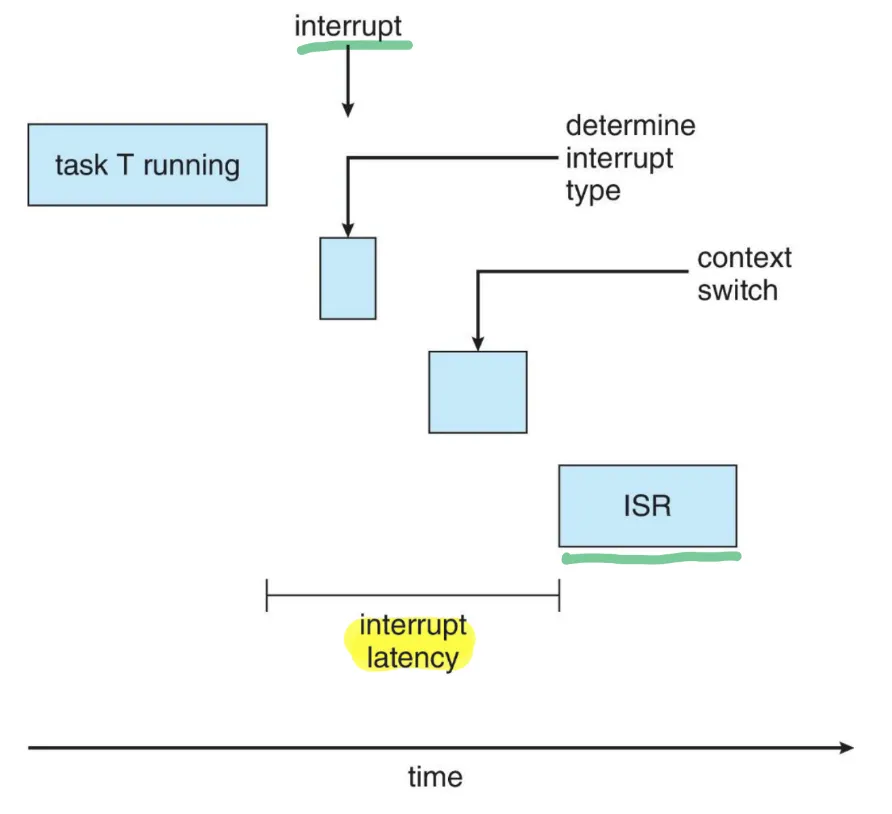
Interrupt latency
: CPU에서 인터럽트가 도착한 후 인터럽트를 서비스하는 루틴이 시작될 때까지 걸리는 시간
Dispatch Latency
Dispatch latency
: scheduling dispatcher가 한 프로세스를 중단하고 다른 프로세스를 시작하는데 필요한 시간
- Preemptive kernel은 dispatch latency를 적게 유지하는 가장 효과적인 방법
dispatch latency의 충돌 단계
- 커널 모드에서 실행중인 임의의 프로세스를 선점(preemptive)
- 우선순위가 높은 프로세스에 필요한 리소스를 우선순위 낮은 프로세스에서 가져오기
Priority-based Scheduling
RTOS에서 가장 중요한 기능은 real-time 프로세스에 즉각적으로 반응하는 것이다.
- 스케줄러는 우선순위 기반의 선점(Preemptive) 알고리듬을 지원해야한다.
- 대부분의 OS는 실시간 프로세스에 높은 우선순위를 부여한다
- preemptive, 우선순위 기반의 스케줄러는 오직 soft real-time 기능만 보장한다.
Hard real-time 시스템은 마감일 요구 사항에 따라 실시간 작업이 서비스될 수 있도록 보장해야 한다.
- 추가적인 스케줄링 기능을 요구한다
Periodic Process
Periodic 프로세스는 일정한 간격으로 CPU가 필요하다.
프로세싱 시간: t
deadline : d
period : p
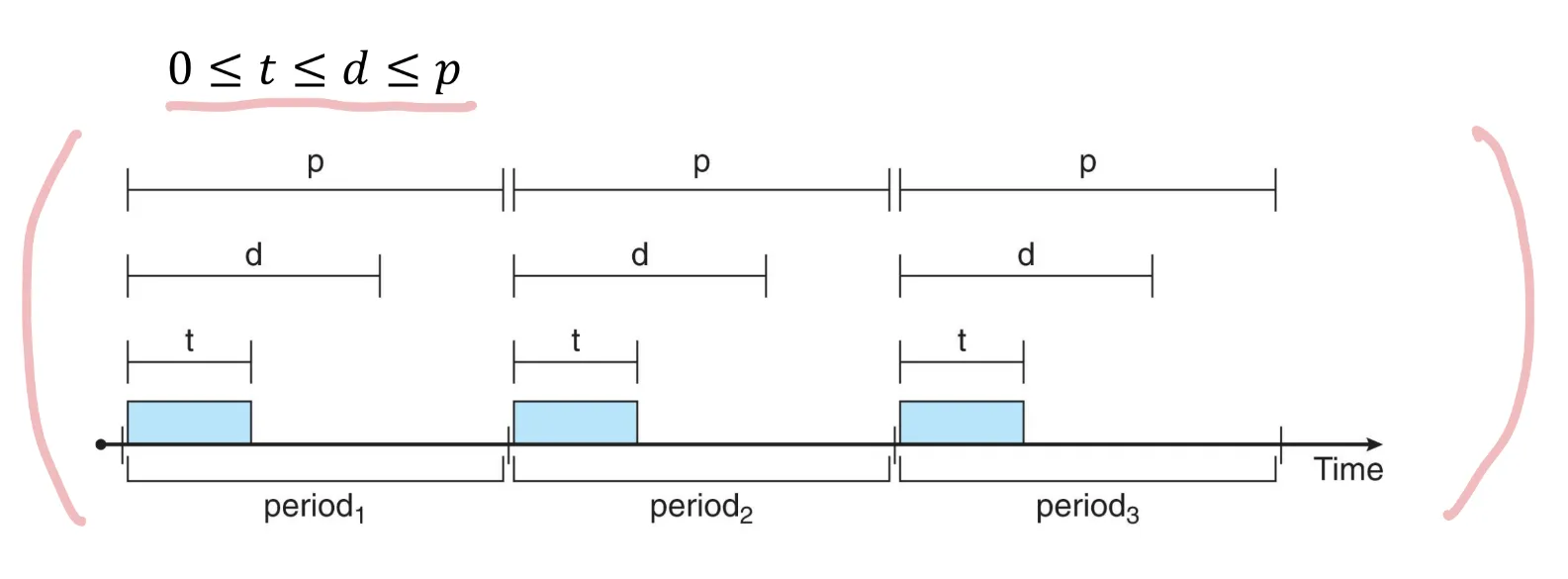
Scheduling with Deadline Requirement
프로세스는 스케줄러에게 deadline을 요청해야 할 수도 있다.
admission-control 알고리듬을 사용하여, 스케줄러는 다음 두가지 옵션 중 하나를 수행한다.
- Admits the process, 프로세스가 제 시간에 완료되도록 보장한다
- Regects the request, 보장할 수 없는 경우 거절
1. Rate-Monotonic Scheduling
static priority 정책(with preemption)을 사용해서 주기적인 작업을 스케줄링한다.
각 주기적 작업은 해당 주기에따라 역으로 우선 순위가 할당된다.
- 짧은 period → high priority
- 긴 period → lower priority
주기적인 프로세스의 프로세싱 시간은 각각의 CPU burst에 대해 동일하다고 가정한다
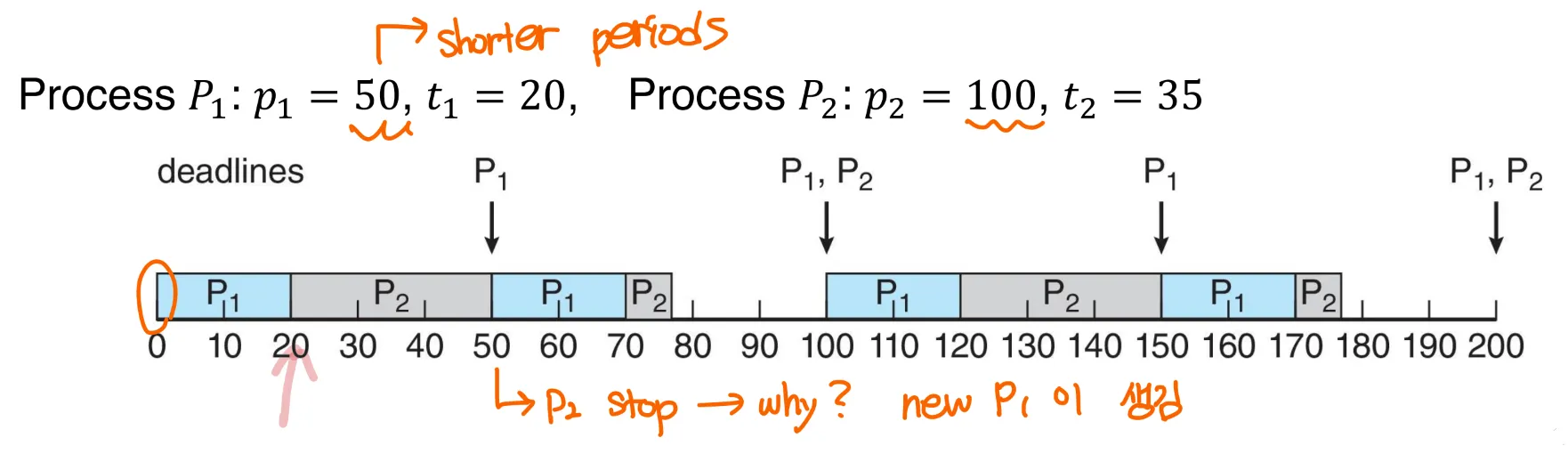
rate-monotonic scheduling은 optimal로 간주된다.
- 이 알고리즘으로 프로세스들을 스케줄링할 수 없는 경우, 다른 어떤 알고리즘으로도 static pirority를 할당하는 스케줄을 짤 수 없다
한계
- CPU 사용률은 제한적이며, CPU 리소스를 항상 최대화할 수 있는 것은 아니다
- 최악의 경우 CPU 사용률 : N:process 개수
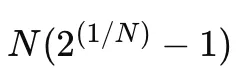

2. Earliest-Deadline-First Scheduling (EDF)
우선순위가 마감기한에 달려있다
- earlier deadline → higher priority
- later deadline → lower priority
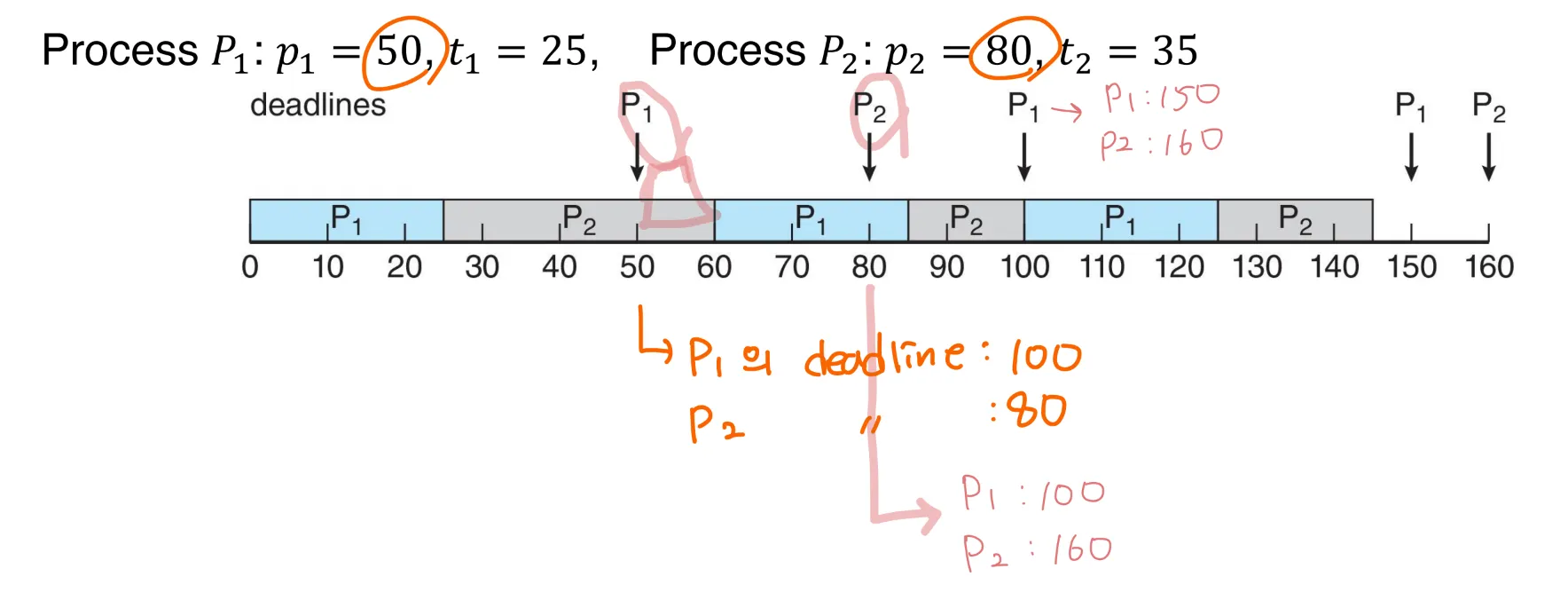
요구사항
- 프로세스가 주기적일 필요가 없으며, 프로세스가 burst 당 일정한 양의 CPU 시간을 필요로 하지 않는다.
- 프로세스를 실행할 수 있게 되면, 시스템에 기한 요구 사항을 공지해야 한다
이론적으로 optimal
- 이론적으로, 각 프로세스가 마감일을 맞추도록 스케줄링할 수 있으며, CPU 활용률은 100%가 된다.
Proportional Share Scheduling
모든 응용프로그램 간에 T 공유를 할당한다.
응용프로그램은 N개의 시간공유를 받을 수 있으므로, 응용 프로그램이 전체 프로세서 시간의 N/T를 갖도록 보장한다.
응용프로그램이 할당된 시간의 몫을 받을 수 있도록 승인 제어 정책과 함께 작동해야 한다.
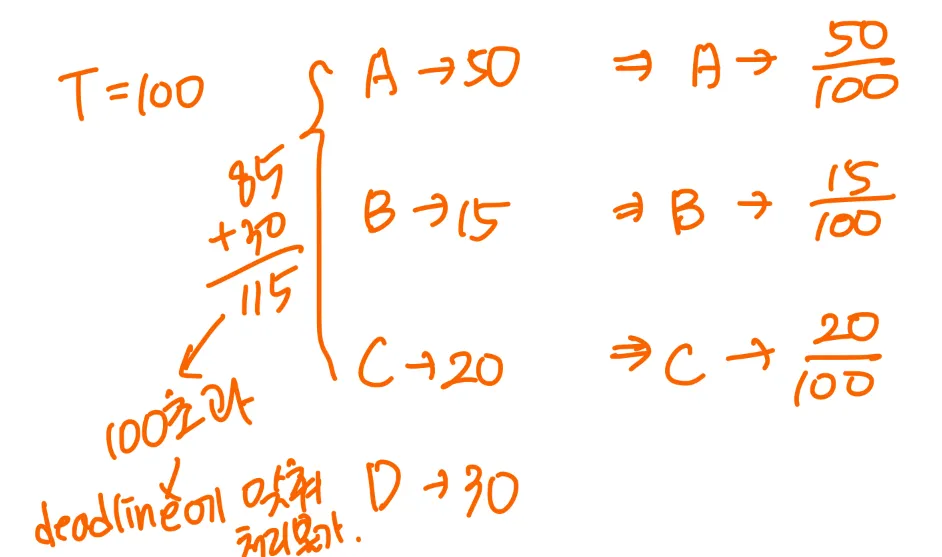
POSIX Real-Time Scheduling
- real-time thread를 위한 scheduling class
- SCHED_FIFO: FCFS policy
- 같은 우선순위의 스레드 사이에 time slicing 없음
- 가장 높은 우선순위의 real-time thread는 응앵,,,,, + 코드 있는데 뭔소릴까
- SCHED_FIFO: FCFS policy
Operating System Example
Linux Scheduler
역사
- 전통적인 UNIX scheduling 알고리즘 (ver. <2.5)
- O(1) scheduling 알고리즘 (ver. ≥2.5)
- O(1) complexity
- SMP 지원 증가
- interactive process를 위한 반응시간 부족
- completely Fair Scheduler (CFS) (ver. ≥ 2.6) 완전 공정 스케줄러
스케줄링 클래스에 기반함
- 각 클래스는 특정 우선순위가 배정된다.
- default scheduling class (CFS) → static priority 100~139
- real-time scheduling class(SCHED_FIFO, SCHED_RR) → static priority 0~99
- 필요하다면, 새로운 scheduling class가 추가될 수 있다
- default scheduling class (CFS) → static priority 100~139
- 시스템의 요구에 따라 다른 스케줄링 알고리듬을 허용한다. ex) server vs. mobile
- 스케줄러는 highest-priority class의 highest-priority task를 선택한다.
Linux CFS Scheduler
CFS 스케줄러는 CPU 처리 시간의 비율을 각 작업에 할당한다.
- portion은 *nice value로 계산된다 *nice value : [-20, 19]에서의 상대적 우선순위, default 값은 0 값이 높을수록 우선 순위가 낮음(’nice’ to other tasks)
- CPU 시간의 비율은 *targeted latency 값에서 할당된다. *targeted latency : 실행 가능한 모든 작업을 한 번 이상 실행해야 하는 시간 간격(interval)
시스템의 활성 작업 수가 특정 임계값 이상으로 증가하는 경우 증가할 수 있다
각 task가 시간을 기록한다.
- 작업당 변수 vruntime(가상 실행시간_virtual run time)
- normal priority task : vruntime
각 task의 vruntime은 decay facor과 관련있다.
- lower priority task → higher decay factor
- higher priority task → lower decay factor
- ⇒ 우선 순위가 높은 작업은 실행 시간이 더 적을 가능성이 높다
스케줄러는 vruntime값이 가장 적은 작업을 선택하기만 하면 된다.
높은 우선순위의 작업은 우선순위가 낮은 작업을 선점(preempt)할 수 있다.
I/O bound task : 짧은 기간동안 실행 → vruntime 짧아짐
CPU bound task : 실행할 수 있을 때마다 함 → vruntime 더 길어짐
⇒ I/O bound task가 더 높은 우선순위를 부여함 (CPU bound task 보다)
(출처)
Operating System Concepts 도서
https://www.booksfree.org/operating-system-concepts-10th-edition-by-abraham-silberschatz-peter-b-galvin-greg-gagne-pdf/
