
본 글은 인프런 김영한님의 JPA 로드맵을 기반으로 정리했습니다.
1. 도메인 모델
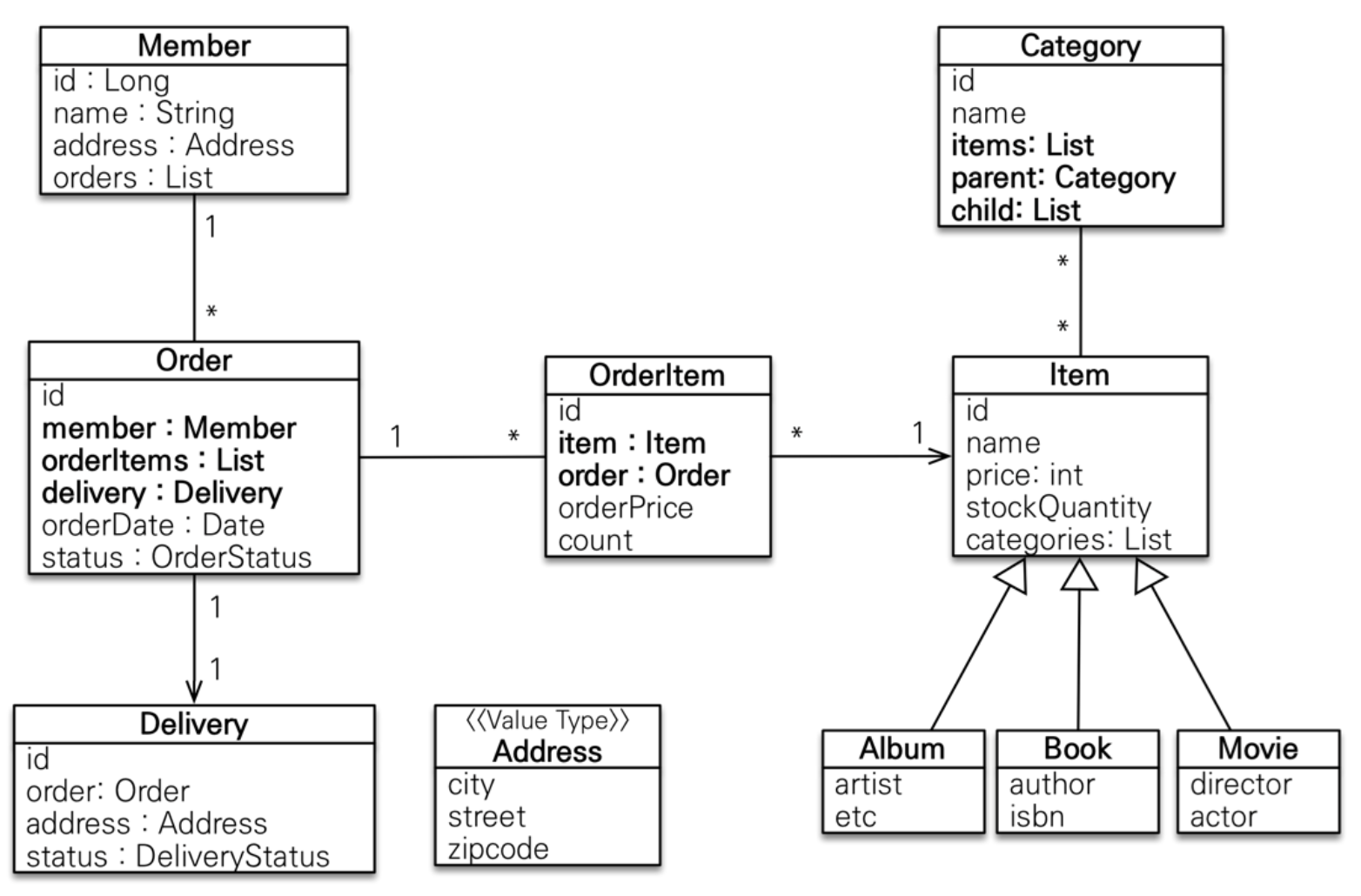
이 도메인 모델을 통해 JPA를 통해 API를 어떻게 설계하고 연관된 엔티티를 어떻게 조회하는 것이 바람직한지 살펴볼 것이다.
Category, Album, Movie 엔티티는 예제에 등장하지 않기 때문에 제외했다. 사용할 엔티티는 Member, Order, Delivery, OrderItem, Item, Book 이다. Address는 임베디드 타입이다.
코드는 다음과 같다. 연관관계에 집중할 수 있도록 비즈니스 메서드, 생성자를 포함한 모든 메서드들을 제거했다.
-
Member (회원)
@Entity @Getter @Setter public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String name; @Embedded private Address address; @OneToMany(mappedBy = "member") private List<Order> orders = new ArrayList<>(); }- 회원은 주문과 일대다 관계를 가진다.
-
Order (주문)
@Entity @Table(name = "orders") @Getter @Setter public class Order { @Id @GeneratedValue @Column(name = "order_id") private Long id; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "member_id") private Member member; @OneToMany(mappedBy = "order", cascade = CascadeType.ALL) private List<OrderItem> orderItems = new ArrayList<>(); @OneToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL) @JoinColumn(name = "delivery_id") private Delivery delivery; private LocalDateTime orderDate; @Enumerated(EnumType.STRING) private OrderStatus status; }-
주문은 회원과 다대일 관계를 가진다.
-
주문은 주문물품과 일대다 관계를 가진다.
-
주문은 배송과 일대일 관계를 가진다.
-
-
Delivery (배송)
@Entity @Getter @Setter public class Delivery { @Id @GeneratedValue @Column(name = "delivery_id") private Long id; @OneToOne(mappedBy = "delivery", fetch = FetchType.LAZY) private Order order; @Embedded private Address address; @Enumerated(EnumType.STRING) private DeliveryStatus status; }- 배송은 주문과 일대일 관계를 가진다.
-
Address (주소)
@Embeddable @Getter public class Address { private String city; private String street; private String zipcode; }- 엔티티가 아닌 임베디드 타입이다. 회원과 배송에 포함된다.
-
OrderItem (주문물품)
@Entity @Getter @Setter @NoArgsConstructor(access = AccessLevel.PROTECTED) public class OrderItem { @Id @GeneratedValue @Column(name = "order_item_id") private Long id; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "item_id") private Item item; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "order_id") private Order order; private int orderPrice; private int count; }-
주문물품은 물품과 다대일 관계를 가진다.
-
주문물품은 주문과 다대일 관계를 가진다.
-
-
Item (물품)
@Entity @Inheritance(strategy = SINGLE_TABLE) @DiscriminatorColumn(name = "dtype") @Getter @Setter public abstract class Item { @Id @GeneratedValue @Column(name = "item_id") private Long id; private String name; private int price; private int stockQuantity; @ManyToMany(mappedBy = "items") private List<Category> categories = new ArrayList<>(); }- 물품은 이 예제에서 사용할 엔티티와는 연관관계를 가지지 않는다.
-
Book (책)
@Entity @DiscriminatorValue("B") @Getter @Setter public class Book extends Item { private String author; private String isbn; }- 물품의 구체 하위 엔티티로써 예제 데이터로 사용된다.
2. 예제 데이터 준비
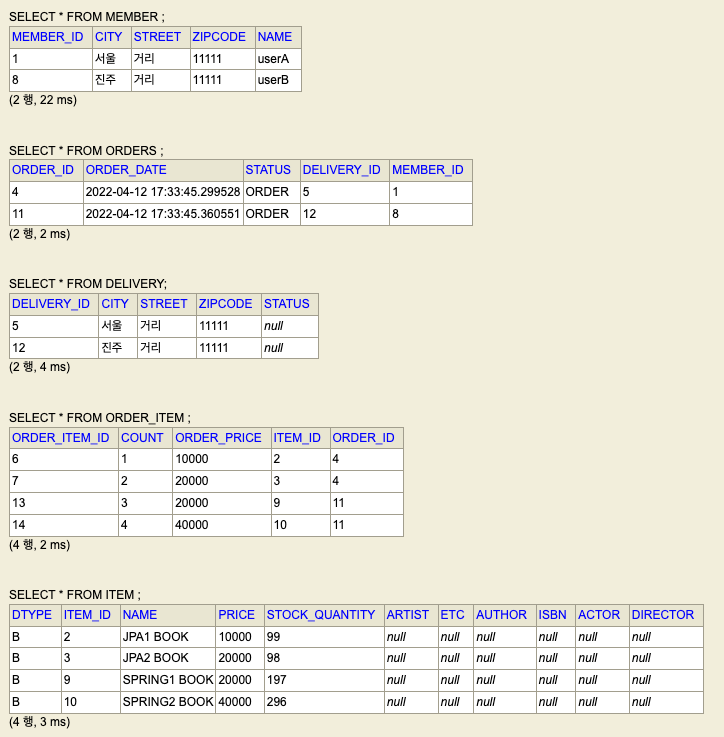
사용할 예제 데이터를 준비했다. 요약하자면 다음과 같은 연관관계다.
/**
* member 1번(userA)
* * order 4번 <-> delivery 5번
* * order_item 6번 <-> item 2번(JPA1 BOOK)
* * order_item 7번 <-> item 3번(JPA2 BOOK)
* member 8번(userB)
* * order 11번 <-> delivery 12번
* * order_item 13번 <-> item 9번(SPRING1 BOOK)
* * order_item 14번 <-> item 10번(SPRING2 BOOK)
*/-
회원은 일대다 관계를 맺는 주문을 1개씩 가지고 있다.
-
두 주문 모두 일대일 관계를 맺는 배송을 1개씩 가지고 있다.
-
두 주문 모두 일대다 관계를 맺는 주문물품을 2개씩 가지고있다.
-
주문물품 각각은 다대일 관계를 가지는 물품과 1개씩 연관된다.
3. API 설계 기본 원칙
API를 설계할 때 지겨야할 2가지 아주 중요한 원칙이 있다.
3.1 사용자 입력을 엔티티가 아닌 DTO로 받아라
// BAD
@PostMapping("/api/v1/members")
public CreateMemberResponse saveMemberV1(@RequestBody @Valid Member member) {
Long id = memberService.join(member);
return new CreateMemberResponse(id);
}위의 코드처럼 사용자의 입력값을 엔티티로 그대로 받으면 다음과 같은 문제가 생긴다.
-
엔티티에
@NotEmpty와 같은 API 검증 요구사항이 들어가서 유지보수가 힘들어진다. -
엔티티는 여러 API에서 참조되는데, 한 엔티티에 여러 API를 위한 모든 요구사항을 담기 어렵다.
-
엔티티가 변경되면 API 스펙이 변한다.
API 요청 스펙에 맞는 별도의 DTO를 만들어서 사용자 입력을 바인딩 받는것이 좋다.
// GOOD
@PostMapping("/api/v2/members")
public CreateMemberResponse saveMemberV2(@RequestBody @Valid CreateMemberRequest request) {
Member member = new Member();
member.setName(request.getName());
Long id = memberService.join(member);
return new CreateMemberResponse(id);
}3.2 응답을 엔티티가 아닌 DTO로 반환하라
// BAD
@GetMapping("/api/v1/members")
public List<Member> membersV1() {
return memberService.findMembers();
}위의 코드처럼 엔티티를 직접 응답값으로 사용하면 다음과 같은 문제가 생긴다.
-
기본적으로 엔티티의 모든 값이 노출된다. API에서는 스펙에 맞는 값만 응답하는 것이 좋다.
-
응답 스펙을 맞추려면
@JsonIgnore와 같은 View 로직이 엔티티에 들어와야한다. -
엔티티는 여러 API에서 참조되는데, 한 엔티티에서 여러 API를 위한 View 로직을 담기는 어렵다.
-
엔티티가 변경되면 API 스펙이 변한다.
-
컬렉션의 경우 직접 반환하면 API 스펙을 변경하기 어려워진다. 컬렉션은 별도의 클래스로 감싸서 응답하는것이 좋다.
// GOOD
@GetMapping("/api/v2/members")
public Result membersV2() {
List<Member> findMembers = memberService.findMembers();
List<MemberDto> result = findMembers.stream()
.map(m -> new MemberDto(m.getName()))
.collect(Collectors.toList());
return new Result(result);
}Member 엔티티 대신 API 스펙에 맞춘 MemberDto를 반환한다. 또한 리스트를 직접 반환하지 않고 래퍼 클래스로 한 번 감싸서 반환했다. 리스트의 경우 별도의 클래스로 한 번 감싸주면 API 스펙 변경과 페이징이 용이해지는 등 장점이 많다.
두 원칙은 한 마디로 정리해서 엔티티를 외부에 노출하지 말라는 것이다. 사용자 입력을 바인딩 받을때와 응답값을 반환할 때 모두 엔티티 대신 별도의 DTO를 사용하자.
4. x대일 연관관계 성능 최적화 (페치 조인)
엔티티 대신 DTO를 응답값으로 사용하라는 대원칙을 알아봤으니 이제 지연 로딩으로 설정된 x대일 연관관계를 조회하는 방법을 살펴보자.
참고로 x대일 연관관계는 즉시 로딩으로 설정하면 항상 테이블에서 조인이 일어나서 성능 튜닝이 어려워지기 때문에 지연 로딩으로 설정하는 것이 좋다. 기본값이 즉시 로딩이기 때문에 직접 지연 로딩으로 수정해줘야한다. 위의 엔티티 코드를 보면 모든 x대일 관계를 지연 로딩으로 설정해두었다.
4.1 N+1 문제
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
return orders.stream()
.map(SimpleOrderDto::new)
.collect(Collectors.toList());
}Order 엔티티를 직접 반환하지 않고 SimpleOrderDto로 변환해서 응답했다.
findAllByString()은 주문 2개를 반환한다.
@Data
class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName(); // 프록시 초기화
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress(); // 프록시 초기화
}
}엔티티를 DTO로 변환하는 과정에서 다음과 같은 순서로 N+1 문제가 발생한다.
-
쿼리 1번 (Order 2개 조회)
-
Member 프록시 2개를 초기화하기 위해 2번의 추가 조회
-
Delivery 프록시 2개를 초기화하기 위해 2번의 추가 조회
Order 입장에서 x대일 관계인 Member, Delivery 는 지연로딩으로 인해 프록시로 조회된다. 문제는 API 스펙에서 Member, Delivery 프록시 초기화가 일어나면서 조회된 Order 만큼 추가 쿼리가 발생한다는 것이다. 이것이 바로 N+1 문제며 조회된 데이터가 많을수록 성능에 치명적이다. 이 경우 총 5번(1 + 2 + 2)의 쿼리가 실행됐다.
4.2 N+1 문제 해결 with 페치 조인
@GetMapping("/api/v3/simple-orders")
public List<SimpleOrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithMemberDelivery();
return orders.stream()
.map(SimpleOrderDto::new)
.collect(Collectors.toList());
}public List<Order> findAllWithMemberDelivery() {
return em.createQuery(
"select o from Order o " +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class)
.getResultList();
}Order 조회시 Member와 Delivery도 함께 페치 조인했다.
페치 조인은 엔티티에 설정한 글로벌 로딩전략을 무시하고 연관된 엔티티를 즉시 로딩한다. 즉시 로딩하기 때문에 프록시가 아닌 실제 엔티티를 조회한다. 프록시가 아니기 때문에 DTO 변환과정에서 프록시를 초기화하면서 발생하는 N+1 문제 또한 발생하지 않는다. 페치 조인을 통해 5번의 쿼리를 1번의 쿼리로 최적화한 것이다.
4.3 DTO 직접 조회
먼저 말하자면 대부분의 경우 x대일 조회 성능은 페치 조인을 통해 최적화한다. 이 방법은 주로 특정한 화면에 딱 맞는 API를 제공해야할 때 사용하는 특수한 방법이다. 데이터베이스에서 조회한 엔티티를 즉시 DTO로 매핑한다.
코드를 통해 살펴보자.
@GetMapping("/api/v4/simple-orders")
public List<OrderSimpleQueryDto> ordersV4() {
return orderSimpleQueryRepository.findOrderDtos();
}public List<OrderSimpleQueryDto> findOrderDtos() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.simplequery.OrderSimpleQueryDto(o.id, m.name, o.orderDate, o.status, d.address)" +
" from Order o " +
" join o.member m" +
" join o.delivery d", OrderSimpleQueryDto.class
).getResultList();
}조회한 데이터를 DTO로 즉시 매핑하기 위해서는 DTO 클래스에 데이터의 타입과 순서가 일치하는 생성자를 만들어야하고 클래스의 패키지명까지 적어줘야되서 약간 번거롭다.
페치 조인이 아닌 일반 조인을 사용한 것에 주목하자. 페치 조인의 경우 연관된 엔티티의 모든 데이터를 조회(SELECT) 하기 때문에 네트워크 전송량이 상대적으로 많아진다. 이 방법은 즉시 DTO로 매핑하기 때문에 필요한 데이터만 선택적으로 조회할 수 있다. 그러나 사실 현대에는 네트워크 대역폭이 넉넉하기 때문에 성능 향상은 생각보다 미비할 수 있다.
@Data
public class OrderSimpleQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public OrderSimpleQueryDto(Long orderId, String name, LocalDateTime orderDate,
OrderStatus orderStatus, Address address) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
}
}데이터베이스의 데이터를 즉시 매핑받는 DTO다. 데이터를 매핑할 수 있도록 생성자를 만들어야한다.
이 방법의 장단점을 정리해보자.
장점
- 딱 필요한 데이터만 조회하기 때문에 성능이 향상된다(미비)
단점
-
쿼리의 재사용성이 떨어진다.
-
API 스펙이 데이터 접근 계층에 들어가버린다.
사용자에게 응답하는 DTO는 사실 API 스펙이기 때문에 데이터를 직접 DTO로 매핑하면 쿼리의 재사용성이 떨어짐은 물론이고 물리적으로 데이터 접근 계층을 나뉘어져 있지만 논리적으로는 데이터 접근 계층이 프레젠테이션 계층에 의존하는 나쁜 상황이 발생한다. 딱 필요한 데이터만 조회(SELECT)해서 얻을 수 있는 성능 향상도 네트워크 대역폭이 넉넉한 요즘에는 큰 효과를 보는 경우는 드물다.
하지만 데이터를 바로 DTO로 매핑해야하는 상황이 충분히 생길 수 있다. 그런 경우에는 일반적인 조회 로직이 있는 범용성 있는 리포지토리와 별개로 특수한 조회 로직이 있는 별도의 리포지토리를 만드는 것을 추천한다. 일반적으로 사용하는 리포지토리와 특수한 경우에 사용하는 리포지토리를 분리해야 유지보수하기 쉬워진다.
정리하자면 쿼리 방식을 선택하는 권장 순서는 아래와 같다.
-
엔티티를 DTO로 변환 (필수)
-
x대일 관계를 페치 조인을 통해 성능 최적화 (대부분의 문제 해결)
-
DTO로 조회하는 방법 사용
-
그래도 안되면, JPA의 네이티브 SQL/SpringJdbcTemplate 등을 이용한 SQL 직접 사용
5. 일대다 연관관계 성능 최적화 (배치 사이즈)
x대일 관계를 최적화 하는 방법을 알아보았으니 이제 일대다 관계를 최적화해보자. Order 기준으로 일대다 관계를 가지는 OrderItem을 조회할 것이다.
5.1 N+1 문제
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
return orders.stream()
.map(OrderDto::new)
.collect(toList());
}findAllByString()은 주문 2개를 반환한다.
@Getter
class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems;
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
orderItems = order.getOrderItems().stream()
.map(OrderItemDto::new)
.collect(toList());
}
}Order 엔티티를 직접 반환하지 않고 OrderDto로 변환해서 응답했다.
@Getter
class OrderItemDto {
private String itemName; // 상품명
private int orderPrice; // 주문 가격
private int count; // 주문 수량
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}Order와 일대다 관계를 가지는 OrderItem도 DTO로 변환해서 응답해야한다. OrderItemDto는 OrderItem과 다대일 관계를 가지는 Item의 데이터도 포함한다.
엔티티를 DTO로 변환하는 과정에서 다음과 같은 순서로 N+1 문제가 발생한다.
-
쿼리 1번 (Order 2개 조회)
-
Member 프록시 2개를 초기화하기 위해 2번의 추가 조회
-
Delivery 프록시 2개를 초기화하기 위해 2번의 추가 조회
-
OrderItem 프록시 컬렉션 2개를 초기화하기 위해 2번의 추가 조회 (OrderItem 4개 조회)
-
Item 프록시 4개를 초기화하기 위해 4번의 추가 조회
총 11번의(1 + 2 + 2 + 2 + 4) 쿼리가 나간다. N+1 문제가 연쇄적으로 터지면서 생각했던 것보다 훨씬 많이 쿼리가 나간다.
5.2 페치 조인 + DISTINCT
일대다 관계의 컬렉션도 페치 조인을 통해 즉시 로딩 할 수 있다. 단, 일대다 관계의 테이블을 조인하면 데이터가 중복되기 때문에 DISTINCT 키워드를 통해 중복을 제거한다. 데이터베이스의 DISTINCT는 모든 컬럼이 같을 때만 중복을 제거하지만, JPQL의 DISTINCT는 엔티티 기준(PK 기준)으로 중복을 추가적으로 제거해준다.
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithItem();
return orders.stream()
.map(OrderDto::new)
.collect(toList());
}public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class
).getResultList();
}위처럼 x대일, 일대다 상관없이 페치조인해서 가져오면 1번의 쿼리만 실행된다. 그러나, 컬렉션을 페치 조인하는 방법은 다음과 같은 한계가 있다.
-
컬렉션을 페치 조인하면 페이징이 불가능하다
위에서 언급한것처럼 일대다 테이블을 조인하면 데이터가 늘어난다. DISTINCT를 통해 엔티티 기준으로 중복을 제거해주는것도 데이터베이스 단에서 해주는 것이 아니기 때문에 페이징이 불가능하다. 컬렉션을 페치 조인하고 페이징 API(setFirstResult, setMaxResults)를 사용하면 모든 데이터베이스 데이터를 읽어서 메모리에서 페이징을 시도해서 매우 위험하다. 절대 사용하면 안 된다.
-
컬렉션 페치 조인은 데이터 정합성 때문에 1개 까지만 가능하다.
5.3 페치 조인 + 배치 사이즈
일대다 관계를 맺은 컬렉션 엔티티를 함께 조회하면서 페이징도 가능한 방법이 있다. JPA 쿼리의 대부분은 이 방법을 통해 최적화할 수 있다.
-
x대일 관계는 페치 조인을 통해 가져온다.
-
컬렉션은 지연 로딩한다.
-
지연 로딩 성능 최적화를 위해
hibernate.default_batch_fetch_size(글로벌 설정)이나@BatchSize(개별 설정)을 적용한다.
@GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3Pagable(
@RequestParam(value = "offset", defaultValue = "0") int offset,
@RequestParam(value = "limit", defaultValue = "100") int limit) {
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset, limit);
return orders.stream()
.map(OrderDto::new)
.collect(toList());
}public List<Order> findAllWithMemberDelivery(int offset, int limit) {
return em.createQuery(
"select o from Order o " +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
}Order 기준으로 x대일 관계인 Member, Delivery는 페치 조인을 통해 즉시 로딩했다. x대일 관계는 데이터의 개수가 늘어나지 않기 때문에 페이징이 가능하다.
spring:
datasource:
url: jdbc:h2:tcp://localhost/~/Coding/Java/inflearn/jpa-inf/jpashop/jpashop
username: sa
password:
driver-class-name: org.h2.Driver
jpa:
hibernate:
ddl-auto: none
properties:
hibernate:
format_sql: true
default_batch_fetch_size: 100 # 요게 핵심!!!!!!
logging:
level:
org.hibernate.SQL: debug컬렉션의 경우 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size를 설정한다. 애플리케이션 특성에 따라 보통 100~1000의 값으로 설정한다. 개별로 설정하려면 컬렉션 필드에 @BatchSize를 적용하면 된다.
이 설정을 사용하면 쿼리 호출 수가 1+N에서 1+1로 최적화 된다. 프록시를 초기화하기 위해 엔티티 각각에대해 N번의 쿼리가 나가는 대신 설정파일에서 설정한 크기만큼 IN쿼리로 묶어서 쿼리가 나간다. IN 쿼리는 PK기반으로 데이터를 가져오기 때문에 일반적으로 속도가 매우 빠르다.
페치 조인은 1번의 쿼리를 통해 필요한 모든 데이터를 가져온다. 배치사이즈 방식은 페치 조인에 비해 쿼리 호출 수가 약간 증가하지만 페이징이 가능하다는 강력한 장점이 있다.
배치 사이즈는 컬렉션 연관관계뿐 아니라 x대일 연관관계에도 적용되지만 x대일 연관관계는 페치 조인을 이용하는 것이 낫다.
6. 정리
정리하자면 권장 순서는 다음과 같다.
-
엔티티 조회 방식으로 접근한다.
1.1. 페치 조인으로 x대일 엔티티를 조회한다.
1.2. 페이징이 필요하면 배치 사이즈를 통해 컬렉션 엔티티를 조회한다. 페이징이 필요없다면 컬렉션 엔티티도 페치 조인한다.
-
DTO로 직접 데이터를 매핑하고 싶으면 DTO 조회 방식을 사용한다. API 응답 스펙이 엔티티의 모양과 전혀 다르다면 이 방법이 나을때가 있다. 다만 이 방식을 사용하면 쿼리의 재사용성이 매우 떨어진다. 유지보수 관점에서 DTO를 응답하는 리포지토리와 엔티티를 응답하는 리포지토리를 분리하는 것을 고려해보자.
-
DTO조회 방식으로도 해결이 안 되면 네이티브 SQL/SpringJdbcTemplate을 통해 직접 SQL을 작성한다. 예를 들어, 특정 SQL에서만 제공하는 함수가 필요한 상황이라면 어쩔 수 없이 SQL을 작성해야하지만 이 경우는 정말 드물다.
