Code From
https://github.com/772435284/transformers_versus_lstms_for_electronic_trading
ABSTRACT
시계열 데이터가 많은 금융 분야에서 LSTM이 우세한 위치에 있어 왔지만, 자연어 처리에 뛰어난 Transformer 모델이 LSTM 보다 뛰어나는지 여러가지 Task들을 통해 비교 분석
1. Introduction
주요 연구 방향
Orderbook
LOB (Limit Order Book) 데이터와 파생된 특징들(거래량 불균형Volume Order Imbalance, VOI, 거래 흐름 불균형Trade Flow Imbalance, TFI)을 기반으로한 예측
- (1) Mid-Price Prediction Prediction : best ask - best bid
- (2) Mid-Price Difference Prediction : 변화량 예측
- (3) Mid-Price Movement Prediction : 상승 / 하락 예측
(1) Transformer가 10~25% Error 값이 LSTM 보다 적지만, Trading에 적용시킬 정도로 유의미한 결과는 나오지 않음
(2) LSTM이 Transformer 보다 더 나은 성능을 보임 (R^2 = 11.5%)
(3) LSTM 기반 모델 'DLSTM'이라는 시계열 decomposition을 결합한 모델은 LSTM, Transformer 보다 더 Robust한 모형이고, 63.73~73.31% 정확도를 보여줌
Ticker
OHLCV 데이터와 파생된 금융 지표들(Relative Strength Index, RSI, Moving average convergence divergence, MACD)을 기반으로한 예측
2. Background and Related work
2.1 LSTM-based Time Series Prediction Solutions
- LSTM & Price Prediction
- Bidirectional LSTM (BiLSTM)
- Sequence-to-Sequence Model
- LSTM과 Attention Mechanism 결합
- CNN과 Attention Mechanism 결합
- DeepLOB (Seq2Seq + Attention Model)
- CNN-LSTM with OFI Feature LOB driven
2.2 Transformer-based Time Series Prediction Solution
Non Financial Data
- LogTrans
- Reformer
- Informer
- Autoformer
- Pyraformer
- FEDformer
Financial Data
-
Temporal Fusion Transformer와 SVR, LSTM을 결합한 Price Pridiction
-
Transformer를 이용하여 Dogecoin Price Pridiction
-
BERT를 사용하여 감성 분석 & 재무 지표와 결합해 GAN을 통한 Price Pridiction
3. Financial Time Series Prediction Tasks Formulation
- price, volumn 10개 호가 범위 + t 시점의 mid price 총 41개 Feature
Task 1: LOB Mid-Price Prediction
- target : t 시점의 mid price
Task 2: LOB Mid-Price Difference Prediction
Task 3: LOB Mid-Price Movement Prediction
- M-는 이전 k개의 MA 값, M+는 이후 k개의 MA 값
- k의 범위는 20, 30, 50, 100로 설정
- M+와 M-의 변화율
fall, rise가 반대 ?
Figure ETH-USDT

Green (Rise) , Red (Fall), Blue (Stationary)
4. Methodology
- DeepLOB-LSTM
- DeepLOB-Seq2Seq
- DeepLOB-Attention
4.1 LSTM-based Models : DeepLOB-LSTM
- Order Book을 분석하기 위해 설계된 LSTM 기반 학습 모델
- Convolution Block / Inception Module / LSTM 3가지 부분으로 나뉨
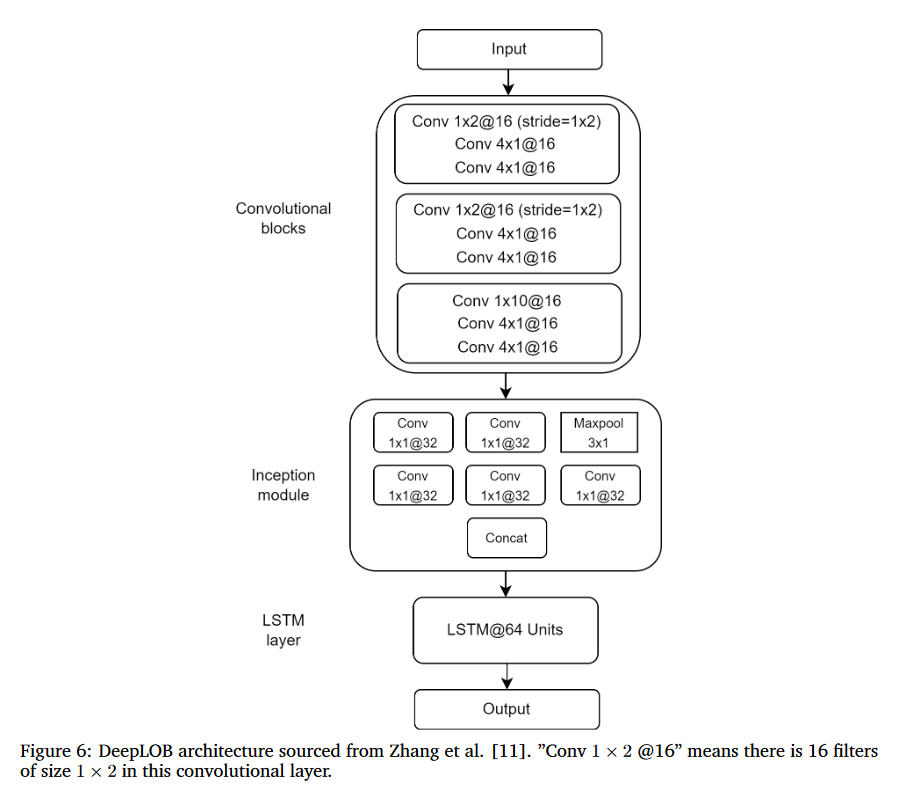
Convolution Block
- 첫 번째 블록은 (1×2) 필터 크기와 (1×2) stride를 가진 레이어로 구성되어 order book의 price & volumn 정보의 특징 추출
Imbalance
Micro Price
-
두 번째 블록도 마찬가지로 (1×2) 필터 크기와 (1×2) stride를 가진 레이어로 구성되고 이전 정보 특징 추출과 Micro Price Mapping
-
세 번째 블록은 이전 두 블록의 정보를 종합
Inception Module

CNN 특성상 더 깊고 자세히 Layer를 구성하면 성능이 좋아지지만, overfitting, running cost 등 많은 문제가 생기게 됨
이에 따른 방법론으로 Inception Module을 사용
- 인셉션 모듈은 시계열 분해 과정을 담당
- 입력 값은 두 개의 (1×1) 컨볼루션과 하나의 Maxpool 레이어에 의해 세 개의 저차원 표현으로 분해
- 32 채널의 컨볼루션 레이어를 통과
- 병합
LSTM
- Classification -> SoftMax Layer
- Regression -> Linear Layer
4.2 Transformer Models
- LogTrans
- Reformer
- Informer
- Autoformer
- Pyraformer
- FEDformer (가장 효율적)
5. Experimentation Result and Evaluation
5.1 Comparison of LOB Mid-Price Prediction
Data SET
- Binance에서 WebSocket API를 사용해 Tick 수집
- kdb+tick triplet DB 저장
- 2022/7/15에 수집된 BTC-USDT 하루 Orderbook / 863,397개 tick
- 시간 간격은 균일하지 않고, 평균 0.1초 단위로 들어옴
- Dataset은 z-스코어 정규화 방법으로 정규화
- Vaildation / Test set은 Train Set의 평균과 표준편차를 사용해 정규화
Model Train
- 모든 모델은 Adaptive Momentum Estimation Optimizer와 L2 Loss function를 사용
- 10 Epoch 동안 Batch Size 32이며, Learning Rate은 1e-4
- 모든 모델은 Pytorch를 사용해 구현
- NVIDIA RTX A5000 GPU(24 GB 메모리)에서 훈련
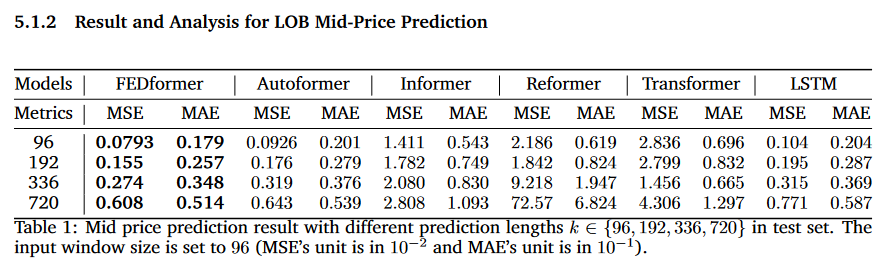
- Lookback은 96 input size
- 예측 범위를 {96, 192, 336, 720}로 나눠서 TEST
- 예측 길이가 길어질수록 (96에서 720으로 갈수록) MSE와 MAE가 일반적으로 증가하는 경향
- FEDformer와 Autoformer 모델은 비교적 낮은 MSE와 MAE 값을 보여 좋은 성능을 나타내는 반면, Refomer와 Transformer 모델은 높은 값을 보여 성능이 상대적으로 떨어짐
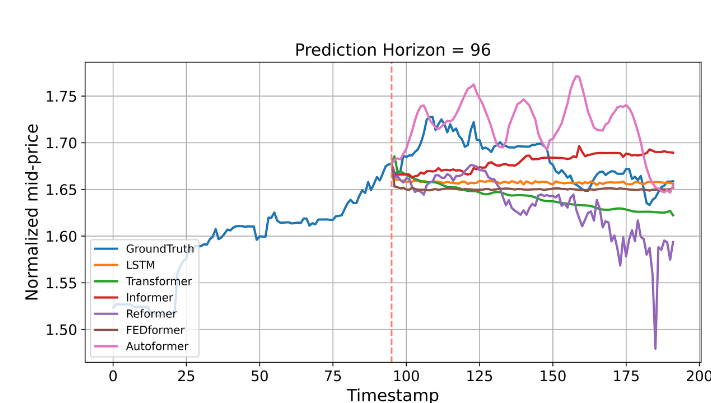
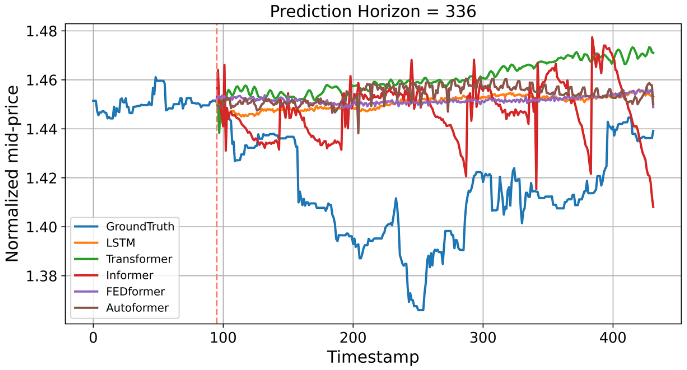
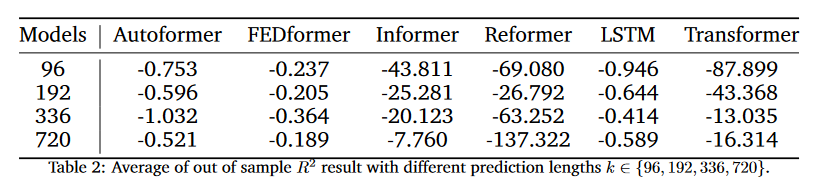
Autoformer와 FEDformer가 MSE와 MAE 측면에서 LSTM을 능가하긴 하지만, 실제 예측 성능은 R-squared 가 0보다 작으므로, 턱없이 부족
5.2 Comparison of LOB Mid-Price Diff Prediction
Data SET
- 2022/7/3 부터 7/6까지 4일간의 BTC-USDT
- Train/ Vaildation / Test : 80 / 10 / 10
Model Train
- LSTM, Vanila Transformer, DeepLOB, Informer, Reformer 5가지 모델
FEDformer와 Autoformer는 시간 분해(time decomposition) 방법을 사용하여 비정상 시계열 데이터에서 의미 있는 패턴을 추출하도록 설계되어 stationary 한 Time series인 현재 데이터에는 맞지 않아 배제함
Result
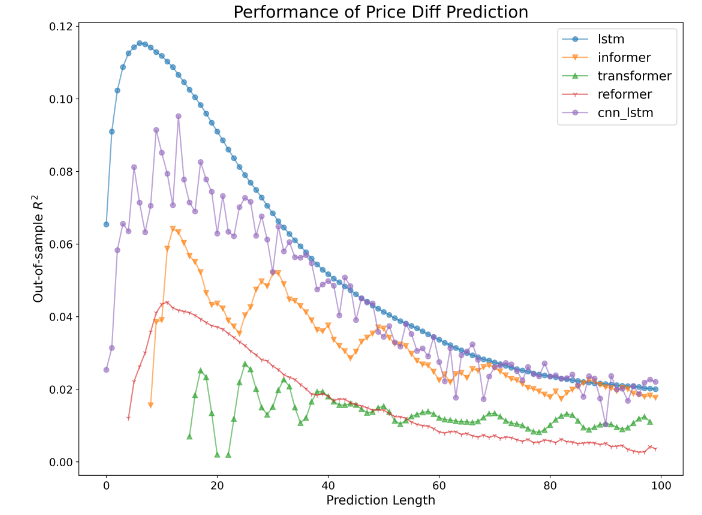
- LSTM이 모든 모델 중 가장 좋은 성능
- 대부분의 모델에서 예측 길이 5에서 15 사이에서 좋은 성능을 보이고
- LSTM이 해당 범위에서 약 11.5%의 가장 높은 R^2를 값을 가짐
- CNN-LSTM은 LSTM과 비슷한 성능을 보이지만, Informer, Reformer 및 Transformer는 LSTM보다 더 낮은 R^2 값을 가짐.
Mid-Price Diff Prediction에 있어서, LSTM 기반 모델은 Transformer 기반 모델보다 더 안정적이고 견고함
Reformer, Informer 및 Transformer가 이전 LOB Mid-Price Prediction에서 LSTM보다 성능이 떨어지는 단점이 그대로 나타남
- 금융 시계열 데이터는 높은 변동성, Noise를 LSTM이 더 잘 잡아내기 때문
- Transformer의 Attention은 시퀀스 내 모든 요소 간의 관계를 다루는데, 금융 시계열 데이터에서는 모든 시점 간의 관계가 동일하게 중요하지 않을 수 있음
5.3 Comparison of LOB Mid-Price Movement Prediction
5.3.1 Innovative Architecture on Transformer-based Methods
Transformer 모델은 회귀 작업에 적합하지만, 가격 움직임 예측과 같은 분류 작업에는 그대로 적용하기 어려움
따라서 회귀 작업으로 예측된 시퀀스 값을 Linear Layer와 Softmax를 통해 Classification Task로 변환해줌
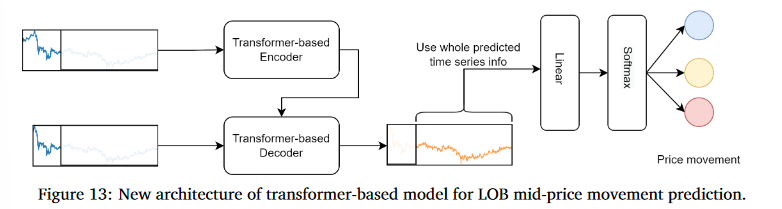
5.3.2 DLSTM: Innovation on LSTM-based Method
DLSTM은 기존 LSTM 모델을 개선헤 시계열 데이터를 두 부분으로 나누어 처리하는데, 하나는 장기적인 추세(Trend)를 나타내고 다른 하나는 단기적인 변동(Remainder)을 나타냄
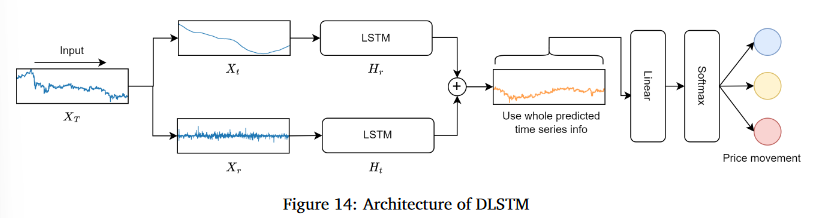
- Xt : 시계열의 이동 평균
- Xr : Xt와의 차이 값, 즉 EMA Spread
5.3.4 Result and analysis for LOB Mid-Price Movement Prediction
Data SET
-
2022/7/3 ~ 7/14, 총 12일간의 ETH-USDT (총 10,255,144개의 Tick)
-
Train 데이터는 처음 6일 동안의 데이터를 사용하고, Vaildation / Test 데이터는 마지막 3일 동안의 데이터를 사용
Model Train
- Vanilla Transformer
- Reformer
- Informer
- Autoformer
- FEDformer
- Vanilla LSTM
- DLSTM
- DeepLOB
- DeepLOB-Seq2Seq
- DeepLOB-Attention
- MLP
Batch Size : 64, Lossfunction : Cross Entropy Loss
Result
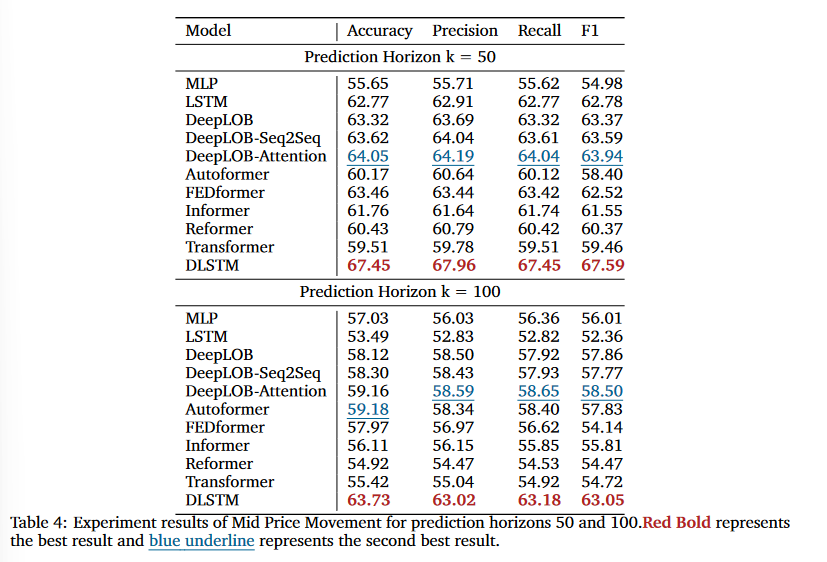
DLSTM의 시계열 분해 구조와 DMS(미래의 값을 한 번에 예측하는 과정Direct Multi-Step Prediction)에서 단일 값을 예측하는 방식을 취하고 있으므로 Error가 커지는 현상이 줄어듦
LSTM 기반 모델들이 일반적으로 금융 시계열 데이터에 대한 Robustness과 compatibility으로 인해 장점이 있음
Transformer 기반 모델은 크고 조정하기 복잡하며 긴 훈련 시간을 필요로 하지만, Autoformer에서의 Time decomposition 방법론 같이 새로운 관점을 제공해주기도함.
5.3.5 Simple Trading Simulation without transaction cost
trading latency
a prediction 2 at time t, μ shares will be bought at time t + 5.
Result
- s : 포지션 (Long 1 / Short 0)
- μ : 단일 Crypto (거래량 하나에 대해서)
- p_holding : 청산 가격
- p_settlement : 진입 가격
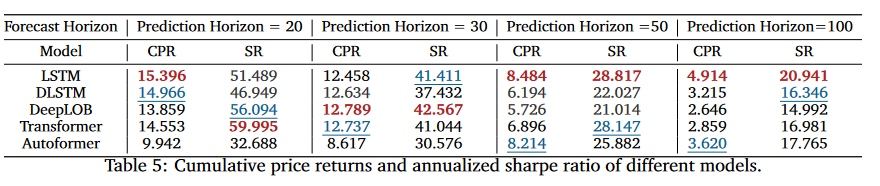
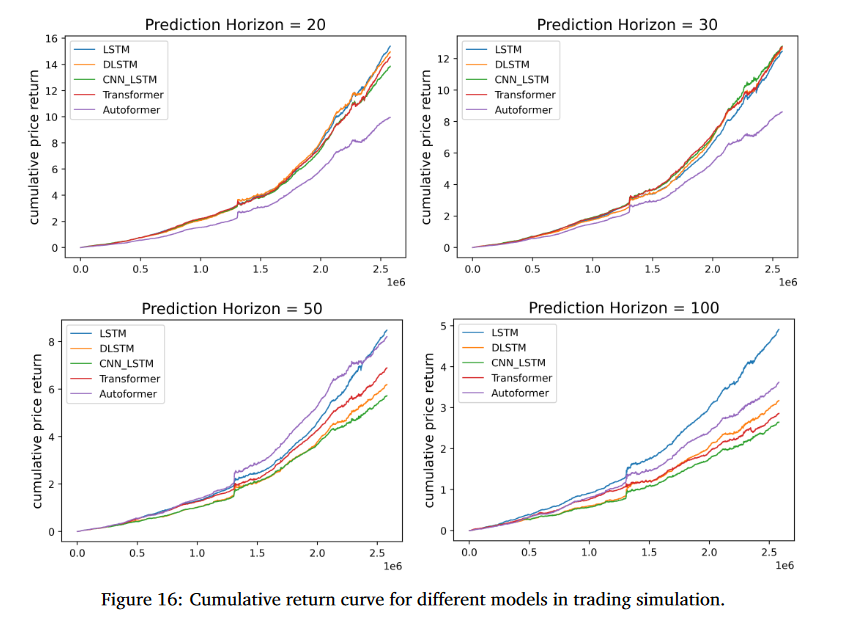
-
Sharp Ratio : 시뮬레이션에서 사용된 가정들이 실제 거래에서 비현실적이기 때문에, 값이 잘 나오지만, 실제 거래에서는 시장 영향력, 거래 비용 같은 요소들을 반영해야 함
-
LSTM 기반 모델의 예측 결과는 일반적으로 Transformer 기반 모델의 결과보다 시뮬레이션 거래에서 더 나은 성능을 보여줌 또한 LSTM 계열 모델은 예측 범위 20과 30에서 가장 높은 CPR과 SR을 보임
5.3.6 Simple Trading Simulation with transaction cost
-
수수료 0.002%라는 가상의 수치를 도입하여 모델의 견고성을 비교
-
DLSTM은 CPR과 SR을 달성해 DLSTM이 거래 비용으로 인한 위험에 대한 강한 수익성과 견고성을 가지고 있음을 보여줌
-
일반적으로 LSTM 기반 방법의 성능이 Transformer 기반 방법보다 우수함을 확인
거래 비용
거래 비용이 증가함에 따라 CPR과 SR이 어떻게 변하는지를 보는 추가 실험 진행
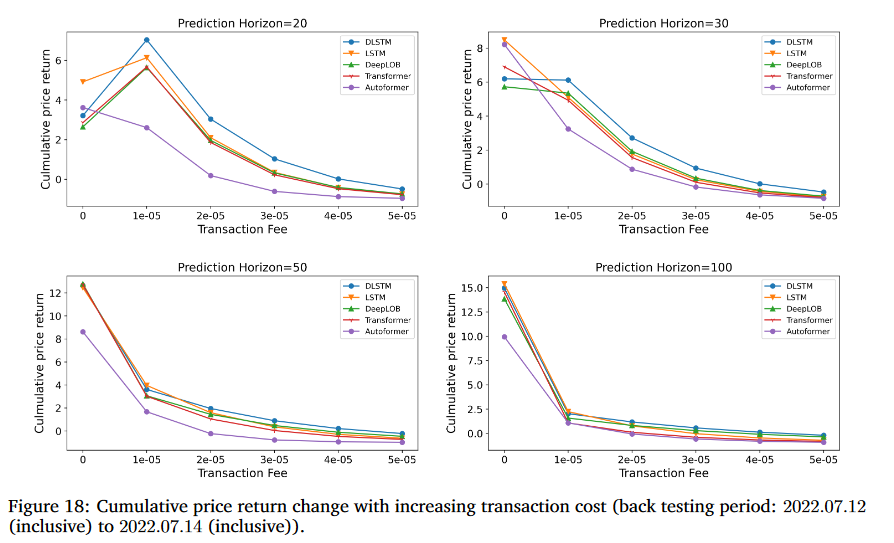
거래 비용을 고려한 시뮬레이션 거래에서 LSTM 기반 모델이 Transformer 기반 모델보다 상대적으로 더 나은 모델임을 다시 한번 확인가능
Model Selection
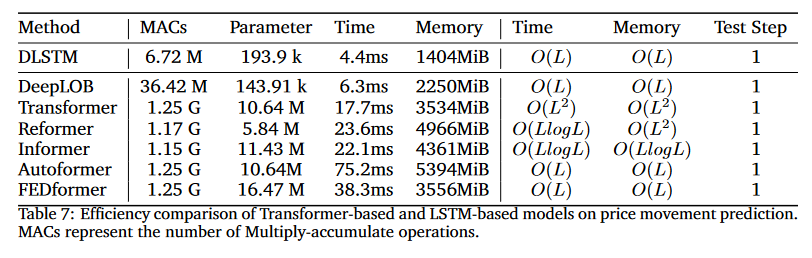
-
LSTM 기반 모델은 낮은 추론 시간과 작은 모델 크기로 인해 Transformer 기반 모델보다 높은 효율성을 가지기에 HFT에서 LSTM 기반 모델이 더 나은 모델임
-
HFT와 같은 환경에서는 모델의 복잡도와 크기가 중요한 역할을 하기 때문에, LSTM과 같은 더 단순하고 효율적인 모델이 더 선호됨
-
시계열 데이터를 다루는 데 있어 모델의 선택이 단순히 최신이라는 이유만으로 결정되어서는 안 되며, 실제 상황에서의 효율성과 성능이 중요함
Insight
-
DLSTM, DeepLOB로 현재 프로젝트 Task에 바로 적용 시켜 볼 필요가 있음
-
향후 변동성을 얼마나 잘 예측 했는지에 대한 Metric 필요성
e.g. 일정 절대값 이상에 대한 예측치
