렌더링?
웹 프로그래밍 관점에서 렌더링은 'HTML 파일을 분석해 내용에 맞게 화면에 그려주는 과정'을 말한다. 브라우저는 Rendering Engine과 JavaScript Engine을 모두 갖고 있고, 둘은 엄연히 다르다.
Rendering Engine은 HTML과 CSS로 작성된 마크업 관련된 코드들을 콘텐츠로서 웹 페이지에 렌더링 하는 역할을 한다.
JavaScript Engine은 자바스크립트 코드를 해석하고 실행하는 인터프리터이다. Chrome이나 Node.js의 경우 V8 엔진을 탑재하고 있고 Firefox는 Gecko 엔진을 탑재했다.
브라우저가 화면을 그리는 과정
어딜 가나 있는 설명이지만.. 이해하기 쉽게 Google 페이지에 접속했다고 가정해보자.
그럼 우리는 브라우저의 주소창에 google.com을 입력한 후 엔터를 누를 것이고, 그 이후에는 복잡한 네트워킹 과정을 거쳐 구글에서는 google.com에 해당하는 HTML 파일을 하나 보내준다.
그럼 브라우저는 이 HTML을 열심히 분석하기 시작한다.
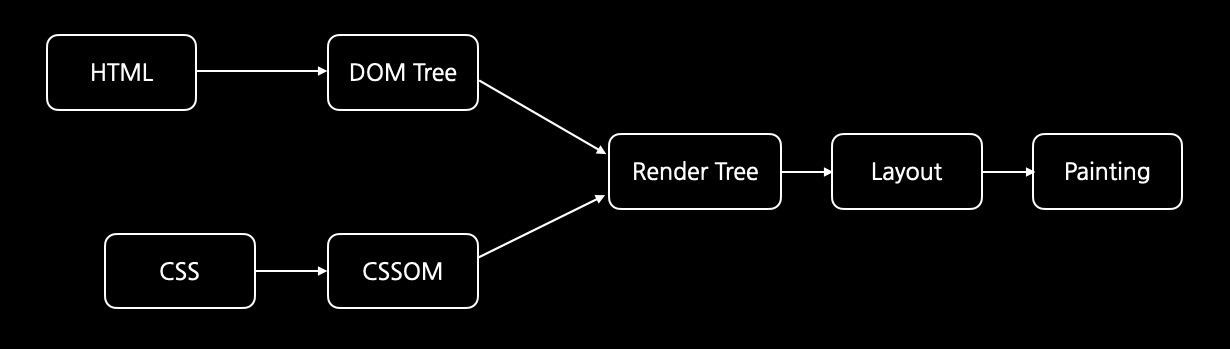
(아 처음으로 내가 직접 만든 그림이다.)
그림에서 HTML을 조금 앞으로 빼내어 그린 이유가 그것이다. HTML을 먼저 분석한다. HTML이 곧 페이지의 내용이므로 이를 분석한 후 일련의 과정을 거쳐 실제 보이는 웹 페이지로 만드는 것이다.
그림을 보면 HTML 파일로 DOM Tree라는 것을 만들고, CSS 파일을 기반으로 CSSOM이라는 것을 만든다. 그럼 JavaScript는? 자바스크립트 엔진이 알아서 처리한다.
DOM Tree 만들기
우선 HTML 파일을 인코딩한다. HTML 파일은 한번에 깔끔하게 다운로드 되는게 아니다. TCP 소켓을 통해 점진적으로 다운로드가 진행되고, 다운로드가 완료된 내용은 바이트 데이터이지 아직 파일이 아니다. 이 데이터를 지정된 인코딩 방식에 따라 인코딩을 진행해야 파싱할 수 있다.
인코딩이 완료되면 파싱에 들어간다. 파싱(parsing)은 텍스트같은 데이터를 의미있는 작은 조각으로 나누는 것을 말한다. HTML 파일은 <, /> 같은 태그 단위를 나타내는 문자들 기준으로 나눌 수 있을 것이다.
이렇게 나눠진 후에는 조각들에 의미를 부여하는 것이 가능하다. 이 과정을 'lexing'이라고 한다.
이런 의미있는 조각들은 각각의 Node로 바뀐다. 태그가 아니고 노드인 이유는 노드가 더 큰 범위이기 때문이다. TCP School 이 링크는 노드들의 종류에 대해 설명하고 있다. 간단히 말하면 텍스트나 태그같은 것들이 전부 노드의 하위 개념이다.
이 과정이 끝나면 DOM Tree가 완성된다. 트리와 같이 위계 구조가 만들어지기 때문에 Tree라고 부른다.
CSSOM 만들기
HTML 내부에는 해당 페이지에서 사용할 CSS, JavaScript 파일에 대한 정보도 같이 들어가있다. link 태그나 script 태그를 이용해 이들을 명시해두는데, 브라우저는 HTML 파일을 최상단부터 읽으며 이들을 만나면 이들을 추가로 요청해 다운로드 받는다. 내가 요청한 google.com이 정상적으로 돌아가기 위해서는 이 CSS 파일과 JavaScript 파일들이 모두 필요하기 때문이다.
이렇게 받아온 CSS 파일을 파싱하고 토큰화하는 과정을 거쳐 CSSOM이 만들어진다. DOM Tree때와 거의 유사한 과정을 거치지만, cascading 규칙이 추가된다는 차이점이 있다. 같은 규칙이라면 이후에 추가된 내용이 우선순위가 높다는 뜻이다.
Render Tree 만들기
Render Tree는 DOM Tree와 CSSOM을 합쳐 실제로 화면에 '보여질' 것들로만 만든다. 예를 들어 <p> 태그 하나의 display 속성이 none인 경우 분명 DOM Tree에는 존재할지라도 Render Tree에는 존재하지 않게 된다.
Render Tree는 Render Object Tree, Render Layer Tree 등 여러가지로 구성되어 있다. Render Layer Tree는 Render Object의 속성에 따라 필요한 경우에 만들어진다. 3d transform을 사용하거나 canvas요소, css animation처럼 WebGL을 필요로 하는 Object일 경우가 대표적인 예이다.
Layout
이제 각각의 노드들이 화면 상의 어디에 위치하는지 계산하는 단계이다. 물론 HTML 파일을 통해 구조와 대략적인 위치를 파악하고, CSS를 통해 세부 위치를 알 수 있었지만, 그것들이 실제 뷰포트 기준으로 어디에 위치해야 할지를 계산해야 한다.
브라우저 창의 크기를 resize 할 경우에도 새롭게 Layout 계산이 필요하다.
이 과정을 Webkit 엔진에서는 layout, Gecko 엔진에서는 reflow라고 부른다.
Paint
Layout까지 완료된 Render Tree를 실제로 눈에 보이는 픽셀들로 바꿔 화면에 그려주는 단계이다. Gecko 엔진에서는 repaint라고 부른다.
reflow와 repaint 개념은 중요하다. CSS 속성이 바뀔 때 어떤 속성인지에 따라 reflow부터 새로 진행하거나 repaint부터 다시 진행한다. 예를 들어 top, left 값을 조절하면 reflow 과정부터 다시 진행한다. top이나 left 값이 바뀌면 모든 요소들의 위치를 전부 다시 계산한 후 paint 작업을 거친다. 반면에 transform(translate)을 통해 요소의 위치를 옮길 경우 repaint 과정만 다시 진행된다. 그래서 요소의 위치 변화가 잦은 경우 transform 사용을 진지하게 고민해볼 필요가 있다.
DOM
그렇다면 DOM은 무엇인가? DOM Tree라는 단어를 위에서 많이 사용했다. DOM은 HTML 문서의 객체 기반 표현 방식이다. DOM을 통해 페이지의 내용, 구조, 스타일을 조작할 수 있다. HTML과 DOM은 비슷하지만 명백히 다르다. HTML은 단순히 텍스트로 구성되어 있지만, 이를 파싱하고 토큰화하는 과정을 거쳐 문서가 조작 가능한 객체로 변환된 것이 DOM이다.
그리고 DOM Tree는 위에서 말했던 것처럼 HTML 문서와 정확히 대응한다고 할 수도 없다.
- HTML 문서는 문서가 완벽하지 않을 수 있다.
<br>태그처럼 닫는 태그를 생략하더라도 Rendering Engine은 적당히 의도를 유추해 교정해준다. 하지만 교정이 일어났다고 원본 HTML이 완전한 것은 아니며 HTML 문서와 DOM Tree가 만약 정확히 대응한다면 DOM Tree에서도 잘못 작성된 br 태그는 없어야 한다. - JavaScript에 의해 DOM이 수정될 수 있다.
그렇다고 수정된 내용이 HTML에 반영되는 것은 아니다.
이런 두가지 이유로 인해 HTML 문서는 DOM Tree와 정확히 대응하지 않는다.
브라우저에 현재 보이고 있는 내용도 DOM Tree가 아니다. 이건 Render Tree다.
React
다시 프레임 얘기로 돌아가서, 위와 같은 과정의 전체를 거치든 일부를 거치든 0.016초 안에 끝나야 한다. 만약 이보다 길어질 경우 흔히 'Jank'라고 부르는 뚝뚝 끊겨보이거나 렉걸린듯한 경험을 사용자에게 선사한다.
Element가 새로 생기거나 없어진다면 Render Tree부터 다시 만들어야 할 것이고 CSS 속성이 바뀌었을 때는 경우에 따라 reflow 과정을 다시 거치거나 repaint 과정을 다시 거친다. 이런 과정이 반복적으로, 그리고 자주 발생한다면 한 프레임의 렌더링을 0.016초 안에 맞출 수 없다.
리액트는 이 문제를 해결하기 위해 Virtual DOM을 사용했다. Virtual DOM이 대단한 것은 아니다. 그냥 실제로 렌더링에 반영되지 않는 가상의 DOM Tree를 하나 더 만든 것이다. 그리고 React에서는 DOM의 변화를 batch 형태로 Virtual DOM에 적용시킨다.
이해를 돕기 위해 10000개의 <li> 태그를 가진 리스트가 하나 있다고 하자. 이 리스트는 어떤 배열의 데이터를 <li> 태그로 감싸 그려주고 있다. 이 중 여러개를 한번에 소거해야 하는 로직을 구현해야 할 때 vanilla JavaScript로 작성하는 경우 for문을 돌거나 어쨌든 반복문을 통해 하나하나 배열의 데이터를 소거할 것이다. 그럼 반복문을 한번 돌때마다 Render Tree가 새로 만들어지고 렌더링 과정이 다시 일어난다.
React는 그렇지 않다. useState 훅을 통해 배열의 내용을 소거했다고 하면, 똑같이 for문을 통해 배열의 데이터를 하나하나 없애면서 state transition이 일어났다고 하더라도 변경 사항을 실제 DOM Tree에 반영하는건 한번만 일어난다. batch로 여러개의 변경사항을 묶어서 반영시키기 때문이다. 그래서 렌더링도 한번만 발생하고, 경제적이며, 빠르다.
그렇다고 모든 상황에서 React가 우수하다는 것은 아니다. React는 신이 아니다. 성능 측면에서만 봐도 벌써 메모리에 별도의 자료구조를 하나 더 갖고있고, React는 굉장히 적극적으로 리렌더링을 발생시키기 때문에 오히려 React를 조금 해본 분들은 React가 만들어내는 수많은 렌더링을 막는 것이 중요하다는 점을 이해하고 있을 것이다. 또한 <canvas>를 주로 사용해야 하는 프로젝트의 경우 canvas와 리액트의 통신이 굉장히 어렵다. 이 문제를 해결하기 위해 유사 IPC 느낌으로 로직을 작성해 해결한 사례도 들어봤다. 굳이 canvas가 아니어도 DOM에 대한 섬세한 조작이 어렵다. useRef 훅 만으로는 한계가 있다.
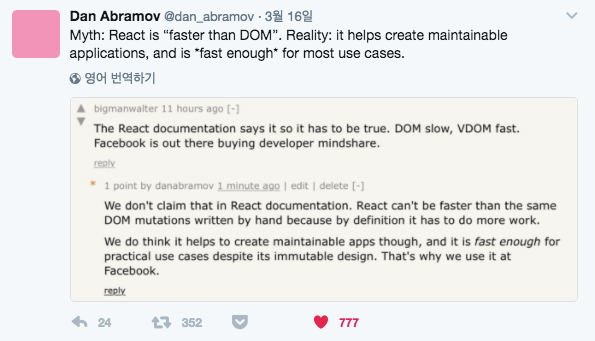
(Redux를 만들었고 현재 React 팀에서 근무하는 아저씨가 쓴 트윗이다. 반박을 위해서는 최소한 이분처럼 React 팀에서 근무해본 경험이 필요할 것이다.)
React는 대부분의 경우에 굉장히 유용하고 대단한 툴인 것은 사실이나, React가 항상 정답이라고는 할 수 없다.
'React 공부 귀찮아 응애' 를 길게 풀어써봤다.
참고
[번역] 리액트에 대해서 그 누구도 제대로 설명하기 어려운 것 – 왜 Virtual DOM 인가?(velopert)
