😉 Aiffel Fundimentals에서 주어진 vgsales.csv로 전처리 Practice입니다. 매우 기본적인 데이터 전처리 과정을 다룰 예정입니다.
TODO
Data: vgsales.csv
Python: 3.9.0
Pandas: 1.3.4
- 결측치(Missing Data) ✔
- 중복된 데이터 ✔
- 이상치(Outlier) ✔
- 정규화(Normalization) ✔
- 원-핫 인코딩(One-Hot Encoding) ✔
- 구간화(Binning) "Skip"
1. Data
path = "D:/dev/Python/Python/data/vgsales.csv"
df = pd.read_csv(path)
df.head()
>>>
Rank Name Platform Year Genre Publisher NA_Sales EU_Sales JP_Sales Other_Sales Global_Sales
0 1 Wii Sports Wii 2006.0 Sports Nintendo 41.49 29.02 3.77 8.46 82.74
1 2 Super Mario Bros. NES 1985.0 Platform Nintendo 29.08 3.58 6.81 0.77 40.24
2 3 Mario Kart Wii Wii 2008.0 Racing Nintendo 15.85 12.88 3.79 3.31 5.82
3 4 Wii Sports Resort Wii 2009.0 Sports Nintendo 15.75 11.01 3.28 2.96 33.00
4 5 Pokemon Red/Pokemon Blue GB 1996.0 Role-Playing Nintendo 11.27 8.89 10.22 1.00 31.37
df.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16598 entries, 0 to 16597
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Rank 16598 non-null int64
1 Name 16598 non-null object
2 Platform 16598 non-null object
3 Year 16327 non-null float64
4 Genre 16598 non-null object
5 Publisher 16540 non-null object
6 NA_Sales 16598 non-null float64
7 EU_Sales 16598 non-null float64
8 JP_Sales 16598 non-null float64
9 Other_Sales 16598 non-null float64
10 Global_Sales 16598 non-null float64
dtypes: float64(6), int64(1), object(4)
memory usage: 1.4+ MB
2. 결측치
- 위의 정보를 보고 "Year" and "Publisher" col에 결측치를 확인할 수 있다.
df.isnull().sum() # Year,Publisher
>>>
Rank 0
Name 0
Platform 0
Year 271
Genre 0
Publisher 58
NA_Sales 0
EU_Sales 0
JP_Sales 0
Other_Sales 0
Global_Sales 0
dtype: int64- "Publisher"의 컬럼의 경우 "NA"값을 "Unknown"으로 변경(본래 데이터에도 "Unknown"이 존재)
idx = df[df["Publisher"].isnull() == True].index
df.loc[idx, "Publisher"] = "Unknown"
df["Publisher"].isnull().sum()
>>>
0- "Year"의 컬럼의 경우 "NA"값을 "Unknown"으로 바꿀 수 없다. 대채되는 값 찾기 에매하지만, 데이터를 확인하면 "Platform" 게임기 컬럼이 존재하는데 각 전자기기마다의 평균년도를 NA값에 넣어주면 된다고 생각했다. 이유는 간단한다 게임기의 경우 계속해서 새로운 버전이 나오고 새로운 버전이 나오면, 전 버전 게임이 출시되지 않는다. 즉, 게임기마다 각각 자신의 시대가 존재한다고 생각했다.
도메인 지식의 중요성??
"Platform"끼리의 Groupby를 통해 평균년도를 구해 대채한다.
- "Year"의 컬럼의 경우 "NA"값을 "Unknown"으로 바꿀 수 없다. 대채되는 값 찾기 에매하지만, 데이터를 확인하면 "Platform" 게임기 컬럼이 존재하는데 각 전자기기마다의 평균년도를 NA값에 넣어주면 된다고 생각했다. 이유는 간단한다 게임기의 경우 계속해서 새로운 버전이 나오고 새로운 버전이 나오면, 전 버전 게임이 출시되지 않는다. 즉, 게임기마다 각각 자신의 시대가 존재한다고 생각했다.
# "Na" 값외에도 "Unknown"값이 존재한다. 두 가지 모두 "0"으로 변경("Year" 타입은 오브젝트이다.)
idx = df[(df["Year"].isnull() == True) | (df["Year"] == "Unknown")].index
df.loc[idx, "Year"] = "0" # type 맞추기
df["Year"].isnull().sum()
>>>
0n_df = df[df["Year"] != 0] # 0이 들어가면 평균 값이 이상해짐
n_df["Year"] = n_df["Year"].astype(float) # 평균 계산을 위해..
plf_mean_by_year = n_df.groupby("Platform")["Year"].mean().apply(lambda x: round(x, 0)).reset_index() # 반올림
plf_mean_by_year.set_index("Platform", inplace=True) # "Platform" 컬럼을 인데스로..
# 각 "Platform"의 평균값으로 대체
for col in plf_mean_by_year.index:
for plf, idx in zip(df[df["Year"] == "0"]["Platform"],df[df["Year"] == "0"]["Platform"].index):
if col == plf:
df.loc[idx,"Year"] = str(plf_mean_by_year.loc[col][0])
df.Year.unique() # no more zeros
>>
array([2006.0, 1985.0, 2008.0, 2009.0, 1996.0, 1989.0, 1984.0, 2005.0,
1999.0, 2007.0, 2010.0, 2013.0, 2004.0, 1990.0, 1988.0, 2002.0,
2001.0, 2011.0, 1998.0, 2015.0, 2012.0, 2014.0, 1992.0, 1997.0,
1993.0, 1994.0, 1982.0, 2003.0, 1986.0, 2000.0, '1973.0', 1995.0,
2016.0, 1991.0, 1981.0, 1987.0, 1980.0, 1983.0, '1956.0', '1729.0',
'1962.0', '1976.0', '1986.0', '1982.0', '1953.0', '1980.0',
'1977.0', '2009.0', 2020.0, 2017.0], dtype=object)
3. 중복 제거
df.duplicated().sum() # 중복 x
>>>
04. 이상치 제거
num_cols = ['NA_Sales',
'EU_Sales', 'JP_Sales', 'Other_Sales', 'Global_Sales']
plt.figure(figsize=(10,8))
for i,col in enumerate(num_cols):
ax = plt.subplot(4,2,i+1)
plt.title(col)
ax.boxplot(df[col])
plt.show()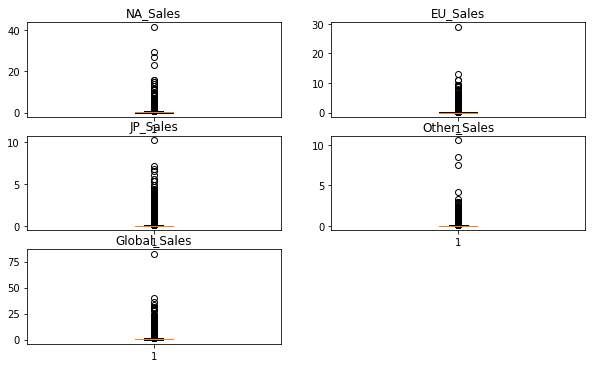
위의 Boxplot을 보면 각 컬럼마다 조금의 이상치 값들이 보인다. 이런 경우에는 IQR이나 Z-score보다는 조금이기에 직접 제거할려고한다.또한 데이터가 대부분 너무 한쪽으로 치우져저 있다.(Log-scale이 필요하다고 생각하지만..SKip..)
df[df["EU_Sales"]>20]
df[df["JP_Sales"]>8]
df[df["Other_Sales"]>7]
df[df["Global_Sales"]>75]
# 이상치 인덱스
idx= [0,17,47,4,1,5,9] # 총 7개
df.drop(index=idx, inplace=True)
5. 정규화
- 정규화가 필요한 이유는 모든 변수들의 값들이 결과값에 동일한 영향력을 행사하게 만들기 위해서 하는 것입니다. 조금 더 풀어서 생각하자면, 일반적으로 변수들 간의 값과 단위 기준이 전부 다릅니다. 이 기준을 동일하게 맞춰줘, 변수들이 결과에 같은 영향력을 행사 할 수 있게 된다.
- MinMaxScale
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
for_norm = df.iloc[:,6:] # numerical한 컬럼만
for_norm
df_output = fitted.fit_transform(for_norm)
df_output = pd.DataFrame(df_output, columns= for_norm.columns)
df_output.describe()
>>>
NA_Sale EU_Sales JP_Sales Other_Sales Global_Sales
count 16591.000000 16591.000000 16591.000000 16591.000000 16591.000000
mean 0.016156 0.011181 0.010583 0.011187 0.014322
std 0.041242 0.034689 0.040454 0.035129 0.036701
min 0.000000 0.000000 0.000000 0.000000 0.000000
25% 0.000000 0.000000 0.000000 0.000000 0.001396
50% 0.005047 0.001553 0.000000 0.002415 0.004468
75% 0.015142 0.008540 0.005556 0.008454 0.012846
max 1.000000 1.000000 1.000000 1.000000 1.000000
기존의 데이터와 Concat
df.reset_index(drop=True,inplace=True)
# 데이터 cocat
scale_df = pd.concat([df[["Name","Platform","Year","Genre","Publisher"]],df_output], axis = 1)6.One-Hot-Encoding
- One-Hot-Encoding이란 범주형 변수를 자신은 1, 나머지는 0으로 하는 컬럼을 만들어 준다. 즉, 범주형 변수의 카테고리 수가 총 5개이면 5개의 새로운 컬럼을 만들어준다. 위와 같은 구분을 하는 이유는 범주는 수치와 다르게 값의 높낮이가 없다(??) 각각의 범주 값이 고유한 의미가 있는 것이지 A의 값이 B값보다 서로 크거나 작거나 하지 않는다. 결국 정확한 데이터 분석을 위해서는 각각의 새로운 컬럼을 만들어줘야 한다.
platform = pd.get_dummies(df["Platform"])
platform.reset_index(drop=True)
>>>
2600 3DO 3DS DC DS GB GBA GC GEN GG ... SAT SCD SNES TG16 WS Wii WiiU X360 XB XOne
0 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 1 0 0 0 0
1 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 1 0 0 0 0
2 0 0 0 0 1 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 1 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 1 0 0 0 0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
16586 0 0 0 0 0 0 1 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
16587 0 0 0 0 0 0 0 1 0 0 ... 0 0 0 0 0 0 0 0 0 0
16588 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
16589 0 0 0 0 1 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
16590 0 0 0 0 0 0 1 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
# Data Concat
scael_ohe_df = pd.concat([scale_df,platform], axis=1)
scael_ohe_df
>>>
Name Platform Year Genre Publisher NA_Sales EU_Sales JP_Sales Other_Sales Global_Sales ... SAT SCD SNES TG16 WS Wii WiiU X360 XB XOne
0 Mario Kart Wii Wii 2008.0 Racing Nintendo 1.000000 1.000000 0.526389 0.799517 1.000000 ... 0 0 0 0 0 1 0 0 0 0
1 Wii Sports Resort Wii 2009.0 Sports Nintendo 0.993691 0.854814 0.455556 0.714976 0.921251 ... 0 0 0 0 0 1 0 0 0 0
2 New Super Mario Bros. DS 2006.0 Platform Nintendo 0.717981 0.716615 0.902778 0.700483 0.837755 ... 0 0 0 0 0 0 0 0 0 0
3 Wii Play Wii 2006.0 Misc Nintendo 0.885174 0.714286 0.406944 0.688406 0.810109 ... 0 0 0 0 0 1 0 0 0 0
4 New Super Mario Bros. Wii Wii 2009.0 Platform Nintendo 0.920505 0.548137 0.652778 0.545894 0.798939 ... 0 0 0 0 0 1 0 0 0 0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
16586 Woody Woodpecker in Crazy Castle 5 GBA 2002.0 Platform Kemco 0.000631 0.000000 0.000000 0.000000 0.000000 ... 0 0 0 0 0 0 0 0 0 0
16587 Men in Black II: Alien Escape GC 2003.0 Shooter Infogrames 0.000631 0.000000 0.000000 0.000000 0.000000 ... 0 0 0 0 0 0 0 0 0 0
16588 SCORE International Baja 1000: The Official Game PS2 2008.0 Racing Activision 0.000000 0.000000 0.000000 0.000000 0.000000 ... 0 0 0 0 0 0 0 0 0 0
16589 Know How 2 DS 2010.0 Puzzle 7G//AMES 0.000000 0.000776 0.000000 0.000000 0.000000 ... 0 0 0 0 0 0 0 0 0 0
16590 Spirits & Spells GBA 2003.0 Platform Wanadoo 0.000631 0.000000 0.000000 0.000000 0.000000 ... 0 0 0 0 0 0 0 0 0 0
16591 rows × 41 columns결론
- 위의 과정들은 매우 기본적인 전처리 과정입니다. 정확한 데이터 분석을 위해서는 추가적인 전처리 과정이 필요하다(ex. 변수선택, 공분산.. 등). 또한 위의 글에서 제시된 방법들은 전처리 방법 중 매우 일부이다. 다른 전처리 방법 또한 필수적으로 익혀야한다고 생각한다.(상황마다 적용해야할 방법들이 다르기 때문에..) 하지만 가장 중요한 건 도메인 지식(데이터에 대한 이해도)라고 생각한다. 데이터가 무엇을 의미하는지 알아야지만 정확한 분석이 가능하다.

Maybe I will be an AI Engineer?