목표
컴퓨터 비전이 활용되는 테스크들에 대해서 알아보자!!
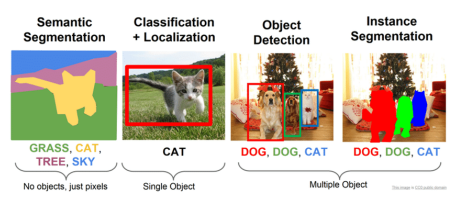
1. CV Task - 이미지 분류(image classification)
이미지 분류의 경우 다음과 같은 과정으로 이루어진다!
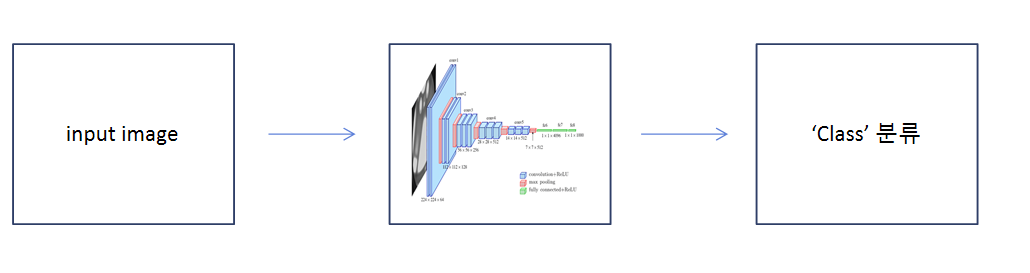 위에서 input image는 우리가 이미지 분류를 할 dataset을 전처리하는 것부터 시작한다.
위에서 input image는 우리가 이미지 분류를 할 dataset을 전처리하는 것부터 시작한다.
예를 들어 CIFAR10 dataset이 있을 때, 이를 다음 CNN model에 넣기 위해서 라벨링을 한다.
각각의 폴더를 만들어 이 폴더들의 위치를 이용한다던지, one-hot-encoding을 이용한다던지,
하나의 폴더에 "라벨명_001.jpg"처럼 넣는다던지.. 아무튼 방법은 아주 많다!!
그리고 다음으로 이 input image를 CNN model에 넣어주는데, 위의 그림처럼 VGGnet을 사용을 한다던가 LeNet을 사용한다던가 CNN model의 종류는 아주 많다.
여기서 CNN model의 종류는 많아도 이미지 분류를 위해 같은 특징을 지니고 있는데,
바로 특징을 추출하는 conv layer 부분과 분류를 진행하는 classifier layer 부분으로 나뉜다는 것이다. 그리고 conv layer 부분의 경우 backbone으로 부른다.
그리고 이 backbone 뒤에 어떤 layer가 붙어있는지에 따라서 CV task가 각각 달라진다고 생각하면 된다!!
[*] ResNet
ResNet는 이미지 분류 부분에서 쓰이는 모델으로 다음과 같은 긴 과정을 거쳐 이미지 분류를 진행한다.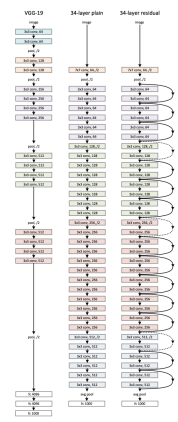 이미지 분류 부분에서 여러 모델이 있지만 ResNet에 대해 대표적으로 소개하는 이유는 ResNet이 딥러닝(CNN) 부분의 하나의 고질적인 문제점을 해결하였기 때문이다.
이미지 분류 부분에서 여러 모델이 있지만 ResNet에 대해 대표적으로 소개하는 이유는 ResNet이 딥러닝(CNN) 부분의 하나의 고질적인 문제점을 해결하였기 때문이다.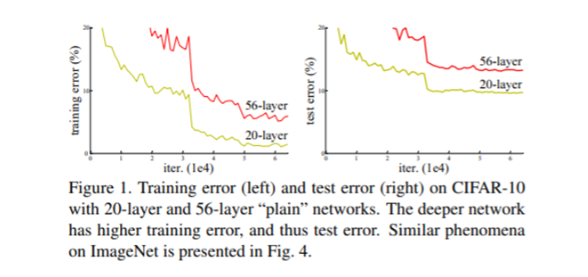
이 문제는 위 그림처럼 Layer가 깊어질수록 머신의 효율이 떨어진다는 것인데, (Training과 Test data 둘 다!)
이 문제는 Vanishing Gradient나 Overfitting 문제가 아니었고, 이에 대한 해결책으로 ResNet이 제안한 방법이 바로 Resudual learning(Skip connection)이다!!
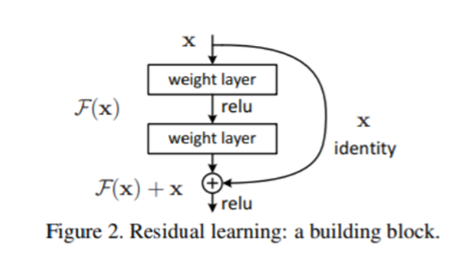 이 방법은 간단히 말하자면 layer skip인데, layer를 거쳐가는 부분과 layer를 건너뛰어서 그대로의 data를 가지고 있는 값을 더해 network를 구성하는 것이다. 이 방법을 통해 layer가 깊어져도 머신의 효율을 유지하는 효과를 드러내었고, 덕분에 아직도 많이 쓰고 있는 이미지 분류 모델이 바로 ResNet인 것이다!!
이 방법은 간단히 말하자면 layer skip인데, layer를 거쳐가는 부분과 layer를 건너뛰어서 그대로의 data를 가지고 있는 값을 더해 network를 구성하는 것이다. 이 방법을 통해 layer가 깊어져도 머신의 효율을 유지하는 효과를 드러내었고, 덕분에 아직도 많이 쓰고 있는 이미지 분류 모델이 바로 ResNet인 것이다!!
2. CV Task - 객체 검출(object detection)
 객체 검출의 경우 우리가 컴퓨터비전을 생각하면 가장 먼저 떠오르는 Task로 위의 그림과 같이 객체들을 구분하고, 위치를 특정하는 것을 말한다.
객체 검출의 경우 우리가 컴퓨터비전을 생각하면 가장 먼저 떠오르는 Task로 위의 그림과 같이 객체들을 구분하고, 위치를 특정하는 것을 말한다.
실제 동작 방식을 나누자면 아래 그림과 같이 나뉜다.
 1. 이미지에서 어디에 존재하는지 ( localization )
1. 이미지에서 어디에 존재하는지 ( localization )
2. 위의 이미지 분류로 이 객체가 무엇인지 ( classification )
3. (추가사항) 객체들을 구분하여 검출하는지 ( multiple object ) 객체가 하나면 single object임.
우리가 객체 검출을 하기 위해선 dataset의 전처리 과정이 필요한데,
이 경우에 image classification과 다르게 하나의 image 파일에 여러 객체가 존재하므로 이 객체들 하나하나 labeling해주는 것이 포인트이다!
labeling을 해줄 때 우리가 해야할 것은 객체들의 가장자리 왼쪽 위의 좌표와 가장자리 오른쪽 아래 좌표를 찾아주는 것이다. labeling은 직사각형의 형태로 진행되므로 위의 두 좌표만 알면 객체의 위치를 알 수 있기에 두 좌표와 객체의 이름을 한 번에 담아 저장하면 된다!!
그 다음으로 YOLO같은 알고리즘에 넣어 object detection을 진행하면 된다!
[*] YOLO (You Only Look Once)
YOLO의 경우 객체 검출 task에서 자주 쓰이는 모델이다. 이 모델은 말 그대로 이미지를 한 번에 보고 이미지 분류와 객체 위치 검출까지 한 번에 하는 모델이다!
YOLO 이전의 모델들은 이미지들 보고 여러 과정을 거쳐 객체 검출을 진행하여 실시간으로 task를 완수하는게 어려웠다. 그러나 YOLO의 경우 한 번에 task를 수행하여 동영상 같은 빠른 이미지에 적용이 가능하다!
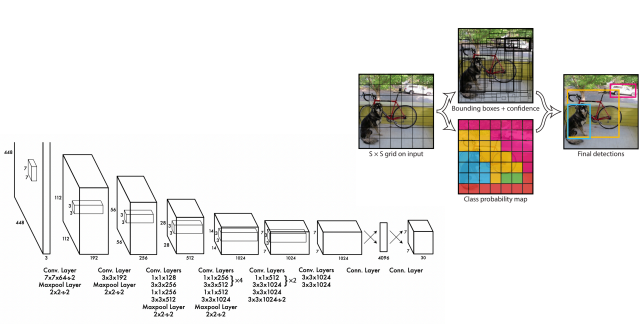 위의 그림은 YOLO의 기본적인 구조를 설명하고 있다.
위의 그림은 YOLO의 기본적인 구조를 설명하고 있다.
일단 처음 input을 7 x 7 grid cell로 나눈 뒤, network를 통과하면 Bounding boxes와 Class probability map을 얻게 된다.
그리고 각 grid cell마다 2개의 Bounding boxes를 가져 총 98개의 Bounding boxes를 보면서 confidence를 측정하고 이 confidence를 가지고 NMS 알고리즘을 거쳐 Final detections을 내게 된다.
현재도 YOLO는 잘 쓰이는 객체 검출 task 머신이고, YOLO의 단점들을 보완하고자 계속해서 새로운 버젼이 업데이트되고 있다!
YOLO에 대한 더 깊은 내용은 다음 링크를 통해 확인할 수 있다!
https://medium.com/@parkie0517/yolo-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-you-only-look-once-uni%EF%AC%81ed-real-time-object-detection-f146af809c57
3. CV Task - 객체 추적 (object tracking)
object tracking task의 경우, 우리가 위에서 배운 object detection과 tracking이 합쳐진 것이라고 보면 된다!
 위 그림과 같이 Object detection를 하는 것 뿐만 아니라 각 객체마다 id를 부여해 객체의 움직임도 파악하는 것이 Object tracking이다!!
위 그림과 같이 Object detection를 하는 것 뿐만 아니라 각 객체마다 id를 부여해 객체의 움직임도 파악하는 것이 Object tracking이다!!
Object tracking의 경우도 전처리 과정이 필요한데,
이 경우에 다른 task와는 다르게 엄청나게 많은 labeling이 필요하다. 왜냐면 객체의 좌표, 객체의 class, 객체의 id를 구성해야하고, tracking이라는게 주로 동영상에 대해 진행하므로 엄청나게 많은 이미지에 대해 위의 labeling을 해야하므로 엄청나게 많은 시간이 필요하다.
그래서 object tracking의 경우 다음과 같이 labeling tool을 이용하여 시간 절약이 가능하다!!
(물론 다른 task도 가능한데, object tracking의 경우 거의 필수적..!)
그래서 labeling에 도움이 되는 tool 하나를 추천해보겠다.
source : https://github.com/darkpgmr/DarkLabel
Ref : https://darkpgmr.tistory.com/16
위의 tool은 interpolation(보간법)을 사용하여 video에서 labeling을 진행할 때, video의 어느 부분의 양 끝만 labeling해도 그 사이에 있는 프레임들을 자연스러운 연결로 labeling해준다!
그리고 interpolation(보간법)의 정확한 뜻은 알려진 값들 사이에 있는 값들을 추정한다는 것이다.
위의 과정으로 전처리 과정이 끝나면 대표적으로 YOLO + DeepSORT를 사용하여 object tracking을 진행할 수 있다!!
[*] DeepSORT
DeepSORT에서 SORT는 Single Online Real-time Tracking의 약자로
kalman filter와 hungarian algorithm으로 구성된다.
-
kalman filter
kalman filter는 task에서 detective된 class가 어디로 이동할지 예측하는 것이다.
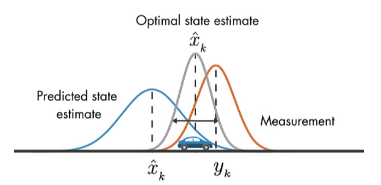 위 그림에서 Predicted state estimate가 예측한 것, Measurement가 실제 측정, kalman은 두 측정값의 차이를 줄여나가는 것이다.
위 그림에서 Predicted state estimate가 예측한 것, Measurement가 실제 측정, kalman은 두 측정값의 차이를 줄여나가는 것이다.
kalman의 경우에 YOLO처럼 Bounding box를 사용하여 데이터를 처리한다! -
hungarian algorithm
hungarian algorithm은 class id가 주어졌을 때, id가 예측과 같은지 판별하는 알고리즘이다.
그렇다면 그냥 tracking에 SORT를 사용하면 될 것 같은데 왜 DeepSORT를 사용하는 것일까?
그 이유는 SORT에 있는 두 가지 문제점 때문이다.
SORT는 occlusion과 id switching이라는 문제를 가지고 있는데 각각을 설명하면 다음과 같다.
- occlusiomn
occlusion은 만약 tracker를 진행하는 도중 class들이 겹쳐서 한 class가 보이지 않는 경우, 이에 대해 SORT는 겹쳐지게 된 class에 대해 탐색을 종료하고 새로운 class인 것처럼 tracker를 진행하게 된다. 위의 그림과 같이 아예 class 탐색을 종료하거나 가려지는 것이 끝나고 새로운 class를 본 것처럼 탐색을 해버린다는 문제이다.
위의 그림과 같이 아예 class 탐색을 종료하거나 가려지는 것이 끝나고 새로운 class를 본 것처럼 탐색을 해버린다는 문제이다. - id switching
id switching는 어떠한 물체에 대해 두 개 이상의 class들이 동시에 보이지 않는 경우, 이에 대해 id를 헷갈려서 tracker를 진행하는 것이다.
예를 들어 두 객체가 나무(장애물)에 가려져서 한 순간 안 보였다가 나타났을 때, 두 객체의 id를 착각하는 것을 말한다.
위의 두 문제를 해결하고자 DeepSORT가 연구되었는데, 여기서 Deep는 Deep-Learning의 Deep이다.
DeepSORT는 class id에 대해 각각의 id의 특징을 학습하여 id의 특징을 가지고 id 판별에 도움을 주는 것이다!!
DeepSORT에 관한 자세한 내용은 다음 링크에서 볼 수 있다!
https://gngsn.tistory.com/94
4. CV Task - 영역 분할(segmentation)
segmentation의 경우 다음 그림과 같은 과정을 거치는 task이다.
 위를 보면 object detection까지 진행을 하고 Instance Segmentation으로 모든 픽셀에 대해 object detection을 진행하는 것이다!!
위를 보면 object detection까지 진행을 하고 Instance Segmentation으로 모든 픽셀에 대해 object detection을 진행하는 것이다!!
영역 분할 task를 진행하기 위한 전처리는 image에 대해 경계선 검출까지 해야해서 엄청난 시간이 소요된다..!
 위의 그림은 하나의 객체에 대해 labeling하는 것인데, 위의 그림에서 "anniotations"는 label을 뜻하고, "segmentation"은 객체에 대한 하나의 좌표 과 그 옆의 좌표 를 하나로 묶어서 labeling을 진행한 것을 말한다.
위의 그림은 하나의 객체에 대해 labeling하는 것인데, 위의 그림에서 "anniotations"는 label을 뜻하고, "segmentation"은 객체에 대한 하나의 좌표 과 그 옆의 좌표 를 하나로 묶어서 labeling을 진행한 것을 말한다.
위의 전처리 과정을 거치면 U-Net 같은 머신을 통해 segmentation을 할 수 있다!!
[*] U-Net
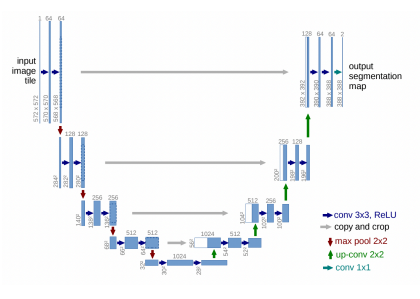 U-Net의 경우 위의 그림처럼 직관적으로 아키텍처를 구성하는 머신이고,
U-Net의 경우 위의 그림처럼 직관적으로 아키텍처를 구성하는 머신이고,
이는 가운데를 기준으로 왼쪽이 Contracting Path, 오른쪽이 Expending Path이다.
간단히 설명하자면 왼쪽은 축소하며 object detection을 진행하고, 오른쪽은 다시 확장하여 segmentation을 진행한다고 생각하면 된다.
왼쪽과 오른쪽은 대칭적인 구조를 가지고 있으며, 중간의 회색선은 Skipconnection을 의미한다!!
U-Net에 대한 자세한 내용은 다음에서 확인할 수 있다.
https://pasus.tistory.com/204
정리
- image classification은 이미지 분류로 class를 분류하는 것을 말한다.
대표적인 머신으로 ResNet, VGGNet이 존재한다.- object detection은 image classification + localization로 객체의 위치와 class의 분류를 말한다. 대표적인 머신으로 YOLO가 존재한다.
- object tracking은 object detection + tracking으로 객체의 class뿐만 아니라 각각의 객체 추적까지 말한다. 대표적인 머신으로는 YOLO + DeepSORT를 이용한다.
- segmentation은 object detection을 전체 픽셀 범위에서 하는 것을 말한다.
대표적인 머신으로는 U-Net이 존재한다.
