Dataframe split algorythm
- Idea From Divide and Conquer
1) Select all index to remove
- Dawn times
- time diff > 1s
- Nan rows
2) Split Dataframe by index
e.g. index가 1,5,10,17 로 설정했다면, split data set은
2~4, 6~9, 11~16 data set들이 나오게 됨
3) Select Dataframe over Block_size
- split dataframe의 row 수가 사용할 Block_size(lookback + forcast range)보다 적다면,
해당 dataframe은 사용하지 않음
4) Merge Whole Dataframe
- 3)에서 선택된 모든 Dataframe을 모두 Dataset으로 만든 후, Merge
Target
- Lookback : 600 / Target : 100 (up, same, down)
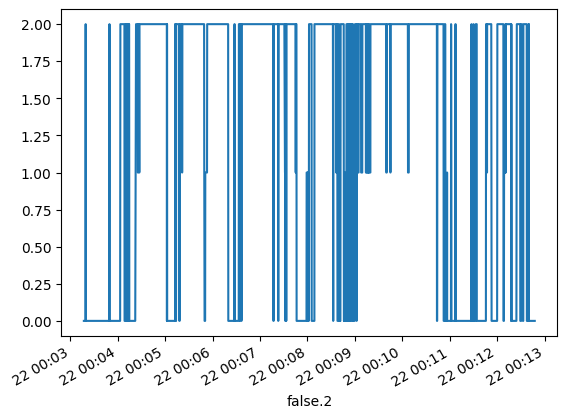
Model Result
- data : btcorder_2024-03-22 오전
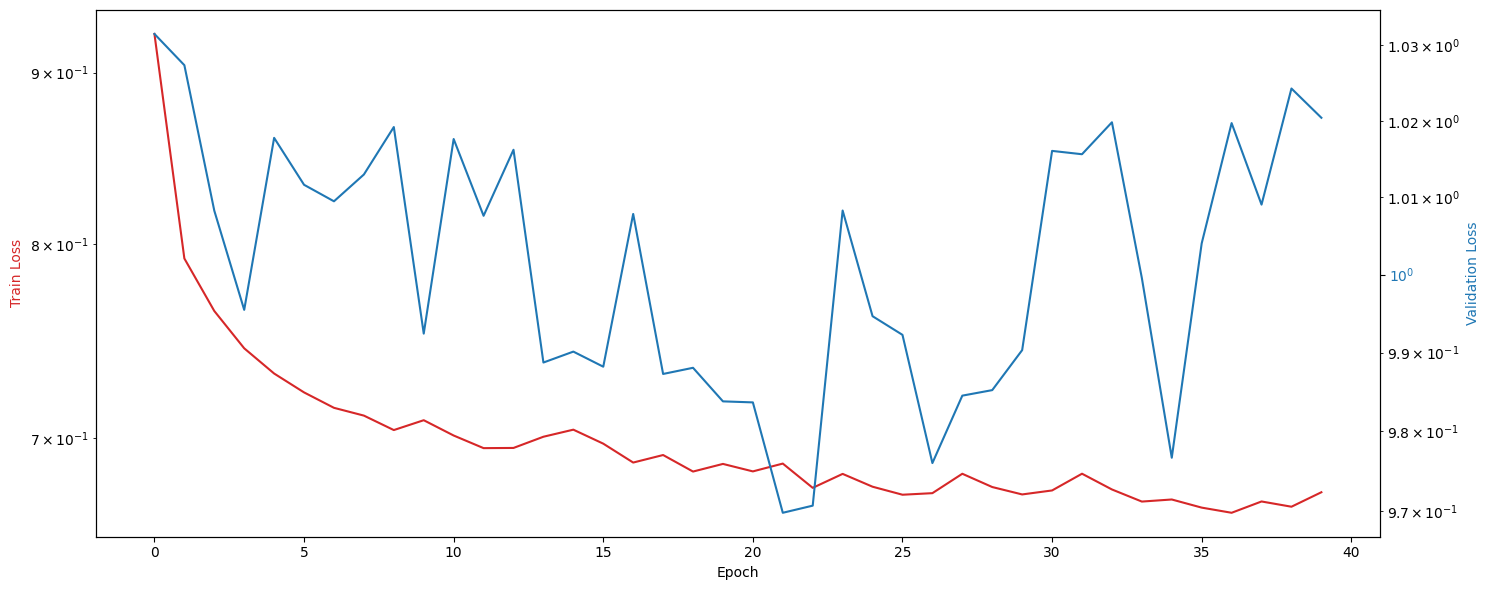
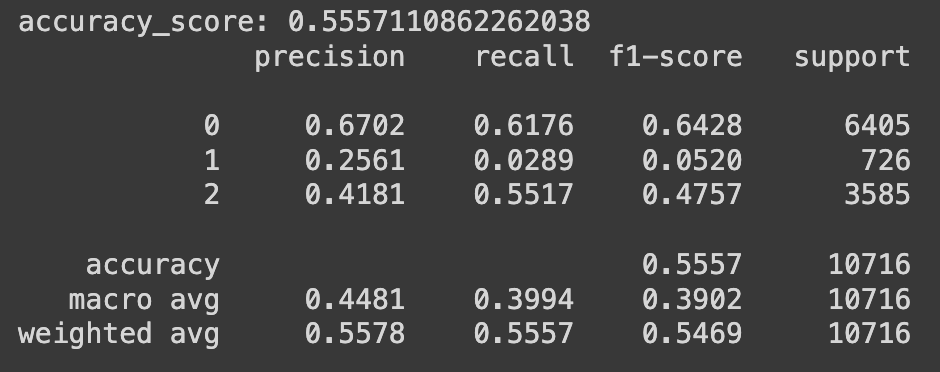
- 가격하락 (0) 에 대해서는 높은 F1-score
- 가격 동일 (1) 은 적은 데이터 수로 학습이 잘 되지 않음
Next Meeting
- Fix target to binary classification
- Balancing Target data
- Regression Model restart
- Cross Check the code
- 1s time series aggmentation

개발 새발