RandomForest
✔ 랜덤포레스트는 기계 학습의 하나이며, 분류, 회귀 분석등에 사용되는 앙상블 학습 방법이다. 훈련 과정에서 구성한 다수의 결정 트리(Decision tree)로부터 분류 또는 평균 예측치를 출력함으로써 동작한다. 조금 더 이해하기 쉽게 설명하면, 다수의 결정 트리를 합친(앙상블) 로직이라고 생각해도 될 듯하다.
Why?
✌ 일반적으로 결정 트리의 단점 중 하나는, 결과 및 성능의 변동 폭이 크다. 다시 이야기하면 학습 데이터에 따라 생성되는 결정 트리를 일반하기 어렵다. 배깅(Bagging) or 랜덤 노드 최적화(Randomized node optimization)와 같은 랜덤화 기술이 이와같은 단점을 해결해준다.
* 배깅(bagging)은 bootstrap aggregating의 준말로서 주어진 데이터에 대해서 여러 개의 부트스트랩 자료를 생성하고 자료를 모델링한 후 결합하여 최종 예측 모형을 산출하는 방법이다. 여기서 부트스트램은 random sampling을 통해 raw data로 부터 크기가 동일한 여러 개의 표본 자료를 말합니다.
https://m.blog.naver.com/muzzincys/220201299384
RandomForest의 특징
✌ 랜덤 포레스트의 가장 큰 특징은 랜덤성(randomness)에 의해 트리들이 서로 조금씩 다른 특성을 갖는다는 점이다. 이 특성은 각 트리들의 예측(prediction)들이 비상관화(decorrelation) 되게하며, 결과적으로 일반화(generalization) 성능을 향상시킨다. 또한, 랜덤화(randomization)는 포레스트가 노이즈가 포함된 데이터에 대해서도 강인하게 만들어 준다. 랜덤화는 각 트리들의 훈련 과정에서 진행되며, 랜덤 학습 데이터 추출 방법을 이용한 앙상블 학습법인 배깅(bagging)과 랜덤 노드 최적화(randomized node optimization)가 자주 사용된다. 이 두 가지 방법은 서로 동시에 사용되어 랜덤화 특성을 더욱 증진 시킬 수 있다.
✔ 배깅을 이용한 포레스트 구성
- 부트스트랩 방법을 통해 T개의 훈련 데이터셋을 생성한다.
- T개의 기초 분류기들을 훈련시킨다.
- 기초 분류기들을 하나의 분류기로 결합한다.
✔ 일반적으로 매우 깊이 성장한 트리는 훈련 데이터에 대해 과적합하게 된다. 부트스트랩 과정은 트리들의 편향은 그대로 유지하면서, 분산은 감소시키기 때문에 포레스트의 성능을 향상 시킨다. 즉, 한 개의 결정 트리의 경우 훈련 데이터에 있는 노이즈에 대해 매우 민감하지만, 트리들의 서로 상관화(correlated)되어 있지 않다면 여러 트리들의 평균은 노이즈에 대해 강인해진다.
✔ 앙상블 모델
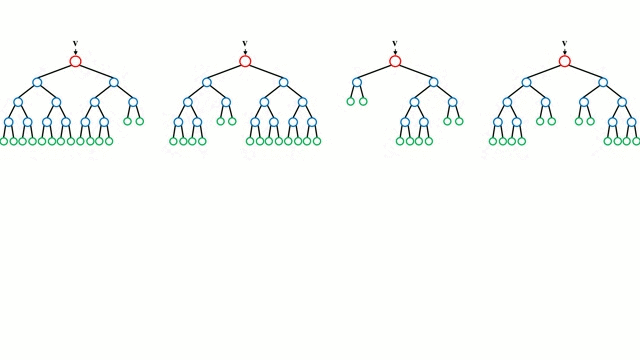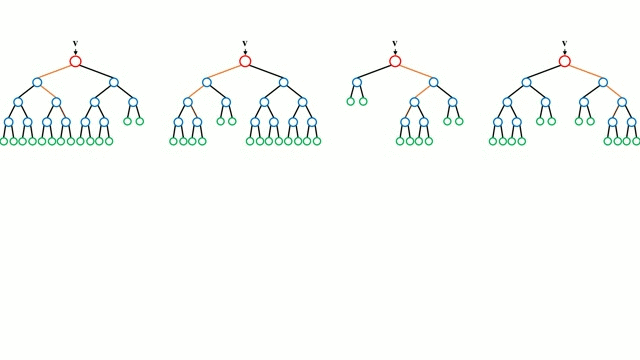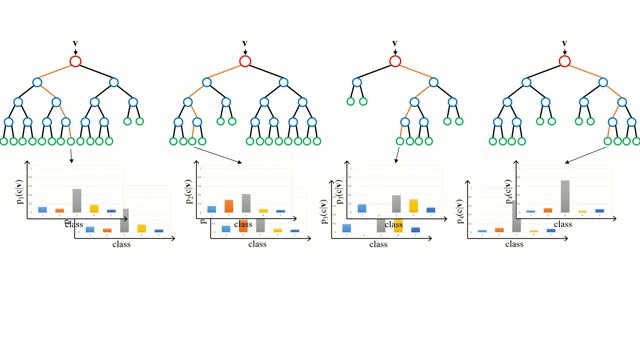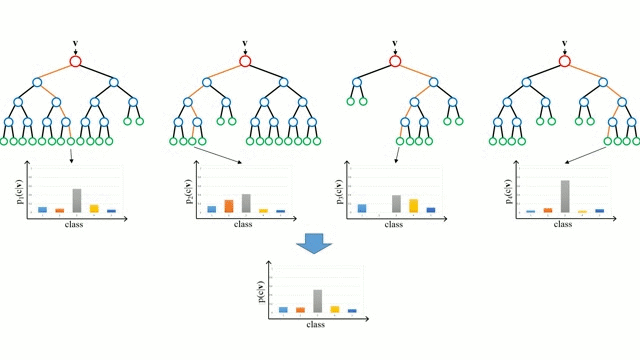
포레스트의 모든 트리들은 독립적으로 훈련 단계를 거친다. 테스트 단계에서 데이터 포인트 v는 모든 트리에 동시로 입력되어 종단 노드에 도달하게 된다. 이러한 테스트 단계는 병렬적으로 진행될 수 있으며, 따라서 병렬 CPU 또는 GPU 하드웨어를 통해 높은 계산 효율성을 얻을 수 있다. 포레스트의 예측 결과는 모든 트리의 예측 결과들의 평균으로 얻는다. 분류의 경우를 보면 다음의 식과 같다. (랜덤포레스트에 대한 자세한 수학적 수식은 아래의 위키피디아에 자세하게 나와있습니다.)

다른 방법으로는 트리들의 결과들을 곱하는 방법이 있다.
👨🏫 아래는 랜덤포레스트 모델의 진행과정이다.
Check Hyperparameter in sklearn
✔ 가장 대중으로 사용되는 사이킷런의 RandomForestClassifier의 Hyperparameter에 대해서 알아볼려고 합니다.
| 파라미터 | 설명 |
|---|---|
| n_estimators | - 결정트리의 갯수를 지정 - Default = 10 Tree의 깊이가 길어지면 overfitting이 일어날 수 있으므로 적절하게 조절해야한다. |
| min_samples_split | - 노드를 분할하기 위한 최소한의 샘플 데이터 수 - 일반적으로 과적합을 제어하는데 사용한다. |
| min_samples_leaf | - 리프노드가 되기 위해 필요한 최소한의 샘플 데이터 수 - 불균형 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 작게 설정 필요 |
| max_features | - 최적의 분할을 위해 고려할 최대 개수 Default = 'auto','log','sqrt' |
| max_depth | - 트리의 최대 깊이 Default = None - 깊이가 깊어지면 과적합될 수 있으므로 적절히 제어 필요 |
| max_leaf_nodes | - 리프노드의 최대 개수 |
✔ 대부분 GridsearchCV, randomsearhCV, 베이지안 최적화 등 다양한 최적의 하이퍼파라미터를 찾아주는 라이브러리를 사용한다. 하지만 어떤 파라미터 어떤 의미를 가지는지는 알고 사용해야할 듯 하다.
👀 참고 자료
- https://ko.wikipedia.org/wiki/%EB%9E%9C%EB%8D%A4_%ED%8F%AC%EB%A0%88%EC%8A%A4%ED%8A%B8
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- https://injo.tistory.com/30
👀 Randomforest Python 구현 자료
- https://eunsukimme.github.io/ml/2019/11/26/Random-Forest/
(공부하실 때 참고하시면 좋을 듯 합니다.)
