
이번에는 SQL을 회고해보려고 한다.
나는 SQLD를 2023년에 취득했고 SQL을 따로 공부해본 적이 없다... 그리고 그때 제대로 공부했다기 보다는 기출만 돌리고 시험을 봐서 SQL에 대해 정말 무지한 상태로 수업을 들었다.
금융권 코테는 무조건 SQL이 들어가기 때문에, 이번 기회에 제대로 공부해보겠다!!
Database
MySQL Architecture
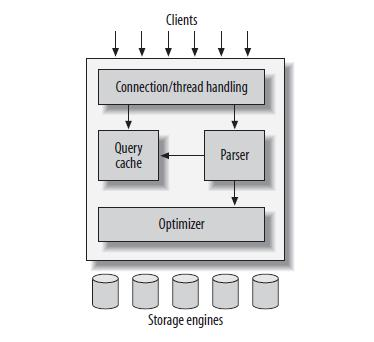
- Connection/thread handling
접속자가 동시에 한개의 데이터베이스에 접속
→ 접속자만큼의 connection이 생김 (약 30명이면 약 30개의 connection이 생김)
→ connection마다 session이 생김
→ session은 곧 한개의 thread
→ 각각의 connection들이 각각의 session에서 쿼리(sql문)를 날림 - Parser
SQL을 파싱을 하고 AST가 만들어짐
→ Query cache에 저장 (재사용 가능)- 무조건 캐싱하는 것은 아님! =>
Prepared - 값을 캐싱하는 것이 아니라 쿼리를 캐싱해서
?에 값만 박기
where id = ? - 무조건 캐싱하는 것은 아님! =>
- Optimizer
- 최적화
- 쿼리 재작성, 테이블 읽기 순서 결정, 사용할 인덱스 선택 등
- 최적화
- Storage Engines
- MySQL이 데이터를 저장하는 방식
Execution path of a query
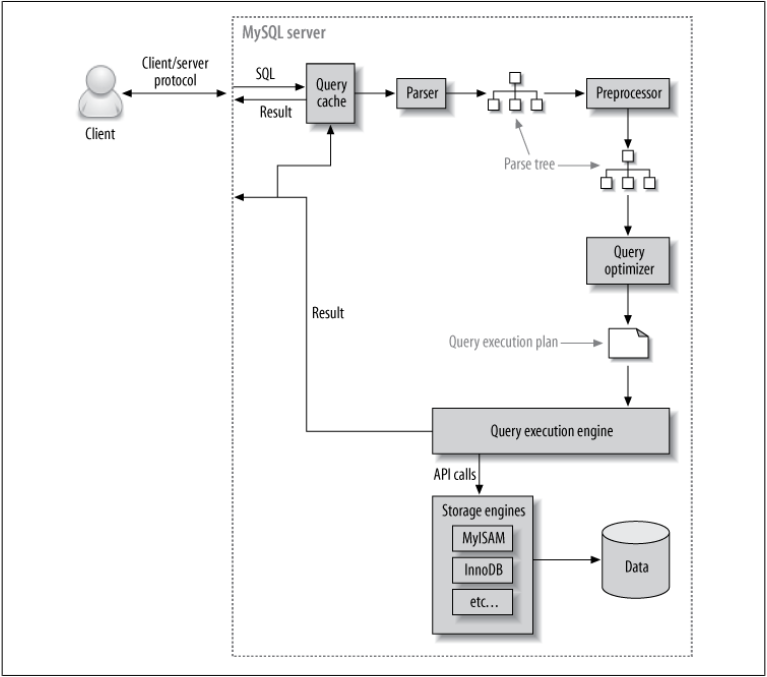
- Client/server protocol
- Query Cache, Parse
- 캐싱되어 있으면 캐시 사용, 없으면 파싱 후 캐싱
- Parse Tree 생성 (AST), Preprocessor(전처리기)
- Syntax 검사
- 문법 검사
- 실제로 존재하는지, 권한이 있는지 확인
- 쿼리 구조 검사
- 옵티마이저 처리 전에!!!
- Query Optimizer
- 스케쥴링(ex. 어떤 테이블을 먼저 읽을지)
- 어느 DB가 더 좋은지 선택(전국민 DB, 소상공인 DB → 소상공인 DB를 뒤지는것이 효율적)
- Query execution engine
- API calls
- Storage engine이 쿼리 마무리
InnoDB의 MVCC(Multi-Version Concurrency Control)
기술면접에서도 나올만큼 중요하다고 한다!
- 잠금(Lock)을 사용하지 않고도 여러 트랜잭션이 동시에 데이터를 읽고 쓸 수 있게 해주는 기술
- Undo Log와 Read View
- 데이터의 여러 버전을 유지
- Undo Log: 데이터를 수정할 때, 수정 전의 데이터를 버리지 않고 보관
- Read View(스냅샷):
- 트랜잭션이 시작될 때, 어떤 버전을 읽어야 할지 결정
- 자신의 시점에서 읽을 수 있음
- A가 데이터를 90에서 91로 바꾸는 중이라면, 나중에 온 B는 Read View를 통해 Undo Log에 있는 90을 읽음
- Undo log를 새로 만들어놓고 작업하기 때문에 Read에 Lock을 걸지 않음
- 트랜잭션의 ACID 속성 만족
- Atomicity 원자성 (All or Nothing)
- 성공하려면 다 성공, 하나 실패하면 다 실패
- Consistency 일관성(제약조건)
- 이 사람도 빼기, 저 사람도 빼기하려고 옴
- 1 → 0 성공
- but 동시에 오면…? 누구한테 에러를 보낼래?
- 두번째 사람만 에러
- Isolation 격리성(별개의 Tx)
- Durability 지속성(보존)
- Atomicity 원자성 (All or Nothing)
Docker
- 배에 '컨테이너'들이 실려있고, 커피, 빵 등이 있음
- 이때 커피, 빵처럼 컨테이너 안에 들어있는 것을 '이미지'라고 부름
- MySQL, Oracle, Tomcat 등
- OS가 이미지를 사용할 수 있도록 함
- 이 컨테이너들이 컴퓨터(Host OS) 위에서 독립적으로 잘 돌아가도록 관리해주는 가상화 플랫폼이 '도커'
Port
- docker를 실행하는 OS는 포트번호를 사용하고 있음
- 이때 이미지가 같은 포트번호를 사용하는 것은 사실 문제가 되지 않음
- 컨테이너 내부이기 때문- 도커 컨테이너는 내부적으로 자신만의 네트워크를 가짐
- but, 컨테이너를 들어가기 위해서는 port와 volume이 필요한데, 이때 포트가 중복되면 안됨
- volume
- 컨테이너는 삭제되면 그 안의 데이터도 사라짐
- 컨테이너 내부의 데이터 저장소나 Host 컴퓨터의 특정 폴더를 연결해서 컨테이너가 사라져도 데이터는 남아있도록 하는 장치
- port
- 컴퓨터에서 컨테이너 안으로 들어가는 통로
- 3308(Host) : 3306(컨테이너) -> 내 컴퓨터의 3308번으로 접속하면 컨테이너의 3306번으로 연결
- volume
즉, 만약 내 컴퓨터에서 이미 다른 프로그램이 3306 포트를 사용 중인 상황에서,
도커로 MySQL을 실행하려 할 때는 컨테이너 내부의 포트를 3306이 아닌 번호로 설정해야 한다.
Docker로 MySQL을 띄우면 누가 어떤 컴퓨터에서 실행하든 항상 똑같이 실행할 수 있고, 독립적으로 사용 가능하다는 이점이 있다.
데이터와 페이지
- 모든 데이터는 페이지 단위로 데이터를 갖고 있음
- 페이지는 기본적으로 16K 단위
- 1번, 2번, 3번 데이터가 쌓이다가 16KB가 꽉 차면 페이지가 떨궈져 나감
=> 페이지 분할
DDL
Data Types
- enum
-
rule
-
많은 회사에서 enum을 사용하지 않는 이유
-
수정을 하게되면 모든 행을 다 확인하고 고쳐줌
-
내부적으로는 정수 인덱스로 관리되므로, 중간에 값을 추가하거나 순서를 바꾸면 데이터 정합성이 깨짐
-
이전에는 4로 조회가 되었던 것이 이제는 5로 조회해야함
select * from T where score = 4; alter table T modify column score enum('A', 'B', 'C', 'D', 'F') default 'F' comment '학점'; select * from T where score = 5;
-
-
요즘에는 잘 쓰는 이유
- ORM과 잘맞음
- Spring에서 enum타입을 정해둠
⇒ enum 컬럼에 숫자는 금지하면서 사용하자!!!
-
TCL
- 트랜잭션: 더 이상 쪼갤 수 없는 업무 단위
- 세션 단위로 Tx 제어
- DDL은 Undo Log가 생기지 않기 때문에, Rollback한다고 해서 돌아가지 않음
start transaction;
update Student set birthdt='20250909';
rollback;
update Studnet set birthdt='20050909' where id = 5;
commit;Save Point
START TRANSACTION;
SavePoint x;
update Dept set dname='xxxxx' where id = 1;
SavePoint y;
update User set dname='yyyyy' where id = 2;
rollback to savepoint y;
COMMIT; 또는 ROLLBACK;- 서비스에 바로 반영이 안되는 경우에는 같이 반영이 되어야 함 => SavePoint 잡아야 함
- 쇼핑몰에 주문했을 때, 주문 테이블에 데이터가 들어가고 재고 테이블에 수량이 줄어들어야 하는데 재고 줄이기가 실패한다면- SavePoint를 활용해서 주문 직전의 SavePoint로 돌아가서 다시 시도하거나 전체를 취소할지 결정
- QA DB에서 프로시저 1개를 만들어서 SavePoint를 잡아서 테스트한 뒤, 그 프로시저를 실DB에 배포
- 만약 6번에서 오류가 난다면 5번 지점까지만 살려두고 다시 시도 가능
Routines
view
- 실제 데이터가 들어있는 것이 아니라, 쿼리 자체를 저장해두고 마치 하나의 테이블처럼 사용하는 가상테이블
- 사용 목적
- 보안: 민감한 데이터는 숨기고 필요한 컬럼만 보여줌- 단순화: 복잡한 조인 쿼리를 뷰로 만들어두면, 뷰만 단순하게 조회 가능
- 성능 및 관리: 컴파일된 쿼리로 동작하여 효율적
Stored Function
- 파라미터를 입력받아 특정 연산을 수행하고 반드시 하나의 결과값을 반환하는 객체
- 반드시 RETURNS 예약어로 반환 데이터 타입을 정의하고, RETURN으로 값을 돌려줘야 함
- 프로시저와 달리 함수 내부에서는 트랜잭션을 제어(COMMIT 등)할 수 없다는 제약
DELIMITER $$
CREATE Function f_dt(_ts timestamp) RETURNS varchar(31)
BEGIN
RETURN date_format(_ts, '%m/%d %H:%i');
END $$
DELIMITER ;Procedure
- 여러 개의 SQL 문과 로직을 하나로 묶어놓은 모듈
- 반환값이 필수는 아니며, 주로 call 프로시저명() 형태로 실행
- 사용 목적
- 접근권한, 소스 보호- 복잡한 비즈니스 로직을 한 번에 처리
- 로직이 변경되었을 때 프로시저만 수정
- 성능 향상
Trigger
- 데이터에 변경(INSERT, UPDATE, DELETE)이 발생할 때 자동으로 실행
- '과목(Subject)' 테이블에 새로운 과목 데이터가 추가(INSERT)될 때, '교수(Prof)' 테이블에 있는 해당 교수의 담당 과목 수(subjectcnt)를 자동으로 1 증가시키는 등의 연쇄 작업에 사용
Cursor
- SELECT 쿼리의 결과로 반환된 여러 행(Row)을 하나씩 순차적으로 읽어 처리할 때 사용
- 작업 절차
- DECLARE CURSOR: 처리할 쿼리 정의
- DECLARE CONTINUE HANDLER: 데이터를 모두 읽었을 때(NOT FOUND)의 동작을 지정
- OPEN: 커서 활성화
- FETCH: 현재 행의 데이터를 변수에 읽기
- CLOSE: 사용이 끝난 커서 닫기
재귀 CTE (Recursive CTE)
- 첫 번째 SELECT(Anchor)는 초기값을 선언하고, UNION ALL 이후의 SELECT(Recursive)가 조건에 맞을 때까지 반복 실행
- 조직도, 카테고리 계층 구조 등 트리 형태의 데이터를 다룰 때 필수적
WITH RECURSIVE fibonacci (n, fib_n, next_fib_n) AS
(
select 1, 0, 1
UNION ALL
select n + 1, next_fib_n, fib_n + next_fib_n
from fibonacci where n < 10
)
select * from fibonacci;인덱스
Clustered vs Non-Clustered
-
클러스터형 인덱스 (Clustered Index)
- 데이터 자체가 인덱스 순서로 물리적으로 정렬 (보통 PK)
- PK는 크기가 작고 값이 변하지 않는 것이 좋음- 복합키를 PK로 쓰기보다 별도의 숫자형 ID를 쓰는 것이 성능상 유리
-
비클러스터형 인덱스 (Non-Clustered Index)
- 데이터는 그대로 두고 주소록(별도 페이지)만 만드는 방식
B-Tree
- 모든 데이터는 16KB 단위의 페이지(Page)에 저장
- 인덱스 탐색 시 이 페이지 단위로 읽기 때문에 페이지 효율이 중요
document db
- uuid
- 유저아이디를 uuid로 할 필요는 없음!!
=> 어차피 의미있는 값은 아니라 유출이 되거나 말거나 중요하지 않음!
=> but 주민등록번호, 카드 번호는 유출되면 안됨
파티셔닝
- 작년 데이터를 그냥 버리냐?? → 버리지 않고 파티셔닝을 함
- 100만건 정도는 되어야 파티셔닝을 하는 것이 의미가 있음
- 이유
- FK 지정이 불가능해서 → join 성능이 떨어짐
- 이유
- 아마존에서 ebs 설정할 때
-
스토리지를 샀다고 가정
-
100기가를 사도 안보임
-
파티셔닝을 나눠줘야 함
-
클라우드 같은 경우 지가 알아서 쪼개줌(2~3개)
-
10기가를 한 파티션으로 몰아버리면 그게 보임…?
-
다른 서버에서는 이 파티션, 다른 서버는 이 파티션 쓸 수 있음
⇒ 마찬가지!!!!
-
- 파티션 드롭하면 데이터도 같이 삭제됨
- 1999년 데이터를 지우고 싶다? → 해당 파티션을 죽여
- 빅데이터,ai인 경우 보통 포린키 없음…
회고
기존에는 단순히 select 구문만 알았는데, 이번에 어떻게 인덱스를 하고 데이터는 어느정도로 크기를 잡아야 하는지 고민할 수 있는 수업이었던 것 같다.
백업 부분 실습이 특히 막히고 어려웠던 것 같다. 그런데 실무에서는 이 과정을 모르면 나중에 실수했을 때 큰 위험이 될 수 있으므로 연습이 필요할 것 같다.
