
🎈 본 리뷰는 CenterNet 및 리뷰를 참고해 작성했습니다.
Keywords
🎈 CenterNet
🎈 Keypoint and Center-based
🎈 Only one anchor
Introduction
✔ 오늘은 CenterNet인 Object as points 논문에 대해 리뷰할 예정입니다. 기존의 one-stage detection들의 경우에는 대부분 많은 Anchor들을 사용하며, 마지막에는 NMX를 사용해 중복을 제거하였습니다. Sliding window(anchor)를 기본으로 한 detector들은 가능한 모든 location과 demension을 구해야 하기 떄문에 wasteful하다는 것을 알 수 있습니다.
✔ 본 논문에서 제시한 방법은 object detection을 standard keypoints 방법으로 해결하는 것입니다. 이는 이전의 CornerMet과 ExtremeNet과 비슷합니다. 또한 CenterNet은 Object detection 뿐만 아니라, 3D bounding box estimation이나 human pose estimation에서 사용됩니다. 본 리뷰는 Object detection에 집중할 예정입니다.
✔ 본 detection 과정에 대해서 간단하게 소개하면, 먼저 FCN으로 부터 heatmap를 generate합니다. 그리고 object center에 해당하는 peaks 지점을 찾습니다. 각각의 peaks를 사용해 bbox와 weight, height를 게산합니다. 추론 시에는 추가적으로 NMS를 사용하지 않습니다.
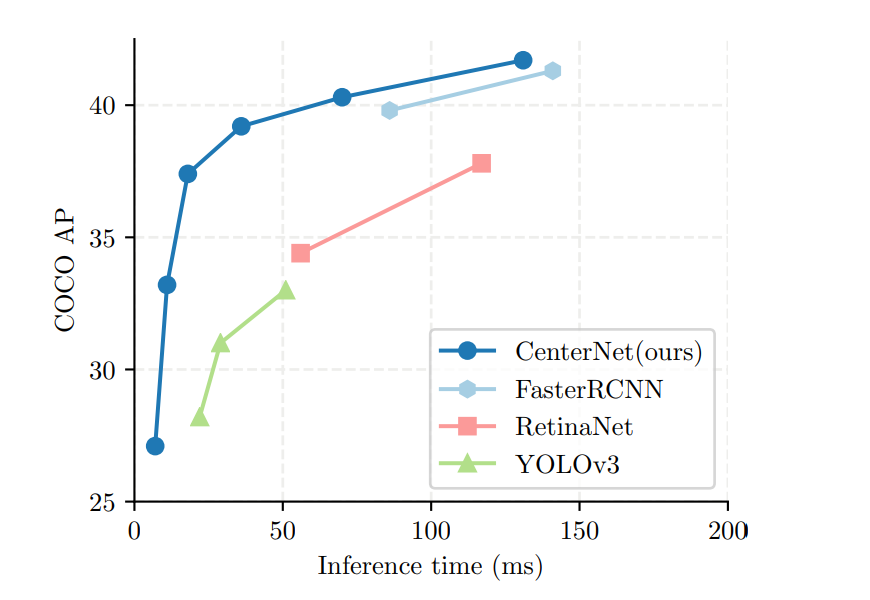
✔ 위의 그래프에서 확인할 수 있듯이 Resnet-18을 backbone으로 사용한 CenterNet은 very hightt speed 보여줍니다. 또한 본 논문에서는 backbone network로 ResNet, Hourglass, DLA 방법을 사용했습니다.
Related work
Object detection with implicit anchors

✔ CenterNet은 anchor-based one stage에 가깝다고 말할 수 있습니다. single shape-agnostic한 center point를 사용하는데, 이는 위의 사진에서 볼 수 있습니다. anchor-based one stage와 다른 점은 먼저 CenterNet은 오직 하나의 "anchor"를 할당합니다. 또한 오직 하나의 positive한 anchor만 존재함으로, NMS를 사용하지 않을 수 있습니다. 마지막으로 CenterNet은 larger output resolution 를 도출합니다.
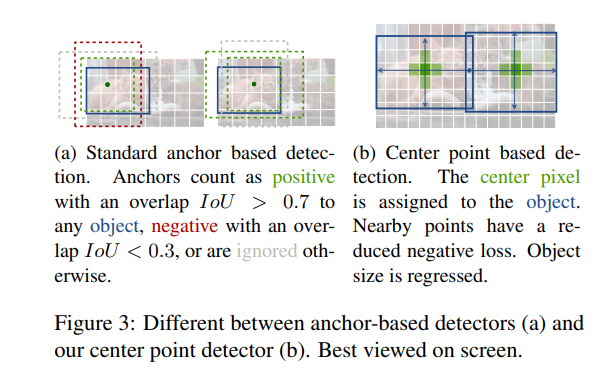
✔ 기존의 Anchor based한 detection들과의 차이를 볼 수 있습니다.
Preliminary
✔ (W, H)을 가지고 있는 input image 라고 한다면, 우리가 도출하는 Keypoint heatmap은 일 것이며, 은 output stride이며, 는 keypoint type의 수 입니다. 예를 들면 COCO dataset이라면 는 80일 것입니다. 본 논문에서 은 4로 사용합니다.
✔ Fully-convolutional encoder-decoer network로 이루어진 backbone를 사용해 detected keypoint에 상응하면 을 이면 background를 의미합니다.
Loss
🎈 CenterNet에서는 3가지 loss를 사용한다고 말할 수 있겠습니다. "Heatmap Variant Focal Loss", " L1 Norm Offset Loss", " L1 Norm Dimension Size Loss"
Heatmap Variant Focal Loss
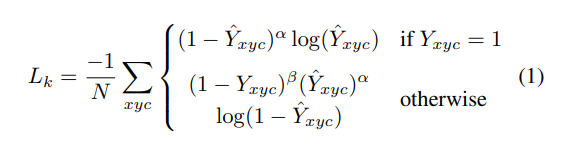
✔ 먼저 Keypoints 학습에는 Focal loss가 사용되었습니다. Focal loss는 RetinaNet에서 제시된 방법으로 easy Negative가 많을 때 그에 대한 loss 영향력을 줄이는 loss 계산 방법입니다.
✔ 는 focal loss의 하이퍼 파라미터이며, 2,4를 사용했다고 합니다.
L1 Norm Offset Loss
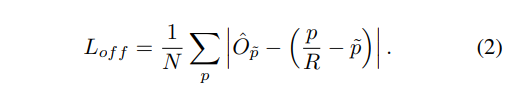
- 은 predict a local offset
✔ Offset의 경우에는 L1 loss를 사용합니다. smoothL1 loss와 비교했을 때, L1 loss의 성능이 더 좋게 나온다고 합니다. 일반적으로 이미지가 network를 통과하면 사이즈가 줄어듭니다. 줄어듬으로써 keypoint의 위치변동이 있기에, 위의 방법으로 조정해줍니다.
L1 Norm Dimension Size Loss
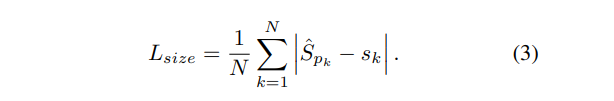
- 는 predicted dimension
- 는 GT size
✔ Object size 역시 L1 loss를 사용합니다.
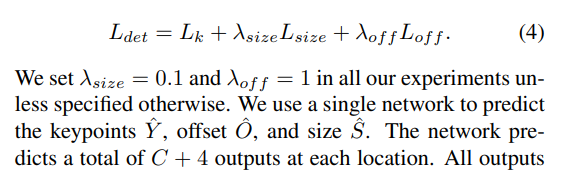
✔ 최종적으로 Loss는 위와 같이 계산됩니다. 각각의 람다는 0.1, 1을 사용했으며, 본 network는 keypoints, offsets and size를 예측합니다.
Objects as Points
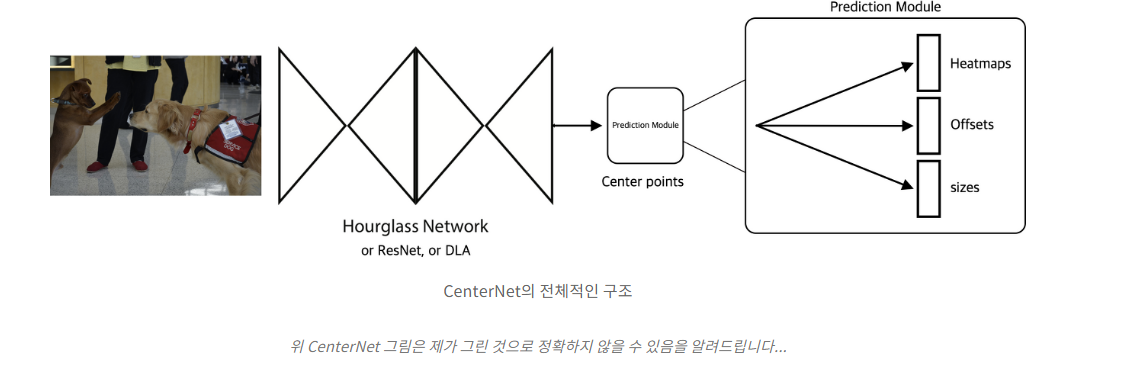
✔ CenterNet의 구조를 논문에서는 따로 시각적으로 보여주지 않아서, 티스토리 글을 가지고 와봤습니다. (이는 아래 Reference 링크에 포함되어 있습니다.) 바로 전에 언급했듯이, network에 keypoints, offsets and size를 예측합니다. 결과적으로 C + 4개의 예측이 됩니다.
From points to bounding boxes

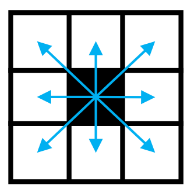
✔ inference time에는 먼저 각각의 카테고리에서 독립적으로 heatmap의 peaks 지점을 추출합니다. peaks 지점의 위의 그림과 같이 주변 8개의 값이 크거나 같은 중간값을 저장하고, 가장 큰 100개의 peak을 남겨놓습니다.

✔ Peak들은 각각 (x,y) 형태로 존재합니다.()
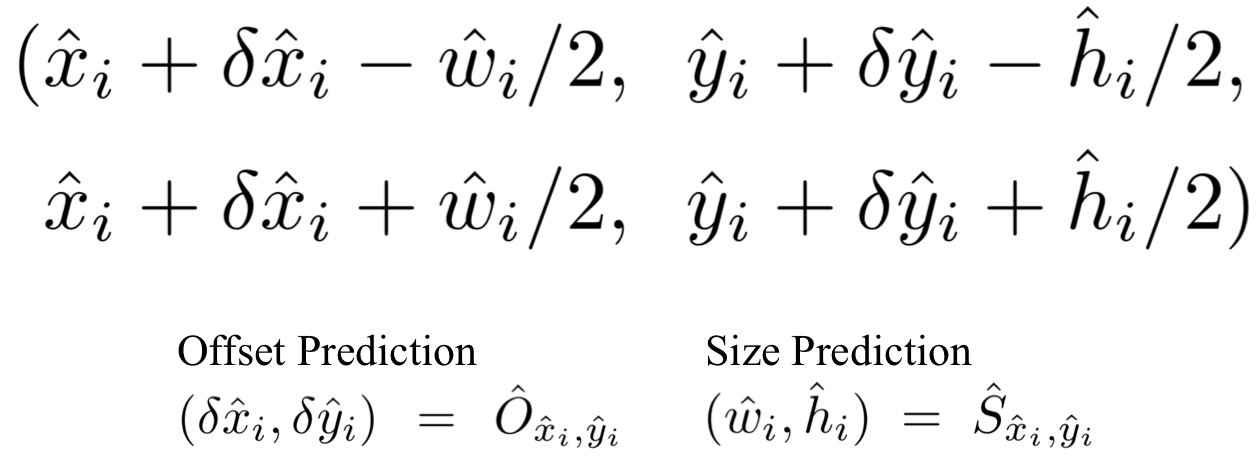
✔ 이를 통해서 위와 같이 bouning box 좌표를 계산할 수 있습니다. 또한 모든 결과는 keypoint estimation에서 바로 나오 결과이며, NMS나 다른 post-processing을 사용하지 않았습니다. 대신 3 x 3 maxpooling 사용했다고 합니다.
🎈 CenterNet은 기존의 방법들과는 다른 방법을 사용했습니다. 또한 CornetNet의 발전된 버전이라고 생각할 수 있습니다. CornetNet을 보고오시면 조금 더 이해하기 쉬울 것이라고 생각됩니다. 다만 위의 결과들이 SOTA를 뛰어넘는 결과를 보여주지 않았지만, 간단한 구조로 좋은 성과를 낸 네트워크라고 생각됩니다.
Experiments
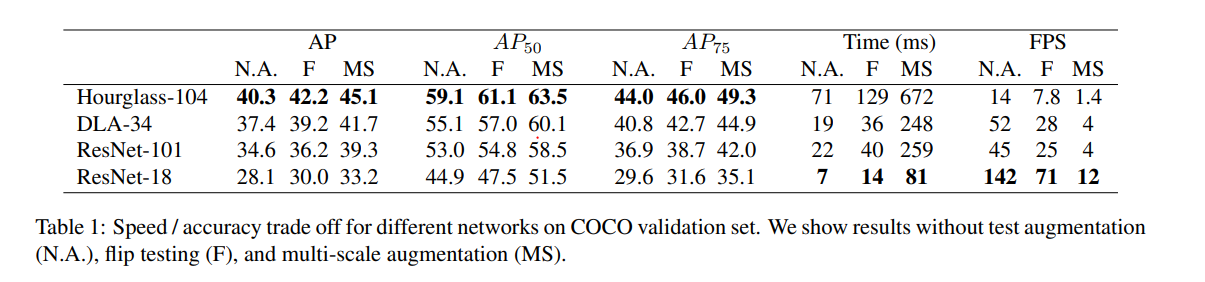
✔ 위의 테이블에서 각각의 backbone 네트워크를 사용한 결과를 볼 수 있습니다. Hourglass-104가 가장 높은 AP를 보여주지만, 속도가 가장 낮은 것을 확인할 수 있습니다. ResNet-18의 경우 상대적으로 낮은 AP를 보여주지만, 속도가 빠른 것을 볼 수 있습니다.
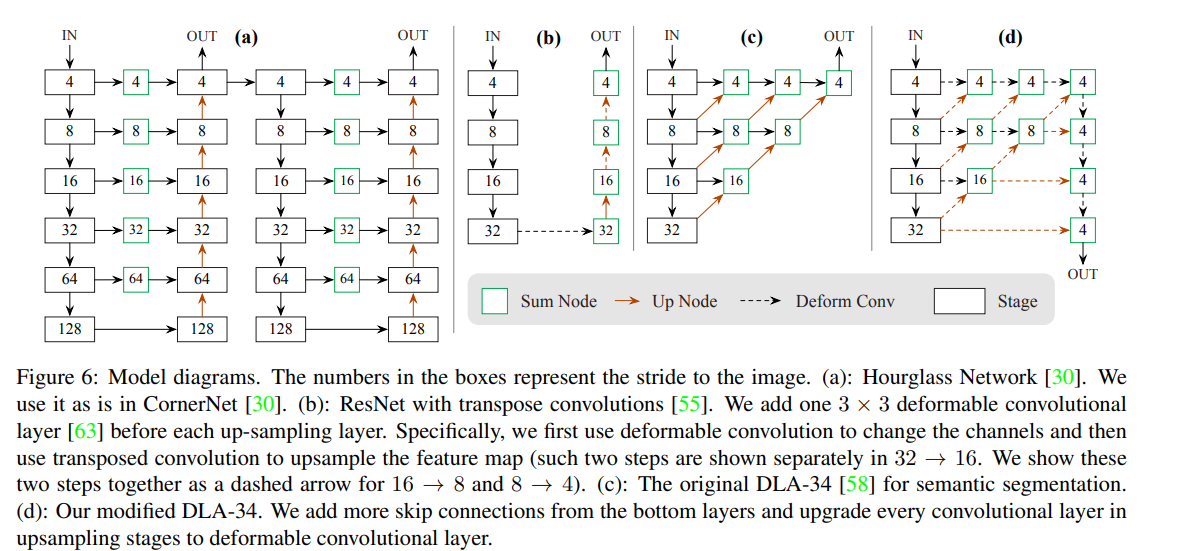
✔ ResNet과 DLA는 기본적으로 encoder-decoder 형태가 아니기에, 추가적으로 upsampling 과정이 필요합니다. Upsampling layer시 deformable convolutional layer를 사용합니다. deformable convolutional layer란 기존의 fix된 feature가 아닌, 좀 더 flexible한 영역에서 특징을 추출하는 방법을 제안합니다.
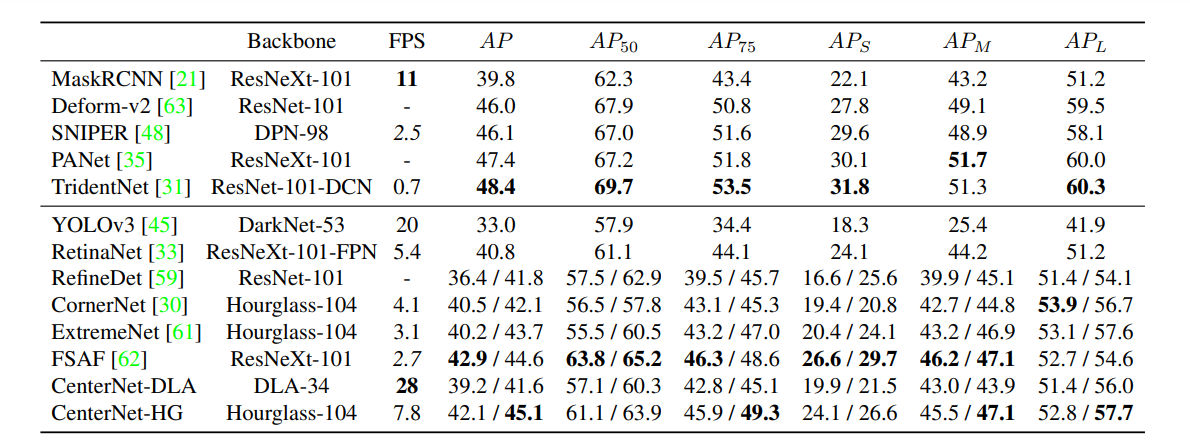
✔ 기존의 다른 네트워크들과 비교해봤을때, 기존의 SOTA 모델을 뛰어넘지는 못하지만, 전반적으로 비슷한 것을 볼 수 있습니다.
Reference
