V8 Engine
ECMA Script와 Web Assembly를 위한 엔진이다. 자바스크립트는 Python과 같은 인터프리터 언어이고, 따라서 코드를 해석하고 실행하는 '실행기'가 필요하다. V8 Engine이 그 역할을 한다. C++로 작성되었고, C++ 애플리케이션에 V8 Engine을 내장시킬 수 있다.
git : v8 github
V8 Engine이 등장하기 전에도 분명 자바스크립트를 위한 엔진은 존재했다. V8 Engine은 구글이 개발한 엔진으로, 이전 엔진의 문제점을 개선했다. 개선한 문제들은 아래와 같다.
- JavaScript 코드를 브릿지 없이 바이트 코드로 바로 변환한다.
- 컴파일된 JavaScript 코드를 캐싱한다.
V8 메모리 구조
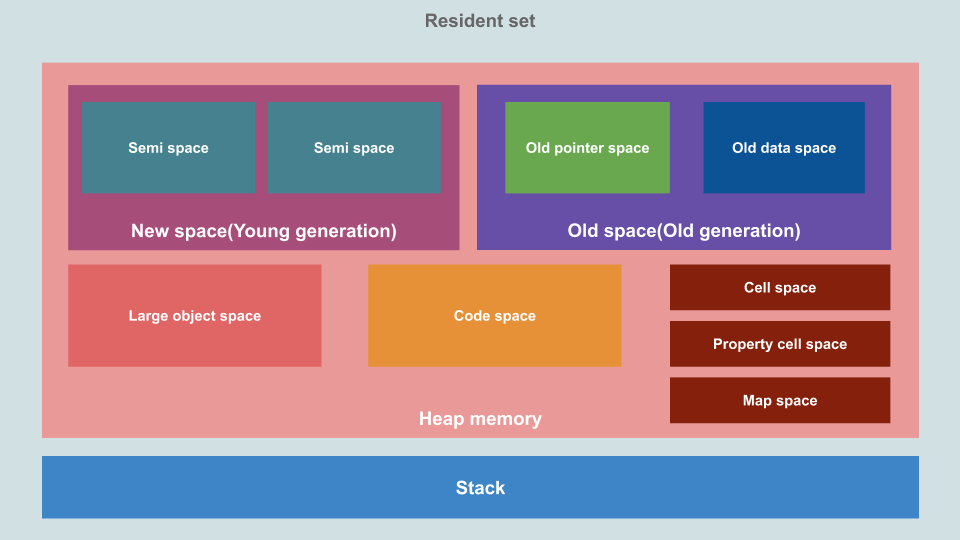 출처 : https://deepu.tech/memory-management-in-v8/
출처 : https://deepu.tech/memory-management-in-v8/
JavaScript는 단일 스레드 언어이다. 따라서 V8은 자바스크립트 컨텍스트 당 하나의 프로세스를 사용한다. 실행중인 프로그램은 V8 프로세스에 할당된 일정량의 메모리로 표현되고, 이 메모리 구조를 Resident Set이라 한다.
그림은 Stack과 Heap으로 나누어져 있다. Stack은 실행 컨텍스트와 원시값, 객체의 포인터같은 정적 데이터가 저장된다. Heap은 객체같은 동적 데이터를 저장한다. 운영체제를 공부했다면 쉽게 이해하겠지만, stack은 위에서부터 아래로 주소가 내려오는 구조이고 Heap은 아래에서부터 위로 주소가 올라가는 구조다. 프로세스마다 메모리가 할당되기 때문에 언젠가 둘은 만난다. 그럼 더이상 메모리 할당이 불가능하기 때문에 stack과 heap을 잘 관리해줘야 한다.
Stack의 경우는 메모리 관리에 대해 크게 신경 쓸 필요가 없다. 아래 코드를 본다.
class Employee {
constructor(name, salary, sales) {
this.name = name;
this.salary = salary;
this.sales = sales;
}
}
const BONUS_PERCENTAGE = 10;
function getBonusPercentage(salary) {
const percentage = (salary * BONUS_PERCENTAGE) / 100;
return percentage;
}
function findEmployeeBonus(salary, noOfSales) {
const bonusPercentage = getBonusPercentage(salary);
const bonus = bonusPercentage * noOfSales;
return bonus;
}
let john = new Employee("John", 5000, 5);
john.bonus = findEmployeeBonus(john.salary, john.sales);
console.log(john.bonus);(출처 : https://speakerdeck.com/deepu105/v8-memory-usage-stack-and-heap)
위 출처의 링크로 들어가면 슬라이드를 통해 이 코드가 돌아갈 때 메모리가 어떻게 관리되는지 쉽게 파악할 수 있다.
간단히 요약해보면..
우선 전역 컨텍스트가 존재하고, 전역변수나 상수, 클래스, 전역 함수(자바스크립트에서 함수는 객체다)가 전역 컨텍스트 안에 잡힌다. 전역 스코프를 돌릴 때 필요한 내용이라고 생각해도 좋다.
그 후 let john = new Employee("John", 5000, 5);를 실행하기 위해 Employee 클래스의 생성자 함수가 호출되며 스택에 쌓인다. 맞다. 함수가 호출되면 스택에 함수의 컨텍스트(lexical environment)가 쌓인다. 이 컨텍스트 내부에는 함수를 돌리기 위해 필요한 지역변수와 내부함수 같은 것들이 포함되어 있고, 상위 컨텍스트가 무엇인지를 가리키는 포인터도 위치해 있다. 함수 실행이 끝나고 원래 컨텍스트로 돌아갈 때는 return 값이 생기며 이를 전달해준다. 함수 생명주기가 끝나면 자연스럽게 스택에서 컨텍스트는 소멸된다. 따라서 스택은 따로 관리해줄 필요가 없다.
문제는 heap이다. heap에는 객체같은 동적 데이터들이 들어간다고 했다. 함수 내부에서 객체를 사용할 수 있는 이유는 스택에 포인터 변수가 하나 잡히고 이 포인터가 힙의 객체를 가리키기 때문이다. 객체는 힙에 존재한다. 그럼 이 객체 사용이 끝나면 자연스럽게 객체가 힙에서 소거될까? 그렇지 않다.
JVM의 경우 Garbae Collector가 존재하고 이를 통해 안쓰는 객체가 청소되고 조각화된 메모리가 압축된다. JavaScript도 마찬가지로 V8 Engine의 Garbage Collector가 이 역할을 수행한다. V8 Engine의 Garbage Collector는 크게 두개로 나뉜다. Young Generation에서 돌아가는 Scavenger(Minor GC)와 Old Generation에서 돌아가는 Major GC가 그것이다.
Young Generation과 Old Generation을 나눈 이유는 효율성을 위해서다. Young Generation은 생성된지 얼마 안된 객체들을 담는 조그마한 공간이고, Old Generation은 생성된지 오래된 객체들을 담는 조금 더 큰 공간이다. 그리고 각각에서 작동하는 GC가 각자에 최적화된 알고리즘을 통해 돌아간다.
Minor GC (Scavenger)
우선 Young Generation부터 본다.
새로운 객체가 생성되면 Young Generation에 객체가 생성된다. 메모리에 직접 객체의 데이터가 쓰인다는 뜻이다. 물론 객체 내부에 다른 객체가 또 있다면 그 객체의 포인터를 저장할 것이다. Young Generation은 Old에 비해 작고(1~8MB), 새로운 객체가 생성되면 포인터가 하나씩 증가하는 방식으로 관리되기 때문에 할당 비용이 저렴한 편이다.
이 포인터가 하나씩 증가할때마다 Scavenger는 화가 난다. 포인터가 Young Generation의 마지막에 도달하면 더 이상 Young Generation에 객체를 할당할 수 있는 공간이 없다는 뜻이다. Scavenger가 더 이상 화를 참을 수 없어 나서게 된다.
사실 Young Generation은 2개의 세미 영역으로 또 한번 나뉜다. To 영역과 From 영역이 그것인데, 이 둘 사이를 왔다갔다 하며 참조가 끊어진 객체를 파악해 없애기도 하고 조각화된 메모리를 압축시키기도 한다.
대부분의 새로운 객체는 From 영역에 생성된다. 여기가 시작점이다. 객체가 쌓이고 From 영역이 꽉 차면 화난 스캐벤저는 From 영역의 '참조가 살아있는' 객체들을 탐색하며 그들을 To 영역으로 옮긴다. 그리고 To 영역은 자동으로 compaction 된다. From 영역에 남은 객체들은 참조가 끊어진 객체들이므로 이들을 free 시킨다. 그럼 스캐벤저는 다시 어느정도 화가 풀린다.
객체들은 From 영역에서 쌓이기 시작해 한번의 숙청을 견뎠고 현재 To 영역에 있다. 이제 새로운 객체는 To 영역에서 쌓이기 시작할 것이고, 꽉 차면 또 다시 스캐벤저가 화가 날 것이다. 이때 To 영역에 있는 객체들은 참조가 살아있다면 From 영역으로 이동한다. 이 과정이 반복된다.
요약하자면 아래와 같다.
- Young Generation은 새로 생긴 객체들을 위한 메모리 공간이다.
- 객체는 주로 From 영역에서 생긴다. 여기서 시작한다.
- 객체가 생길때마다 Young Generation에 있는 포인터가 하나씩 증가하고, 끝까지 포인터가 증가하면 스캐벤저가 숙청을 시작한다.
- 스택 포인터(GC root)부터 시작해서 From 영역까지 순회하며, 참조가 남아있는 객체만 재귀적으로 To 영역으로 옮긴다.
- 자연스럽게 From 영역에는 참조가 끊긴 객체가 남게 되고, 소거된다.
- 무사히 To 영역으로 이동한 '참조가 살아있는' 객체들은 자동으로 compaction이 이루어진다.
- From -> To로 이동하며 GC가 일어났다. 이제 새 객체는 To에 쌓인다.
- 여기도 꽉찬다면 2~7의 과정이 From과 To를 반대로 하여 다시 일어난다.
스캐벤저는 stop-the-world 프로세스이지만, 매우 빠르기 때문에 무시해도 될 정도의 수준이다. 결코 메인스레드를 '눈에 띄게' 블락시키지 않는다. 그래도 매우 자주 발생하기 때문에 별도의 병렬 헬퍼 스레드를 통해 실행시킨다.
Major GC
Old Generation은 만든지 오래된 객체들이 위치한다고 했다. 그럼 '오래된'의 기준은 무엇인가? 스캐벤저로부터의 두번의 숙청(From - To - From 혹은 To - From - To)에도 살아남은 객체들이다.
Major GC는 Old Generation의 공간이 충분하지 않다고 판단될 때 실행된다. 다만 Old Generation이 Young에 비해 크기 때문에 Major GC는 자주 화내지 않는다. 스캐벤저에서 썼던 Cheney 알고리즘을 사용하지도 않는다. 이는 작은 공간에 효율적인 알고리즘이기 때문이다.
Major GC는 mark-sweep-compact 3단계로 이루어진다. 마지막 단계는 조각화 휴리스틱에 따라 진행된다.
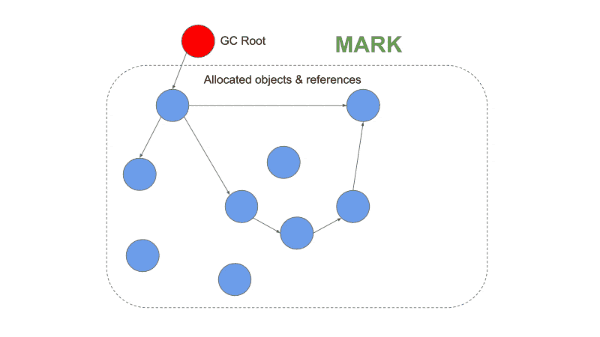
(출처 : https://blog.appsignal.com/2020/05/06/avoiding-memory-leaks-in-nodejs-best-practices-for-performance.html)
-
Marking
스택 포인터에서 시작해 사용중인 모든 객체를 탐색한다. 참조는 스택에서 힙 방향으로 하기 때문이다. 힙 메모리를 방향 그래프로 간주해 DFS를 돌려 참조 여부를 판단한다. 사용중인 객체라면 마킹해둔다.
문제가 있다. 지금 보고있는 데이터가 다른 객체를 가리키는 포인터인지 데이터인지 확인이 어렵다. 이를 위해 V8 Engine은 Tagged Pointer 방식을 이용한다. 각 데이터의 끝에 이게 다른 객체를 가리키는 포인터인지 데이터인지 적어둔다. 컴파일러의 지원이 필요하지만 굉장히 간단하고 효율적이다. 이제 Major GC는 포인터들만 타고 다니며 참조가 살아있는 객체와 죽어있는 객체를 구분할 수 있다. 참조가 살아있는 객체들은 '활성 상태'라고 하자. -
Sweeping
활성 상태가 아닌 객체들의 메모리 주소들을 기록하는 단계이다. 근데 '기록만' 한다. 실제로 sweeping 단계에서 메모리가 비워지지 않는다. Major GC는 lazy 하게 동작한다. 워낙에 오래걸리고 무거운 task이기 때문에 되도록이면 이 과정을 단축시키려 하고, 그래서 메모리를 비우는건 나중에 메모리가 필요한 시점으로 미룬다. 그래서 일단 free-list에 적어두기만 한다. -
Compacting
조각화를 없애는 단계이다. 메모리가 조각나 있다면 새로운 객체를 할당하기 어렵다. 그 빈 공간들을 하나로 모아 새로운 객체가 들어오기 쉽도록 해주는 과정이다.
Major GC도 마찬가지로 stop-the-world 프로세스이다. 자주 발생하지는 않지만 무겁고 느리기 때문에 스캐벤저처럼 별도의 병렬 헬퍼 스레드로 처리된다. 그래도 느리기 때문에 아래와 같은 꼼수들을 쓰기도 한다.
- Incremental GC : Major GC는 한번에 전부 수행되지 않는다. 3단계로 나눠 점진적으로 이루어지며, 중간에 우선순위가 높은 프로세스가 충분히 개입할 수 있다.
- Concurrent : 메인 스레드를 블락시키지 않고 헬퍼 스레드를 이용한다.
- Lazy Sweeping : 위에서 설명한것 처럼 '필요한 시점에' 메모리를 비운다.
참고

10개의 댓글


안녕하세요. 유익한 글이네요. 덕분에 V8 메모리 관리를 다시 한번 짚고 갈 수 있는 기회였던 것 같아요.
그러나 영어 원문과 차이가 있는 거 같아 말씀드립니다!
TOAST UI의 번역 글을 참고하셔서 Minor GC 관련해서 글 작성하신 것 같아요.
이 번역 글의 원문은 https://deepu.tech/memory-management-in-v8/ 입니다. 하지만 원문 글이 추후에 바뀌었는지, 번역 과정에서 문제가 생겼는지 모르겠지만 Minor GC 관련해서 번역 글과 원문 글의 차이가 있습니다.
원문에선
-
Minor GC recursively traverses the object graph in “from-space” starting from stack pointers(GC roots) to find objects that are used or alive(Used memory). These objects are moved to a page in the “to-space”. Any objects reference by these objects are also moved to this page in “to-space” and their pointers are updated. This is repeated until all the objects in “from-space” are scanned. By end of this, the “to-space” is automatically compacted reducing fragmentation
-
Minor GC now empties the “from-space” as any remaining object here is garbage
라고 하고 있습니다. 이를 보면 스캐빈저의 첫 숙청은 객체들이 첫 이동 후 돌아오는 과정에서 최초로 시작한다기 보단 처음에 스택포인터와 reachable한 객체들을 'from-space' 에서 'to-space'로 옮긴 후 reachable하지 못해서 'from-space'에 남은 객체들을 garbage로 여기고 empty 하는 것부터 시작한다고 볼 수 있겠네요!
시각화된 참조 자료 : https://speakerdeck.com/deepu105/v8-minor-gc


궁금한게 있는데 질문좀 드려도 될까요?
출처(https://speakerdeck.com/deepu105/v8-memory-usage-stack-and-heap?slide=6)와 같이 글을 보고 있는데
예시에서 Employee의 this에 john Object을 가리키고 있는데,
john object의 메모리 주솟값이 Employee의 this에 있다고 이해하면 될까요?

Stack의 경우는 메모리 관리에 대해 크게 신경 쓸 필요가 없다.
-> 왜 Stack의 경우 메모리 관리에 대해 크게 신경 쓸 필요가 없는지, 왜 GC가 Heap에 초점에 맞추어져 있는지 제대로 설명이 필요하다고 생각합니다.
Mark and Sweep가 기본적인 GC의 알고리즘인데 이에 대한 설명도 부족합니다.
객체들은 From 영역에서 쌓이기 시작해 한번의 숙청을 견뎠고 현재 To 영역에 있다
-> 숙청이라는 단어가 과연 이 문장 안에 적합한지 고민할 필요가 있다고 생각합니다.
Young Generation은 Old에 비해 작고(1~8MB)
-> Young Generation이 왜 Old generation에 비해 작을까요? 왜 V8에서 Young, Old를 구분한걸까요?
글이 굉장히 유익하고 진지한데 왜 웃길까요 아모튼 잘보고 갑니다~!!~!!!!!😆