동시성 제어
하나의 DBMS에서 여러 트랜잭션들이 동시에 처리되면 프로세서 및 디스크 활용도가 늘어나 throuput(단위시간당 처리되는 트랜잭션의 수)이 증가하고, 짧은 트랜잭션이 다른 트랜잭션들을 기다리지 않아도 되기 때문에 response time(응답시간)이 줄어드는 이점이 있다. 하지만 동시에 여러 트랜잭션이 실행되기 때문에 각 트랜잭션 안의 작업이 수행되는 순서에 따라 예상하지 못한 결과가 나올수도 있다. 이를 방지하기 위해 DBMS는 각 트랜잭션의 독립성과 정확성을 보장하기 위해 동시성을 제어하는 방법을 마련해야 하는데, 대표적인 방법으로 트랜잭션 스케줄링이 있다.
스케줄링
트랜잭션의 Schedule이란 여러 트랜잭션을 동시에 처리하기 위한 시간적 작업 순서를 의미한다. 각 트랜잭션은 하나 이상의 작업으로 이루어져있는데, 각 트랜잭션을 구성하는 작업의 상대적인 순서에 따라 다른 스케줄을 만들 수 있다.
T1 T2
read(A) read(A)
A := A - 50 temp := A * 0.1
write(A) A := A - temp
read(B) write(A)
B := B + 50 read(B)
write(B) B := B + temp
commit write(B)
commitT1은 A가 B에게 50원을 송금하고, T2는 A의 잔액의 10%를 B에게 송금하는 트랜잭션이다. 위와 같은 작업을 포함한 두 트랜잭션이 있을 때, 각 작업의 순서를 조정하여 스케줄 S1~S4를 만들 수 있다.
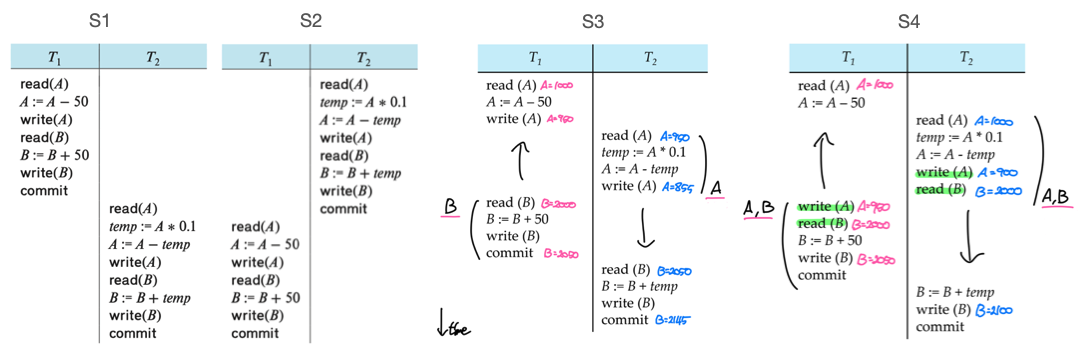
이외에도 구성할 수 있는 스케줄의 경우의 수는 매우 많지만 모든 스케줄에서 각 트랜잭션 내부의 작업순서는 지켜져야 한다.
위의 예시에서 S1은 T1->T2순서로, S2는 T2->T1순서로 실행되지만 S3와 S4는 두 트랜잭션이 동시에 실행된다. A = 1000, B = 2000일때 각 스케줄에 따라 트랜잭션을 실행한 결과는 아래 표와 같다.
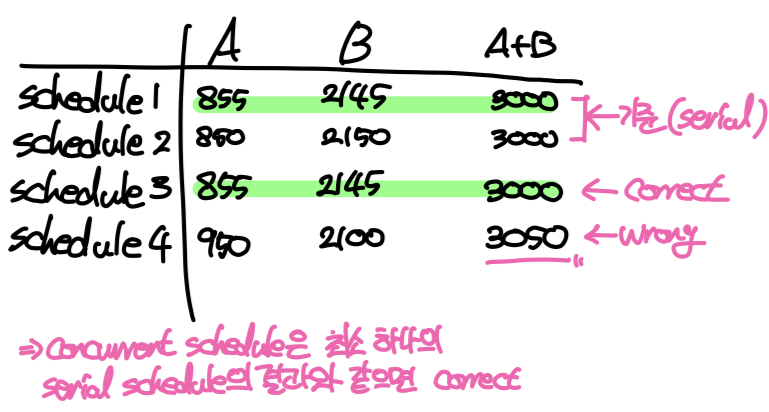
결과를 보면 S1과 S2의 경우 A,B의 값이 다르지만 A+B의 값은 3,000으로 같다. 또한 S3의 결과는 S1과 같은 것을 확인할 수 있다. 하지만 S4의 경우 A,B의 값 뿐만 아니라 A+B의 값도 다른 스케줄과는 다르다. 이처럼 스케줄에 따라 결과가 달라질 수 있기 때문에, DBMS는 이중 올바른 결과를 산출하는 스케줄을 선택해야 한다. 이때 기준으로 잡는 스케줄이 바로 S1, S2와 같은Serial Schedule이다.
Serial Schedule
Serial Schedule이란 스케줄 중에서 모든 트랜잭션이 순서대로 처리되는 스케줄로, DBMS는 serial schedule의 결과를 기준으로 스케줄의 정확성을 판단한다. 즉, 위의 예시에서 S3는 serial schedule인 S1과 결과가 같기 때문에 DBMS가 선택할 수 있는 스케줄이지만, S4의 경우 T1와 T2로 구성가능한 모든 serial schedule중 하나도 일치하는 것이 없으므로 reject한다.
Serial schedule의 개수는 동시에 실행되는 모든 트랜잭션을 순서대로 나열하는 경우의 수와 같기 때문에, n개의 트랜잭션이 동시에 수행될때 만들 수 있는 serial schedule의 개수는 n!개이다. 따라서 concurrent schedule은 하나 이상의 serial schedule과 결과가 같으면 DBMS에서는 이 스케줄의 결과가 정확하다고 판단한다.
위의 예시에서 S3와 S4는 모두 concurrent schedule이지만 S3는 accept될 수 있고, S4는 reject된다. 아래 그림에서 두 스케줄의 작업순서를 좀 더 자세히 확인할 수 있다.
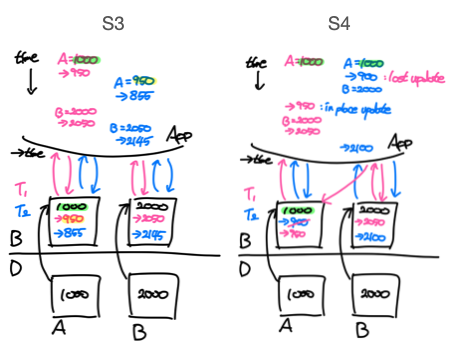
S3를 보면 T1이 버퍼에서 A를 가져와서 작업을 처리하고 다시 버퍼에 저장한 다음 T2가 A값에 접근하는 것을 볼 수 있다. 하지만 S4를 보면 T1이 먼저 A값을 어플리케이션으로 가져오고 값을 변경하는데, T1이 A를 버퍼에 쓰기 전에 T2에서 A값을 가져와 작업을 수행하는 것을 확인할 수 있다. 그 다음 T2가 먼저 A의 값을 바꿔서 버퍼에 쓰지만 이후 T1에서 변경한 값을 그대로 버퍼에 덮어쓰면서 T2에서 변경한 A의 값이 무시된다. 즉, T2의 write(A)는 무시되고 (Lost update) T1의 write(A)는 기존 값을 덮어쓰는 (in-place update) 상황이 발생하였다. 이 때문에 S4는 serial shcedule과 결과가 달라 정확하지 않은 값을 가지게 되고, 그 결과 S4가 수행되면 DB의 정합성(일관성)을 해칠 수 있기 때문에 DBMS는 S4를 reject한다.
Serializability
둘 이상의 트랜잭션이 수행될 때 올바른 결과를 내는 가장 간단한 방법은 Serial schedule을 채택하는 것이지만, DBMS는 트랜잭션 처리의 효율을 높이기 위해서 Concurrent schedule을 채택한다. 이때, Concurrent schedule중에서도 DB의 일관성을 해치지 않는 스케줄을 선택하기 위해서 DBMS는 Serializable한 스케줄을 선택한다. Serializability란 스케줄을 serial schedule로 만들 수 있는 특징으로, 자신과 동일한 결과를 가지는 serial schedule이 있을 때 이 스케줄은 serializable하다.
Serializability는 기본적으로 모든 트랜잭션과 Serial schedule은 DB 일관성을 보장한다는 가정하에 출발한다. 따라서 Serializable schedule 역시 DB 일관성을 보장하므로 DBMS에서 이 스케줄을 선택해도 문제가 되지 않는다.
Conflict
스케줄이 Serializable한지 확인하기 위해서는 현재 스케줄에 Conflict(충돌)가 발생하였는지 확인한다. Conflict란 서로 다른 두 트랜잭션에서 작업의 순서가 전체 스케줄의 결과에 영향을 미칠 때 발생한다. 즉, 충돌이 발생한 두 작업의 순서가 바뀌면 전체 스케줄의 결과가 바뀌는데, 일반적으로 서로 다른 트랜잭션에서 동시에 같은 데이터에 접근할 때 발생한다. conflict에 영향을 주는 read/write연산만을 고려했을때 다음과 같은 경우 충돌이 발생한다.
- Ti: read(A), Tj: write(A)
- Ti: write(A), Tj: read(A)
- Ti: write(A), Tj: write(A)
즉, 동일한 데이터에 대해서 read-write혹은 write-write의 순서를 바꾸면 결과에 영향을 주므로 충돌이 발생한다(read(A) - read(A)는 충돌이 발생하지 않는다).
한 스케줄 S가 위와 같은 충돌이 발생하지 않는 작업들의 순서를 조정해서 스케줄 S'로 변환할 수 있다면 S와 S'은 (Conflict)Equivalant하다. 이때 S'이 Serial schedule이라면 S는 (Conflict) Serializable하다.
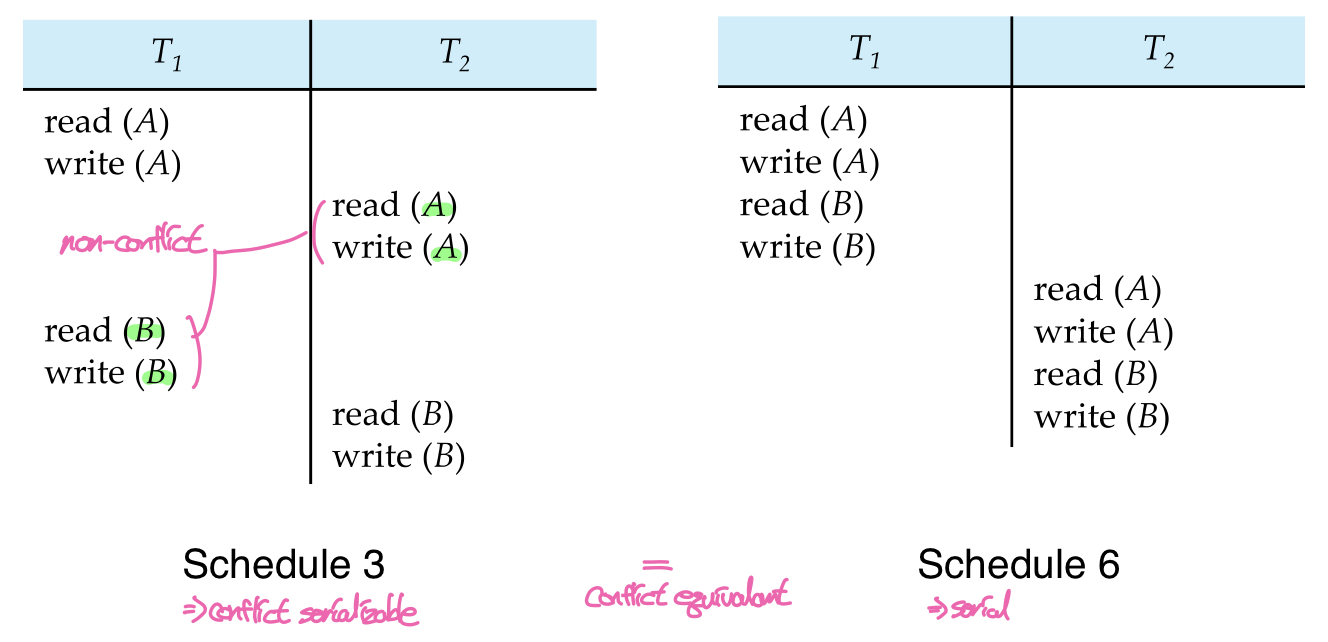
위의 예시에서 S3를 T1 -> T2로 직렬화하기 위해서는 T1의 read(B)->write(B)와 T2의 read(A)->write(A)의 순서를 바꿔야 하는데, 두 작업이 서로 다른 데이터에 접근하기 때문에 충돌이 발생하지 않으므로 오른쪽의 S6으로 변환이 가능하다. 따라서 S3와 S6는 conflict equivalant하고, S6가 serial하므로 S3는 conflict serializable하다.
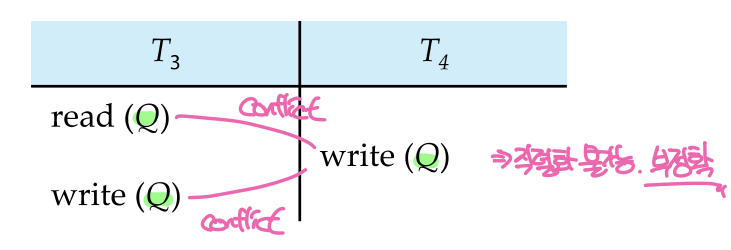
하지만 이 경우 T3와 T4가 동일한 데이터 Q에 접근하고있는데, 이 스케줄을 직렬화시키기 위해서는 T3의 read(Q)와 T4의 write(Q)의 순서를 바꾸거나 T3의 write(Q)와 T4의 write(Q)의 순서를 바꿔야 한다. 하지만 두 경우 모두 충돌이 발생하기 때문에(read-write, write-write) 이 스케줄은 conflict serializable하지 않다.
주의사항
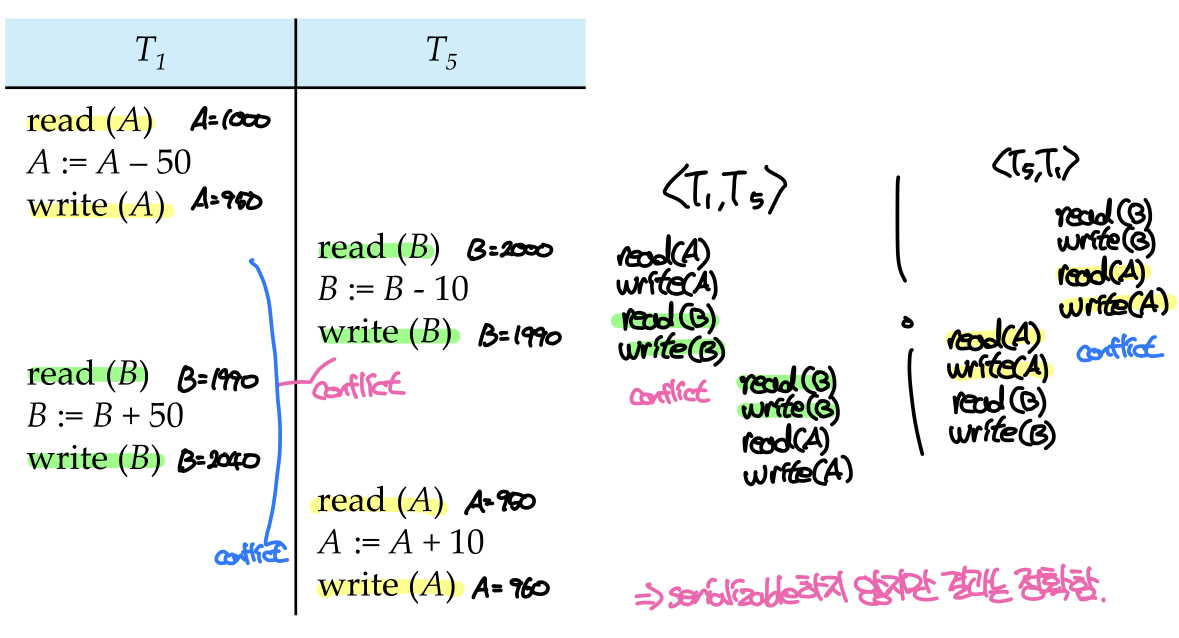
위 스케줄을 직렬화하기 위해서는 (T1->T5)T1의 read(B)와 T5의 write(B), 혹은 (T5->T1)T1의 write(A)와 T5의 write(A)의 순서가 바뀌어야 한다. 하지만 두 경우 모두 충돌이 발생하므로 이 스케줄은 conflict serializable하지 않다. 하지만 A = 1000, B = 2000일 때 이 스케줄을 수행한 결과는 (A, B, A+B) = (960, 2040, 3000)으로 serial schedule인 (T1->T5), (T5->T1)과 결과가 같다. 이처럼 Serializable한 스케줄은 Correct하지만 그 역은 성립하지 않는다.
Testing Serializability
한 스케줄이 Seriazable한지 검사하기 위해서는 해당 스케줄에 대한 Precedence graph를 만들고, 그래프에 Cycle이 발생하는지 확인하는 방법으로 conflict의 유무를 검사할 수 있다. Precedence graph란 스케줄을 구성하는 모든 트랜잭션을 노드로 가지고 다음 3가지중 한가지 조건을 만족하는 간선을 가지는 그래프이다.
- write before read
- read before write
- write before write
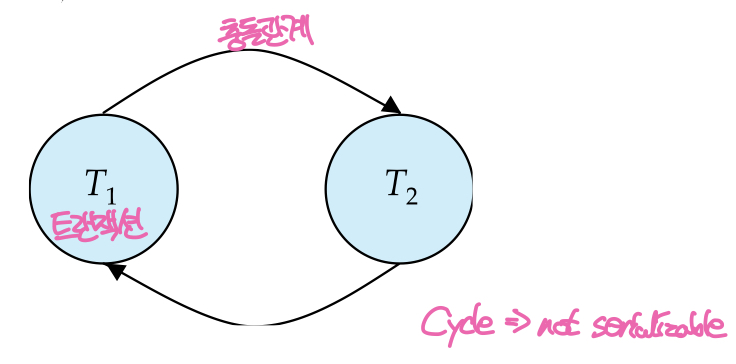
스케줄에 대해 precedence graph를 구성한 다음에는 이 그래프에 cycle이 발생하는지 검사한다. 만약 cycle이 있다면 트랜잭션 사이에 충돌관계가 있는 것이므로 serializable하지 않다. 반대로 cycle이 없다면 이 스케줄은 직렬화가 가능하므로, topological sorting(위상정렬)을 통해 직렬화를 위한 트랜잭션들의 순서를 결정할 수 있다.
하지만 런타임에 Serializability를 검사하여 스케줄을 고른 뒤 트랜잭션을 실행하는 것은 많은 시간이 소모되고 비효율적이기 때문에, 일반적으로 모든 트랜잭션은 Serializability를 보장하는 프로토콜을 따라 수행되고, 사후에 해당 스케줄이 Serializable한지 검사할 때 Precedence graph가 사용된다.
Recorverablility
지금까지는 항상 commit이 성공하는 경우만 다루었는데, 실제 DB환경에서는 여러가지 이유로 트랜잭션이 실패하는 경우가 생긴다. 이때 DBMS는 해당 트랜잭션이 실행되기 전 시점으로 DB를 복구해야 하는데, 여러 트랜잭션이 동시에 실행되는 경우 정상적으로 복구가 되지 않을 수도 있다. 따라서 이를 해결하기 위한 방법으로 DBMS는 트랜잭션들을 복구 가능(Recorverable)하도록 스케줄링 해야한다.

이 스케줄에서 T9가 작업을 마치면 commit하여 DB에 변경된 A를 반영한다. 하지만 이후 T8에서 작업이 실패하여 abort되면 DB는 이 스케줄이 시작되기 이전 시점으로 복구되어야 하는데, 이미 T9이 commit되었으므로 복구가 불가능하다. 이 스케줄이 Recoverable하지 않은 이유는 내부 트랜잭션인 T9가 read(A)에서 커밋되지 않은 dirty data읽고 T8보다 먼저 커밋되어 dirty data가 그대로 DB에 반영되었기 때문이다.
따라서 이런 상황을 해결하기 위해서 DBMS는 Recorverable한 스케줄을 채택해야 하는데, 한 트랜잭션이 데이터를 변경한 다음 커밋하기 이전에 다른 트랜잭션이 해당 데이터를 읽었다면 데이터를 변경한 트랜잭션이 먼저 커밋될 때 이 스케줄은 Recorverable schedule하다. 즉, dirty data를 읽은 트랜잭션이 나중에 commit되어야 스케줄이 Recorverable하다고 말할 수 있다.
참고로 Serializability가 DB의 일관성을 보장하기 위한 것이었다면 Recorverablility는 트랜잭션의 원자성을 보장하기 위해서 필요하다. 즉, 위의 예시는 Recoverable하지 않은 스케줄로 인해 T8의 원자성이 깨진 경우이다.
Cascading rollback
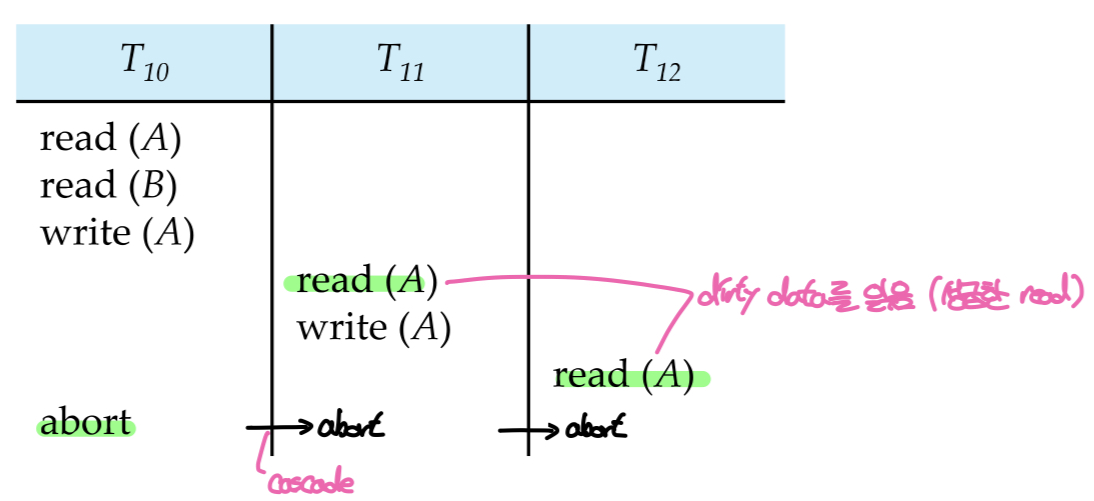
Cascading rollback이란 아래의 스케줄과 같이 한 트랜잭션의 실패로 인해 다른 트랜잭션들이 줄줄이 rollback되는 것을 말한다. Cascading rollback이 발생하면 스케줄의 모든 트랜잭션이 롤백되었기 때문에 복구 가능한 스케줄이지만 많은 양의 작업들이 무효화되었기 때문에 자원을 낭비할 수 있다는 문제점이 있다.
Cascadeless Schedule
Cascading rollback은 주로 dirty data를 읽는 작업(성급한 read)으로 인해 발생한다. 따라서 Cascading rollback이 발생하지 않는 스케줄을 만들기 위해서는 한 트랜잭션이 데이터를 변경했을 때 이를 커밋한 이후에 다른 트랜잭션이 읽도록(dirty data를 읽지 않도록) 작업의 순서를 조정해야 한다. 이러한 조건을 만족하는 스케줄을 Cascadeless schedule이라고 한다. Cascadeless schedule은 데이터를 변경한 트랜잭션이 해당 데이터에 접근하는 트랜잭션보다 먼저 커밋되어야 하므로 자연스럽게 Recorverability를 만족한다.
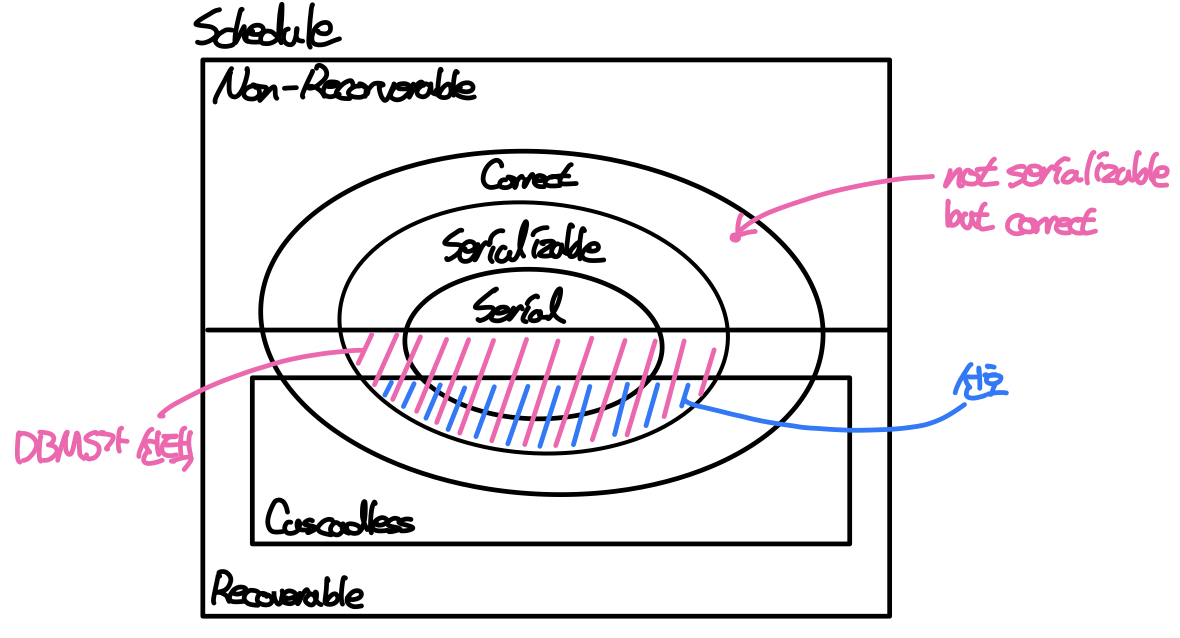
따라서 DBMS는 동시성 제어를 위해 Serializable하고 Recorverable한 스케줄을 선택하고, 가능하면 Cascadeless한 스케줄을 선호한다.
