
목표
딥러닝계의 Legend 논문(이론) 중 혁신적인 논문 중 하나인 DenseNet에 대해 배워보자!
이 내용은 혁펜하임님의 'Legend 13' 강의를 기반으로 작성함.
이 내용은 전 작성 내용과 이어집니다.
DenseNet
ResNet의 skip-connection은 정보의 일정한 흐름을 '보존'하며 층을 깊게 쌓아도 정보가 원활하게 전달되도록 한다.
하지만, skip-connection은 이전의 값인 와 잔차 의 값의 차이가 클 때에도 덧셈 방식으로 진행하기에 정보의 흐름을 유지해준다는 의미가 퇴색될 수 있다.
즉, 정보의 흐름이 지연되면서 정보가 뭉개지는 일이 발생할 수 있다는 비판이 있다.
여기에 DenseNet은 정보의 흐름을 유지하는 방법으로 덧셈이 아닌 concat! 즉, 이전의 feature map들을 모두 사용하는 방법을 제시하였다!
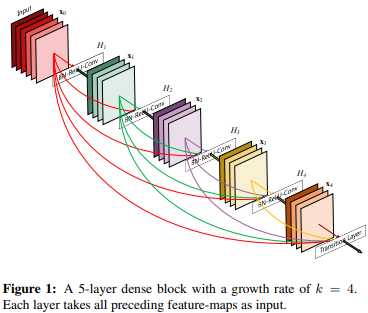
(논문 : https://arxiv.org/pdf/1608.06993)
위와 같은 방법을 ResNet의 가장 최근 연구인 full pre-activation을 사용하며 진행하였다!
concat으로 인한 파라미터 수 문제
위의 방식을 사용하면 이전의 정보 흐름을 놓칠 일은 없다는 점에서 좋지만, concat을 계속 하기에 파라미터 수가 너무 많아질 수 있다는 단점이 있다..!
그러기에 DenseNet은 growth rate 를 32로 고정하여 concat시에 개씩 채널 수가 누적되도록 하였다!!
(위의 그림에선 로 4개씩 누적되어 총 22개의 채널 수로 되는 것을 볼 수 있다.)
이렇게 를 고정시켜서 하면 파라미터 수를 일정하게 유지할 수 있을 뿐만 아니라 각 concat마다 특징을 딱 개만 뽑아내기에 새로운 정보의 양을 규제하는 효과를 낼 수 있다!!
즉, 전에 있던 layer에 있던 정보를 또 뽑는 것은 정보 흐름을 유지한다는 것에 어긋나기에 꼭 필요한 특징만 뽑는다는 것이다!!
concat으로 인한 사이즈 문제
concat시에 파라미터 수 문제도 있었지만, CNN 구조상 feature map의 size를 줄여야 성능이 좋아지는데, 계속 크기가 커진다는 문제도 있다.
이에 DenseNet은 Dense Block을 진행하는 가운데, 채널 수와 사이즈를 반으로 줄이는 Transition Layer를 가진다!
Transition Layer에선 BN, 1 X 1 conv, 2 X 2 pooling을 진행한다!
 위의 그림을 보면 3개의 Dense Block 사이에 2개의 Transition Layer를 진행하는 것을 볼 수 있다.
위의 그림을 보면 3개의 Dense Block 사이에 2개의 Transition Layer를 진행하는 것을 볼 수 있다.
Bottleneck Layer
위의 그림에서 채널 수는 6 4, 10 4, 14 4, 18 4 이렇게 진행이 된다. 이 경우에 각 concat을 진행할 때마다 확 줄어드는 병목 현상이 점점 커지게 된다.
그러기에 DenseNet Layer는 Bottleneck Layer를 사용하는데, 아래 그림처럼 (입력 채널 수) (1 X 1 conv, ) (3 X 3 conv, )로 진행하게 된다.
이 경우에 점진적으로 떨구기에 병목 현상도 완화하고 파라미터 개수도 절약할 수 있다고 한다.
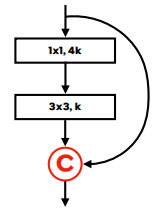 다만 내 생각에 6 4와 같은 Dense Block의 초기 단계에선 병목 현상이 거의 일어나지 않는데, 6 16 4 이렇게 가버리면 불필요한 파라미터 수도 증가하고 전보다 병목 현상이 심해진다..
다만 내 생각에 6 4와 같은 Dense Block의 초기 단계에선 병목 현상이 거의 일어나지 않는데, 6 16 4 이렇게 가버리면 불필요한 파라미터 수도 증가하고 전보다 병목 현상이 심해진다..
그러므로 입력 채널 수가 보다 이하인 경우 Bottleneck Layer를 진행하지 않는 것이 더 효율적이라고 생각한다..!
(논문에선 의 를 hyperparameter라고 하기에 더 좋은 성능을 가지는 상황에 맞춰서 바꾸는 것이 좋아보인다!)
DenseNet 전체 구조
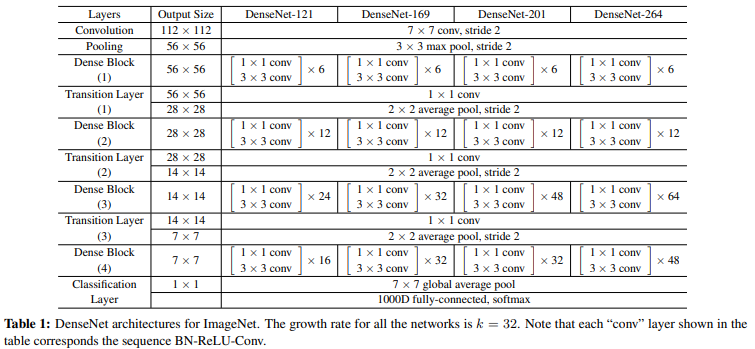 , 첫 conv에선 필터 2k개로 사용하였다.
, 첫 conv에선 필터 2k개로 사용하였다.
이에 따라 feature map의 개수 추이는 다음과 같은 흐름으로 바뀌게 된다. (DenseNet-121 기준)
DenseNet이 레전드인 이유
- ResNet의 skip-connection이 덧셈 연산으로 진행되어 정보가 뭉개질 수 있다는 문제에 concat을 하는 방식을 채용하여 해소하고자 하였다!!
- concat으로 파라미터, 사이즈가 많아지는 문제를 Transition Layer와 BottleNeck Layer로 해소하였다!
