
목표
딥러닝계의 Legend 논문(이론) 중 혁신적인 논문 중 하나인 MobileNet에 대해 배워보자!
이 내용은 혁펜하임님의 'Legend 13' 강의를 기반으로 작성함.
이 내용은 전 작성 내용과 이어집니다.
MobileNet V1
MobileNet은 모델을 Mobile 기기에 넣어도 될 정도로 가볍지만 성능은 유지하는 그러한 모델을 만들기 위한 과정에서 나온 논문이다.
(논문 : https://arxiv.org/pdf/1704.04861)
MobileNet V1에서의 모델을 가볍게 하기 위한 획기적인 방안은 Depthwise separable conv를 사용한 것이다!
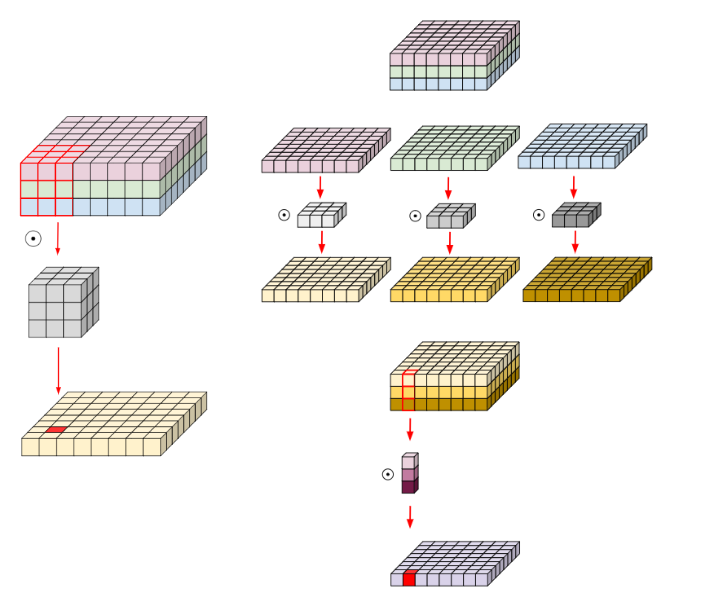
Depthwise separable conv란 Depthwise Conv를 진행하고 Pointwise Conv를 진행한 것을 통틀어서 말하는데, 이를 위의 그림으로 설명하면 다음과 같다.
3 X 3 conv에 대해 왼쪽 그림과 같이 공간적인 측면과 채널 축까지 정보를 합쳐서 계산하면 nn.Conv2d(3,16,3)으로 weight shape은 16 x 3 x 3 x 3이 나온다.
하지만 오른쪽처럼 각 입력 채널에 대해 3 x 3 conv 하나의 필터가 연산을 진행해 하나의 feature map을 생성하고 (Depthwise Conv), 그 뒤로 생성된 feature maps를 1 x 1 conv로 합치면 (Pointwise Conv) weight shape는 3 x 3 / 3 x 3 x 3 + 16 x 3 x 1 x1로 나오게 된다!
이는 왼쪽 그림의 방법보다 무려 6배나 파라미터가 줄어든 것이 된다!!
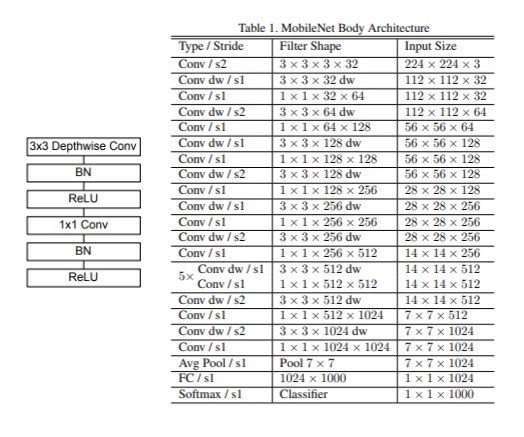 전체 구조는 위의 그림과 같은데, 처음 Conv를 제외하고 두 개씩 짝지어서 DepSepConv를 진행한다.
전체 구조는 위의 그림과 같은데, 처음 Conv를 제외하고 두 개씩 짝지어서 DepSepConv를 진행한다.
그리고 Stride = 2인 채널에서 down sampling을 진행한다.
(마지막 쪽에 7 x 7 x 1024 부분의 s2는 s1인데 오타난 것이다..!)
또 다른 특징으로 파라미터 수가 많지 않기에 regularization 및 data augmentation을 소극적으로 적용했다는 것이다!
여러 성능 비교
- 파라미터 수 비교
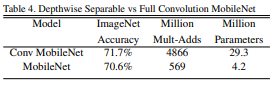 그냥 Conv와 비교한 결과, Accuracy의 차이에 비해 파라미터 수의 차이는 7배나 차이 나는 것을 볼 수 있다!
그냥 Conv와 비교한 결과, Accuracy의 차이에 비해 파라미터 수의 차이는 7배나 차이 나는 것을 볼 수 있다! - Narrow vs Shallow
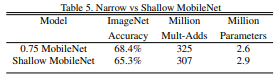 Narrow는 MobileNet에 = 0.75 (width multiplier로 입출력 채널에 를 곱해 크기를 줄이는 역할이다.)를 적용한 것이고, Shallow는 전체 구조에서 5번 반복되는 부분을 삭제한 것이다.
Narrow는 MobileNet에 = 0.75 (width multiplier로 입출력 채널에 를 곱해 크기를 줄이는 역할이다.)를 적용한 것이고, Shallow는 전체 구조에서 5번 반복되는 부분을 삭제한 것이다.
둘이 비슷한 파라미터라고 보았을 때, 깊이를 줄이는 것이 더 critical한 정확도 감소를 보여준다. - width multiplier
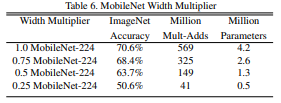 는 1.0일 때 가장 성능은 좋았지만, 논문에선 파라미터를 줄이는 측면까지 생각하여 0.75로 두었다!
는 1.0일 때 가장 성능은 좋았지만, 논문에선 파라미터를 줄이는 측면까지 생각하여 0.75로 두었다! - resolution multiplier
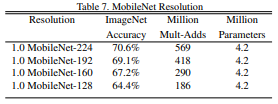 는 해상도를 말하며 해상도의 경우, 높을수록 더 accuracy가 높은 모습을 보인다!
는 해상도를 말하며 해상도의 경우, 높을수록 더 accuracy가 높은 모습을 보인다!
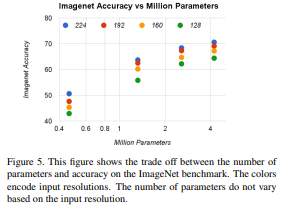 또한, 해상도는 파라미터 수를 증가시키진 않지만, 연산량이 증가하는 모습을 보여준다!
또한, 해상도는 파라미터 수를 증가시키진 않지만, 연산량이 증가하는 모습을 보여준다! - 다른 모델과의 비교
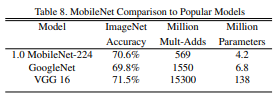 다른 모델과 비교해도 정확도도 높고, 특히! 파라미터 수와 연산량이 압도적으로 낮은 것을 볼 수 있다!!
다른 모델과 비교해도 정확도도 높고, 특히! 파라미터 수와 연산량이 압도적으로 낮은 것을 볼 수 있다!!
MobileNet V1이 레전드인 이유
- 기존부터 존재하던 Depthwise separable conv를 사용하여 파라미터 수와 연산량을 압도적으로 낮게 줄였다.
- width multiplier 와 resolution multiplier 를 하이퍼파라미터로서 조절하여 모델의 효율을 더 늘렸다!
MobileNet V2
앞서 설명한 MobileNet V1은 Depthwise Separable Conv를 이용하여 모델 경량화를 한 것이었고, MobileNet V2는 'ReLU의 효율적 배치'를 목적으로 모델 경량화를 진행한다!
활성화 함수인 ReLU는 비선형성을 위해 필요하나, 음수 쪽에서 정보 손실을 야기한다는 특징이 있다.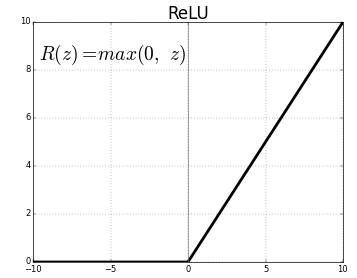 규모가 큰 모델 내에서는 쓸 수 있는 자원이 많기에 ReLU 정도의 정보 손실은 그냥 넘어갈 수 있지만, 경량화를 하는 입장에서는 이러한 정보 손실 또한 치명적으로 다가온다.
규모가 큰 모델 내에서는 쓸 수 있는 자원이 많기에 ReLU 정도의 정보 손실은 그냥 넘어갈 수 있지만, 경량화를 하는 입장에서는 이러한 정보 손실 또한 치명적으로 다가온다.
심지어 ResNet의 Bottlenect의 경우, 채널 수가 작아지고 ReLU를 진행하기에 더더욱 큰 정보 손실을 야기한다.
하지만 다행인 점은 ReLU를 쓰더라도 dim이 크면 정보 손실을 줄일 수 있다는 특징이 있다..!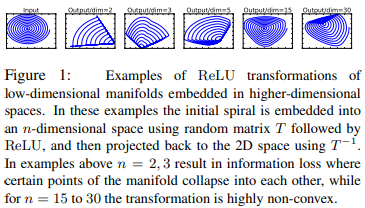 이에 MobileNet V2는 위 특징을 사용하여 Inverted BottleNect 구조를 사용한다!
이에 MobileNet V2는 위 특징을 사용하여 Inverted BottleNect 구조를 사용한다!
Inverted Residual Block
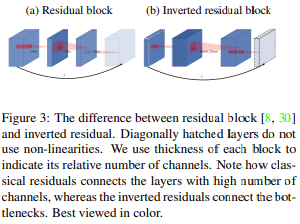
(논문 : https://arxiv.org/pdf/1801.04381)
Inverted BottleNect은 오히려 BottleNect에서 차원을 키우자는 것인데, 이것이 가능했던 이유는 DepSepConv가 아주아주 가벼웠기 때문이다!
(만약 다른 모델이었다면 파라미터가 너무너무 많아진다..!)
하지만 여기엔 두 가지 해결해야 될 문제점이 있다.
첫번째는 dim을 계속 늘리는 것은 좋은데 계속 늘리기만 하면 파라미터 수가 결국은 너무 많아지고 깊게 모델을 만들지 못한다는 것이고,
두번째는 계속 dim을 키우면 (실선) skip-connection을 사용하지 못한다는 것이다.
(in_c = out_c 이어야 사용 가능)
그래서 채널 수를 다시 줄이는데, 여기서 ReLU까지 쓰면 정보가 너무 많이 손실이 일어난다..!
그러기에 채널 수를 줄일 때에는 그냥 통과시킨다..! (linear activation)
물론 이 방법이 비선형성이 떨어지는 것은 맞지만, 정보 손실은 줄일 수 있다는 장점이 있는 것이다!!
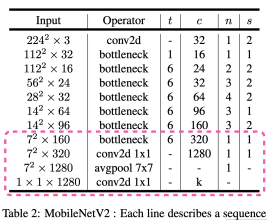
전체 구조
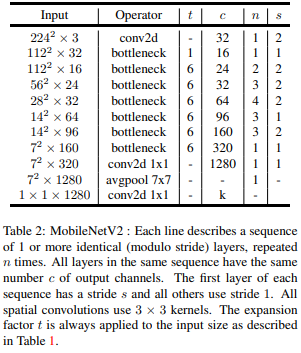 전체 구조는 아래 그림처럼 bottlenect 구조를 사용하는 식으로 전개가 된다.
전체 구조는 아래 그림처럼 bottlenect 구조를 사용하는 식으로 전개가 된다.
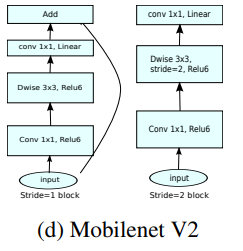
일단, t=1인 부분은 위의 왼쪽 그림에서 앞의 1 x 1 conv를 제외한 DepSepconv이다.
s=1이면서 in_c = out_c일 때에 skip-connection을 사용해준다.
그리고 s=2인 부분은 Dwise로 하나씩 계산하는 부분에서 진행한다.
ReLU의 경우 8-bit 양자화에 특화되며, 0~6 사이의 bound를 가져 안정적인 ReLU6를 사용하였다!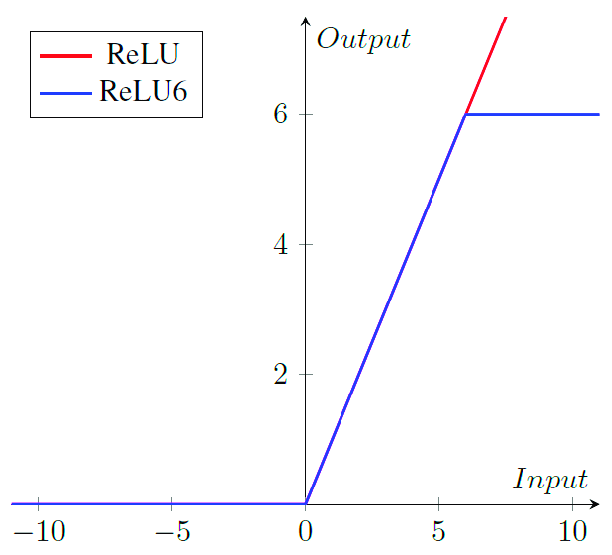
성능 비교
- 연산량
여기서도 width multiplier 를 사용하였고, 채널 수가 많을수록, 해상도가 클수록 성능이 올라가는 것을 확인할 수 있다.
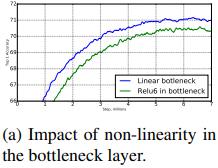
- Linear bottlenect
bottlenect 후에 ReLU6를 사용한 것과 비교를 해보았는데, 아래 그림처럼 그냥 선형으로 넘어간 것이 더 좋았음을 볼 수 있다.
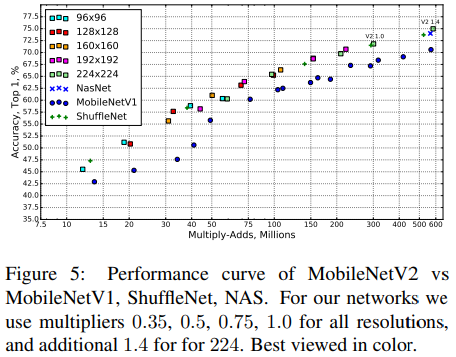
- 전체적 성능 비교
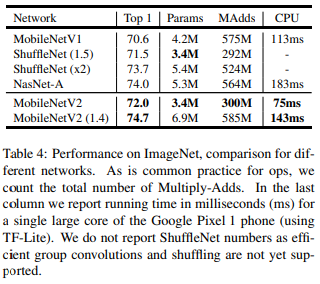 그림을 보면 V1에 비해 파라미터 수는 줄었으나 성능은 오히려 더 좋아졌음을 볼 수 있다!!
그림을 보면 V1에 비해 파라미터 수는 줄었으나 성능은 오히려 더 좋아졌음을 볼 수 있다!!
MobileNet V2가 레전드인 이유
- ReLU의 비선형성을 챙기면서 정보 손실을 막기 위해 inverted residual block를 설계하였다!
- 그래도 정보 손실을 더더욱 막고자 linear bottlenect 구조를 포함시켜 성능을 더욱 끌어올렸다!
MobileNet V3
MobileNet V3는 전에 배웠던 SE-block를 적용하고, 새로운 activation을 제안한 것이 특징인 모델이다. 똑같이 경량화와 동시에 성능도 이끌기 위해 진행하였고, 입출력 구조도 변경한 것이 특징이다.
SE-block
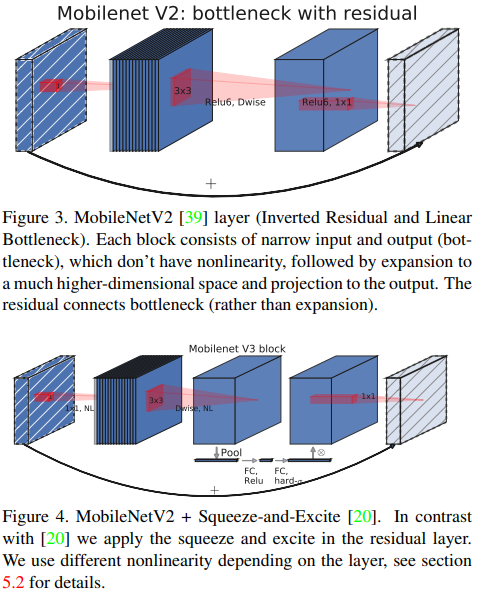
(논문 : https://arxiv.org/pdf/1905.02244)
SE-block은 전에 SENet에서 reduction ratio 로 16을 사용하였는데, MobileNet V3는 4로 사용하였다. 이는 MobileNet이 이미 채널 수가 적고, 정보 손실을 최대한으로 막으면서 성능을 올리깅 위해 4로 사용하였다!
MobileNet V3는 이 SE-block를 depthwise conv 이후에 배치하여 사용하였다.
새로운 activation 제안
SE-block를 사용하는 것은 좋은데.. 그 안에 사용하는 sigmoid는 mobile 장치에서는 부담스러운 activation이다.
왜냐하면 sigmoid는 의 형태인데, 여기서 지수 연산이 mobile cpu에서 조금 부담스럽기 때문이다.
또한, 지수 연산을 할 시에 중간값들을 저장해야 하는데 이것이 모바일 메모리의 접근 수를 높이고 부담을 준다.
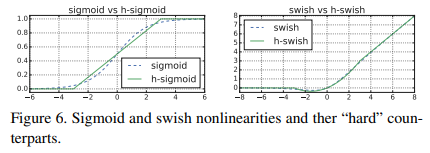
그래서 MobileNet V3는 새로운 activation으로 Hard Sigmoid를 사용하였다!
Hard Sigmoid는 으로 기존 Sigmoid와 비슷하면서 precision loss도 없고 메모리 접근 수도 줄이는 효과를 보여주었다!!
(precision loss : 숫자 표현에서 어쩔 수 없이 표현 범위를 줄이기에 생기는 정확도의 손실)
그리고 Hard Swish (=) 또한 제안하였다!
입출력 구조 변경
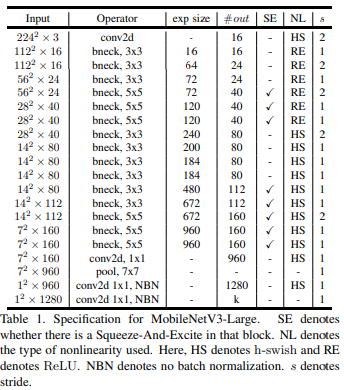
일단 MobileNet V3에서는 첫 conv에 Hard Swish를 사용하도록 바꾸었고, 이에 따라 첫번째 conv의 필터 수가 32였던 것을 16으로 줄일 수 있었다!
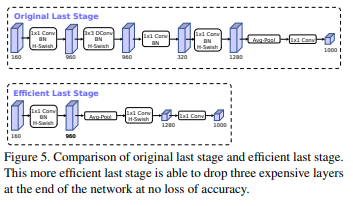
 그리고 마지막 부분(점선 부분)에서 아래 그림과 같이 GAP 후에 1 x 1 conv를 여러번 통과하는 것으로 바꾸었다!!
그리고 마지막 부분(점선 부분)에서 아래 그림과 같이 GAP 후에 1 x 1 conv를 여러번 통과하는 것으로 바꾸었다!!
전체 구조
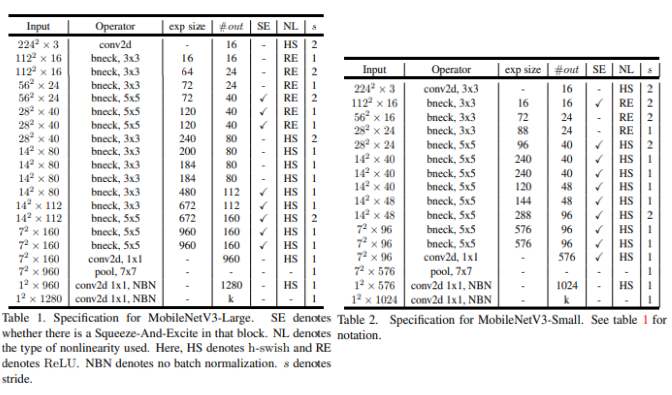 MobileNet V3는 Large와 Small 이렇게 두가지로 NAS를 사용하여 제안하였다.
MobileNet V3는 Large와 Small 이렇게 두가지로 NAS를 사용하여 제안하였다.
(NAS : AI가 AI 모델의 구조를 자동으로 디자인하도록 하는 것.)
특징으로는 ReLU6는 안 쓰고 다시 ReLU로 돌아간 것이고, Hard Swish는 모델의 절반 정도만 사용하였다!
또한 모든 채널을 8의 배수로 맞추어서 연산 효율과 메모리 절약을 하도록 설계 되었다.
Ablation Study
- activation의 차이
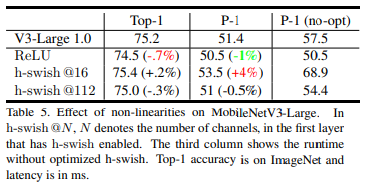 확실히 H-Swish를 적절히 사용하였을 때, 10% 정도의 실행 시간 단축을 보여준다!
확실히 H-Swish를 적절히 사용하였을 때, 10% 정도의 실행 시간 단축을 보여준다!
성능 비교
- MobileNet V2와의 비교
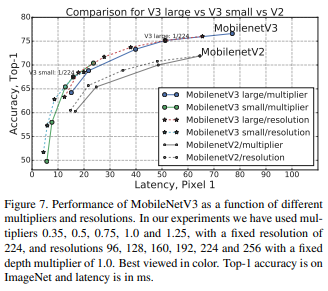 V2와 비교하였을 때, 같은 latency를 가지나 정확도가 더 큰 것을 볼 수 있다!!
V2와 비교하였을 때, 같은 latency를 가지나 정확도가 더 큰 것을 볼 수 있다!! - 다른 모델들과의 비교
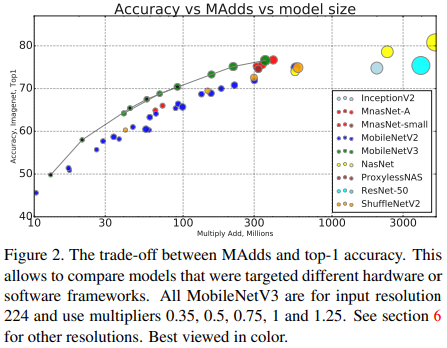 다른 비슷한 모델과의 비교에서도 더 효율적인 모습을 볼 수 있다!
다른 비슷한 모델과의 비교에서도 더 효율적인 모습을 볼 수 있다!
MobileNet V3가 레전드인 이유
- SE-block를 도입하여 더욱 성능을 끌어올리고자 하였고, Sigmoid의 문제점을 해결하기 위해 H-Sigmoid를 사용하였다!
- 전체 구조에서 H-swish를 사용해 성능을 높이고, 마지막 부분을 GAP 후에 1 x 1 conv의 반복 사용으로 MLP를 적용시켰다.
