[OS] CPU Scheduling
Basic concepts
"CPU는 쉬는 시간이 없다"
따라서 빈 시간이 없게 프로세스를 채워줘야 한다.
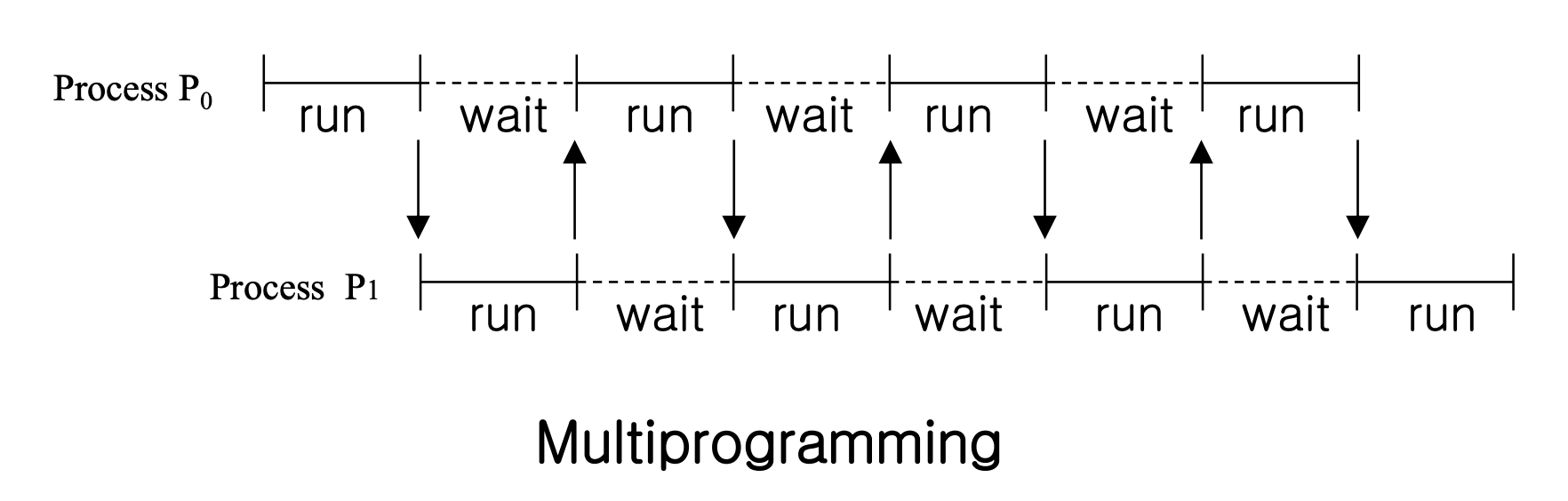
Burst
- CPU Burst : 프로세스가 CPU를 활용하여 명령을 처리하는 짧은 기간
- I/O Burst : ""
- 일반적으로 프로세스는 CPU burst(활동적인 연산)와 I/O burst(입출력 대기) 사이를 번갈아 가며 진행
- 프로세스의 시작과 끝은 CPU burst
Type of Process
- CPU Bound Process : CPU Busrt 가 긺
- I/O Bound Process : CPU Busrt 가 짦음
우리가 사용하는 프로세스는 대부분 I/O Bound Process
CPU Schduler
Ready Queue에서 프로세스를 가져와 CPU에 전달
- 주로 Priority Queue 구조이고, 데이터는 PCB

Scheduling 발생 시점
1) 프로세스가 실행(running) 상태에서 대기(waiting) 상태로 전환될 때
2) 프로세스가 실행 상태에서 준비(ready) 상태로 전환될 때 - 인터럽트가 발생했을 때
3) 프로세스가 대기 상태에서 준비 상태로 전환될 때 - 입출력(I/O) 작업이 완료되었을 때
4) 프로세스가 종료(terminated)될 때
- 1, 4는 반드시 스케줄링이 일어나지만, 2, 3은 선택
Preemptive scheduling
실행 중인 프로세스를 중단하고 다른 프로세스에 CPU를 할당할 수 있는 권한을 가진 Scheduling
- Ex) interrupt, process with higher priority
- 1) ~ 4) 모든 상황에서 Scheduling 발생
- 하드웨어의 지원과 공유 데이터를 다루는 메커니즘이 필요
Race Condition
- 프로세스 또는 스레드가 공유된 자원에 동시에 접근하려 할 때, 그 접근 순서에 따라 결과가 달라지는 상황을 의미
- 선점형 스케줄링을 사용하는 시스템은 이러한 문제를 해결하기 위해 동기화 메커니즘을 사용하여 자원에 대한 접근을 조정해야 함
- mutexes, semaphores, lock
Non Preemptive scheduling
- 1) , 4) 에서 Scheduling 발생
- 실행 중인 프로세스는 Interrupted 되지 않음
Preemptive Kernel
시스템 호출 중에도 프로세스를 선점할 수 있는 기능을 제공하는 커널
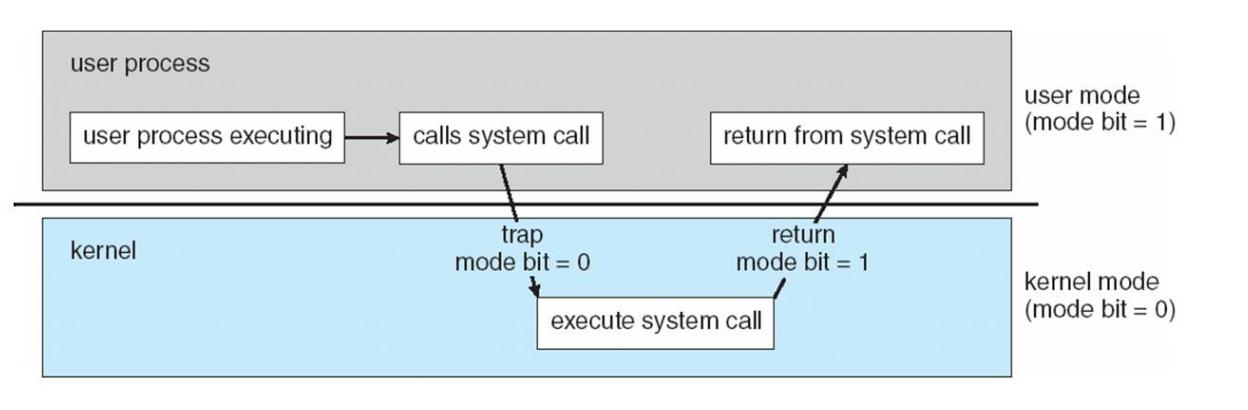
Dispatcher
짧은 기간 동안 스케줄링(short-term scheduling)에 의해 선택된 프로세스에게 CPU의 제어를 넘겨주는 역할
- Switching context : 현재 실행 중인 프로세스의 상태(컨텍스트)를 저장하고, CPU가 다음에 실행할 프로세스의 상태를 로드
- 컨텍스트에는 프로세스의 PC(program counter), 레지스터 상태, 메모리 관련 정보 등이 포함
- Switching to user mode : CPU를 사용자 모드로 전환하여, 다음 프로세스가 사용자 수준의 코드를 실행할 수 있도록 함
- Jumping to proper location in user program: 새로 실행될 프로세스가 이전에 중단된 지점이나 적절한 시작 지점에서 실행을 계속할 수 있도록 프로그램 카운터를 설정
- Dispatch latency : 프로세스의 실행을 멈추고 다음 프로세스가 시작되기까지 걸리는 시간을 의미, 지연 시간은 가능한 한 짧아야 함
Scheduling Criteria (스케줄링 기준)
스케줄러가 어떻게 작동해야 할지 결정할 때 고려하는 다양한 성능 지표
- CPU Utilization : CPU를 가능한 한 바쁘게 유지하여, 비활동적인 시간을 최소화
- Throughput : 시간 단위당 완료되는 프로세스의 수
높은 처리량은 시스템이 많은 일을 처리하고 있다는 것을 나타냄- Turnaround Time : 프로세스가 제출되고 완료될 때까지의 시간 간격
반환 시간에는 프로세스의 실행 시간과 대기 시간이 모두 포함- Waiting Time : 준비 큐에서 실제 실행되지 않고 대기하는 데 소비되는 시간의 총합
프로세스가 CPU를 할당받기 전에 얼마나 오래 대기했는지를 나타냄- Response Time : 요청이 제출된 후 첫 번째 응답을 받기까지의 시간
대화형 시스템에서 사용자가 시스템의 반응을 느끼는 데 중요한 지표
Scheduling algorihtms
First-come, first-served (FCFS) scheduling
- 선입 선출 스케줄링
- Non Preemptive scheduling (Interrupt X)
- 실행 시간이 긴 프로세스가 도착하면 뒤에 도착한 짧은 프로세스들이 오랫동안 대기해야 하는 convoy effect 발생
Shortest-job-first (SJF) scheduling
- Burst Time이 짧은 순서대로 할당
- 프로세스 대기 시간의 합이 최소가 되므로, 이론적으로는 최소 평균 대기 시간 (Optimal)
- non-preemptive 방식과 preemptive 방식 둘 다 가능
문제점
- 실제 시스템에서는 프로세스의 다음 CPU Burst 길이를 정확히 알기 어려움
- starvation / indefinite postponement가 발생
Priority scheduling
프로세스마다 우선순위를 부여하고, 우선순위에 따라 CPU 접근 순서를 결정하는 알고리즘
Internal Priority (내부적 우선순위)
- Time Limit : 정해진 시간 내에 완료해야 하는 작업에 더 높은 우선순위를 부여
- Memory Requirement : 더 적은 메모리를 요구하는 프로세스에 높은 우선순위
- Number of Open Files : 자원 사용이 많은 프로세스에 낮은 우선순위를 부여
- I/O 버스트 대 CPU 버스트 비율 : I/O 중심의 작업에 더 높은 우선순위를 부여하여, CPU는 계산 작업에 더 많이 사용
External Priority (외부적 우선순위)
importance, political factor (OS 정책)
문제점
starvation -> aging (우선 순위 늦춰질 때마다 우선 순위 높여줌)
Round-robin scheduling
다중 프로그래밍 환경에서 공정한 CPU 시간 분배를 위해 설계된 선점형 스케줄링 방법
각 프로세스는 CPU를 사용할 수 있는 고정된 시간(타임 퀀텀 또는 타임 슬라이스)을 할당 받음
- preemptive scheduling
time-sharing system : 여러 사용자가 시스템을 공유하면서 각각에게 CPU 시간을 공평하게 배분하기 위해 적용
time quantum : 일반적으로 10~100 밀리초로 설정되며, 이 시간 동안 프로세스가 실행
너무 짧으면 컨텍스트 스위칭으로 인한 오버헤드가 증가하고, 너무 길면 라운드 로빈의 응답 시간이 길어질 수 있음
switching latency : 프로세스를 전환할 때 발생하는 지연 시간은 일반적으로 10 마이크로초로 매우 짧음 하지만 프로세스 전환 횟수가 많으면 이 지연이 누적되어 시스템의 효율성에 영향을 줄 수 있음
circular queue : Ready queue는 순환 구조로 운영되며, 모든 프로세스는 큐에서 동등한 기회를 가짐
CPU 스케줄러의 역할: Ready queue에 있는 프로세스들을 순회하며 각각에게 한 번에 하나의 타임 퀀텀 동안 CPU 시간을 할당
Multilevel queue scheduling
프로세스를 여러 그룹으로 분류하고 각 그룹에 다른 스케줄링 알고리즘을 적용하는 방식
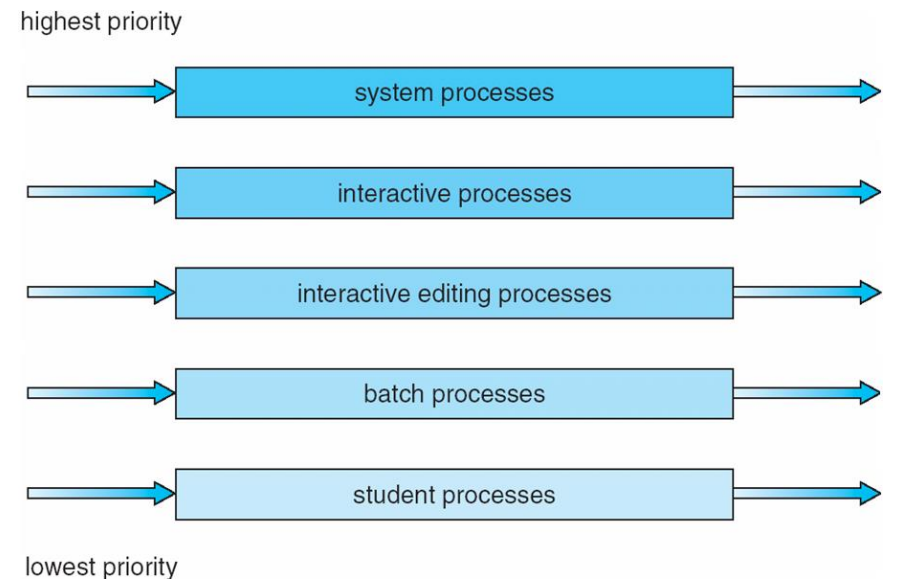
- Fixed-priority preemptive scheduling : 낮은 우선순위의 프로세스는 높은 우선 순위의 프로세스가 끝나야지만 실행 가능
- Time-slicing among queues : foreground queue (interactive processes 대화형 프로세스): 80% / background queue (batch processes 사용자의 개입 x): 20%
- permanent : 시스템 내에서의 우선순위나 역할이 변경되지 않는 한, 프로세스가 한 번 특정 큐에 할당되면, 그 큐에 계속 속하게 됨
Multiple feedback-queue scheduling
큐 간의 이동 가능 : 프로세스는 실행 도중에 그 특성에 따라 다른 큐로 이동할 수 있음
이는 프로세스의 우선순위가 시간이 지나면서 변할 수 있음을 의미
CPU 버스트 특성에 따른 분류: 프로세스는 그들의 CPU 사용량에 따라 큐를 이동
예를 들어, CPU 시간을 많이 소비하는 프로세스는 낮은 우선순위 큐로 이동시켜, 덜 자원을 요구하는 프로세스에게 더 많은 기회를 주도록 함
I/O-바운드 및 대화형 프로세스의 우선순위: I/O 작업이 많거나 사용자와의 상호작용이 필요한 프로세스는 높은 우선순위 큐에 배치되어 빠른 응답성을 유지함
=시스템의 반응 시간을 최적화하고 사용자 경험을 향상시키는 데 중요
Multiple-processor scheduling
여러 CPU를 사용하는 시스템에서 프로세스를 효과적으로 관리하고 할당하는 데 필요한 스케줄링 방법
- Load Sharing : 여러 프로세서가 작업을 공유함으로써, 하나의 프로세서에 모든 부하가 집중되는 것을 방지
Multiprocessing
Symmetric Multiprocessing, SMP
대칭형 처리에서는 모든 프로세서가 메모리와 I/O를 포함한 시스템 자원을 공유합니다.
모든 프로세서가 동일한 역할을 수행하며, 어떤 프로세서도 다른 프로세서보다 우선 순위가 높지 않습니다. 이 구조에서는 모든 프로세서가 운영 체제의 하나의 인스턴스 아래에서 동등하게 작업을 수행합니다.
장점: 프로세서 간의 균등한 작업 분배로 인해 부하 균형이 잘 이루어지며, 시스템 자원의 활용도가 높다.
단점: 모든 프로세서가 동일한 메모리와 I/O 자원을 공유하기 때문에, 자원 접근에 대한 병목현상이 발생할 수 있다.
Asymmetric Multiprocessing, AMP
비대칭형 처리에서는 주로 한 개 또는 소수의 프로세서가 시스템 관리와 같은 특정 작업을 처리하며, 나머지 프로세서는 사용자 애플리케이션 처리와 같은 다른 작업에 집중한다. 이 구조에서는 "Master" 프로세서가 시스템 관리를 담당하고, "Slave" 프로세서들이 주어진 작업을 실행한다.
장점: 특정 프로세서가 시스템 관리를 전담함으로써 다른 프로세서들이 작업 처리에 더 집중할 수 있다. 관리와 실행 작업의 분리로 인해 효율적인 작업 처리가 가능하다.
단점: 마스터 프로세서에 과부하가 걸리거나 실패하는 경우, 시스템 전체의 성능에 영향을 줄 수 있다.
Thread Managing Strategies
Processor Affinity
Overhead of migration
프로세스가 다른 프로세서로 이동하면 프로세서가 사용하던 데이터 명령어가 저장되어 있는 캐시가 날라가게 됨 ->
또 다시 불러와서 저장하고 캐시 만들고 어쩌구 저쩌구...
Processor Affinity
프로세스 친화성은 프로세스를 가능한 같은 프로세서에서 계속 실행시켜 마이그레이션으로 인한 오버헤드를 줄이려는 전략이 필요함
Soft Affinity: 운영 체제는 프로세스를 가능한 동일한 프로세서에서 실행시키려고 시도한다.
그러나 필요에 따라 프로세스는 다른 프로세서로 이동할 수 있다.
Hard Affinity: 특정 프로세스가 다른 프로세서로 마이그레이션되는 것을 완전히 막는다.
이는 프로세스가 특정 프로세서의 리소스(예: 캐시 메모리)를 최대한 활용하도록 하여, 성능을 최적화한다.
NUMA
Load Balancing
모든 프로세서에 작업 부하를 고르게 분산시키려는 시도로, 멀티프로세서 시스템의 성능을 최적화하는 데 필수적
각 프로세서가 자신만의 준비 큐를 가지고 있는 시스템에서는 더욱 중요
Push Migration
특정 작업이 주기적으로 각 프로세서의 부하를 확인하고, 부하 불균형이 발견되면 과부하된 프로세서에서 유휴 상태 또는 상대적으로 바쁘지 않은 프로세서로 프로세스를 이동시키는 방식
장점: 시스템 전체의 부하가 증가하는 상황에서 효과적으로 대응 가능
단점: 부하 상태를 주기적으로 체크하고 프로세스를 이동시키는 데 추가적인 자원이 소모 됨
Pull Migration
유휴 상태인 프로세서가 작업을 ‘당겨오는’ 방식
프로세서는 대기 중인 작업을 자동으로 가져와 처리
장점: 유휴 프로세서가 능동적으로 작업을 처리하게 함으로써 자원 활용도를 높일 수 있다
단점: 작업을 가져올 때, 적절한 작업 선택과 메모리 접근에 따른 지연이 발생할 수 있다
Multi-core Processor
하나의 물리적 칩에 여러 개의 프로세서 코어를 통합한 것으로 단일 코어 프로세서에 비해 처리 속도가 빠르고, 전력 소비가 적은 장점이 있음
각 코어가 독립적으로 작업을 처리할 수 있으며, 이로 인해 멀티프로세싱보다 훨씬 효율적인 작업 수행이 가능
Issue
Memory Stall : 멀티코어 프로세서에서는 각 코어가 메모리에 동시에 접근하려고 할 때, 데이터가 캐시에 없는 경우 심각한 지연이 발생할 수 있음. 이러한 상황은 프로세서가 데이터를 기다리는 동안 대기해야 하므로 성능 저하를 초래함
Cache Coherence: 멀티코어 프로세서에서 각 코어의 캐시 사이에 데이터의 일관성을 유지하는 것이 중요하다 이는 캐시된 데이터가 최신 상태를 유지하도록 보장하여, 데이터 불일치로 인한 문제를 방지한다.
Multi-Threaded Processor Cores
위 Issue 해결책으로 멀티쓰레드 프로세서 코어는 하나의 코어에 두 개 이상의 하드웨어 쓰레드를 할당하여, 한 쓰레드가 메모리에 접근을 기다리는 동안 다른 쓰레드가 계산을 계속할 수 있도록 합니다.

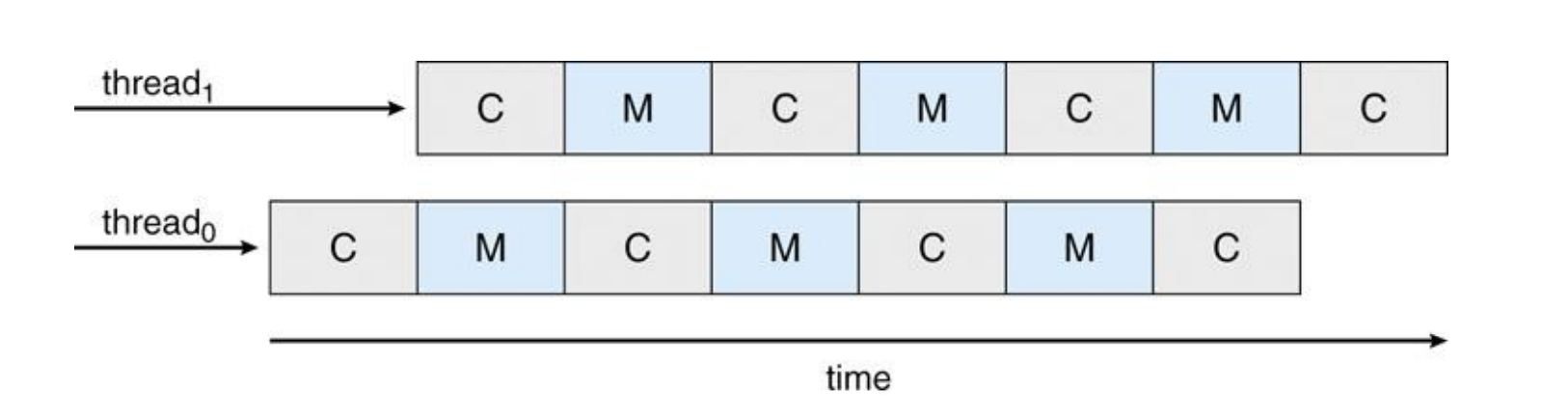
Thread scheduling
Contention Scope
스레드가 경쟁하는 자원의 범위
Process-contention scope (PCS)
사용자 스레드가 경량 프로세스(LWP)에 대한 접근을 경쟁하는 범위
- Many to One
- Many to Many
System-contention scope (SCS)
커널 스레드가 CPU 자원에 대한 접근을 경쟁하는 범위
- 운영 체제가 스레드를 어떻게 스케줄할지 결정하는 기준
Pthread
pthread_attr_setscope(pthread_attr_t *attr, int scope)
스레드 속성 객체에 스케줄링 스코프를 설정
scope : PTHREAD_SCOPE_SYSTEM / PTHREAD_SCOPE_PROCESS
pthread_attr_getscope(pthread_attr_t *attr, int *scope)
설정된 스케줄링 스코프를 조회
int main()
{
pthread_t thread;
pthread_attr_t attr;
int scope;
// 스레드 속성 초기화
pthread_attr_init(&attr);
// 스레드 속성에 시스템 콘텐션 스코프 설정
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
// 설정된 스코프 확인
if (pthread_attr_getscope(&attr, &scope) != 0)
{
perror("pthread_attr_getscope");
}
else
{
if (scope == PTHREAD_SCOPE_SYSTEM)
{
printf("Scope set to PTHREAD_SCOPE_SYSTEM\n");
}
else if (scope == PTHREAD_SCOPE_PROCESS)
{
printf("Scope set to PTHREAD_SCOPE_PROCESS\n");
}
else
{
printf("Scope set to unknown\n");
}
}Real-time CPU scheduling
실시간 운영 시스템 | 엄격한 시간 제약을 충족하는데 중점을 둔 시스템
- e.g. 자동차 브레이크를 밟았는데, 5초 뒤에 멈춘다??????
Soft Real-Time Systems
소프트 실시간 시스템은 실시간 작업의 정시성을 보장하기 위해 노력하지만, 모든 실시간 제약을 엄격하게 만족시키는 것은 보장하지 않음
Hard Real-Time Systems
작업이 정해진 데드라인 내에 반드시 완료되어야 하고, 데드라인 못 지킨 것들은 실패처리 됨
Minimizing Event latency
Most real-time systems are event-driven system : Interrupt
Interrupt Latency
외부 이벤트가 발생하고 시스템이 해당 인터럽트를 인식하기까지의 시간
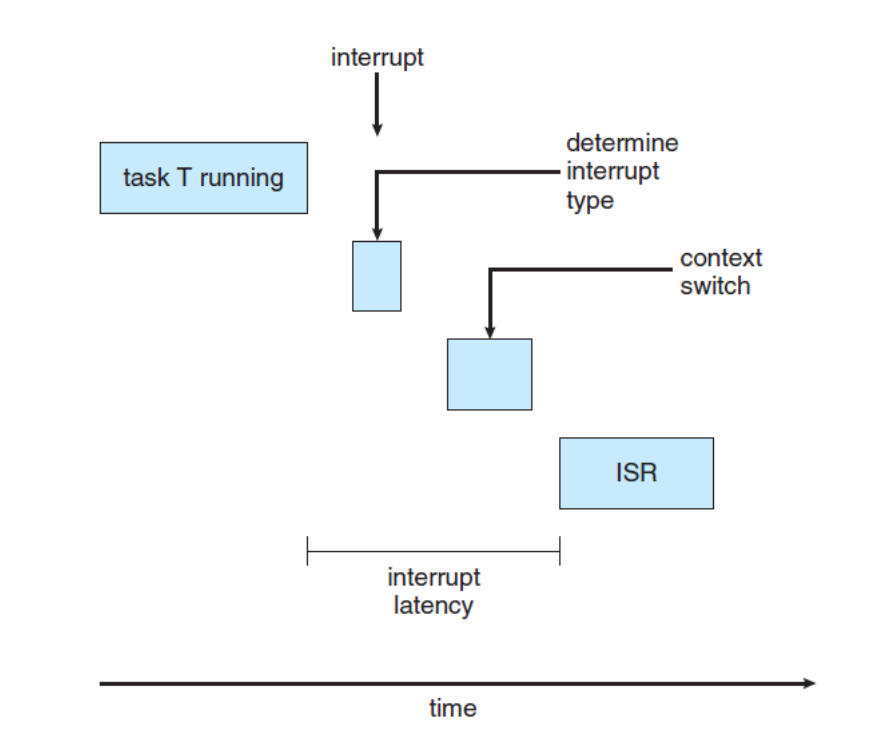
Dispatch Latency
인터럽트가 처리된 후 적절한 핸들러나 서비스 루틴으로 제어가 전달되는 데까지 걸리는 시간
- Preemptive Kernels는 디스패치 지연을 낮게 유지하는 가장 효과적인 기술 중 하나
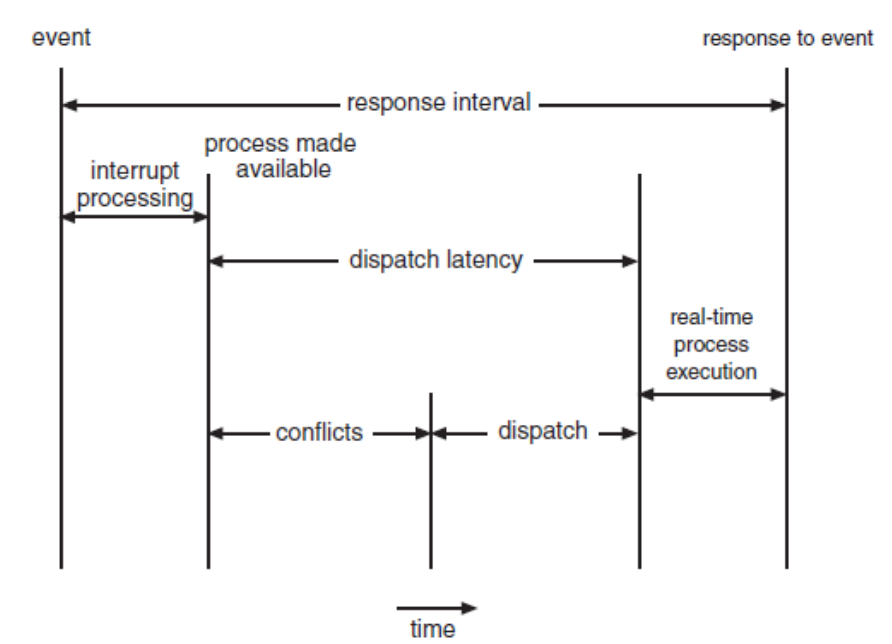
Conflict Phase
시스템이 긴급하게 처리해야 하는 고우선순위의 작업을 실행할 수 있도록 필요한 조건을 만들어줌
- [1] Preemption (선점) : 현재 커널 모드에서 실행 중인 낮은 우선순위의 프로세스가 있을 경우, 멈춤
- [2] Release of resources : 최우선 순위 프로세스가 필요로 하는 resources가 우선순위가 낮은 프로세스에 묶여 있다면, 해당 resources를 최우선 프로세스에게 넘김
Dispatch Phase
준비가 완료된 후 최우선순위 프로세스를 CPU에 스케줄링
- 최우선순위 프로세스 스케줄링 : 모든 준비가 완료되면, 스케줄러는 고우선순위 프로세스를 사용 가능한 CPU에 할당
- Context Switch : 선점된 낮은 우선순위 프로세스의 컨텍스트(즉, CPU 상태 정보)를 저장하고 고우선순위 프로세스의 컨텍스트를 로드합니다.
Periodic Process
일정한 간격(주기)으로 CPU를 필요로 하는 프로세스
- t : 프로세스가 CPU에서 실행되어야 하는 고정된 시간
- d : dead line | 프로세스가 서비스를 받아야 하는 최종 시간
- p : 프로세스가 반복적으로 CPU를 요구하는 간격
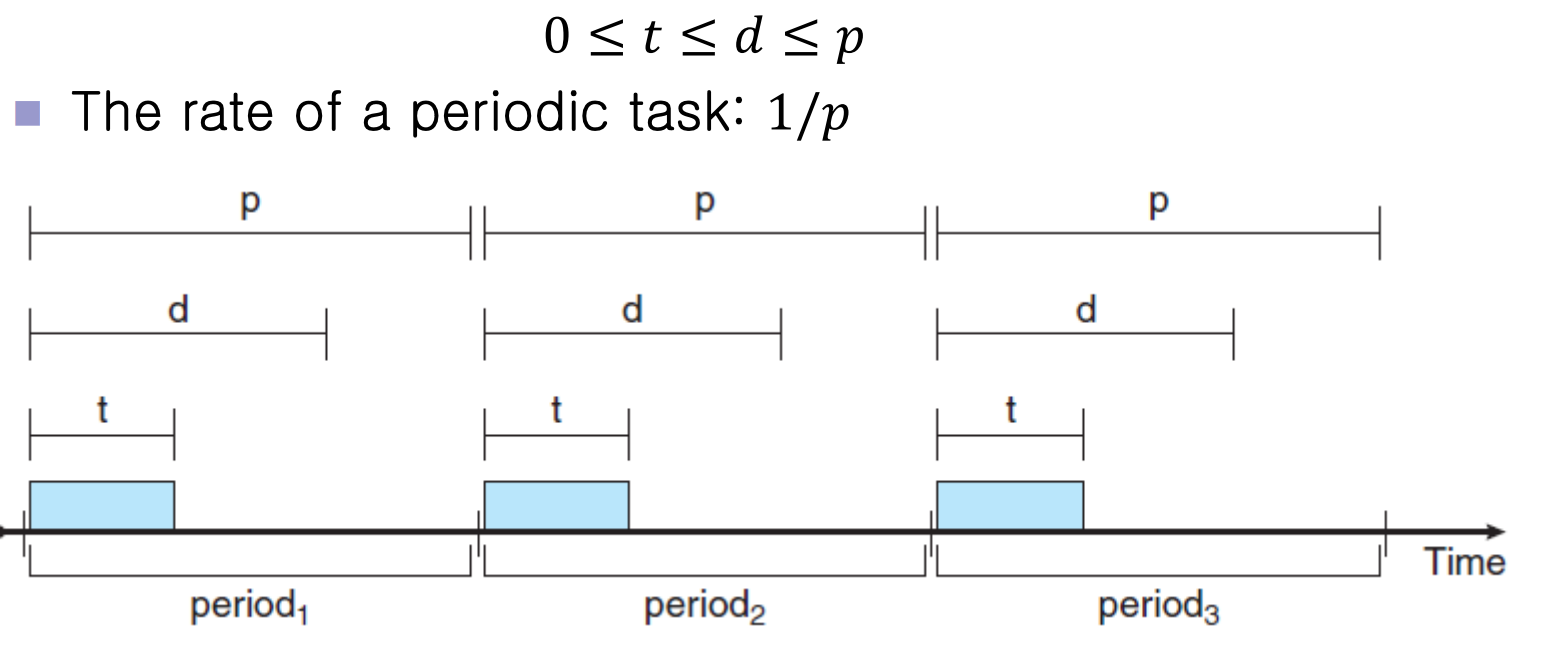
POSIX Real-Time Scheduling
SCHED_FIFO : FCFS policy (FIFO)
같은 우선순위를 가진 스레드 사이에는 시간 할당(time slicing)이 없음
가장 높은 우선순위를 가진 실시간 스레드가 큐의 앞쪽에 있을 때,
그 스레드는 종료되거나 차단(block)될 때까지 CPU를 점유주로 단순하고 예측 가능한 실시간 스케줄링이 필요할 때 사용
SCHED_RR : a round-robin policy.같은 우선순위를 가진 스레드 사이에는 시간 할당이 있어, 각 스레드가 동일한 시간 동안 CPU를 사용
task 사이에 공정한 CPU 점유 시간 배분이 필요할 때 사용
int i = 0, policy = 0;
pthread_t tid[NUM_THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* get the current scheduling policy */
if(pthread_attr_getschedpolicy(&attr, &policy) != 0)
fprintf(stderr, "Unable to get policy.\n");
else
{
if(policy == SCHED_OTHER)
printf("SCHED OTHER\n");
else if(policy == SCHED_RR)
printf("SCHED RR\n");
else if(policy == SCHED_FIFO)
printf("SCHED FIFO\n");
}
/* set the scheduling policy
- FIFO, RR, or OTHER */
if (pthread_attr_setschedpolicy(&attr, SCHED_FIFO) != 0)
fprintf(stderr, "Unable to set policy.\n");
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
Linux Scheduler
Completely Fair Scheduler (CFS)
- 리눅스의 기본 스케줄링 알고리즘
- 모든 태스크에 대해 '공평하게' CPU 시간을 분배
- CFS는 시간 분할(time slice) 방식을 사용하여, 실행 가능한 각 태스크에 실행 시간을 할당
- 스태틱 우선순위 범위는 100에서 139 사이
NICE
- CFS는 모든 실행 가능한 태스크에 대해 비례적인 CPU 시간을 할당
- 이 할당은 nice 값에 의해 조정 됨
- 태스크의 상대적 우선순위를 나타내며, 범위는 -20(가장 높은 우선순위)부터 +19(가장 낮은 우선순위)까지
- 기본값은 0
Targeted Latency
- 스케줄러가 설정한 시간 간격으로, 이 기간 동안 모든 실행 가능한 태스크가 적어도 한 번씩 실행되어야함
- 기본값과 최소값은 시스템 설정에 따라 다를 수 있으며, 태스크의 수가 특정 임계값을 초과할 경우 증가할 수 있음
Real-Time Scheduling Class
- 실시간 스케줄링 클래스에는 SCHED_FIFO와 SCHED_RR이 포함
- 스태틱 우선순위는 0에서 99 사이
- 실시간 태스크가 비실시간 태스크보다 높은 우선순위를 갖도록 함
Operation system examples
