
🎈 본 리뷰는 RetinaNet 및 리뷰를 참고해 작성했습니다.
Key Words
🎈 Focal Loss
🎈 One-Stage
Introduction
👨🏫 RetinaNet은 Focal Loss를 사용한 One-stage detector로써 핵심은 focal loss를 사용해 "easy negative"의 Loss 기여도를 줄여, "hard negative" 더 많은 기여도를 높여 좋은 성능을 보여 주는 네트워크라고 할 수 있습니다.
✔ 최근의 SOTA detectors는 two-stage를 based로 구성한 네트워크들 입니다. 대표적으로 R-CNN 계열들의 모델이라고 말할 수 있습니다. fisrt-stage에서는 객체 후보군들을 찾으며(ex RPN, Seletive Search), two-stage에서는 각 후보 위치를 foreground class 또는 background class를 예측합니다.
✔ 본 논문에서는 위와 같은 FPN, Mask R-CNN 등등에 버금가는 COCO Ap를 가지는 one-stage detector 소개합니다. 위와 같은 성과를 얻기 위해서 one-stage dector에서 training 중 class imbalance가 발생하는 것을 확인했고, 새로운 loss function을 통해 imbalanc를 해결했다고 합니다.
✔ 기존의 two-stage detector은 two-cascde and sampling heuristics를 적용해 class imbalance를 해결했다고 합니다. 하지만 one-stage detector의 경우에는 많은(~100k) 후보군을 추출하는데, 이것이 class imbalance를 초래합니다. 구체적으로 실제 이미지에 확인할 수 있는 객체는 소수이면서, 대부분의 배경을 의미합니다. 즉, 많은 후보 객체들 중 대부분이 배경을 의미하기에 불균형을 초래합니다.
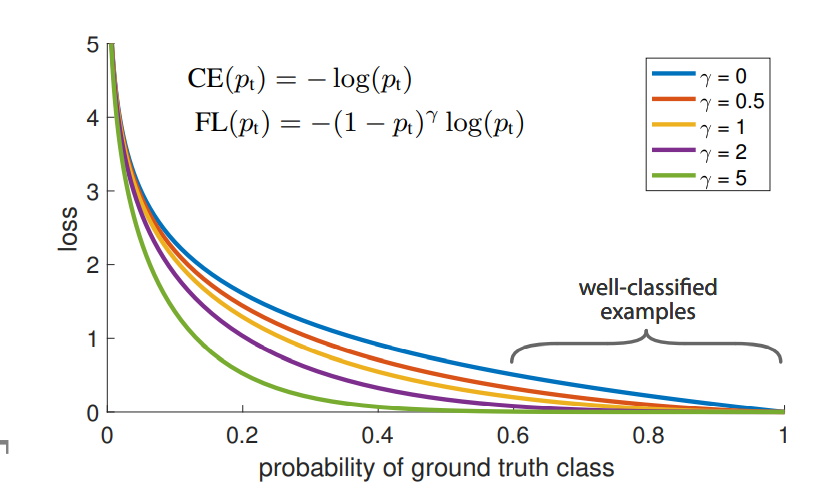
✔ 본 논문에서는, Focal Loss 라는 새로운 loss function을 제시합니다. Focal Loss는 train시 더 높은 정확도와 one-stage detecotor에서의 중요한 기능을 제시합니다. 직관적으로 train 중 easy examples를 down-weighting 시켜, 나머지 hard example의 중요도를 높입니다.
✔ 위의 Focal loss를 증명하기 위해, RetinaNet이라고 부르는 간단한 one-stage object detector 제시합니다. RetinaNet는 효과적이고 정확하며, ResNet 101-FPN backbone을 사용해 COOO test-dev에서 39.1 AP의 성능과 5fps의 속도를 보여줍니다.
Focal Loss
✔ Focal loss는 one-stage detector의 foreground와 background의 class imbalance를 해결해 줍니다.
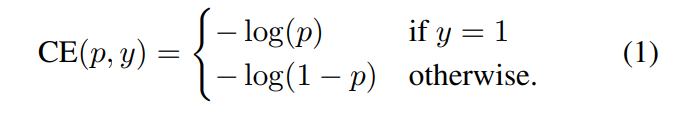
ground truth class
1이라고 예측한 확률
✔ Focal loss을 이야기하기 전, cross entropy(CE) for binary classification에 대해 위와 같이 확인할 수 있습니다. 참고로 multi-classification으로도 확장하면 가능하다고 합니다.
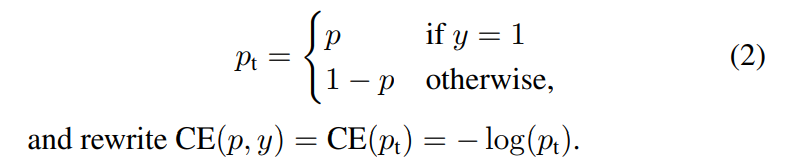
✔ 위와 같은 표현으로 다시 정의할 수 있습니다.
✔ 위의 파란색 선은 = 0 , 즉 CE라고 의미할 수 있습니다. 값이 바뀌면서 그래프가 바뀌는 것을 볼 수 있습니다.
Balanced Cross Entropy
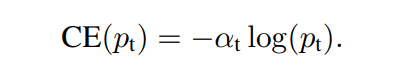
✔ Class imbalance를 해결하기 위한 한 가지 커먼한 방법은 가중치 을 class 1인 경우에 1 - 를 class -1에 부여합니다. 위의 방법은 positive/negative example 문제에는 영향을 주지만, easy/hard negative에 대해선 영향을 주지 못한다고 합니다.
Focal Loss Definition
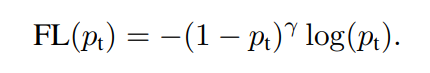
✔ 대부분의 easy classified nagatives loss가 gradient의 대부분 지배하는 것을 볼 수 있습니다.(class imbalance) 위의 balance cross entropy가 easy/hard negative 문제를 해결할 수 없어, 새로운 modulating factor()를 제시합니다. Focal loss는 위의 식의로 정의할 수 있습니다.
✔ 예를 들면 값이 작고 잘못 예측했다면, 위의 modulating factor는 1에 가까우며, loss에 영향을 주지 않습니다. 다른 예시로 가 1에 가까우면, factor는 0에 가까워 질 것이고, well-classified된 예시의 loss는 down-weight 될 것입니다.
✔ 또 다른 예시로 이거, 이면 CE에 비해 100배 낮은 loss를 가지고, 이면 1000배 낮은 loss 값을 가집니다.
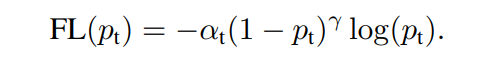
✔ 위의 식과 같이 본 논문에서는 -balance 값을 추가해 사용합니다. 단순하게 위의 방법을 사용했을 때 더 좋은 결과를 도출했다고 합니다.
Class Imbalance and Model Initialization
✔ Binary classification models은 y = -1 or 1에 상관없이 출력 확률이 같도록 초기화 됩니다. 이러한 초기화는, 손실이 전체 손실을 지배할 수 있어 불안정한 초기 traing 초래할 수 있습니다. 위의 방법을 막기위해 prior(=p)를 사용합니다. p값은 rare class에 의해 추정된 값으로 지정합니다.
Class Imbalance and Two-stage Detectors
✔ Two-stage detector의 경우에는 CE를 사용하지만, 대신 2가지 방법으로 불균형을 해결합니다.
(1) two-stage cascade, (2) biased minibatch sampling을 사용합니다. cascade 방법은 proposal의 수를 약 천개에 가깝게 줄입니다. 여기서 중요한건 proposal을 줄이는 것을 랜덤이 아닌 임의로 선택해서 진행하는데, 위의 과정에서 easy negative를 줄일 수 있습니다.
RetinaNet Dectector
✔ RetinaNet은 One-stage detector로써 backbone + two task specific subnetworks로 구성되어 있습니다. 각각의 subnet은 object classification과 bounding box를 예측합니다.
Feature Pyramid Network Backbone
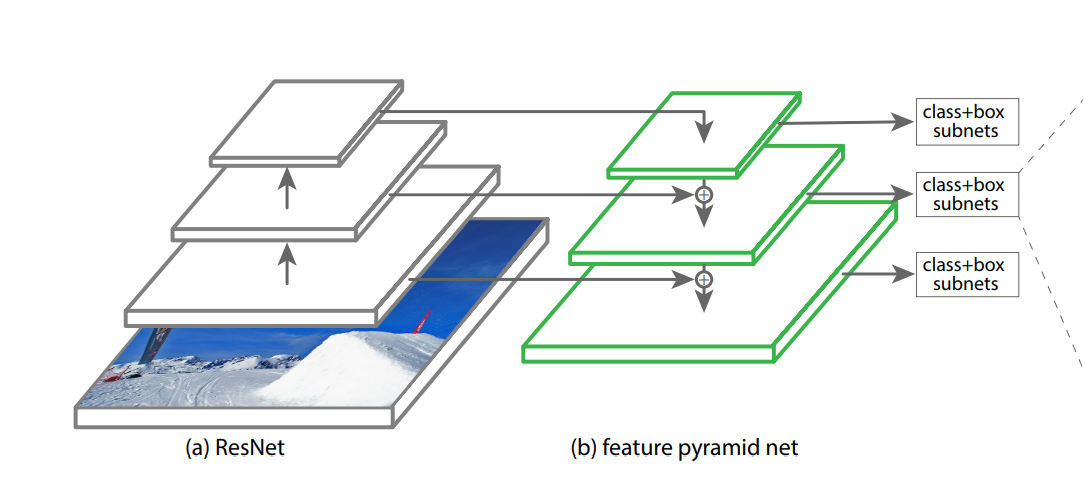
✔ FPN은 top-down pathway + lateral connections을 사용하고, single resolutions을 받아 multi-scale feature pyramid를 추출합니다.
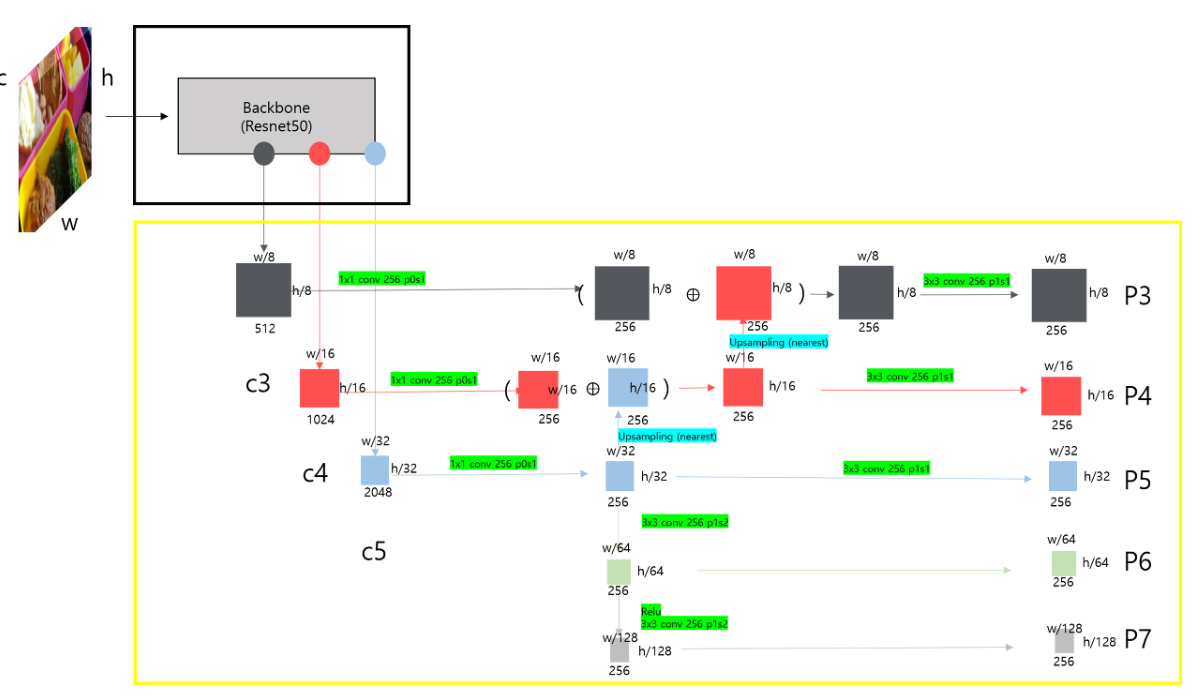
✔ ~ 의 피라미드 구조를 이루며 각각 256의 채널을 가지고 있습니다. 제사한 내용은 FPN 논문을 참고해주시기 바랍니다.
Anchors
✔ 위의 anchor box들의 사이즈는 ~ 를 고려해 32 ~ 512의 사이즈를 가지고 있습니다. 또한 각각의 피라미드 레벨에서 3개의 aspect ratios와 3개의 size를 추가로 사용합니다. (총 9개의 anchors)
✔ 각 anchor에는 class(=K)개의 one-hot vector가 할당되고 4개의 bbox 값이 할당됩니다. 모든 anchor들을 사용한 것이 아닌 IoU > 0.5 이상인 값들만을 사용하며, 0 <= IoU < 0.4의 값들은 background로 사용합니다. 이외의 anchor들은 무시합니다.
Classification & Box Regression Subnet

✔ Classification subnet에서는 각각의 공간 위치에 A anchors와 K object class에 대한 확률을 예측합니다. 위의 subnet은 FPN level에 작은 FCN을 추가한 것이라고 말할 수 있습니다.

✔ Class subnet은 위와 같은 구조를 가지고 있습니다. 또한 RPNs는 대조적으로, 위의 classification subnet은 더 깊으며, 오직 3x3 conv만 사용하고, box regression과 파라미터를 공유하지 않습니다.
✔ Box regression Subnet은 object classification과 병렬적으로 처리되며, 또다른 작은 FCN구조를 추가한다고 합니다. 위의 마지막 구조와 같이 4A를 추출합니다. 또한 본 논문에서는 class-agnostic bbox regressor을 사용했다고 합니다.
Inference and Training
✔ RetinaNet은 ResNet-FPN backbone + two subnet with FCN의 구조 가지고 있습니다. inference시 속도를 향상시키기 위해 FPN에서 가장 높은 1000개 중 0.05 이상의 confidence 값들만 추출해 예측했습니다. final detection에서 0.5이상의 threshold로 NMS를 진행했습니다.
✔ 본 논문에서는 Focal Loss에 대해 설명했습니다. Focal loss는 classification subnet의 결과로 사용했으며, 로 설정하고 진행했다고 합니다. 또한 본 RetinaNet에서의 focal loss는 all ~ 100k의 anchor들에 대해 계산을 진행했는데, 이는 이전의 RPN이나 OHEM에서 작은 셋의 미니배치를 사용한 것과는 대조적입니다.
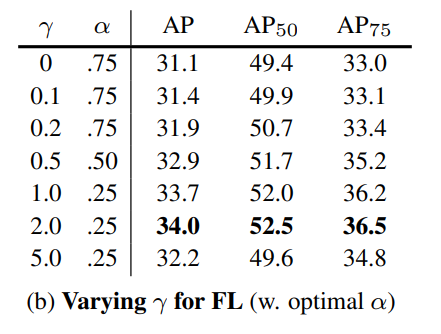
✔ 이미지의 전체 focal loss은 모든 ~100k anchor의 대한 focal loss의 합으로 계산되며, GT로 할당된 anchor의 수로 정규화합니다. 와 의 파라미터 설정은 위의 표에서 볼 수 있습니다.
✔ Backbone(ResNet)을 사용했으며, FPN에 추가적으로 layer에 대해 초기화를 진행했습니다. 마지막 layer 제외한 모든 추가적인 layer에 대해 bias b = 0으로 weight는 을 가지는 가우시간 분포로 초기화 합니다. 마지막 conv layer의 bias에 대해 값으로 초기화합니다. 를 주고 모든 실험을 진행했다고 합니다.
✔ Optimization의 경우 SGD를 사용해 진행했습니다. Retinanet은 8개의 GPU를 동기화해 사용했고 각 미니배치당 16개의 이미지를 학습합니다. 총 90K의 iteration을 진행했습니다. 초기 learning rate는 0.01로 60K에 0.001로 80k에 0.0001로 진행했다고 합니다. Weight decay는 0.0001로 momentum은 0.9로 사용했다고 합니다. 또한 training loss = focal loss + standard smooth L1 loss(box regression) 사용했다고합니다.
👨🏫 이 후의 내용들은 대부분 실험 결과에 대한 이야기들 입니다. 궁금하시면 논문 참고 부탁드리겠습니다.
Reference
