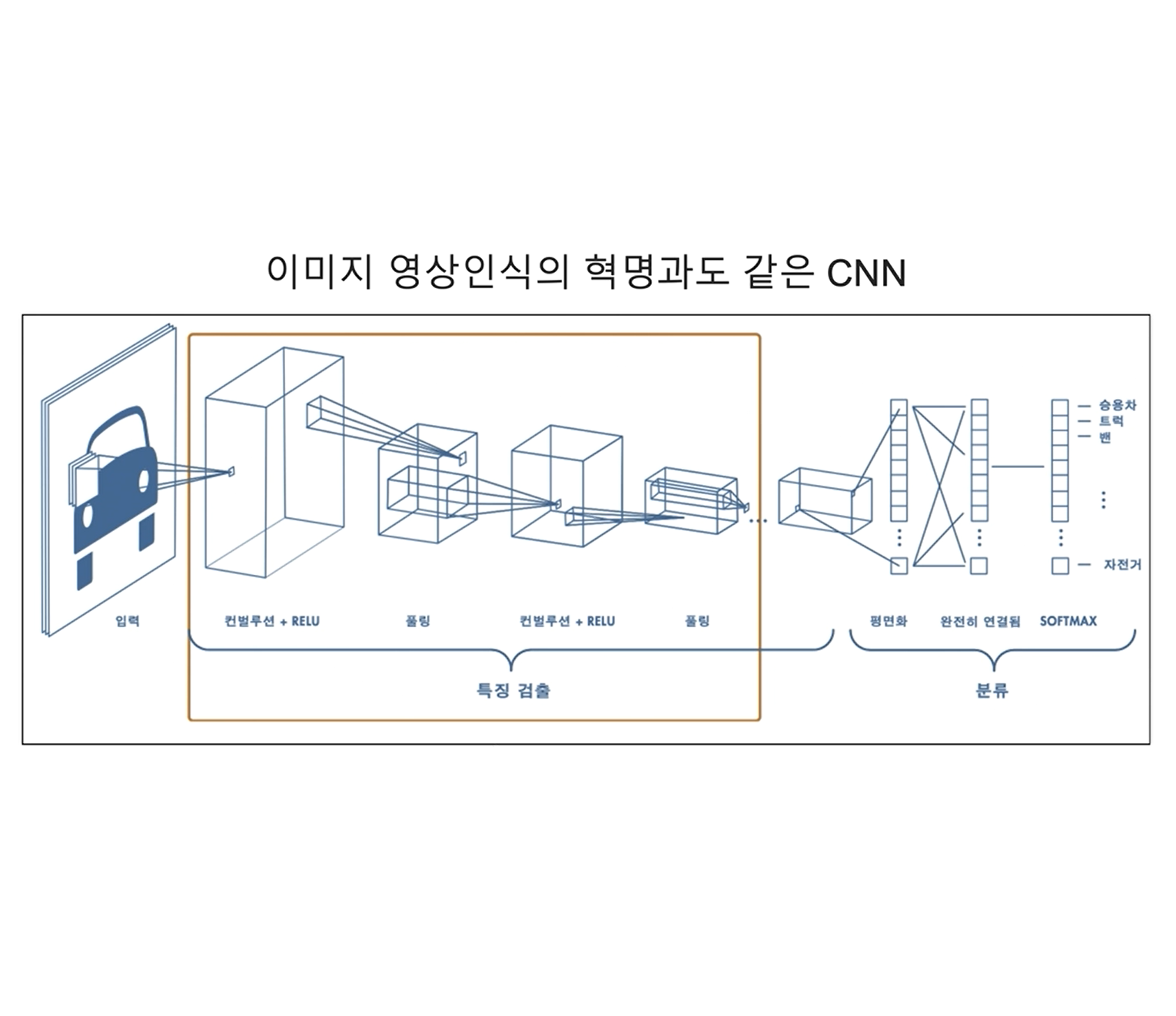
목표
CNN에 대해 이해해보자!
이 강의는 혁펜하임님의 'ALL DEEP DIVE' 강의를 기반으로 작성함
CNN은 어떻게 인간의 사고방식을 따라했을까?
CNN은 이미지나 동영상에서 물체를 구별하는데 잘 쓰이는 인공신경망 중 하나이다.
그렇다면 CNN은 어떤 방식으로 인간의 사고방식을 흉내냈을까?
-
신경 다발(Connections)을 잘 끊어냄
MLP에서는 FC Layer로 이미지를 구별하는데, 이것처럼 layer에 대해 모든 픽셀을 하나하나 따지는 것이 과연 인간이 이미지를 파악하는 방법일까?
MLP의 방식으로 하자면 모든 픽셀이 정해진 Connection이 있어 사진을 퍼즐처럼 쪼개서 흩뿌려놔도 어떤 사진인지 맞출 수 있을 것이다. 그러나 이것은 인간이 이미지를 구별하는 방법이 아니다..!
뇌과학에서 분석한 결과 우리가 이미지나 동영상을 보고 물체를 특징할 때, 뇌의 일부분만 활성화되었다는 결과가 있다. 그리고 실제로 이를 활용하여 사용한 것이 CNN이다! -
위치별 특징을 추출함
이는 위치 정보를 유지한 채, 특정 패턴(=특징)을 찾아낸다는 말이다.
간단하게 예시로 설명하자면, 갓 태어난 아기한테 강아지와 고양이를 구분하도록 하면 어떻게 구분할까? 애초에 강아지를 처음 봤으니 무엇이 눈이고.. 코이고.. 입인지.. 아무것도 알 수 없을 것이다. 따라서 아기들은 어떠한 패턴(큰 패턴 : 얼굴, 몸통, 다리 등 & 작은 패턴 : 눈, 코, 입 등)의 존재를 파악하고, 이들이 위치적인 관계(눈, 코, 입은 어디에 배치되며.. 얼굴, 몸통, 다리는 어떻게 배치되는지..)로 이루어짐을 알고 나서야 강아지와 고양이의 차이를 볼 수 있을 것이다..!
그리고 이는 머신도 똑같이 적용된다!!
컨볼루젼이라는 위치별 패턴을 찾는 연산을 신경망에 적용시켜 "내가 주는 사진은 어떠한 패턴이 존재하고, 이들이 어떠한 위치적인 관계를 이루고 있어!"라는 사전 정보를 알려주는 셈이다!
그 다음으로 구분하는 동작을 실행한다!
그렇다면 컨볼루젼이 무엇일까? 다음 그림들을 통해서 설명해보겠다.
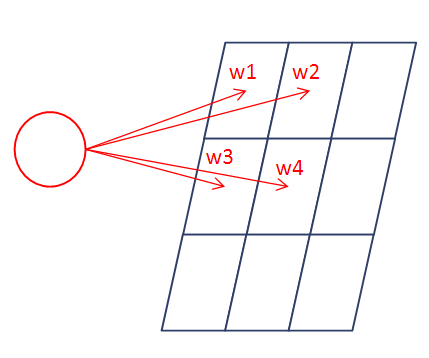 위의 그림을 보면 입력층에서 모든 connection을 한 것이 아니라 오른쪽과 아래는 끊어내고 연결한 모습을 볼 수 있다.
위의 그림을 보면 입력층에서 모든 connection을 한 것이 아니라 오른쪽과 아래는 끊어내고 연결한 모습을 볼 수 있다.
그리고 CNN에서 컨볼루젼은 아래와 같이 같은 weight set을 가지고 부분부분을 긁는다!
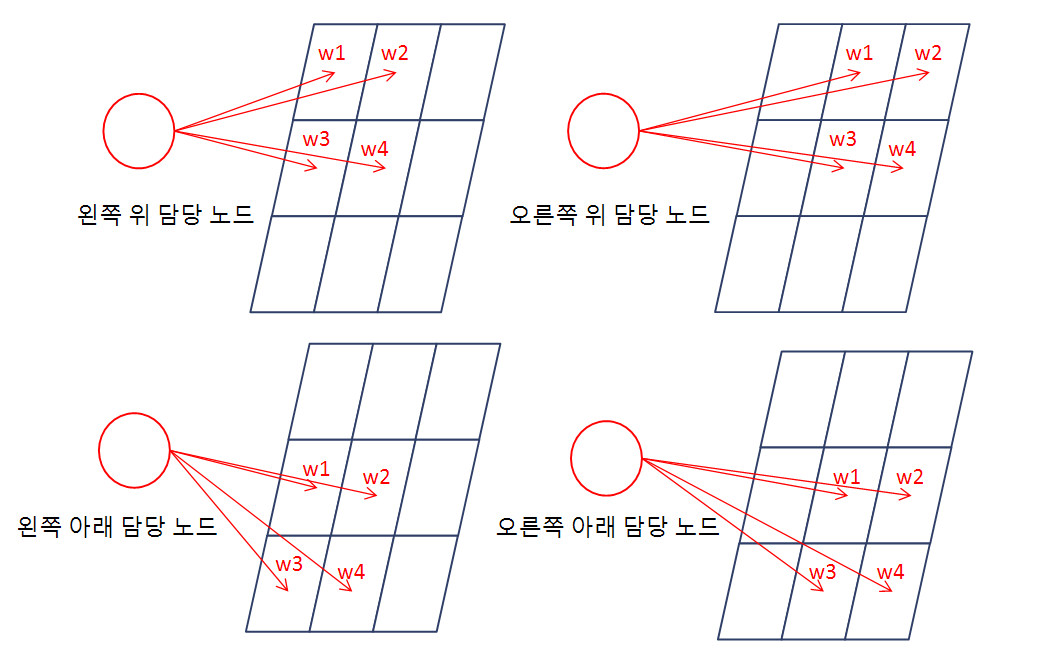 위와 같이 하면서 가까이 있는 것들을 연결하므로
위와 같이 하면서 가까이 있는 것들을 연결하므로
위치 정보를 잃지 않고, 마치 치환을 해준 것처럼 담당 노드라는 '새로운 의미'가 생긴다!!
여기서 이 담당 노드를 만드는 weight set을 커널 or 필터라고 부르며
( 물론 인공신경망이기에 bias도 포함하는데 이는 필터당 하나를 가져, 위의 경우 weight set은 가 된다!)
이렇게 부르기에 인공신경망에서 컨볼루젼은 필터링, 특징 추출이라고 보면 된다!!
수학적으로 컨볼루젼을 설명하자면..!
컨볼루젼은 '합성곱'이라고 부른다.
이는 하나의 함수와 또 다른 함수를 가지고 한 함수를 반전 이동한 값을 곱하고, 구간에 따라 적분하여 하나의 새로운 함수를 구하는 수학 연산자이다.
수학적 기호를 사용하면 다음과 같다.
간단히 말하자면 다음과 같다.
- 두 함수 중 하나를 좌우 반전시킨다.
서로 다른 방향에서 충돌하면서 일어나는 함수 개형을 보고 싶은 것이 합성곱이기 때문!- 를 움직이며 두 함수의 곱의 적분 값을 찾는다.
이를 예시와 함께 설명해보겠다.
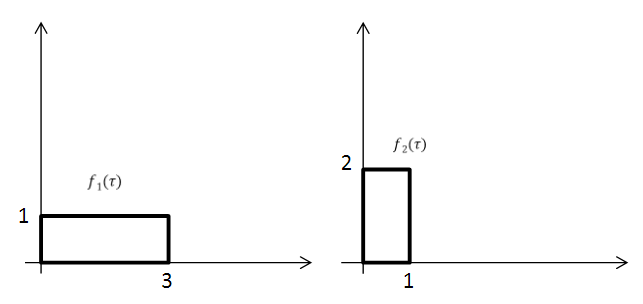 다음과 같이 두 함수가 있을 때, 이 중 한 함수를 좌우반전시킨다. (를 로)
다음과 같이 두 함수가 있을 때, 이 중 한 함수를 좌우반전시킨다. (를 로)
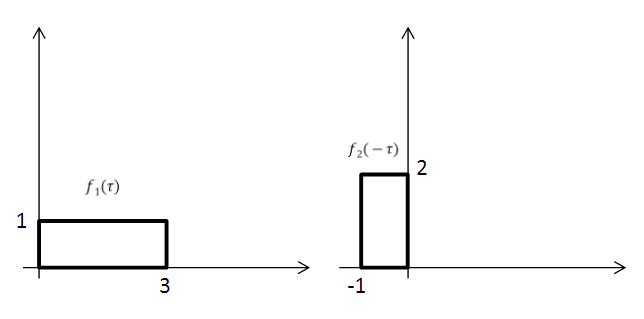 그리고 좌우 반전한 함수에 대해 를 더해가며 겹치는 부분의 곱의 적분값을 찾으면 된다.
그리고 좌우 반전한 함수에 대해 를 더해가며 겹치는 부분의 곱의 적분값을 찾으면 된다.
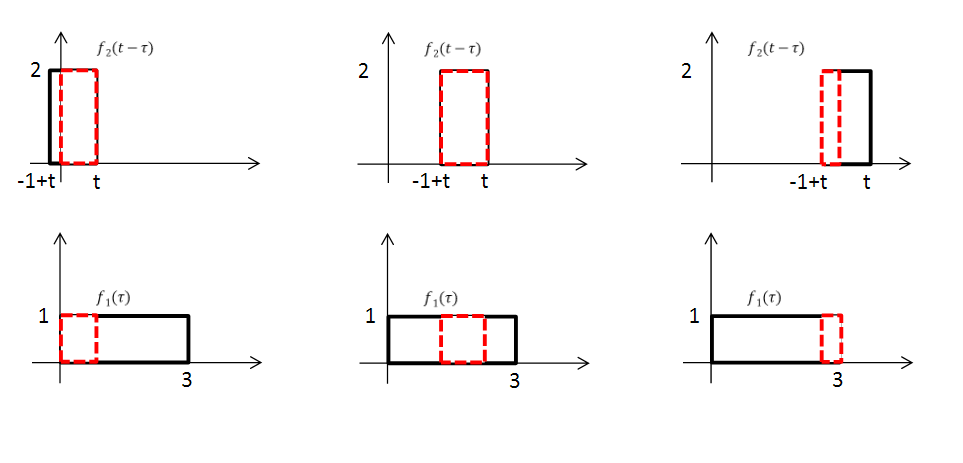
- : 겹치는 부분이 없음.
- :
- :
- :
- : 겹치는 부분이 없음.
따라서 위 두 함수에 대한 컨볼루젼은 다음과 같은 함수로 나온다.
 이렇게 컨볼루젼을 구하는 방법을 알았는데..! 이를 쓰는 효과가 무엇일지 보면 다음과 같다!
이렇게 컨볼루젼을 구하는 방법을 알았는데..! 이를 쓰는 효과가 무엇일지 보면 다음과 같다!
1. 미분 가능하지 않던 두 함수를 가지고 미분 가능한 함수 하나로 만들어줌.
2. 다양한 형태의 값을 활용한 필터로 활용! (이는 바로 다음 챕터에서 명료하게 다룬다!)
CNN이 특징을 추출하는 방법
컨볼루젼은 다음 그림처럼 패턴 매칭으로 쭉 스캔하면서 필터와 같은 패턴을 찾는다!!
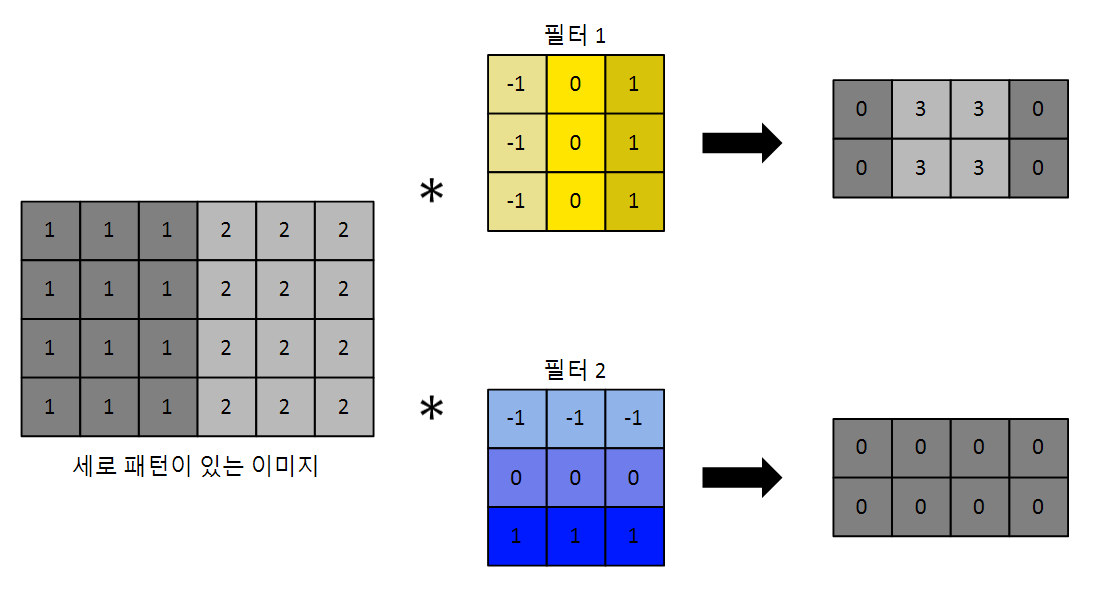 위에서 적힌 각각의 숫자들은 weight들이고, bias가 없다고 했을 때, 이 웨이트들을 합성곱(각각 자리에 있는 웨이트들끼리 곱하고 모든 값들을 더함.)하면 위의 오른쪽 두 그림처럼 나오게 된다!
위에서 적힌 각각의 숫자들은 weight들이고, bias가 없다고 했을 때, 이 웨이트들을 합성곱(각각 자리에 있는 웨이트들끼리 곱하고 모든 값들을 더함.)하면 위의 오른쪽 두 그림처럼 나오게 된다!
그리고 '필터 1'의 경우 세로 패턴을 보는 것이고, '필터 2'는 가로 패턴을 보는 것인데 위의 그림을 보면 '필터 1'을 통해 가운데 부분은 세로 패턴이 있음을 볼 수 있고, '필터 2'를 통해 가로 패턴이 없다는 것을 볼 수 있다.
즉, 보고자 하는 패턴(필터)가 어디에, 얼만큼 있나를 볼 수 있는 것이다!!
(필터와 유사한 웨이트 값의 형태를 보고 찾는 것.)
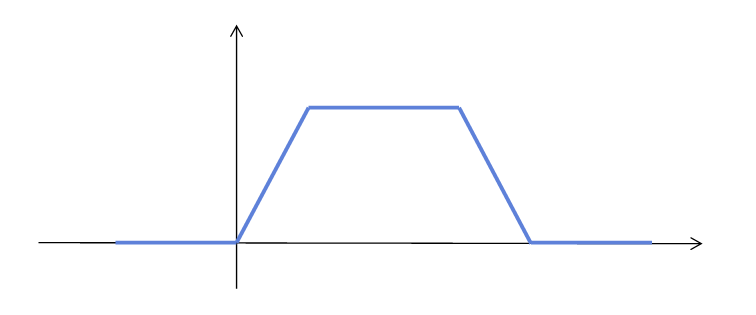
그리고 컨볼루젼은 특징을 뽑기도 하고, 이미지에 변형을 주기도 하는데 아래 그림처럼 이미지에 변형을 주는 것을 blur이라고 한다!
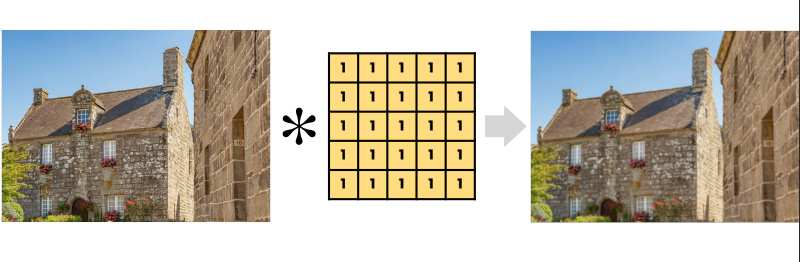 (출처 : 혁펜하임님의 강의)
(출처 : 혁펜하임님의 강의)
이렇게 컨볼루젼은 특징을 뽑는데, 어느 하나의 필터만 사용하는 것이 아닌 다양한 필터(세로 필터, 가로 필터, 대각선 필터.. 등등) 결과를 위치 정보를 유지한채로 사용한다!
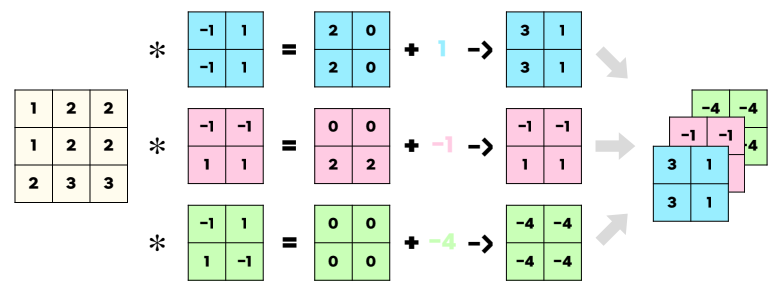 위처럼 각각의 컨볼루젼 결과를 깊이 축(=채널 축)으로 쌓는다. (이를 feature map이라고 한다.)
위처럼 각각의 컨볼루젼 결과를 깊이 축(=채널 축)으로 쌓는다. (이를 feature map이라고 한다.)
- conv layer가 FC layer과 다른 점
- conv layer는 주변만 연결한다! (신경망을 잘 끊어서 위치 정보를 잃지 않는다.)
- weight를 재사용한다. (쭉 나아가면서 스캔하기에 weight를 재사용하고, 내가 보고자 하는 패턴이 이미지의 어디에 있어도 찾을 수 있다!)
- 여러 종류의 필터로 여러 종류의 특징을 추출하는데, 이를 머신이 알아서 학습한다!!
(어떤 필터를 쓰는 것이 좋은 필터인지 알아서 고른다는 뜻!)
그리고 conv layer를 가지고 FC layer를 표현하면 다음과 같다.
예를 들어 100 x 100 입력 이미지를 FC layer로 하면 모든 connection이 있어야 하므로 필터가 100 x 100이다. 그리고 이러한 필터 종류 10개를 사용하는 conv layer는 10개의 FC layer와 동일하다!
CNN을 한마디로 표현하자면 곱하고 더하고 activation하던 신경망을 가지고 밀면서 특징을 뽑는 것이다!
3D 입력에 대한 Convolution
3D 입력에 대해 Convolution을 진행할시 standard convolution, depth-wise conv 등등 많은데..!
이 중 가장 표준이고 잘 헷갈리는 standard에 대해 알아보겠다.
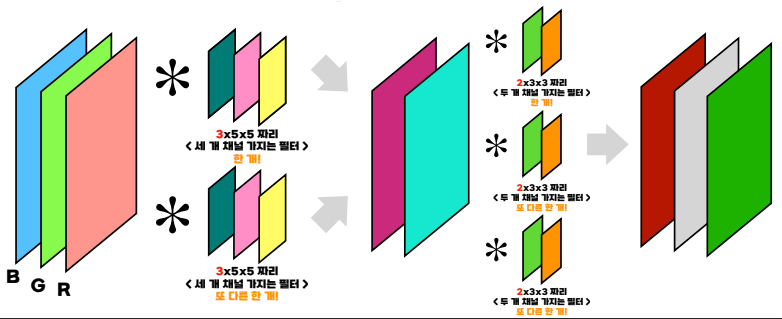 (출처 : 혁펜하임님의 ALL DEEP DIVE 강의 내용 중 하나)
(출처 : 혁펜하임님의 ALL DEEP DIVE 강의 내용 중 하나)
위의 그림을 보면 RGB 세 개의 채널을 가지는 3D 입력에 대해
필터는 무조건 앞의 채널 수에 맞춘 개수로 가지게 된다!!
그리고 입력값에 이 필터로 지나면 나오는 출력값은 한 개의 채널의 출력으로 나오게 된다!
위의 그림을 보았을 때, 3 x 5 x 5 짜리 필터 두 개를 사용하여 출력값으로 채널 2개를 만든 것을 볼 수 있다..!
그리고 layer가 하나가 아니기에 다음 layer도 conv layer로 진행할 시,
채널 2개에 대해 필터가 맞춰지므로 2 x 3 x 3으로 나오게 된 것이고, 이 필터 3개를 가지고 출력값으로 채널 3개를 만든 것을 볼 수 있다!!
간단히 요약하자면 입력값의 채널 수에 맞게 필터의 수를 가지고, 필터의 수에 맞게 입력값의 채널 수가 정해지는 것이다!!
[*] depth-wise convolution..?
depth-wise convolution은 필터의 채널에 대해 각각 따로 적용된 출력값이 나오게 되는 컨볼루젼이다! 위의 그림을 예시로 들자면 3 x 5 x 5 필터를 이용할 시, 이에 대한 출력값의 채널이 필터 각각의 채널에 대해 대응이 되어 3개가 나오게 된다!! (요즘엔 depth-wise convolution을 더 많이 쓴다고 한다..!)
[*] 필터가 1 x 1이면..?
one by one convolution으로 입력값의 채널들에 대해 웨이트합을 구해준다고 보면 된다!!
Padding & Stride & Pooling
- Padding
convolution을 할 때, 아래 그림처럼 필터를 적용하면 출력값은 크기가 줄어들게 된다.
여기서 출력값의 크기를 유지하거나 덜 줄어들게 만드는 것이 Padding이다.
보통의 Padding 사용은 가장자리에 0을 추가해서 크기를 유지하는 것을 목적으로 사용한다.
이 때, 가장자리 값은 좋은 출력값으로 나오지 않더라도 크기를 유지하는 것에 중점으로 사용한다!
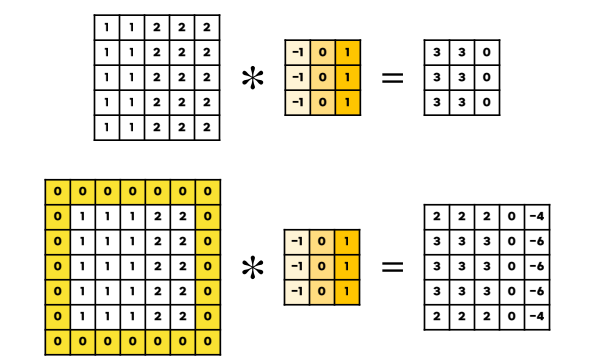 (출처 : 혁펜하임님의 강의)
(출처 : 혁펜하임님의 강의)
- Stride
Stride는 우리가 지금까지 한칸씩 필터를 이동하였는데, 이것은 Stride를 (1,1)로 잡은 것이고
내가 이동하고 싶은 걸음 수를 표현하는 것이 Stride이다!! Stride는 다음과 같이 확인할 수 있다.
Stride = (2, 2) 행으로 갈 때 2칸씩, 열로 갈 때 2칸씩 이동한다는 뜻!
(위에서 보면 Stride = (2,1)도 가능하지만, 보통 둘이 숫자를 맞춘다.)
- Pooling
Pooling은 Convolution에 자주 쓰이는 기법인데, 값의 사이즈를 줄여 넓은 범위를 대표할 수 있는 대푯값으로 채우는 것이다! (파라미터가 필요 없다!!)
(Ex : Max Pooling , Average Pooling 등등..)
예시로 size = (2, 2), Stride = (2, 2) ( 이 두 값은 hyperparameter! )인 필터를 가지고 각각하면 다음과 같다.
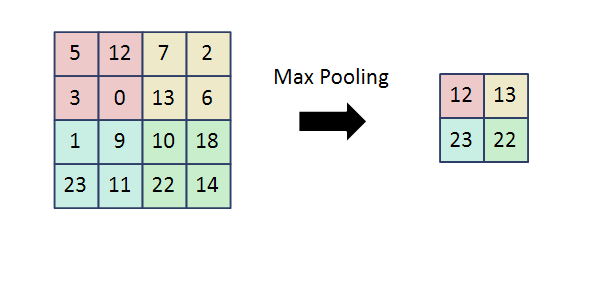 Max Pooling은 대푯값으로 가장 큰 값을 가지고 크기를 줄인다!
Max Pooling은 대푯값으로 가장 큰 값을 가지고 크기를 줄인다!
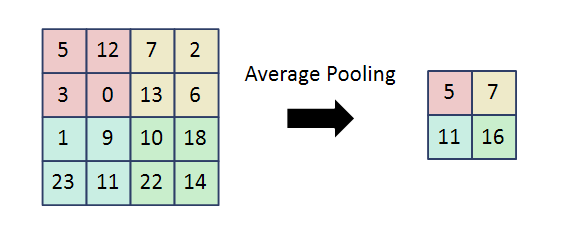 Average Pooling은 대푯값으로 평균을 가지고 크기를 줄인다!
Average Pooling은 대푯값으로 평균을 가지고 크기를 줄인다!
Pooling의 특징은 입력값의 채널의 수에 맞춰서 각 채널마다 적용해 채널의 수가 유지된다는 것이다.
(3개의 채널을 가지고 Pooling을 하면 그대로 채널 3개를 가지고 나온다!)
[*] 만약 위의 그림에서 size = (4, 4) ( = 이미지 사이즈 )로 Pooling을 하면?
이는 GAP(Global Average Pooling)으로 전체 이미지 사이즈를 하나의 대푯값으로 줄이는 것을 말한다!!
실제 CNN으로 Feature Map 만드는 과정
실제 사용을 할 때, Convolution과 Pooling을 반복하며 어느 한 부분을 특정하는 값들만 남기고 이를 가지고 이미지를 구별한다!
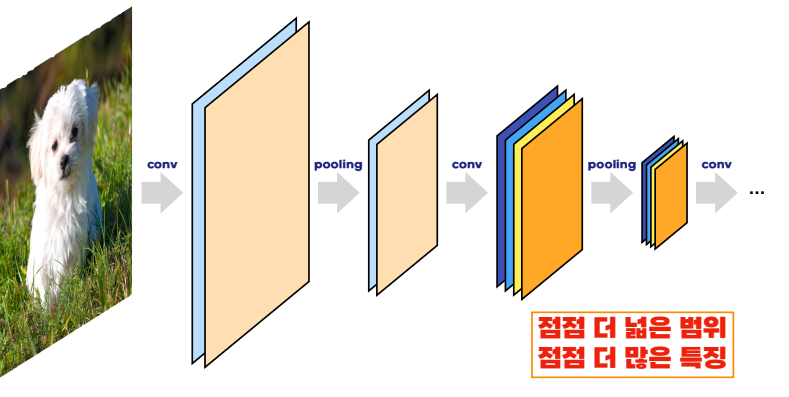 (출처 : 혁펜하임님의 ALL DEEP DIVE 강의 내용 중 일부분)
(출처 : 혁펜하임님의 ALL DEEP DIVE 강의 내용 중 일부분)
위와 같이 conv와 pooling을 반복하며
점점 더 넓은 범위를 대표하는 픽셀로 만들고,
점점 더 많은 특징을 쌓아간다!
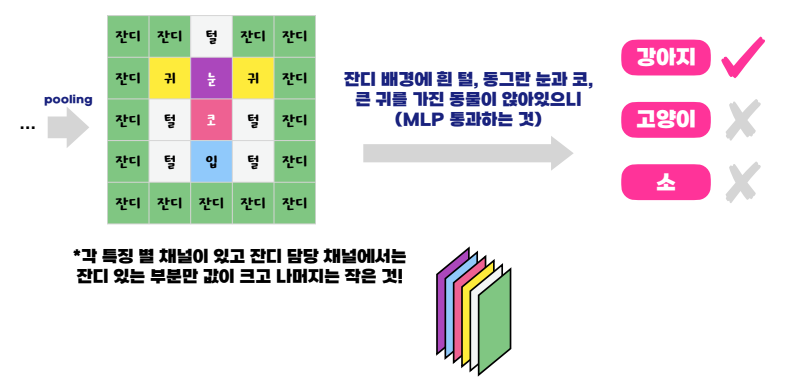 (출처 : 혁펜하임님의 ALL DEEP DIVE 강의 내용 중 일부분)
(출처 : 혁펜하임님의 ALL DEEP DIVE 강의 내용 중 일부분)
그리고 위처럼 대표하는 값들이 무엇을 나타내는지 확인을 한다.
(사실 머신은 이것이 잔디이다.. 귀다.. 눈이다... 이렇게 판단하는 것이 아니라 그냥 최적화를 하다보니 이런 특징을 나타내는 한 채널로 발전하게 된 것이다..!)
그 다음으로 MLP를 통과하여 분류를 하는 것을 진행한다!
VGGnet
VGGnet은 이미지 인식 부분에서 아주아주 유명한 모델이다!
이제 이 모델도 우리가 해석할 수 있기에 차근차근 해석해보겠다.
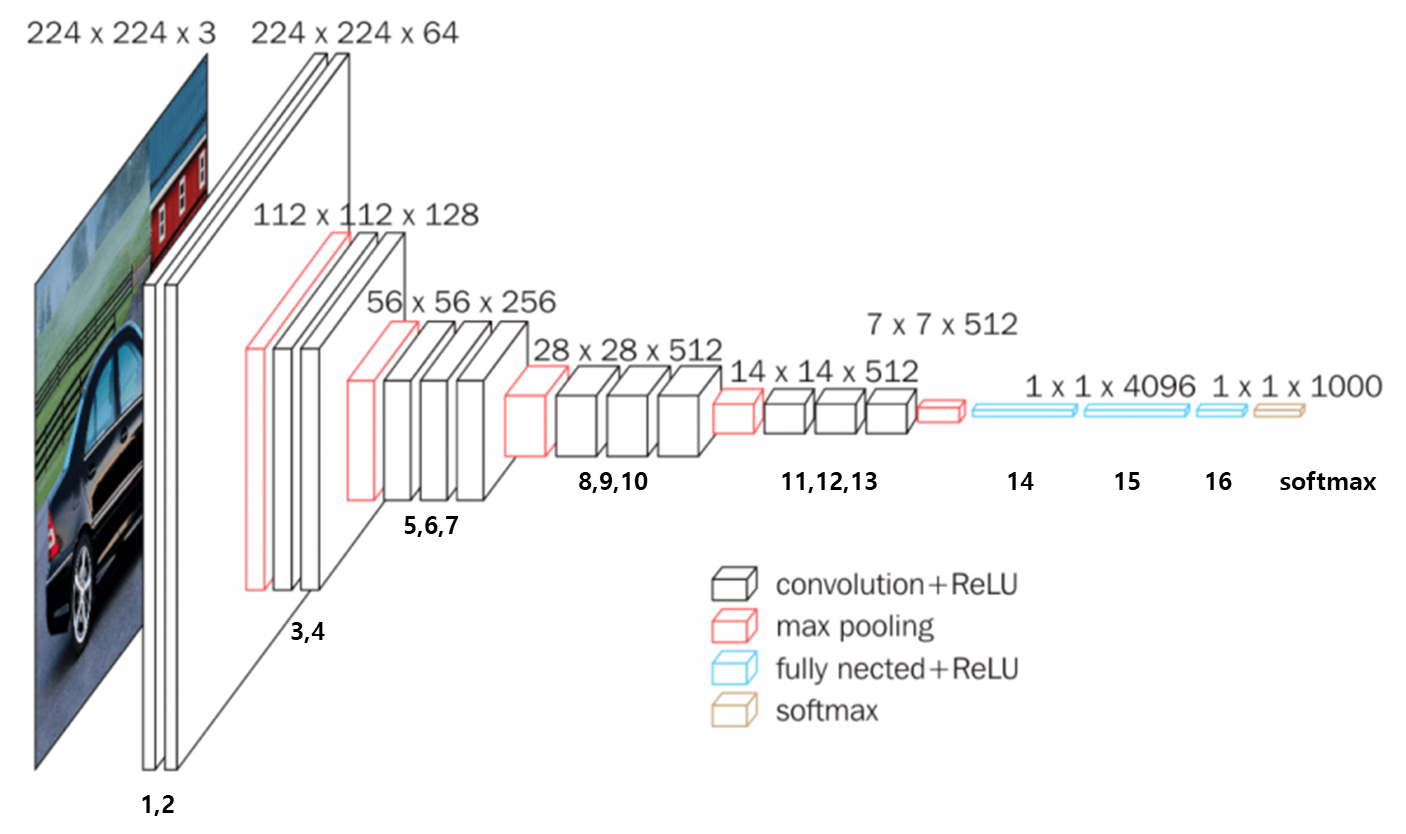 위의 이미지 인식 방법이 바로 VGGnet인데, 딱 봐도 우리가 지금까지 배운 내용으로 구성되어있음을 알 수 있다!!
위의 이미지 인식 방법이 바로 VGGnet인데, 딱 봐도 우리가 지금까지 배운 내용으로 구성되어있음을 알 수 있다!!
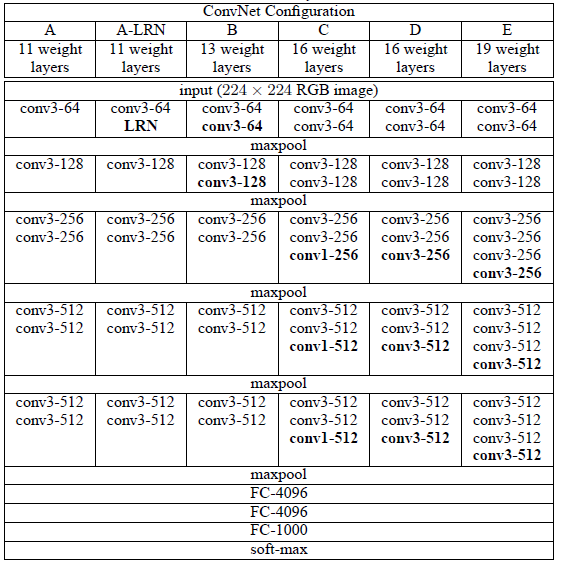 그리고 위의 표는 VGGnet의 구성 단계를 표로 나타낸 것이다.
그리고 위의 표는 VGGnet의 구성 단계를 표로 나타낸 것이다.
이제부터 이 표 중에 D구조(16개의 layer들로 이루어짐.)를 중심으로 천천히 해석해보겠다.
- Input layer
Input layer로는 3 x 224 x 224 (3은 RGB)의 이미지로 받을 수 있다. - 1st layer
conv3-64라고 되어있는데, 이는 conv layer로 3 x 3 x 3 필터 64개(64 x 3 x 3 x 3)를 가지고 컨볼루젼을 한다는 의미이고, 보통 stride = (1, 1), zero padding = 1로 해서 컨볼루젼을 진행해준다!
그리고 conv layer를 한 뒤에 ReLU를 사용해 Vanishing Gradient를 막아주고자 하였다.
1st layer를 지나면서 64 x 224 x 224로 출력값이 나오게 된다. - 2st layer
conv3-64를 진행해 64 x 64 x 3 x 3의 필터로 64 x 224 x 224로 출력값이 나오게 되고,
그 뒤에 maxpooling(2)을 진행해 64 x 112 x 112로 줄여주었다! (pooling은 채널 수 변화 x) - 3st layer
conv3-128이므로 128 x 64 x 3 x 3의 필터로 128 x 112 x 112의 출력값이 나오게 된다. - 4st layer
conv3-128이므로 128 x 128 x 3 x 3의 필터로 128 x 112 x 112의 출력값이 나온다.
그리고 maxpooling(2)를 진행해 128 x 56 x 56으로 줄어들게 된다! - 5st layer
conv3-256이므로 256 x 128 x 3 x 3의 필터로 256 x 56 x 56의 출력값이 나온다. - 6st, 7st layer
conv3-256으로 256 x 256 x 3 x 3의 필터로 256 x 56 x 56의 출력값이 나온다.
그리고 7st layer 후에 maxpooling(2)로 256 x 28 x 28이 된다. - 8st layer
conv3-512로 512 x 256 x 3 x 3의 필터로 512 x 28 x 28의 출력값이 나온다. - 9st, 10st layer
conv3-512로 512 x 512 x 3 x 3의 필터로 512 x 28 x 28의 출력값이 나온다.
그리고 10st layer 후에 maxpooling(2)로 512 x 14 x 14가 된다. - 11st , 12st, 13st layer
conv3-512로 512 x 512 x 3 x 3의 필터로 512 x 14 x 14의 출력값이 나온다.
그리고 13st layer 후에 maxpooling(2)로 512 x 7 x 7이 된다. - 14st layer
FC-4096으로 되어있는데, 이는 FC layer로 4096개의 노드를 모두 연결해주는 것을 의미한다.
이 때, 512 x 7 x 7의 feature map을 flatten하게 펴줘서 1차원 벡터로 만들어 연결해준다.
이를 통해 512 x 7 x 7개의 노드와 4096개의 노드가 FC하게 된다!
(이 FC가 전체 웨이트의 90퍼 정도를 차지한다..ㅎㄷㄷ) - 15st layer
FC-4096이므로 4096개의 노드와 4096개의 노드를 FC layer로 연결한다.
이 때, 훈련시 dropout을 하게 된다! - 16st layer
FC-1000이므로 4096개의 노드와 1000개의 노드를 FC layer로 연결한다.
출력값들은 softmax 함수로 활성화가 된다!
여기서 1000개인 이유는 1000개의 클래스로 분류한다는 목적이기 때문이다.
[*] 왜 3 x 3의 필터를 사용할까?
3 x 3 필터가 3개이면 웨이트가 총 27개를 가진다. 이렇게 되었을 때, 더 큰 필터보다 학습 속도가 빨라지게 된다. 그리고 동시에 층의 개수가 늘어가서 특성에 비선형성을 증가시키기에 특성이 더 유용하게 쓰이게 된다!
Beautiful Insight for CNN
이 부분에선 CNN에 대해 정리해보겠다!!
- 왜 CNN을 쓰는가?
FC layer와 다르게 적은 수의 weight를 가지고 위치별 특징을 추출할 수 있기 때문!
그리고 Convolution을 사용함으로써 위치별로 어떠한 특징을 가지고 있다는 사전 정보를 준 셈이기에 효율적인 이미지 구별이 가능하다!
CNN을 통과하면서 그 패턴들이 곱하고 (무엇이 더 중요한 특징인지?) 합해진다! (low -> high level feature)
- 여러번 conv layer를 통과하는 이유?
이는 receptive field가 넓어지기 때문이다!
receptive field란 "한 픽셀을 결정하는데 참고한 노드가 어느 정도가 되는가?" 라는 의미인데, 3 x 3 필터를 두 번 반복하게 되면 한 픽셀에 대해 3 x 3으로 필터를 보고 이 3 x 3의 범위를 보는데 3 x 3 필터를 반복하기에 5 x 5의 범위를 참고하여 한 픽셀이 결정되었다고 볼 수 있다!!
- 그렇다면 그냥 3 x 3 필터 두 번 하는 것보다 5 x 5로 한 번 하는게 낫지 않을까..?
세 가지 측면에서 봤을 때, 그냥 3 x 3 필터로 두 번 하는 것이 더 효율적이라고 볼 수 있다!
첫 번째로 파라미터 수, 5 x 5 필터로 하면 웨이트가 25개이고 3 x 3 필터로 두 번 하면 3 x 3 x 2로 웨이트가 18개이다. 웨이트가 적을수록 학습 속도가 빠르기에 3 x 3 필터 두 번이 낫다.
두 번째로 비선형성, conv layer도 다른 신경망처럼 활성화함수를 지나게 된다. 3 x 3 필터로 두 번 지나가면 활성화함수를 두 번 지나기에 비선형성이 더 증가한다고 볼 수 있다!!
세 번쨰로 집중도, 5 x 5 필터로 한 픽셀을 결정할 시 25개의 픽셀의 범위가 동등한 입장으로 한 픽셀을 결정하게 된다. 그러나 3 x 3 필터로 두 번 할시에 한 필터를 결정하는데 25개의 픽셀의 범위 중에서 그 픽셀의 가운데 부분인 9개의 픽셀의 범위는 두 번 보게 된다. 그러므로 한 픽셀을 결정하는 집중도가 차이가 있어 더욱 특성을 잘 파악할 수 있게 된다!!
결국, CNN을 쭉 통과하면 테두리보단 중심을 더 집중해서 보게 되고 이는 인간의 이미지 인식 방식과 닮아있는 부분이다!!
- conv, pooling을 쭉 통과한 다음 마지막엔 MLP를 진행하는 이유는?
위에서 말했듯이 CNN은 테두리보단 중심을 더 보게 되는 경향이 있다.
(이는 Padding을 한다고 해도 마찬가지..)
하지만 이미지에는 중심에만 중요한 내용이 있는 것이 아니기 때문에
나중에는 각 영역별 특징을 싹 다 보고 결정을 해줘야한다! (정제된 특징)
예를 들어 물 속에 있는 강아지를 본다고 하면 이 이미지를 강아지라고 판별해도 물 속에 강아지가 있는 것이 사실상 말이 안 된다. 그러므로 테두리까지 보게 되면 이를 물개라고 판별할 수 있을 것이다.
- max-pooling을 너무 많이 한다면?
공간적인 정보를 너무 많이 잃게 된다..!
만약 VGGnet에서 512 x 7 x 7이 아니라 512 x 2 x 2까지 줄이게 되었다면 그냥 왼쪽 위에는 이렇게 생겼고.. 오른쪽 아래는 이렇게 생겼고.. 이런 정보밖에 얻을 수 없을 것이다.
즉, "해당 정보가 어디에 있는가?"에서 어디에가 너무 뭉뚱그려져서 CNN의 장점을 잃게 된다!
- CNN을 한마디로 표현하자면?
CNN은 Connection을 어떻게 할지 고민한 것이다. (이는 사전 정보를 신경망에 심는 방법 중 하나이다!)
그리고 위치적으로 가까운 노드를 먼저 조합하고 그 다음 layer는 조합된 정보를 가지고 조합하기에
멀리 있는 정보는 뭉뚱그려서 (정제해서) 조합하게 된다!!
요약
- CNN은 FC layer와 다르게 weight를 한정적이게 쓰고 위치별 특징 정보를 추출한다!
- 3D 입력에 대해 conv에서 필터는 무조건 앞의 채널 수에 맞춘 개수로 가지게 된다! (중요)
- Padding은 테두리에 0을 넣어 크기 유지하는 것이다.
- stride는 내가 필터를 미는데 어느 정도의 세기로 미는지에 대한 것이다.
- pooling은 파라미터를 사용하지 않고 대푯값을 설정하면서 크기를 줄이는 것이다.
- CNN은 보통 conv, pooling으로 feature map을 구성하고 MLP로 분류를 진행한다!
- CNN은 Connection을 어떻게 할지 고민한 것이다. (사전 정보를 신경망에 심는 방법 중 하나)
- CNN은 conv를 여러 번 진행하면서 멀리 있는 정보를 뭉뚱그려서 조합하게 된다는 특징이 있다!
