USING BINDLESS RESOURCES WITH DIRECTX RAYTRACING
ABSTRACT
Direct3D 12의 리소스 바인딩은 복잡하고 올바르게 구현하기 어려울 수 있으며, 특히 DirectX 레이트레이싱과 함께 사용할 경우 더욱 그렇습니다. 이 장에서는 바인드리스 기술을 사용하여 셰이더에 모든 리소스에 대한 전역 액세스를 제공하여 애플리케이션 및 셰이더 코드를 간소화하는 동시에 새로운 기술을 구현하는 방법을 설명합니다.
INTRODUCTION

Direct3D 12가 도입되기 전에는 GPU 텍스처 및 버퍼 리소스에 간단한 CPU 기반 바인딩 모델을 사용하여 액세스했습니다. GPU의 리소스 액세스 기능은 일반적으로 논리적 GPU 파이프라인의 특정 단계에 연결된 '슬롯' 집합으로 노출되었으며, GPU가 리소스 뷰를 노출된 슬롯 중 하나에 '바인딩'할 수 있는 API 함수가 제공되었습니다. 이러한 종류의 바인딩 모델은 일반적으로 셰이더 코어가 리소스에 액세스하는 데 사용하는 고정된 하드웨어 디스크립터 레지스터 세트를 특징으로 하는 초기 GPU의 자연스러운 기능입니다.
이 오래된 바인딩 방식은 비교적 간단하고 이해도가 높았지만, 당연히 많은 제약이 따랐습니다. 바인딩 슬롯의 제한된 특성으로 인해 프로그램은 일반적으로 특정 셰이더 프로그램에서 액세스하는 정확한 리소스 세트만 바인딩할 수 있었으며, 이는 종종 모든 드로우 또는 디스패치 전에 수행해야 하는 작업이었죠. CPU 기반 바인딩의 특성상 셰이더에 필요한 리소스를 컴파일 후에 정적으로 알아야 했기 때문에 셰이더 프로그램의 복잡성에 내재된 제한이 자연스럽게 발생했습니다.
GPU의 레이 트레이싱이 주목받기 시작하면서 기존의 바인딩 모델은 한계점에 도달했습니다. 레이 트레이싱은 본질적으로 글로벌 프로세스인 경향이 있습니다. 하나의 셰이더 프로그램이 씬의 모든 머티리얼과 상호 작용할 수 있는 광선을 발사할 수 있습니다. 이는 디스패치 전에 CPU가 고정된 리소스 집합을 바인딩하는 개념과 크게 양립할 수 없습니다. 아틀라싱이나 스파스 버추얼 텍스처링[1]과 같은 기술은 글로벌 리소스 액세스를 에뮬레이션하는 수단으로 사용할 수 있지만 렌더러에 상당한 복잡성을 추가해야 할 수도 있습니다.
다행히도 최신 GPU와 API에는 더 이상 동일한 제한이 없습니다. 대부분의 최신 GPU 아키텍처는 리소스 설명자를 레지스터가 아닌 메모리에서 로드할 수 있는 모델로 전환했으며, 경우에 따라 메모리 주소에서 직접 리소스에 액세스할 수도 있습니다. 이로써 특정 셰이더 프로그램에서 액세스할 수 있는 리소스 수에 대한 이전의 제한이 사라지고 셰이더 프로그램이 실제로 액세스할 리소스를 동적으로 선택할 수 있는 길이 열렸습니다.
이 새로운 유연성은 이전 버전의 API에 비해 완전히 개선된 Direct3D 12의 바인딩 모델에 직접 반영되어 있습니다. 특히 바인드리스 리소스[2]로 알려진 기술을 총체적으로 활성화하는 기능을 지원합니다. 바인드리스 기술을 구현하면 셰이더 프로그램에 GPU에 존재하는 전체 텍스처 및 버퍼 세트에 대한 전체 글로벌 액세스를 효과적으로 제공할 수 있습니다. CPU가 각 개별 리소스에 대한 뷰를 바인딩할 필요 없이 셰이더는 사용자가 정의한 데이터 구조에 자유롭게 임베드할 수 있는 간단한 32비트 인덱스를 사용하여 개별 리소스에 액세스할 수 있습니다. 이러한 수준의 유연성은 기존의 래스터화 시나리오에서는 매우 유용할 수 있지만[6], 다이렉트X 레이트레이싱(DXR)을 사용할 때는 거의 필수적입니다.
이 장의 나머지 부분에서는 Direct3D 12(D3D12)를 사용하여 바인드리스 리소스 액세스를 활성화하는 방법에 대해 자세히 설명하고, DXR 레이 트레이서에서 바인드리스 기술을 사용하는 방법에 대한 기본 사항도 다룹니다. D3D12와 DXR에 대한 기본적인 지식이 있다고 가정하고, 레이 트레이싱 젬 1권의 입문 장을 참고하시기 바랍니다.
TRADITIONAL BINDING WITH DXR
다른 D3D12와 마찬가지로 DXR은 루트 서명을 활용하여 셰이더 프로그램에서 리소스를 사용할 수 있도록 하는 방법을 지정합니다. 이러한 루트 서명은 루트 디스크립터, 디스크립터 테이블, 32비트 상수의 컬렉션을 지정하고 이를 HLSL 바인딩 레지스터의 범위에 매핑합니다. DXR을 사용할 때 실제로는 글로벌 루트 서명과 로컬 루트 서명이라는 두 가지 유형의 루트 서명을 처리합니다. 글로벌 루트 서명은 광선 생성 셰이더는 물론 실행된 모든 미스, 임의 히트, 가장 가까운 히트 및 교차 셰이더에 적용됩니다. 로컬 루트 시그니처는 특정 히트 그룹에만 적용됩니다. 글로벌 및 로컬 루트 서명을 함께 사용하면 CPU 코드가 셰이더 프로그램에 필요한 모든 리소스에 대한 디스크립터를 "푸시"하는 상당히 전통적인 바인딩 모델을 구현할 수 있습니다. 일반적인 렌더링 시나리오에서는 로컬 루트 시그니처가 히트 그룹에 할당된 특정 머티리얼에 필요한 모든 텍스처와 상수 버퍼가 포함된 디스크립터 테이블을 제공하도록 할 수 있습니다. 이러한 전통적인 리소스 바인딩 모델의 예는 그림 17-2에 나와 있습니다.
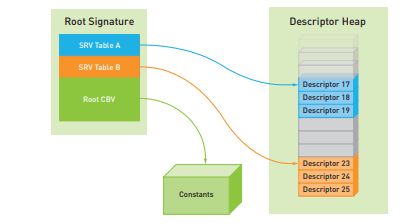
그림 17-2. D3D12의 기존 리소스 바인딩 예시.
루트 시그니처에는 글로벌 디스크립터 힙 내의 인접한 SRV 디스크립터 범위를 가리키는 두 개의 SRV(셰이더 리소스 뷰) 디스크립터 테이블 항목이 포함되며, 각 항목은 루트 CBV(Constant Buffer View)를 포함하고 있습니다.
이 접근 방식은 실행 가능할 수 있지만 이상적이지 않은 몇 가지 문제가 있습니다. 첫째, 로컬 루트 서명의 메커니즘이 D3D12 내에서 루트 서명이 일반적으로 작동하는 방식과 다소 일치하지 않습니다. 표준 루트 서명을 사용하려면 명령 목록 API를 사용하여 루트 서명의 해당 항목에 바인딩할 상수, 루트 설명자 및 설명자 테이블을 지정해야 합니다. 로컬 루트 서명은 단일 상태 객체 내에 여러 가지 루트 서명이 포함될 수 있기 때문에 이러한 방식으로 작동하지 않습니다. 대신 루트 서명 항목의 파라미터를 히트 그룹 셰이더 테이블의 셰이더 레코드 내에 인라인으로 셰이더 식별자 바로 다음에 배치해야 합니다. 이 설정은 셰이더 레코드와 루트 서명 파라미터 모두 준수해야 하는 특정 정렬 요구 사항이 있기 때문에 더욱 복잡해집니다.
셰이더 식별자는 32바이트(D3D12_SHADER_IDENTIFIER_SIZE_IN_BYTES)를 사용하며 32바이트에 맞춰 정렬된 오프셋(D3D12_RAYTRACING_SHADER_RECORD_BYTE_ALIGNMENT)에 위치해야 합니다. 루트 디스크립터와 같이 크기가 8바이트인 루트 서명 파라미터도 8바이트에 맞춰 정렬된 오프셋에 배치해야 합니다. 따라서 셰이더 테이블을 생성할 때 이러한 특정 규칙을 충족하려면 신중하게 작성된 패킹 코드 또는 헬퍼 유형을 사용해야 합니다.
다음 코드는 셰이더 레코드 헬퍼 구조가 어떤 모습일지 보여주는 예시입니다:
struct ShaderIdentifier
{
uint8_t Data[D3D12_SHADER_IDENTIFIER_SIZE_IN_BYTES] = { };
ShaderIdentifier() = default;
explicit ShaderIdentifier(const void* idPointer)
{
memcpy(Data, idPointer , D3D12_SHADER_IDENTIFIER_SIZE_IN_BYTES);
}
};
struct HitGroupRecord
{
ShaderIdentifier ID;
D3D12_GPU_DESCRIPTOR_HANDLE SRVTableA = { };
D3D12_GPU_DESCRIPTOR_HANDLE SRVTableB = { };
uint32_t Padding1 = 0; // CBV에 8바이트 정렬이 있는지 확인합니다.
uint64_t CBV = 0;
uint8_t Padding[8] = { }; // 셰이더 ID를 32바이트 정렬로 유지해야 함
};메시와 머티리얼이 많은 복잡한 시나리오의 경우 로컬 루트 서명 방식은 다루기 힘들고 오류가 발생하기 쉽습니다. 히트 셰이더 테이블 채우기의 일부로 CPU에서 로컬 루트 서명 인수를 생성하는 것이 가장 간단한 방법이지만, 동적 인수를 지원하기 위해 자주 수행해야 하는 경우 귀중한 CPU 사이클을 소모할 수 있습니다. 또한 히트 셰이더에 필요한 리소스 집합을 미리 알고 있어야 하며 셰이더 자체가 정적 리소스 바인딩 집합을 사용하도록 작성해야 하는 등 이전 버전의 D3D에서와 마찬가지로 셰이더 프로그램에 몇 가지 제한이 있습니다.
컴퓨팅 셰이더를 사용하여 GPU에서 셰이더 테이블을 생성하는 것은 더 많은 GPU 기반 렌더링 접근 방식을 허용하는 실행 가능한 옵션이지만, 동등한 CPU 구현에 비해 작성, 검증 및 디버그가 훨씬 더 어려울 수 있습니다. 또한 셰이더 프로그램과 액세스할 리소스를 동적으로 선택하는 것과 관련된 제한 사항도 제거되지 않습니다. 로컬 루트 서명을 사용하는 것은 더 이상 옵션이 아니기 때문에 두 가지 접근 방식은 DXR 1.1에 추가된 새로운 인라인 레이트레이싱 기능과 근본적으로 호환되지 않습니다. 즉, 일반적인 렌더링 시나리오에서 새로운 레이쿼리 API를 사용하려면 덜 제한적인 바인딩 솔루션을 고려해야 합니다.
BINDLESS RESOURCES IN D3D12
앞서 언급했듯이 바인드리스 기술을 사용하면 셰이더 프로그램에 현재 로드된 모든 리소스에 대한 전역 액세스를 작은 하위 집합으로 제한하지 않고 효과적으로 제공할 수 있습니다. D3D12는 셰이더 가시 디스크립터 힙을 활용하는 모든 리소스 유형에 대한 바인드리스 액세스를 지원합니다: (셰이더 리소스 뷰(SRV), 상수 버퍼 뷰(CBV), 정렬되지 않은 액세스 뷰(UAV) 및 샘플러)
그러나 이러한 유형에는 각각 다른 제한 사항이 있어 바인드리스 시나리오에서 사용하지 못할 수 있으며, 대부분 장치에서 노출되는 D3D12_RESOURCE_BINDING_TIER 값에 따라 결정됩니다. 이러한 제한 사항 중 일부는 섹션 17.5에서 자세히 다루겠지만, 지금은 주로 셰이더 프로그램에서 액세스하는 리소스의 대부분을 차지하는 SRV에 바인드리스 기술을 사용하는 데 중점을 두겠습니다. 그러나 여기서 설명하는 개념은 일반적으로 약간의 노력만 기울이면 다른 리소스 뷰로 확장할 수 있습니다.
D3D12에서 바인드리스 리소스를 활성화하기 위한 핵심은 단일 루트 파라미터를 통해 전체 디스크립터 힙을 효과적으로 노출하는 방식으로 루트 서명을 설정하는 것입니다. 이를 수행하는 가장 간단한 방법은 single unbounded descriptor range와 함께 D3D12_ROOT_PARAMETER_TYPE_DESCRIPTOR_TABLE 유형의 파라미터를 추가하는 것입니다.
// Unbounded range of descriptor SRV to expose the entire heap
D3D12_DESCRIPTOR_RANGE1 srvRanges[1] = {};
srvRanges[0].RangeType = D3D12_DESCRIPTOR_RANGE_TYPE_SRV;
srvRanges[0].NumDescriptors = UINT_MAX;
srvRanges[0].BaseShaderRegister = 0;
srvRanges[0].RegisterSpace = 0;
srvRanges[0].OffsetInDescriptorsFromTableStart = 0;
srvRanges[0].Flags = D3D12_DESCRIPTOR_RANGE_FLAG_DESCRIPTORS_VOLATILE;
D3D12_ROOT_PARAMETER1 params[1] = {};
// Descriptor table root parameter
params[0].ParameterType = D3D12_ROOT_PARAMETER_TYPE_DESCRIPTOR_TABLE;
params[0].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
params[0].DescriptorTable.pDescriptorRanges = srvRanges;
params[0].DescriptorTable.NumDescriptorRanges = 1;렌더링용 커맨드 목록을 빌드할 때 ID3D12DescriptorHeap::GetGPUDescriptorHandleForHeapStart()에서 반환한 핸들을 ID3D12GraphicsCommandList::SetGraphicsRootDescriptorTable() 또는 ID3D12GraphicsCommandList::SetComputeRootDescriptorTable()에 전달하여 해당 힙의 전체 내용을 셰이더에서 사용할 수 있도록 할 수 있습니다. 이렇게 하면 힙을 분할할 필요 없이 생성한 디스크립터를 힙의 어느 곳에나 배치할 수 있습니다.
셰이더 프로그램에서 특정 리소스의 디스크립터에 액세스하려면 디스크립터 인덱싱이라는 기술을 사용할 수 있습니다. HLSL에서 이 기법을 사용하려면 먼저 특정 셰이더 리소스 유형(예: Texture2D)의 배열을 선언해야 합니다. 특정 리소스에 액세스하려면 일반 정수를 사용하여 배열에 인덱싱하기만 하면 됩니다. 그림 17-3에 표시된 것처럼 상수 버퍼를 사용하여 디스크립터 인덱스를 셰이더에 전달하는 간단하고 직관적인 방법이 있습니다.
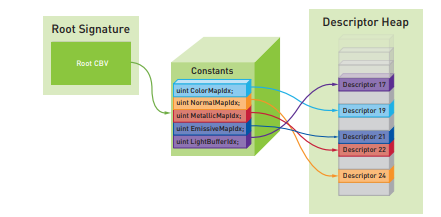
그림 17-3. 바인드리스 기술을 사용하여 SRV 디스크립터에 액세스하는 예제입니다. 루트 서명에는 루트 상수 버퍼 뷰가 포함되어 있으며, 이 뷰는 전역 기술자 힙 내에서 기술자의 32비트 인덱스가 포함된 상수 블록을 가리킵니다. 바인드리스 설정을 사용하면 셰이더에 필요한 디스크립터가 디스크립터 힙 내에서 연속적일 필요가 없으며 셰이더가 리소스에 액세스하거나 선언하는 방식과 관련하여 순서를 지정할 필요가 없습니다.
// 텍스처 배열 선언
Texture2D GlobalTextureArray[] : register(t0);
SamplerState MySampler : register(s0);
// 텍스처 인덱싱을 위한 Constant Buffer
struct MyConstants
{
uint TexDescriptorIndex;
};
ConstantBuffer <MyConstants > MyConstantBuffer : register(b0);
float4 MyPixelShader(in float2 uv : UV) : SV_Target0
{
uint texDescriptorIndex = MyConstantBuffer.TexDescriptorIndex;
Texture2D myTexture = GlobalTextureArray[texDescriptorIndex];
return myTexture.Sample(MySampler , uv);
}이 예제가 작동하려면 루트 서명의 디스크립터 테이블 파라미터가 셰이더의 Texture2D 배열에서 사용하는 t0 레지스터에 매핑되어 있는지 확인하기만 하면 됩니다.
이 작업이 제대로 수행되면 셰이더는 사실상 전체 전역 디스크립터 힙에 대한 전체 액세스 권한을 갖게 됩니다. 또는 적어도 Texture2D HLSL 유형에 매핑할 수 있는 모든 디스크립터에 액세스할 수 있습니다.
현재 버전의 HLSL의 한 가지 한계는 셰이더에서 액세스하려는 각 HLSL 리소스 유형에 대해 별도의 배열을 선언해야 하며, 각 배열에는 겹치지 않는 별도의 레지스터 매핑이 있어야 한다는 것입니다. 할당이 겹치지 않도록 하는 간단한 방법은 각 리소스 배열에 대해 서로 다른 레지스터 공간을 사용하는 것입니다. 이렇게 하면 셰이더에 배열 크기를 컴파일할 필요 없이 무제한 배열을 계속 사용할 수 있습니다.
Texture2D Tex2DTable[] : register(t0, space0);
Texture2D <uint4 > Tex2DUintTable[] : register(t0, space1);
Texture2DArray Tex2DArrayTable[] : register(t0, space2);
TextureCube TexCubeTable[] : register(t0, space3);
Texture3D Tex3DTable[] : register(t0, space4);
Texture2DMS <float4 > Tex2DMSTable[] : register(t0, space5);
ByteAddressBuffer RawBufferTable[] : register(t0, space6);
Buffer <uint> BufferUintTable[] : register(t0, space7);
// ... and so onTexture2D와 Texture3D처럼 서로 다른 리소스 유형에 대해 별도의 배열이 필요할 뿐만 아니라 동일한 HLSL 리소스 유형에서 서로 다른 반환 유형(C++ 템플릿 구문을 사용하여 표현)에 대해 별도의 배열이 필요할 수도 있습니다.
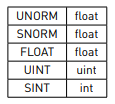
이는 Texture2D와 Texture2D(반환 유형이 없는 텍스처 리소스는 암시적 반환 유형이 float4입니다)의 배열이 모두 있는 앞의 예에서 분명하게 드러납니다. 특정 포맷에서는 셰이더가 특정 반환 유형으로 HLSL 리소스를 선언해야 하므로 가능한 모든 DXGI(DirectX 그래픽 인프라) 텍스처 포맷을 지원하려면 다양한 반환 유형을 가진 텍스처를 보유해야 하는 것은 아쉽지만 필수입니다. 다음 표에는 DXGI_FORMAT 열거형에서 사용할 수 있는 각 포맷 수정자에 적합한 반환 유형이 나열되어 있습니다:
별도의 HLSL 리소스 배열과 레지스터 공간 바인딩을 사용할 때 발생하는 한 가지 결과는 선언된 각 배열에 대해 루트 서명에 해당 설명자 범위가 있어야 한다는 것입니다. 다행히도 하나의 루트 매개변수에 여러 개의 무제한 기술자 범위를 스택으로 쌓을 수 있습니다. 이는 궁극적으로 각 루트 서명에 대해 글로벌 디스크립터 힙을 한 번만 바인딩하면 된다는 것을 의미합니다:
D3D12_DESCRIPTOR_RANGE1 ranges[NumDescriptorRanges] = {};
for(uint32_t i = 0; i < NumDescriptorRanges; ++i)
{
ranges[i].RangeType = D3D12_DESCRIPTOR_RANGE_TYPE_SRV;
ranges[i].NumDescriptors = UINT_MAX;
ranges[i].BaseShaderRegister = 0;
ranges[i].RegisterSpace = i;
ranges[i].OffsetInDescriptorsFromTableStart = 0;
ranges[i].Flags = D3D12_DESCRIPTOR_RANGE_FLAG_DESCRIPTORS_VOLATILE;
}
D3D12_ROOT_PARAMETER1 params[1] = {};
// Descriptor table root parameter
params[0].ParameterType = D3D12_ROOT_PARAMETER_TYPE_DESCRIPTOR_TABLE;
params[0].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
params[0].DescriptorTable.pDescriptorRanges = ranges;
params[0].DescriptorTable.NumDescriptorRanges = 1;이 접근 방식을 사용하면 다양한 유형의 버퍼 및 텍스처 리소스에 대한 바인딩 없는 액세스에 대한 지원을 확장할 수 있습니다. 단일 헤더 플레에 HLSL 리소스 배열 세트를 선언한 다음 리소스에 액세스해야 하는 모든 셰이더 코드에 해당 플레를 포함할 수도 있습니다.
하지만 일반적으로 사용자가 정의한 구조체 유형에 템플릿을 지정하는 StructuredBuffer나 ConstantBuffer와 같은 유형은 어떨까요? 이러한 유형에는 사실상 무제한의 순열이 존재하므로 공유 헤더 플레에서 미리 정의할 수 없습니다. 이러한 유형을 처리하는 한 가지 가능한 접근 방식은 루트 시그니처에 개별 셰이더 프로그램에서 활용할 수 있는 추가 디스크립터 테이블 범위를 예약하는 것입니다. 예를 들어 레지스터 공간 100~107을 사용하여 8개의 추가 디스크립터 범위로 루트 서명을 정의할 수 있습니다. 그런 다음 사용자 정의 구조체 유형으로 StructuredBuffer에 액세스해야 하는 셰이더 프로그램을 작성하는 경우 이러한 예약된 레지스터 공간 중 하나에 바인딩된 배열을 선언하기만 하면 됩니다:
// Define an array of our custom buffer type assigned to one of our reserved register spaces.
StructuredBuffer <MyStruct > MyBufferArray[] : register(t0, space100);
MyStruct AccessMyBuffer(uint descriptorIndex , uint bufferIndex)
{
StructuredBuffer <MyStruct > myBuffer = MyBufferArray[descriptorIndex];
return myBuffer[bufferIndex];
}원래의 설명자 인덱싱 예제에서는 상수 버퍼에서 설명자 인덱스를 가져왔습니다. 이는 CPU 코드가 이러한 인덱스를 셰이더 프로그램에 전달하는 매우 간단한 방법이며, 드로우 또는 디스패치 직전에 상수 버퍼를 채우면 이 접근 방식을 사용하여 보다 전통적인 바인딩 설정을 에뮬레이트할 수도 있습니다. 하지만 디스크립터 인덱스를 전달할 때 상수 버퍼를 사용하는 데에만 국한되는 것은 아닙니다. 상수 버퍼는 단순한 정수이기 때문에 이제 거의 모든 곳에 패킹할 수 있습니다. 예를 들어 씬에 로드된 모든 머티리얼에 대한 디스크립터 인덱스 세트가 포함된 StructuredBuffer가 있다면 셰이더 프로그램은 머티리얼 인덱스를 사용하여 적절한 인덱스 세트를 가져올 수 있습니다. 이 인덱스가 유용하다면 UINT 형식(부호 없는 정수)의 렌더 타깃 텍스처로 작성할 수도 있습니다! 실제로 이러한 인덱스를 리소스에 대한 핸들 또는 리소스의 콘텐츠에 대한 액세스 권한을 부여하는 포인터로 생각할 수 있습니다.
디스크립터 인덱싱을 사용하는 셰이더 코드를 작성할 때는 항상 특정 인덱스가 균일한지 여부를 평가하는 데 주의를 기울여야 합니다. 여기서 특정 드로, 디스패치 또는 히트, 미스, 애니 히트 또는 교차 셰이더 호출 내의 모든 스레드에 대해 동일한 값을 갖는 경우 디스크립터는 균일합니다. 원래 디스크립터 인덱싱 예제에서 인덱스는 상수 버퍼에서 제공되었으므로 모든 픽셀 셰이더 스레드가 동일한 디스크립터 인덱스를 사용했음을 의미합니다.
이 경우 인덱스가 균일하다고 간주합니다. 하지만 이제 좀 더 복잡한 시나리오를 고려해 보겠습니다. 인덱스가 상수 버퍼에서 오는 대신 버텍스 셰이더에서 보간으로 전달된다면 어떨까요? 이렇게 하면 픽셀 셰이더 스레드 내에서 해당 인덱스의 값이 달라질 수 있습니다. 이 경우 인덱스는 균일하지 않은 것으로 간주됩니다.
비균일 디스크립터 인덱스는 D3D12에서 허용되지만 특별한 고려가 필요합니다. 올바른 결과를 보장하려면 인덱스가 리소스 배열에 인덱싱되는 데 사용되기 전에 비균일하지 않은 리소스 인덱스(NonUniformResourceIndex) 내재에 전달되어야 합니다. 이렇게 하면 인덱스가 달라질 수 있음을 드라이버에 알리기 때문에 SIMD 실행 환경 내에서 달라지는 디스크립터를 올바르게 처리하기 위해 추가 명령어를 삽입해야 할 수 있습니다. 대부분의 기존 GPU 아키텍처에서 이러한 명령어의 추가 비용은 아키텍처별 스레드 그룹(흔히 워프 또는 웨이브프론트라고 함) 내의 발산 정도에 비례합니다. 이러한 이유로 비균일 인덱싱을 언제 어디서 사용할지 신중하게 판단하는 것이 중요합니다. 또한 비균일 인덱싱의 결과는 NonUniformResourceIndex가 생략된 경우 정의되지 않으므로, 이를 사용하지 않으면 한 아키텍처에서는 올바른 결과가 나오지만 다른 아키텍처에서는 그래픽 아티팩트가 발생할 수 있다는 점을 알아두는 것이 중요합니다.
셰이더에 제공되는 추가적인 유연성이 바인드리스 스타일의 디스크립터 인덱싱을 채택하는 주요 동기가 될 수 있지만, 이러한 기술을 렌더링 엔진 전체에 배포할 때 애플리케이션 코드를 간소화할 수도 있습니다. 인덱싱을 통해 디스크립터에 액세스하면 본질적으로 힙의 모든 디스크립터에 드물게 액세스할 수 있으므로 특정 셰이더의 디스크립터 집합을 해당 힙 내에서 연속적으로 유지할 필요가 없습니다. 인접한 디스크립터 테이블을 유지하려면 CPU 코드에서 복잡하고 비용이 많이 드는 관리를 수행해야 하는 경우가 많으며, 특히 데이터 변경에 따라 디스크립터를 업데이트해야 하는 경우 더욱 그렇습니다.
가장 일반적인 예는 CPU 업데이트 버퍼로, 이전 버전의 D3D에서는 동적 버퍼라고도 합니다. GPU가 버퍼에서 읽는 동안 CPU는 버퍼에 쓸 수 없기 때문에 동일한 리소스 메모리에 대한 동시 액세스를 방지하기 위해 더블 버퍼링 또는 링 버퍼링과 같은 기술이 종종 배포됩니다.
그러나 새로운 내부 버퍼로 '스왑'하는 작업은 (루트 디스크립터를 사용하지 않는 경우) 디스크립터도 교체해야 하므로 기존 디스크립터 테이블이 모두 유효하지 않게 됩니다. 이 문제를 해결하려면 일반적으로 전체 디스크립터 테이블을 버전 관리하거나 특정 버퍼가 참조되는 모든 테이블을 업데이트하는 데 CPU 사이클을 소비해야 할 수 있습니다. 바인드리스 기술을 사용하면 더 이상 인접한 디스크립터 테이블에 대해 걱정할 필요가 없으므로, 특정 버퍼의 내용이 변경될 때마다 힙 내에서 하나의 디스크립터만 업데이트하면 됩니다. 여전히 GPU 명령을 실행하여 현재 참조 중인 디스크립터 힙을 업데이트하지 않도록 주의해야 하지만, N개의 글로벌 디스크립터 힙(여기서 N은 렌더러가 허용하는 최대 프레임 수)을 통해 스왑함으로써 글로벌 수준에서 이 문제를 처리할 수 있습니다.
버퍼의 '버전'에 대한 디스크립터가 항상 글로벌 힙 내에서 동일한 오프셋에 배치되어 있는 한 셰이더는 동일한 영구 디스크립터 인덱스를 사용하여 버퍼에 계속 액세스할 수 있습니다. 이러한 패턴이 실제로 어떻게 사용되는지에 대한 예시는 GitHub의 DXRPathTracer 리포지토리에 있는 StructuredBuffer::Map() 구현을 참조하십시오.
