[Trading Machine Project] Code Review : SGX-Full-OrderBook-Tick-Data-Trading-Strategy
Trading Machine Project
목록 보기
5/20
Code From
https://github.com/rorysroes/SGX-Full-OrderBook-Tick-Data-Trading-Strategy/tree/master
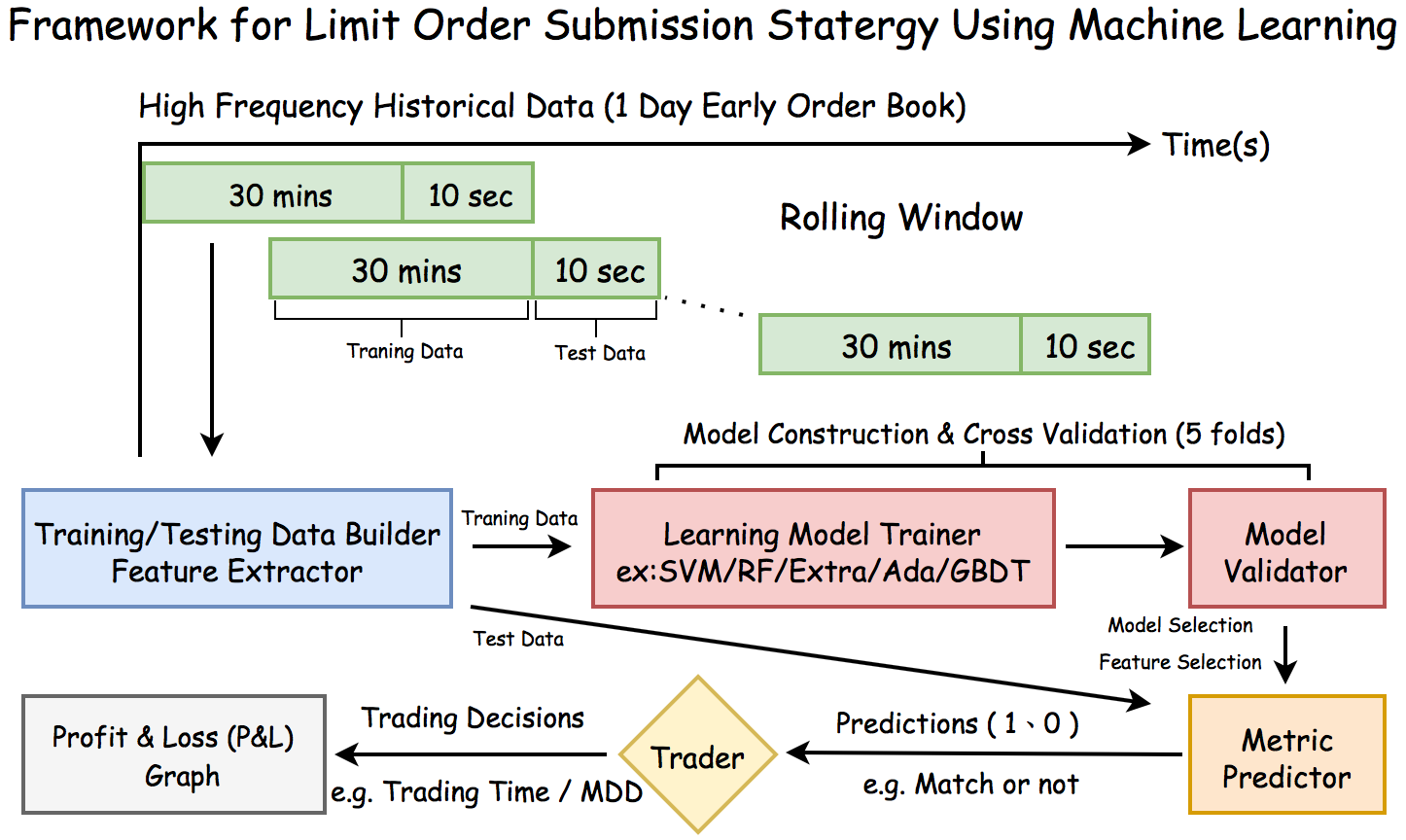
Overview
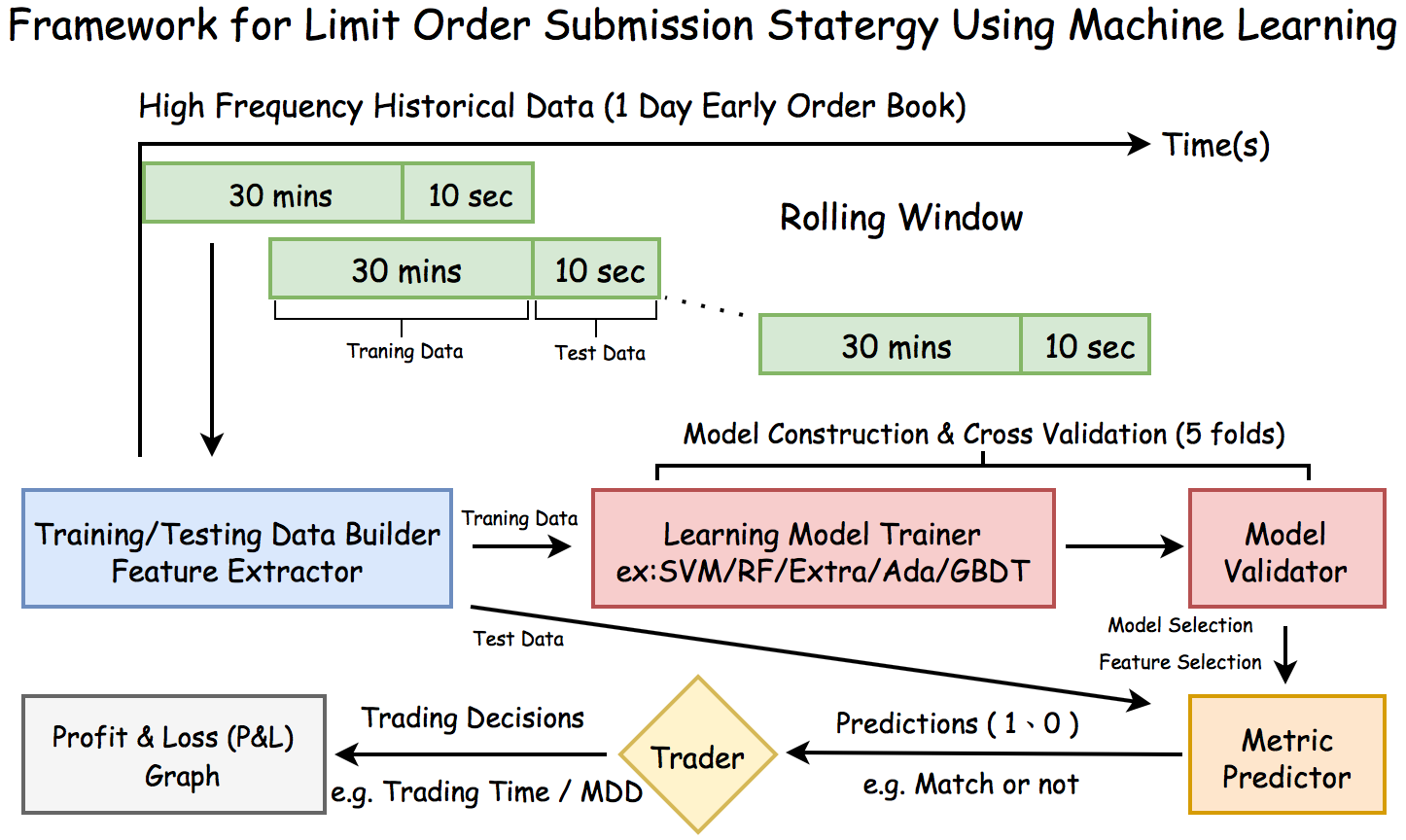
Data : 중국 A50 주가 지수 선물 (SGX:CN : FTSE–Xinhua China A50 Index)의 2014/01/02 Intraday OrderBook Tick Data (7 Hours)
Purpose : 과거 30분을 Train 하여 향후 10초의 각각의 target을 Prediction
- target : 현재 시점 기준 bid_best_price가 600초 이후 체결이 될 것 인지 (1/0)
Workflow
Raw Data

- Timestamp
- Ask Price 1,2,3
- Bid Price 1,2,3
- Ask Size 1,2,3
- Bid Size 1,2,3
Feature Engineering
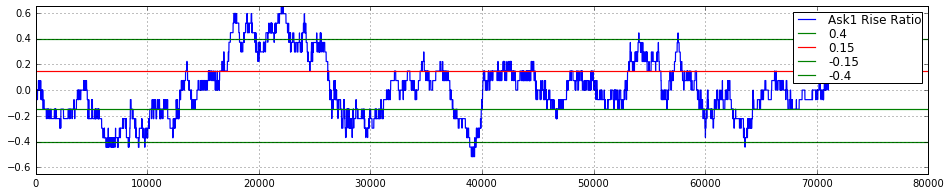
rise_ask()
- before_time 동안 ask1 price의 return을 계산
- before_time 기준 값들은 6m 00s ~ 20m 30s 까지 30s 단위로
weight_pecentage()
- 각 호가 깊이 별 가중치가 곱해진 bid ask 호가 비율 (Depth ratio)
- bid ask 호가 비율 상대적인 차이를 정규화하여 -1 ~ 1 사이 값으로 표시
def weight_pecentage(w1,w2,w3,ask_quantity_1,ask_quantity_2,ask_quantity_3,\
bid_quantity_1,bid_quantity_2,bid_quantity_3):
Weight_Ask = (w1 * ask_quantity_1 + w2 * ask_quantity_2 + w3 * ask_quantity_3)
Weight_Bid = (w1 * bid_quantity_1 + w2 * bid_quantity_2 + w3 * bid_quantity_3)
W_AB = Weight_Ask/Weight_Bid
W_A_B = (Weight_Ask - Weight_Bid)/(Weight_Ask + Weight_Bid)
return W_AB, W_A_Btraded_label_one_second()
- Target 변수 설정
각 시점의 bid_price_1 값이 600초 이후 ask_price_1들 중
최소값보다 큰 경우 1
현재 가장 비싸게 사는 가격이 미래 어느 시점의 가장 싸게 파는 가격보다 크다는 것은 가격 하락 의미하고, 현재 시점의 매수 호가가 Match 됨을 의미
Time Separate
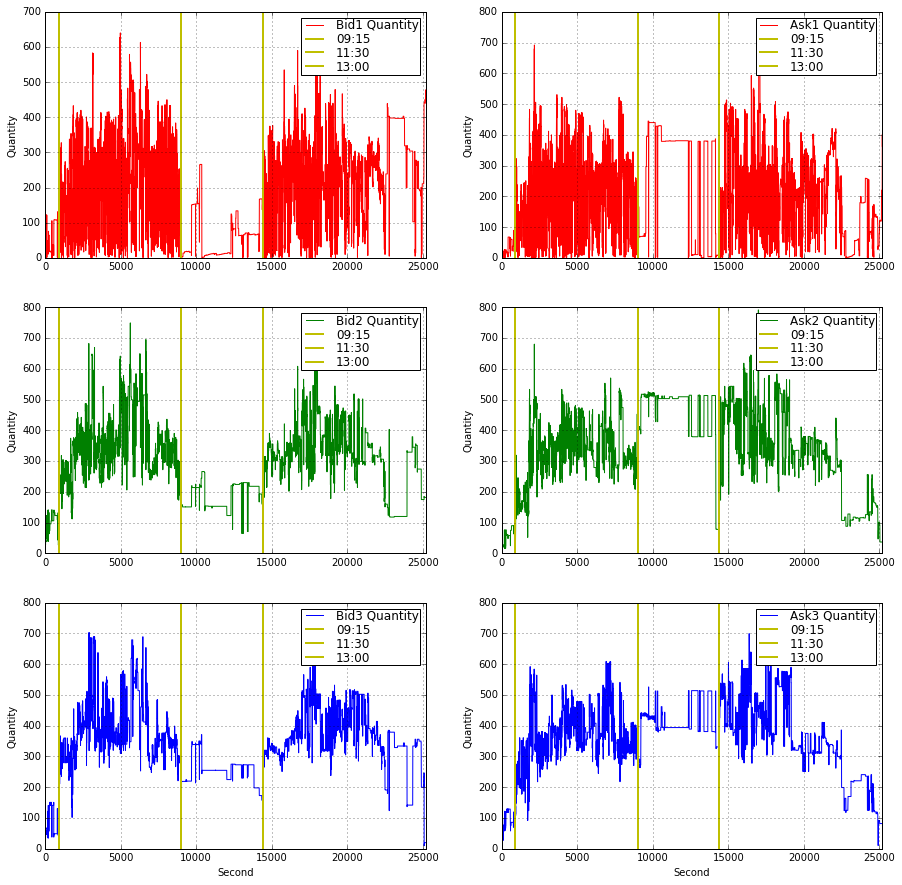
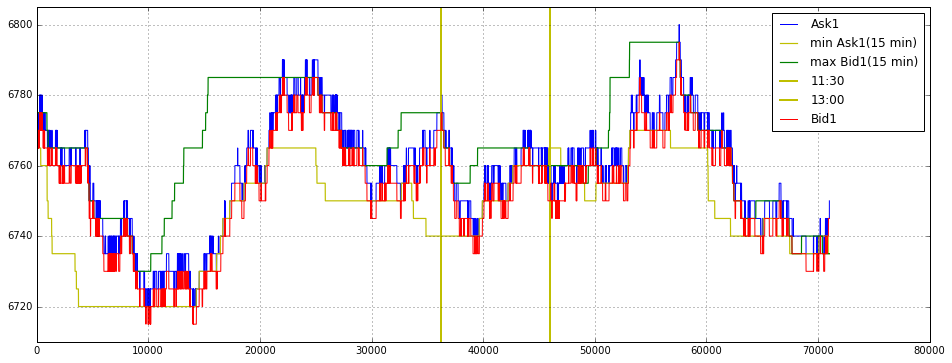
- 중국 주식시장 특성 상 점심시간 개념이 있기에 9:15 ~ 11:30 / 13:00 ~ 17:00 두 타임으로 Data Set 나눔
Plot
Quantity Plot
Price Plot
Return Plot
Machine Learning
Model Selection
- RandomForest Classifier
- ExtraTrees Classifier
- AdaBoost Classifier
- GradientBoosting Classifier
- SVC
Model Train / Test
- train 1800s / test 10s의 하나의 dataset을 10초 간격으로 Rolling Window 진행
- train data에 대해 모든 모델을 학습 후 Cross Vaildation (cv=5)
- test data (10s) 예측
- 위 과정이 하나의 Cycle
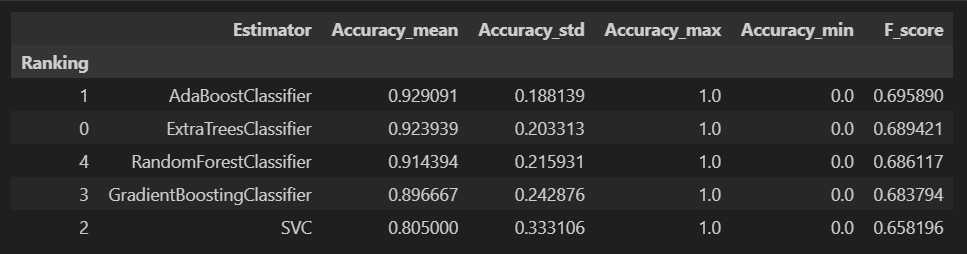
Result
- Accuracy : 예측한 10초(10개) 중 몇 개를 맞추었는지
CV Accuracy
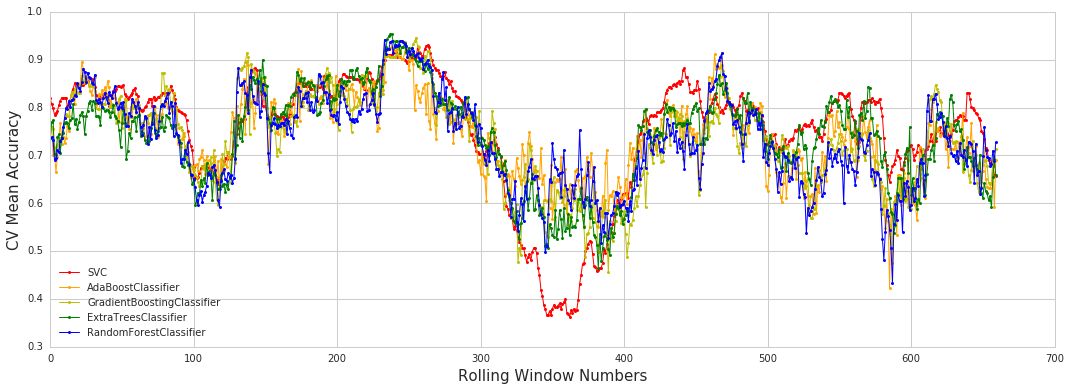
Test Accuracy
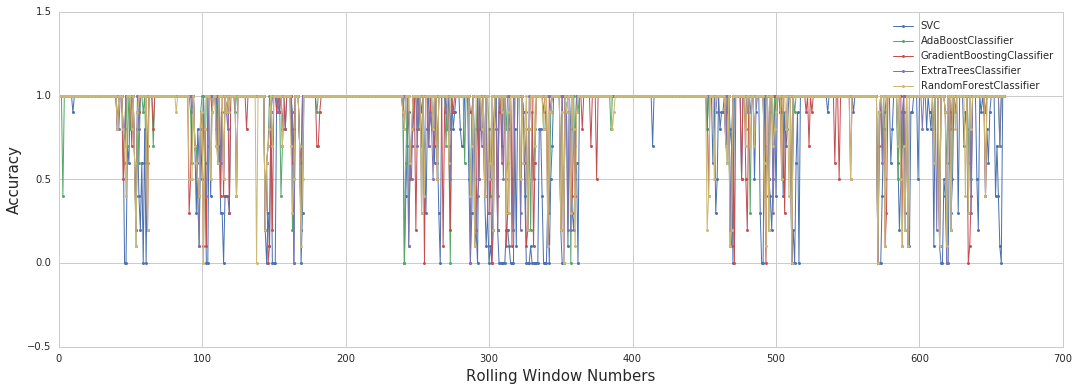
Good Day
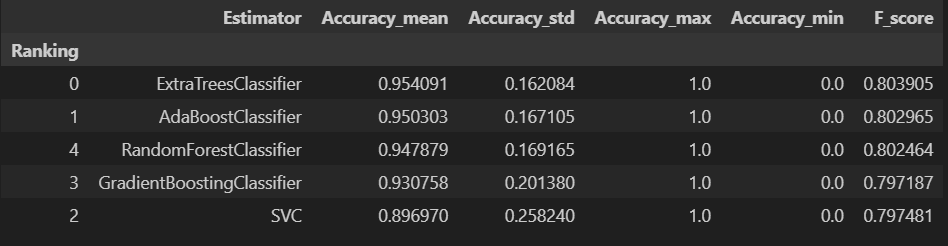
Bad Day
Profit & Loss
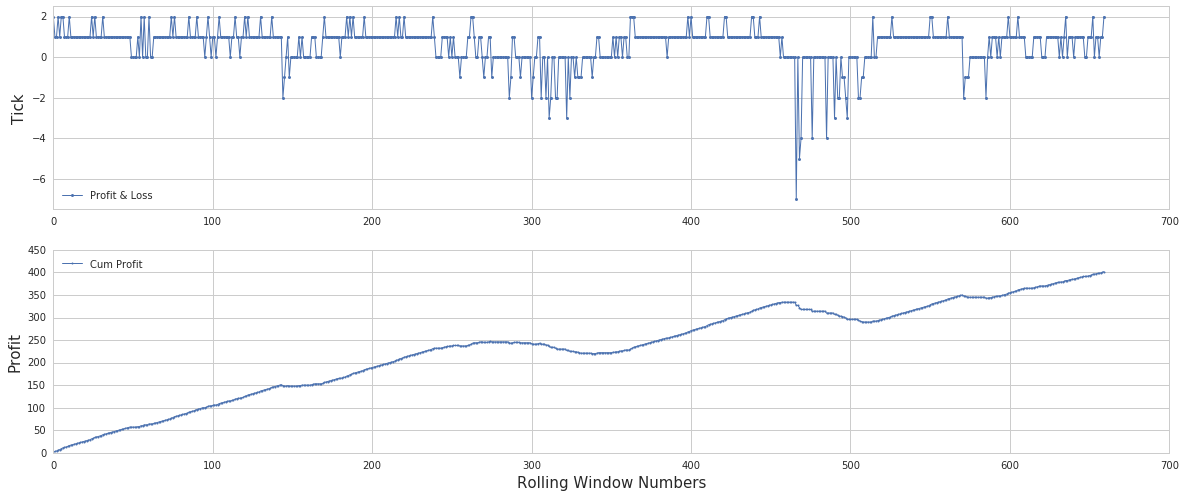
손익 계산에 사용된 데이터는 공개되지 않음
# data_2014['65'] ?????
# data_2014['66'] best ask
# data_2014['67'] best bid
# compute cum_profit and Best_cv_score
dict_ = {}
dict_['cum_profit'] = []
dict_['Best_cv_score'] = []
for day in range(0,1,1):
cum_profit_label = []
cum_profit = []
best_cv_score = []
spread = 0.2 * data_2014[day]['65'][1800:][9::10].values
loss = 0.2*(data_2014[0]['67'][1800:9000-600][9::10].values - data_2014[day]['67'][1800+600:9000][9::10].values)
for j in range(0,len(pip.cv_acc_day.values()[0][day]),1):
max_al = {}
for i in range(0,len(pip.keys),1):
max_al[pip.keys[i]] = np.array(pip.cv_acc_day[pip.keys[i]])[day][j]
# select best algorithm in cv = 5
top_cv_acc = sorted(max_al.items(),key = lambda x : x[1], reverse = True)[0:1][0]
best_cv_score.append(top_cv_acc[1])
submission = pip.predict_values_day[top_cv_acc[0]][day][j][-1]
true_value = pip.true_values_day[top_cv_acc[0]][day][j][-1]
if submission == true_value:
if submission == 1:
cum_profit_label.append(1)
cum_profit.append(spread[j])
elif submission == 0:
cum_profit_label.append(0)
cum_profit.append(0)
elif submission != true_value:
if submission == 1:
cum_profit_label.append(-1)
cum_profit.append(loss[j])
elif submission == 0:
cum_profit_label.append(0)
cum_profit.append(0)
dict_['cum_profit'].append(cum_profit)
dict_['Best_cv_score'].append(best_cv_score)Thought
- 16 호가 중 물량이 많은 N개의 호가만 뽑아서 호가 간 갭이 차이가 어느정도인지 상승률 혹은 차이값 Feature 추가 가능
- N초 대비 변화율을 Feature로 추가

개발 새발