Failure Classification
DB환경에서 고장(Failure)의 종류는크게 3가지로 분류할 수 있다.
- Transactional failure : 사용자 어플리케이션의 트랜잭션 레벨에서 발생한 고장으로 Logical error(e.g. Division by Zero)와 System error(e.g. Deadlock)로 구분한다. 가장 사소하고 대부분 복구가 쉽다는 특징이 있다.
- System crash : 정전등의 이유로 휘발성 메모리가 날아간 경우로, DBMS의 버퍼가 초기화되어 최신 데이터가 날아간 경우이다. Recovery System의 주요 대상이다.
- Disk failure(Media failure) : 가장 심각한 고장으로 비 휘발성 메모리(디스크)가 고장난 경우이다. 주기적인 백업을 통해 복구가 가능하다.
위에서 설명한 것처럼 Recovery System의 주요 관심사는 System crash를 복구하는 것인데, 이때 전제가 되는 가정으로는 System crash는 비 휘발성 메모리에 영향을 주지 않는다는 것이다. 따라서 System crash를 복구하기 위해서는 복구에 필요한 정보를 비 휘발성 메모리인 디스크에 보관하여 관리한다.
Recovery System에서 저장공간은 Volatile storage, Nonvolatile storage, Stable storage로 나누는데, 이때 Stable storage란 절대 고장나지 않는 저장소로 현실에 존재할 수 없는 가상의 개념이다. 하지만 고장의 관점에 따라서 Stable storage를 설정할 수 있는데, System crash는 디스크에 영향을 주지 않는다고 가정했기 때문에 이때 디스크는 Stable storage로 간주할 수 있다.
Recovery Algorithm
System crash는 트랜잭션의 모든 시점에서 발생할 수 있다. 예를 들어 A가 B에게 50원을 송금하는 트랜잭션에서 고장이 발생할 수 있는 시점은 아래 그림과 같다.
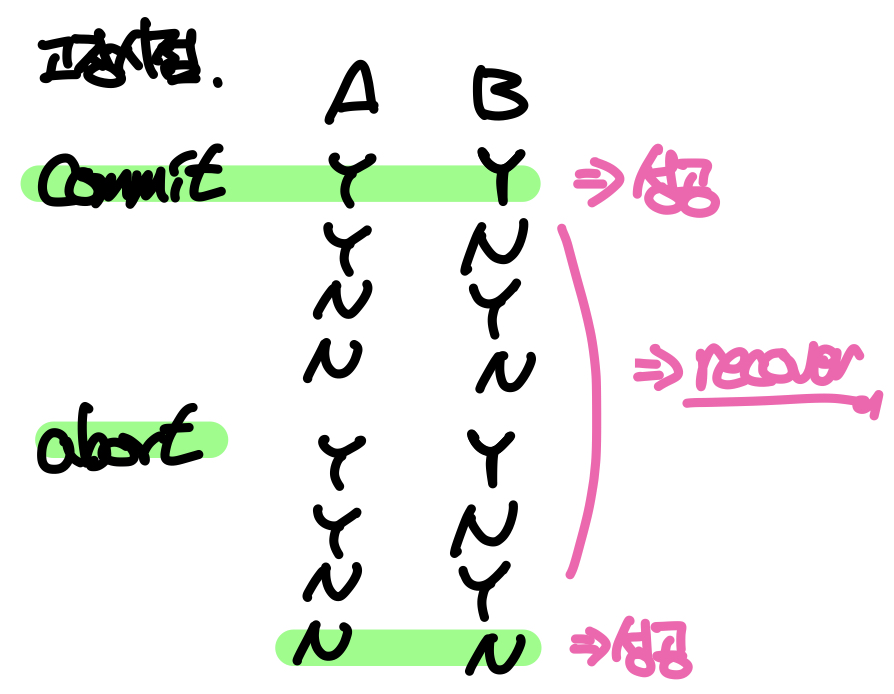
위의 8가지 경우 중에서 트랜잭션이 커밋되고 디스크에 A와 B가 반영된 경우와 트랜잭션이 롤백되고 디스크에 A와 B가 반영되지 않은 두 가지 시점을 제외하면 나머지 시점에서는 디스크에 올바르지 않은 정보가 저장된 상태에서 고장이 발생한 것이기 때문에 복구의 대상이 된다. 따라서 DBMS는 트랜잭션의 모든 시점에 고장이 발생할 수 있음을 인지하고 이에 대비해야 하기 위해 Recovery Algorithm을 사용하는데, 복구 알고리즘이 반드시 갖추어야 하는 요소들은 다음과 같다.
- 정상적인 트랜잭션이 실행될 때 고장 복구에 필요한 정보들을 수집해야 한다.
- 고장이 발생하면 데이터베이스를 복구하여 원자성, 일관성과 지속성을 보장해야 한다.
Data Access

고장복구에 앞서 트랜잭션과 디스크 I/O사이의 관계에 대해 설명하자면, input/output은 DBMS내에서 버퍼와 디스크 사이에 발생하는 작업이고, 트랜잭션의 read/write는 트랜잭션과 DBMS(버퍼)사이에서 발생하는 작업이다. 위의 그림에서 버퍼와 디스크는 DBMS의 영역이고, 트랜잭션은 어플리케이션의 영역이다. 주의할 점은 write는 트랜잭션이 커밋되기 전에 수행되지만 write직후 디스크로 output이 발생하지 않을 수도 있다는 점이다. read/write와 input/output은 별개의 작업이기 때문에 디스크에는 항상 최신의 데이터가 보관되지 않을 수 있다.
Log-based Recovery
Log란 일련의 log records의 집합으로, Log records는 데이터베이스가 업데이트 되는 작업에 대한 정보를 기록한다. 로그는 복구작업을 위해 사용되기 때문에 stable storage에 저장한다. 로그 레코드에 기록되는 작업의 종류는 다음과 같다.
- <T start> : 트랜잭션 T가 시작할 때 기록
- <T, X, V1, V2> : 트랜잭션 T에서 X의 값을 V1에서 V2로 변경하기 직전에 기록(write(X), old value = V1, new value = V2)
- <T commit> : 트랜잭션 T가 마지막 작업을 완료하면 기록
- 로그가 디스크에 저장되기 전까지는 커밋된 것이 아님
- <T, X, V> : undo(T)를 통해 X의 old value(V)가 복구될 때 기록(compensation log record)
- <T abort> : undo작업이 완료되면 기록
- <checkpoint L> : 복구 범위를 줄이기 위해 체크포인트를 설정하면 기록(L : 체크아웃 시점에 진행중이던 트랜잭션의 집합)
Database Modification
트랜잭션이 데이터베이스를 수정하는 것은 DBMS의 버퍼나 디스크에 있는 데이터를 수정하는 것이다. Database Modification은 수정 시점에 따라 두 가지로 나눌 수 있다.
- Immediate Database Modification : 트랜잭션이 커밋되기 전에도 DB영역에 데이터를 write할 수 있음
- 대부분의 DBMS가 채택
- Defferred Database Modification : 트랜잭션이 커밋된 이후에만 DB영역에 데이터를 write할 수 있음
- Dirty data가 DB에 반영되는 것을 방지하므로 복구가 간편함.
- 어플리케이션이 커밋 이전까지 수정한 데이터를 모두 보관하고있어야 하기 때문에 오버헤드가 큼.
Immediate Database Modification 방식에서 로그 레코드는 반드시 데이터베이스에 데이터가 반영되기 전에 업데이트되어야 한다. 또한 변경한 데이터를 포함한 블록이 디스크에 반영되는 순서는 데이터가 변경된 순서와 다를 수 있다. 추가로 트랜잭션의 커밋은 commit 로그 레코드가 디스크로 내려가야 완료된다. 이때, 커밋로그보다 이전에 있는 모든 로그들은 디스크에 내려가있어야 하고, 트랜잭션에 의해 변경된 데이터는 커밋 이후에 디스크에 저장될 수도 있다.

위 예시를 보면 T0에서 A의 값을 50 감소시키고 B의 값을 50 증가시키는 로그가 작성된 이후 트랜잭션은 DBMS에 A와 B의 값을 write한 다음 T0를 커밋한다. 이어서 T1에서 C의 값을 600으로 변경하고 DBMS에 C의 값을 write한 뒤 T1을 커밋한다. 이때 데이터가 디스크에 기록되는 순서는 B,C -> A순인데, A와 B는 트랜잭션이 커밋된 이후 output되었지만 C는 T1이 커밋되기 전에 디스크에 output된 것을 볼 수 있다. 또한 T0에서 A가 B보다 먼저 write되었지만 디스크에는 B가 먼저 반영되는 것을 확인할 수 있다.
Concurrency control

동시에 진행되는 트랜잭션들은 하나의 버퍼와 하나의 로그를 공유하기 때문에, 서로 다른 트랜잭션들의 로그 레코드는 하나의 로그에 섞여서 존재할 수 있다.
Undo, Redo
Undo는 트랜잭션이 abort되었을 때 수행되는 작업으로 트랜잭션 중 변경된 데이터를 다시 기존 데이터로 변경하기 위해 가장 최신 로그부터 뒤로 돌아가면서 트랜잭션의 작업을 무효화한다. 이는 Immediate modification방식에서 고장 시점 이전에 커밋되지 않은 데이터가 이미 디스크에 저장되었을 수도 있으므로 로그를 보고 이전값으로 되돌리기 위한 것이다.
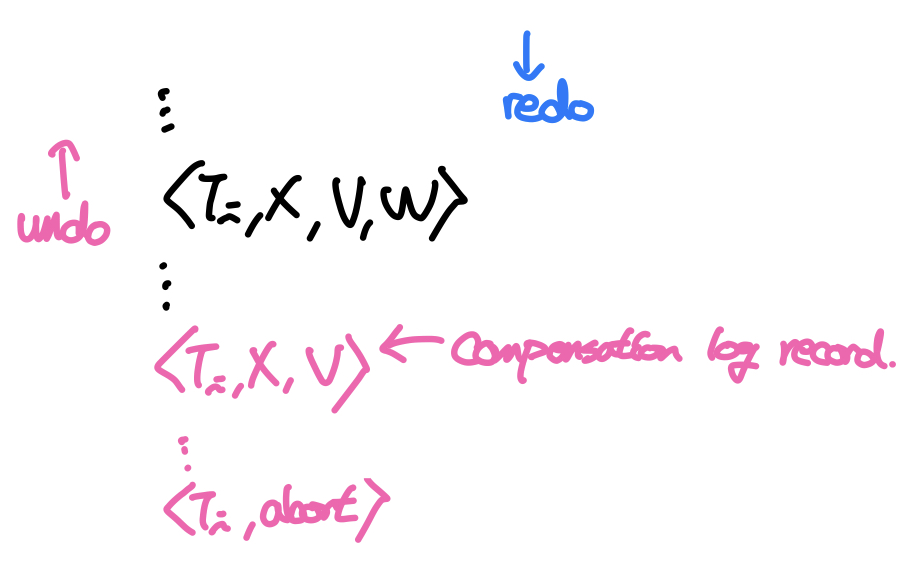
undo가 시작되면 로그를 거꾸로 올라가면서 <T, X, V1, V2>라는 업데이트 로그를 찾고 X의 값을 V1으로 덮어쓴다. 이후 <T, X, V>라는 Compensation Log Record를 남기고 다음 업데이트 로그를 찾는다. 만약 트랜잭션의 시작로그를 만났다면 롤백이 완료된 것이므로 <T abort>로그를 남긴다. 이때 중요한 것은 undo작업으로 복원된 데이터는 버퍼에만 저장되고 디스크에 output하지는 않는다. 왜냐하면 복구의 역할은 DBMS의 버퍼가 최신 값들을 가지고 있도록 하는 것 까지이기 때문이다.
Redo는 트랜잭션이 수행한 업데이트 작업을 다시한번 수행하여 데이터를 최신화하는 작업으로, 트랜잭션의 첫번째 로그부터 순서대로 로그에 적힌 작업을 그대로 수행한다. undo와 달리 redo는 추가적인 로그를 남기지 않는다.
복구과정에서 Undo와 Redo가 수행되어야 하는 상황은 각각 다음과 같다.
- Undo : 트랜잭션 시작로그가 있지만 커밋이나 롤백로그가 남지 않은 상태(<T start>는 있지만 <T commit>이나 <T abort>가 없음)
- Redo : 트랜잭션 시작로그가 있고 커밋/롤백로그가 남은 상태(<T start> ~ <T commit> or <T abort>)
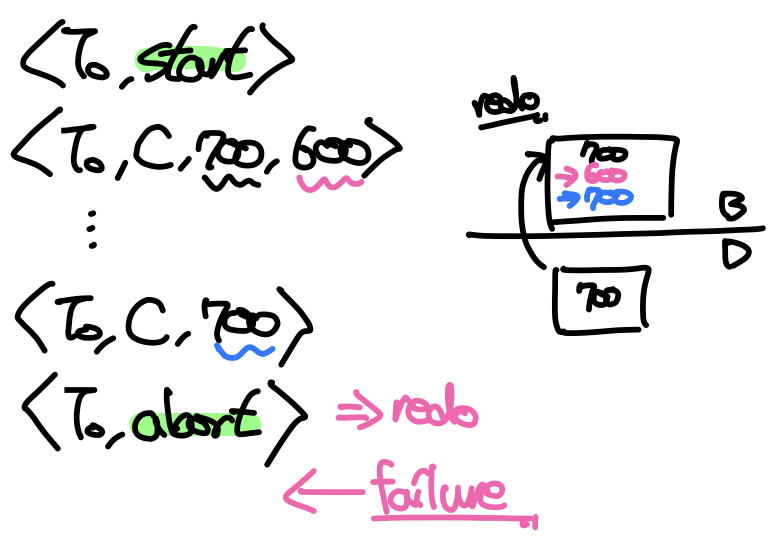
일반적으로 Redo는 고장 전에 버퍼의 내용이 디스크에 반영되지 않았을 수도 있기 때문에 한번 더 데이터를 최신화해주는 것인데, 이때 고장 전에 디스크에 반영된 데이터라도 동일하게 작업을 수행한다. 이를 Repeating History라고 한다. repeating history는 낭비일수도 있지만 복구과정을 단순하게 해준다는 장점이 있다.

위 예시를 보면 (a)는 T0가 완료되기 이전에 고장이 발생했기 때문에 undo의 대상이 되어 <T0, B, 2000>, <T0, A, 1000>, <T0 abort>라는 로그를 추가로 남기고 데이터를 복원한다.
(b)에서는 고장 발생 이전에 T0는 커밋되었기 때문에 redo의 대상이지만 T1은 완료되지 못한 채로 고장이 발생하여 undo된다. 따라서 <T1, C, 700>, <T1 abort>라는 로그를 추가로 남긴다.
마지막으로 (c)는 고장 시점에 T1과 T2 모두 커밋되었기 때문에 추가적인 로그를 남기지 않고 T1과 T2가 redo된다.
Checkpoint
로그가 많이 축적된 상황에서 고장이 발생했을 때 로그 전체를 탐색하면서 redo/undo하는 것은 시간이 매우 많이 소모된다. 따라서 주기적으로 Checkpoint를 두면 고장 발생시 복구의 범위를 제한할 수 있다. Checkpoint를 만들기 위해서는 아래의 과정을 따른다.
- 로그 버퍼에 있는 모든 로그를 디스크에 저장한다.
- DBMS 버퍼에 수정된 모든 데이터를 디스크에 저장한다.
- 진행중이던 트랜잭션의 정보를 포함하여 체크포인틀 로그를 남기고 디스크에 저장한다.(<checkpoint L>)
체크포인팅이 이루어지는 동안에는 시스템이 중단되어야 하므로 데이터의 업데이트가 불가능하다. 체크포인팅 과정 중에서 로그정보를 디스크에 쓰는 작업은 큰 문제가 되지 않지만, 버퍼의 데이터를 디스크로 내리는 과정은 많은 시간이 필요하기 때문에 그 시간동안 시스템은 중단되어야 하므로 체크포인트를 너무 많이 만드는 것도 좋은 방법은 아니다.
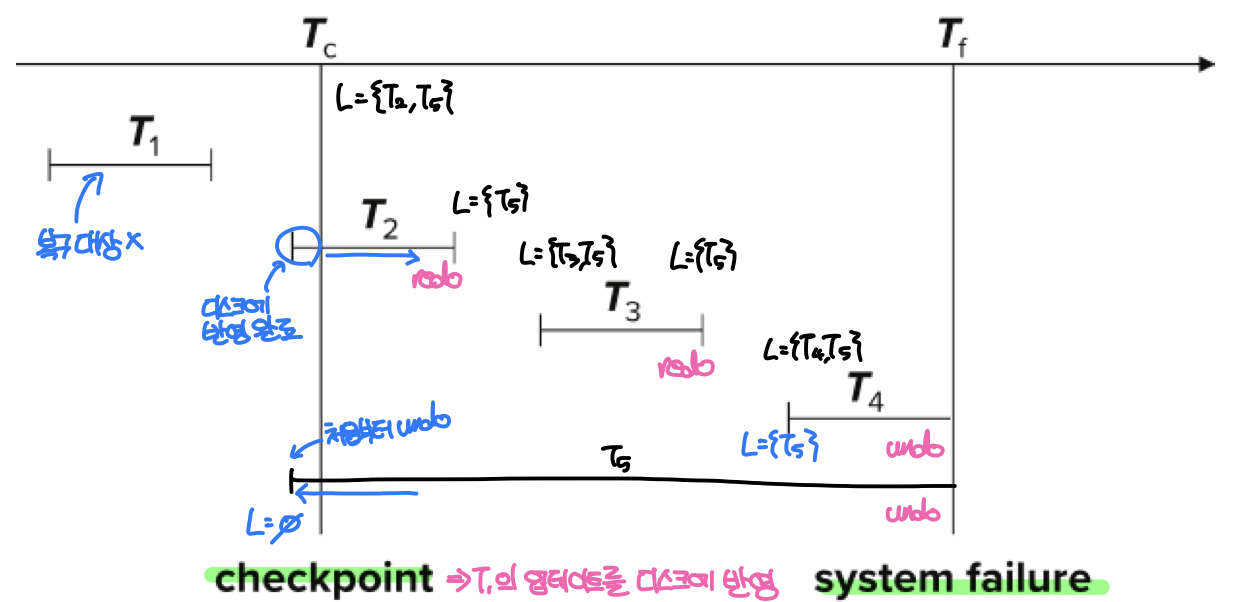
체크포인트가 포함된 로그를 읽고 버퍼를 복구할 때에는 먼저 로그의 끝에서부터 뒤로 탐색하며 가장 최근에 기록된 체크포인트를 찾는다. 이후 체크포인트 이전에 커밋이 완료된 트랜잭션은 무시하고, 체크포인트 시점에 진행중이던 트랜잭션(L)과 체크포인트 이후 실행된 트랜잭션에 대해서만 undo와 redo를 수행한다.
복구는 체크포인트 시점으로 돌아가 로그 순서대로 redo를 진행하고 고장시점에 도달하면 다시 뒤로 돌아가면서 undo를 수행한다. 위의 예시에서 구체적인 복구과정은 다음과 같다.
- T1은 체크포인트 이전에 완료되었으므로 체크포인트를 만들때 디스크에 변경사항이 반영되었기 때문에 복구대상이 아니다.
- 체크포인트 시점에 진행중이던 트랜잭션은 T2와 T5이므로 두 트랜잭션을 복구 대상에 포함한다.
- T2에 대한 완료 로그가 있으므로 redo를 수행한다. 이때 체크포인트 이전 부분은 이미 디스크에 반영되었으므로 체크포인트 이후 작업만 다시 수행한다.
- T3가 시작되었다는 로그를 확인하고 복구대상에 포함한다. 이후 T3의 완료로그를 읽으면 redo한다.
- T4의 시작로그를 읽고 복구대상에 포함한다.
- 고장 시점에 다다르면 복구대상에 남아있는 트랜잭션들을 undo한다. 이때 T5는 ubdo를 위해 체크포인트 이전 시점의 로그까지 사용한다.
Fuzzy Checkpointing
Fuzzy Checkpointing은 체크포인팅이 일어나는 동안에도 다른 트랜잭션이 실행될 수 있도록 하는 방법으로, 많은 DBMS에서는 Fuzzy Checkpointing을 사용한다. 구체적인 동작 순서는 다음과 같다.
- 일시적으로 모든 트랜잭션을 중단한다.
- 체크포인트 로그를 남기고 디스크에 디스크에 로그를 저장한다.(<checkpoint L>)
- 수정된 데이터 블록 전체를 리스트에 기록한다.
- 중단된 트랜잭션을 재개한다(normal processing)
- 리스트에 있는 모든 블록을 디스크에 저장한다.
- checkpoint레코드를 가리키는 포인터를 last_checkpoint에 저장한다.

이때, last_checkpoint는 가장 최근 체크포인트 로그의 위치를 가리키는 포인터로, 복구 알고리즘이 동작하는 시작점이 된다. 즉, last_checkpoint 이전 로그들은 이미 디스크에 반영되었음을 보장하기 때문에 redo되지 않아도 된다. 또한 체크포인트가 완료된 이후에 last_checkpoint를 업데이트 하기 때문에 체크포인트 도중 고장이 발생해도 last_checkpoint부터 복구를 시도하면 정상적으로 데이터를 안전하게 복구할 수 있다.
Log-based Recovery Algorithm
앞서 알아본 것처럼 고장 복구 알고리즘은 정상상태에서의 동작과 고장발생시 동작을 규정해야 한다. 로그 기반 복구 알고리즘에서 각 상황별 구체적인 동작방식은 다음과 같다.
- 정상 상태
- 로깅 : 트랜잭션 시작시 <T start>, 업데이트 발생 시 <T, X, V1, V2>, 트랜잭션 완료시 <T commit>을 기록
- 롤백 : 로그의 끝부터 뒤로 탐색하면서 업데이트 로그를 만나면 X의 값을 V1으로 덮어쓰고 <T, X, V1>(compensation log record)를 기록. <T start>를 만나면 탐색을 끝내고 <T abort>를 기록
- 고장 복구
- Redo phase : 모든 트랜잭션을 다시 수행한다.
- 마지막 <checkpoint, L>을 찾고 undo-list를 L로 초기화한다.
- 체크포인트부터 고장 시점까지 로그를 읽으면서 아래 작업을 수행한다.
- update나 compensation log를 만나면 해당 작업을 그대로 다시 수행한다.
- start로그를 만나면 undo-list에 해당 트랜잭션을 추가한다.
- commit이나 abort로그를 만나면 undo-list에서 해당 트랜잭션을 제거한다.
- Undo phase : 완료되지 않은 트랜잭션을 undo한다.
- 고장시점부터 로그를 뒤로 탐색하면서 undo-list에 남아있는 트랜잭션에 대해 아래 작업을 수행한다.
- update로그를 만나면 데이터를 롤백하고 compensation log를 남긴다.
- start로그를 만나면 abort로그를 남기고 undo-list에서 해당 트랜잭션을 제거한다.
- undo-list가 빌 때까지 반복한다.
- 고장시점부터 로그를 뒤로 탐색하면서 undo-list에 남아있는 트랜잭션에 대해 아래 작업을 수행한다.
- Undo phase까지 끝나면 다시 정상 트랜잭션을 수행한다.
- Redo phase : 모든 트랜잭션을 다시 수행한다.
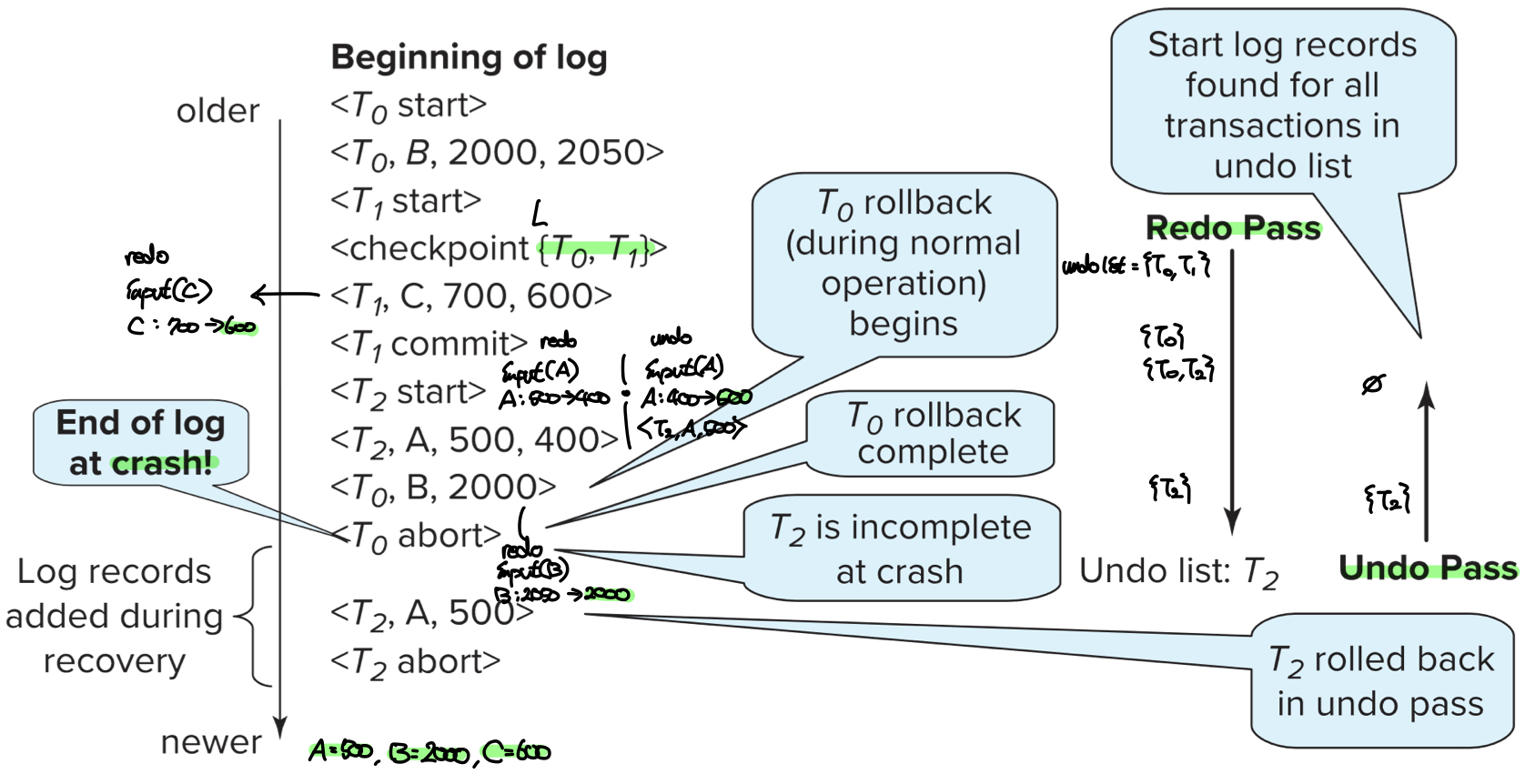
위의 예시에서 <T0 abort>직후 고장이 발생하여 복구알고리즘이 수행되었다. 먼저 로그를 탐색하면서 <checkpoint {T0, T1}>을 찾고 undo-list = {T0, T1}으로 초기화한다. 이후 로그를 따라 내려가면서 모든 로그에 대해 redo를 수행한다. redo phase이후 각 데이터의 값과 undo-list의 상태는 다음과 같다.
- A = 400, B = 2000, C = 600
- undo-list = {T2}
이후 undo phase에서는 undo-list에 남아있는 트랜잭션 T2에 대해 undo를 진행한다. <T2, A, 500, 400>이라는 로그가 있으므로 A의 값을 500으로 덮어쓰고 <T2, A, 500>로그를 남긴다. 이후 바로 윗 줄에서 <T2 start>를 만나므로 <T2 abort>로그를 남기고 undo-list에서 T2를 제거하면 undo phase가 마무리된다. 최종적으로 복원된 데이터의 값은 다음과 같다.
- A = 500, B = 2000, C = 600
Log Record Buffering
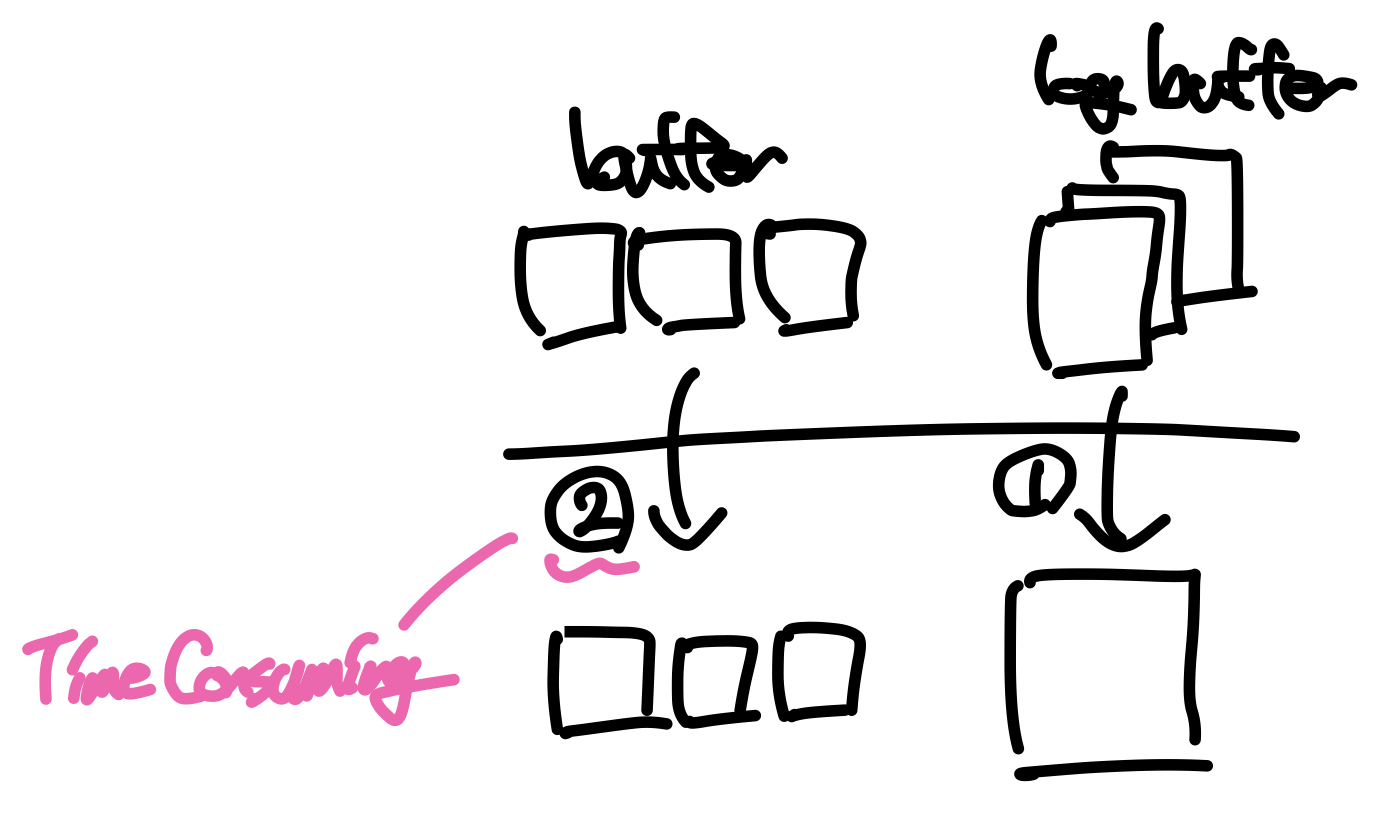
로그 레코드는 복구를 위해서는 stable storage에 저장되어야 한다. 그런데 레코드가 생성될 때마다 디스크로 output하면 DBMS의 I/O횟수가 지나치게 증가하기 때문에 Log Buffer를 이용한다. DBMS는 로그의 I/O를 줄이기 위해 Log buffer를 운영하여 로그 레코드를 모아서 디스크에 output하는데, 이를 Log Record Buffering이라 한다.
로그버퍼가 디스크로 output되는 경우는 두가지 경우가 있다.
- 로그 버퍼가 가득 찬 경우
- Log Force연산을 수행하는 경우
Log Force란 강제로 로그버퍼의 내용을 디스크에 output하는 것으로, 일반적으로는 트랜잭션이 커밋될 때 같이 수행된다. 단, 버퍼 관리 정책에 의해 커밋되지 않은 데이터가 디스크로 output될 수 있는데, 이 경우에는 undo를 위한 로그를 먼저 force해서 디스크에 남겨야 한다. 이를 WAL(write-ahead logging)프로토콜이라 한다.
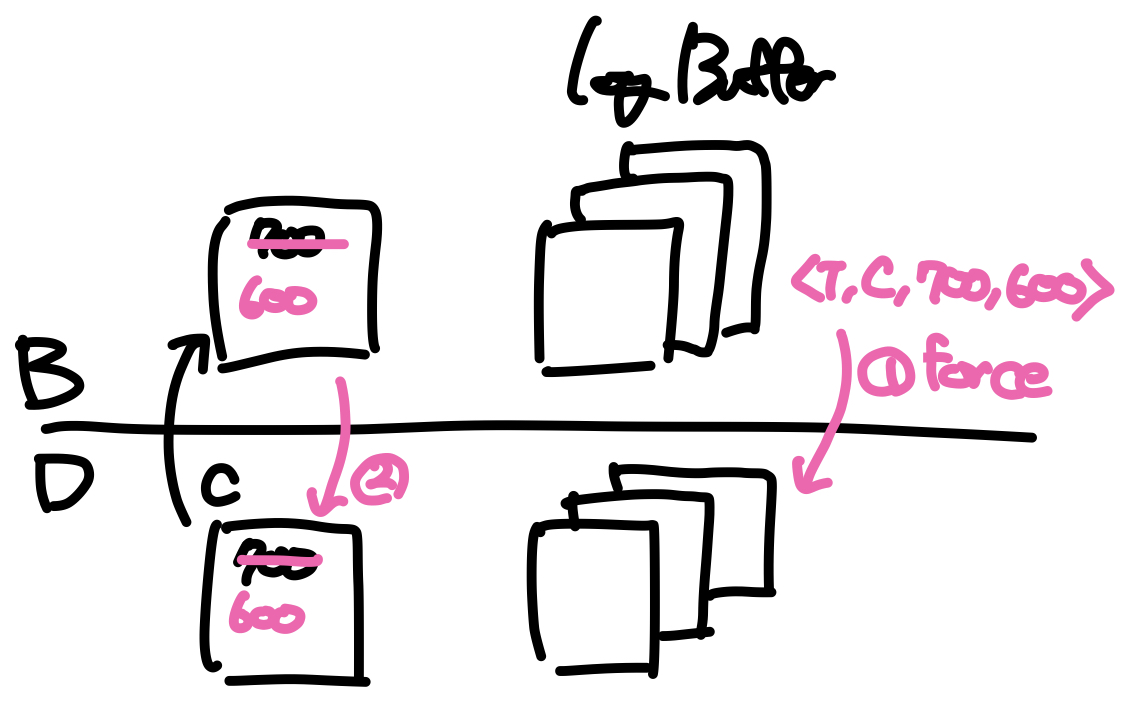
위 그림에서 C의 값이 600으로 변경된 후 커밋되기 이전에 페이지가 교체되면서 디스크에 output되는 상황이 발생하였는데, 이때 WAL을 지키기 위해 로그에 먼저 <T, C, 700, 600>을 기록하고 force연산을 통해 지금까지의 로그를 디스크에 저장한다. 이후 모든 로그가 디스크에 반영이 되면 C가 속한 페이지를 디스크로 output한다.
Database Buffering
복구 알고리즘의 관점에서 DBMS 버퍼가 데이터를 관리하는 방법에 따라 복구 알고리즘이 담당해야 하는 연산의 레벨이 달라진다. 크게 DB버퍼링은 force/no-force policy와 steal/no-steal policy에 의해 분류된다.
- force policy : 커밋시 변경된 데이터가 디스크에 저장되어야 함.
- no-force policy : 커밋 시점에 해당 데이터가 디스크에 반영되지 않아도 됨.(default)
force/no-force 정책의 경우 커밋된 데이터를 디스크에 반영하는 시점에 대해 다루고 있는데, 이중 force정책은 트랜잭션이 커밋될 때마다 디스크에 변경된 데이터를 반영하기 때문에 커밋된 데이터는 항상 디스크에 있고, 따라서 복구 알고리즘은 redo를 수행하지 않아도 된다. 하지만 커밋 연산의 비용이 증가하기 때문에 잘 사용하지는 않는다.
- steal : 커밋되지 않은 데이터가 디스크에 저장되는 것을 허용.(default)
- no-steal : 커밋되지 않은 데이터는 디스크에 저장될 수 없음
steal/no-steal 정책의 경우 커밋되지 않은 데이터를 디스크에 반영하는 것에 대해 다루고 있는데, 이중 no-steal정책은 커밋된 데이터만을 디스크에 저장하기 때문에 디스크에는 커밋되지 않은 데이터가 저장될 수 없고, 따라서 복구 알고리즘은 undo를 수행하지 않아도 된다. 하지만 이 경우 어플리케이션이 모든 변경사항을 가지고있어야 하는데, 어플리케이션의 성능이 저하되므로 잘 사용하지 않는다.
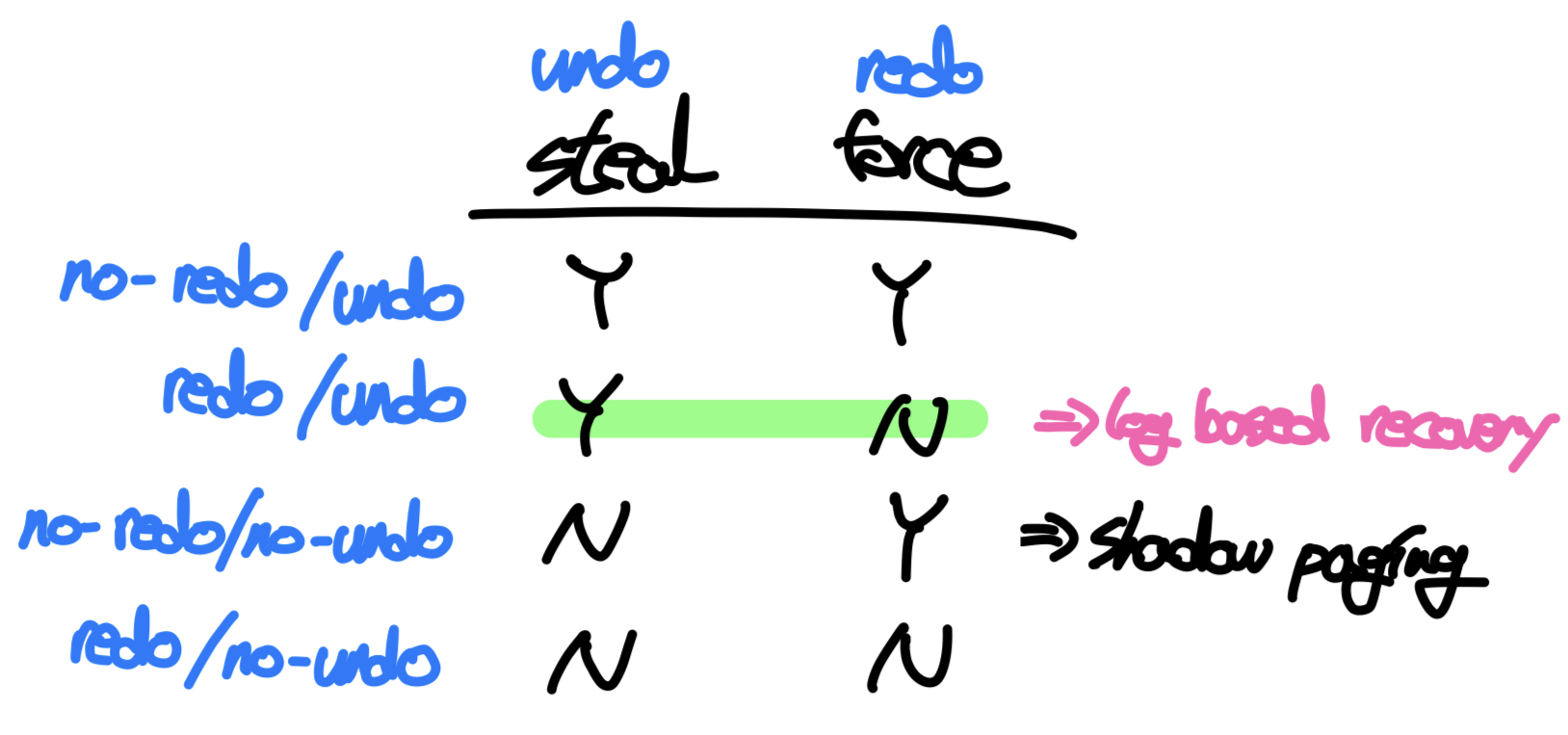
DB의 버퍼링 정책을 steal과 force를 기준으로 정리해보면 위의 표와 같다. 로그 기반 복구 알고리즘은 redo와 undo를 모두 준비하여 DB버퍼링의 기본 정책인 steal/no-force 정책을 지원한다. 하지만 no-steal/force 정책의 경우 복구 알고리즘은 redo와 undo모두 지원하지 않아도 되는데, 이 경우 Shadow paging 기반의 복구 알고리즘이 사용된다.
