1. 컴퓨터 시스템 개요
운영체제의 이해를 돕기 위해 그 기반이 되는 컴퓨터 시스템 하드웨어에 대해 정리한다.
컴퓨터 구조에 관한 자세한 내용은 Computer Architecture 시리즈를 참고하자.
1.1 컴퓨터의 기본 구성요소
컴퓨터는 일반적으로 아래 4가지 구성요소로 이루어져 있다.
- 프로세서(Processor): 컴퓨터의 동작을 제어하고 데이터를 처리하는 유닛
- 주기억장치(Main memory): 데이터와 프로그램을 저장. 휘발성(volatile)메모리
- 입출력 모듈(I/O module): 컴퓨터와 외부 환경간의 데이터 이동을 담당
- 외부 환경 : 보조기억장치(디스크), 통신장비 등
- 시스템 버스(System Bus): 프로세서, 주기억장치, 입출력 모듈간의 통신을 제공
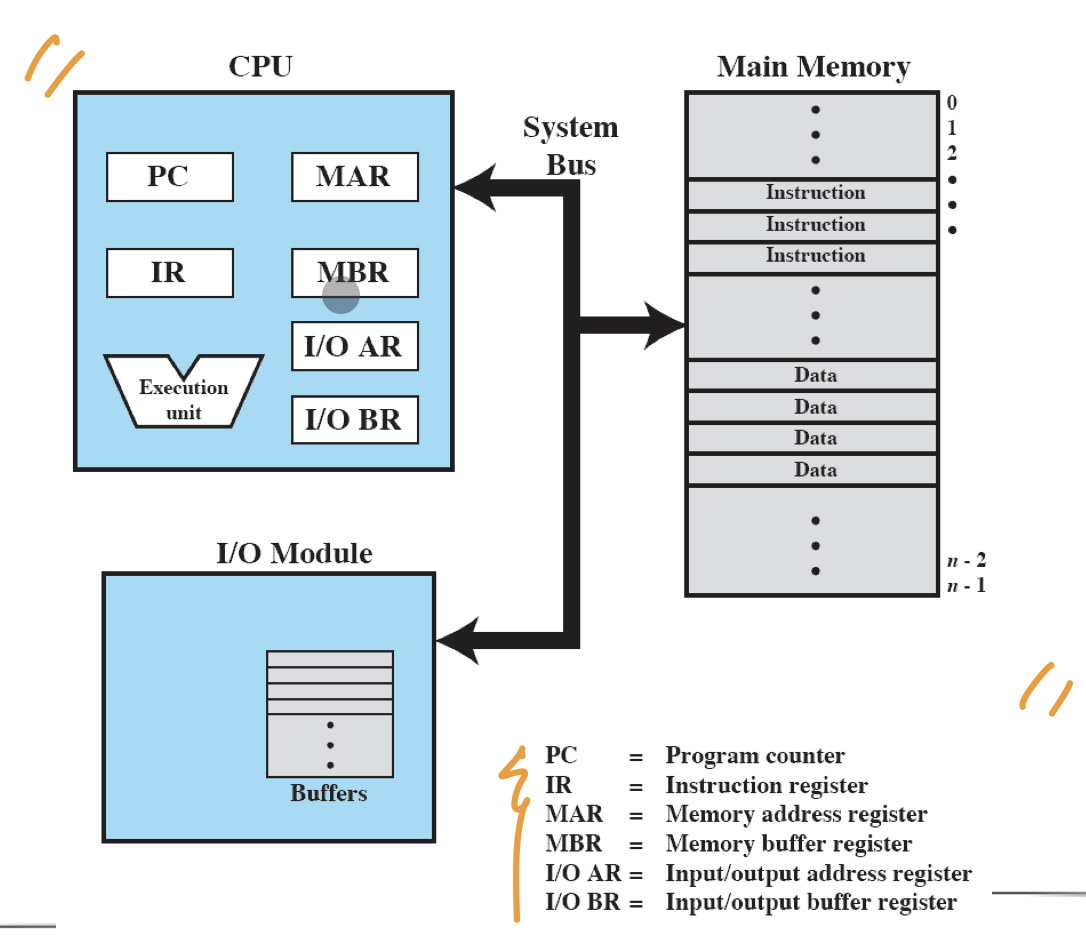
프로세스의 주요 기능중 하나는 메모리와 데이터를 교환하는 것이다, 이를 위해 프로세서 내부에는 메모리보다 작지만 빠른 저장공간인 레지스터를 가지고있다.
위의 그림에서 프로세서는 MAR에 저장한 주소의 데이터를 메모리로부터 읽어 MBR에 저장하거나 MAR의 주소에 저장할 데이터를 MBR에 담아둔다. 비슷한 방식으로 I/O모듈과의 통신에는 I/O AR과 I/O BR이 사용된다.
레지스터는 사용자에 따라 크게 두 가지 종류로 나눌 수 있다.
- User visible register : 메인메모리로의 참조를 최소화하기 위해 모든 프로그래머에게 제공되는 레지스터
- Data
- Address(Index, Segment pointer, Stack pointer)
- Control & Status register : 프로세서나 프로그램의 동작을 제어하기 위해 권한이 주어진 운영체제가 사용하는 레지스터
- PC(Program Counter) : 다음으로 fetch되는 명령의 주소
- IR(Instruction Register) : 가장 최근에 fetch된 명령
- PSW(Program Status Word) : Condition codes(flag). 명령을 실행한 결과값
1.2 명령어 사이클
프로그램이란 메모리에 저장된 명령어들의 집합으로, 프로세서에 의해 수행된다. 프로세서는 한번에 하나의 명령을 메모리로부터 읽고 실행하는 과정을 반복하며 프로그램을 수행한다.
명령어 사이클이란 하나의 명령을 수행하기 위한 처리과정으로, 가장 단순한 버전인 2단계 명령어 사이클의 모습은 아래 그림과 같다.
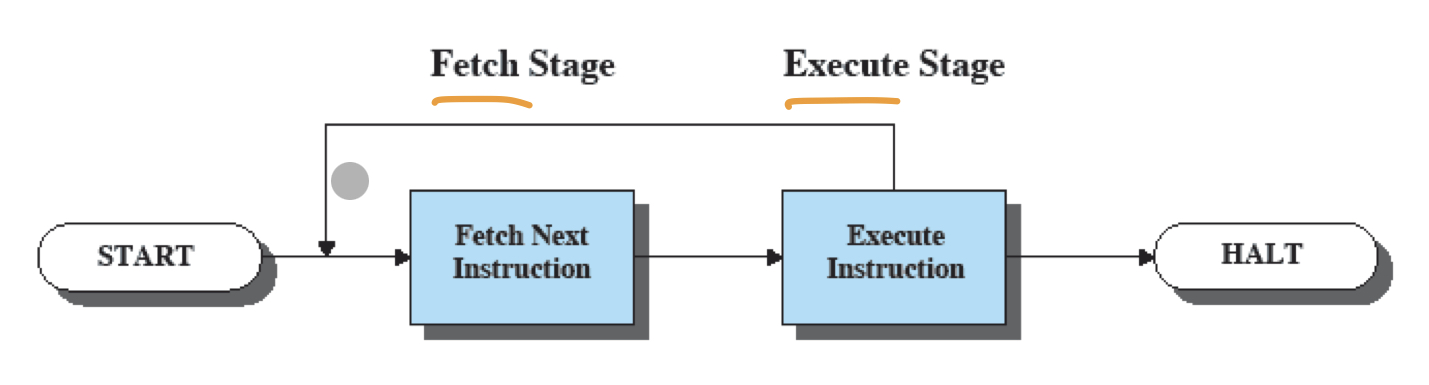
- Fetch Stage : 프로세서가 메모리로부터 명령어를 읽어오는 단계
- Execution Stage : 프로세서가 읽어들인 명령어를 수행하는 단계
프로세서는 별도의 명령이 없는 한, fetch단계 이후 PC의 값을 증가시켜 다음 명령어가 순서대로 읽어지도록 하고, fetch된 명령어는 IR에 저장되어 프로세서가 명령어를 해석하고 작업을 수행하도록 한다.
일반적으로 프로세서가 수행하는 작업은 4가지로 나눌 수 있다.
- 메모리로부터 데이터 읽기, 데이터 쓰기
- I/O모듈과 데이터 송/수신
- 데이터 산술, 논리연산
- 제어명령(명령어 수행 순서 변경)
1.3 인터럽트
인터럽트의 등장 배경
일반적으로 프로세서는 메모리나 입출력장치에 비해 훨씬 빠르다. 그런데 만약 프로세서로 들어온 명령이 입출력장치를 통해 값을 입력받아 사용해야 한다면 프로세서는 입출력장치로부터 값이 전달될 때까지 idle상태가 되어 수많은 클락사이클이 낭비된다. 이렇게 낭비되는 시간을 줄이기 위해 등장한 방법이 인터럽트이다.
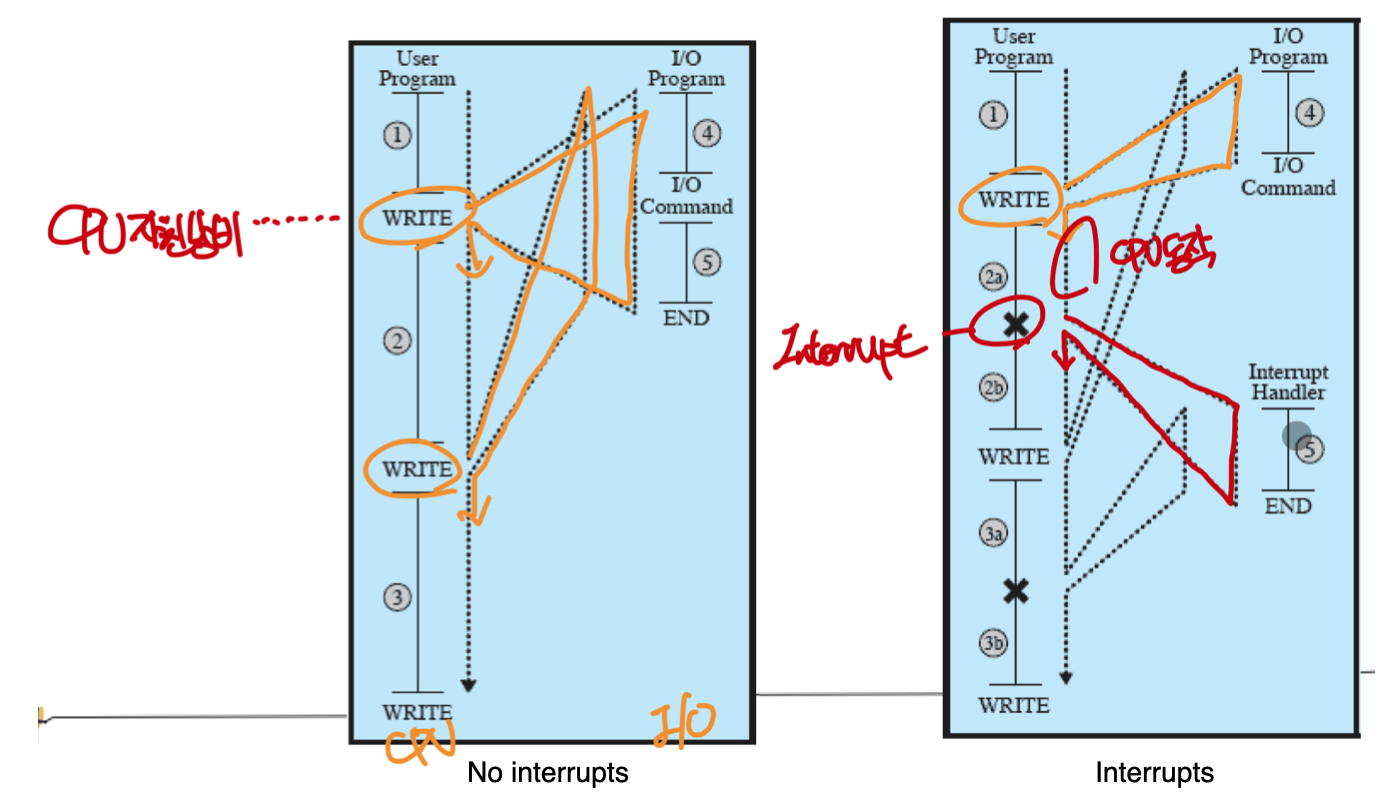
인터럽트를 이용하는 경우 프로세서는 I/O장치에게 작업을 지시하고 입출력 연산이 진행되는 동안 다른 명령을 수행시킨다.
그 후 I/O장치의 작업이 완료되면 I/O장치는 프로세서에게 인터럽트 요청을 보낸다.
요청을 받은 프로세서는 진행중이던 프로그램의 작업을 보류하고 인터럽트 처리기로 분기하여 I/O장치에 대한 서비스를 진행한 뒤 다시 프로그램을 재개한다.
사용자 입장에서 인터럽트는 정상적인 프로그램의 수행을 중지한 뒤 다시 수행하는 것이기 떄문에 사용자가 I/O장치의 작업을 위해 특별한 코드를 작성할 필요가 없다. 프로그램의 수행을 중단하고 인터럽트 처리 후 같은 곳에서 프로그램을 재개하는 것은 운영체제와 프로세서의 몫이다.
인터럽트를 포함한 명령어 사이클
인터럽트를 포함한 명령어 사이클은 총 3단계로 구성되어있다.
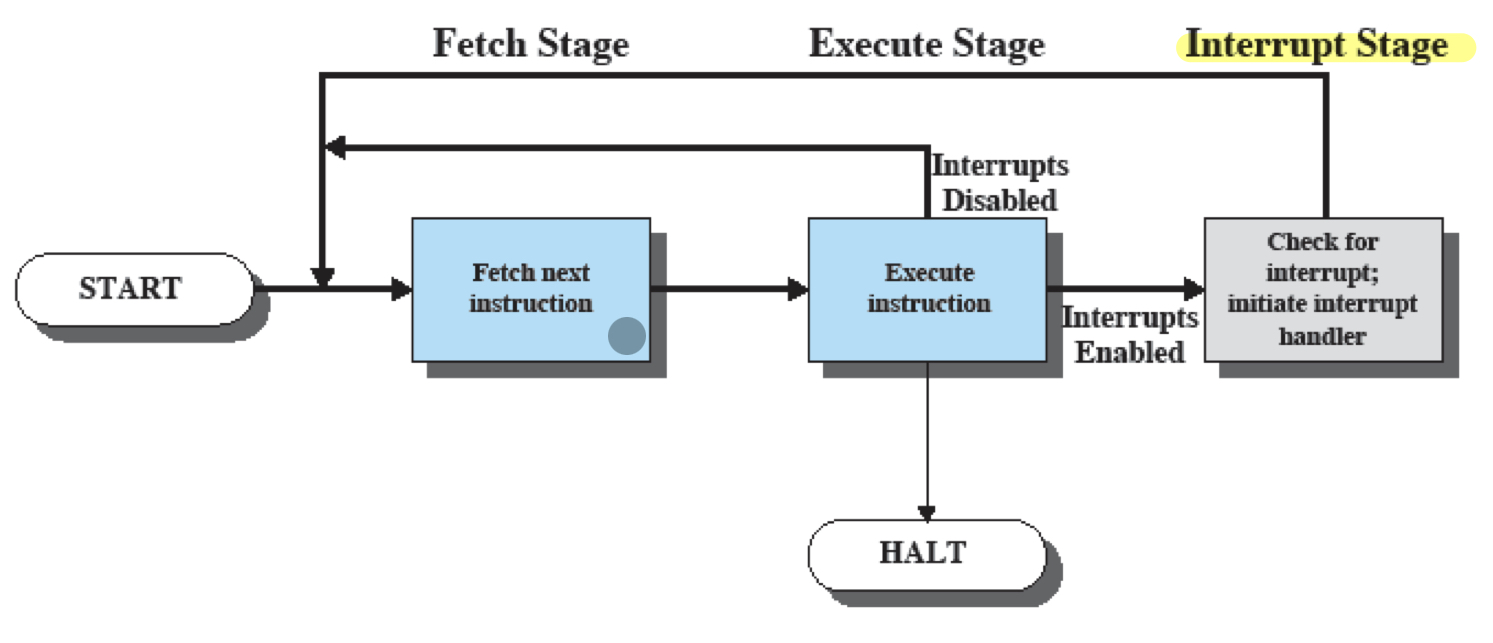
이전 2단계 명령어 사이클에서 인터럽트 단계가 추가되었는데, 이 단계에서는 인터럽트 핸들러가 인터럽트의 발생여부를 검사하여 인터럽트 요청이 없으면 정상적으로 다음 명령어를 fetch하고, 인터럽트 신호가 있으면 현재 프로그램의 수행을 중단하고 인터럽트 서비스 루틴(ISR)을 수행한다.
인터럽트 처리과정
인터럽트의 구체적인 처리과정은 다음과 같다.
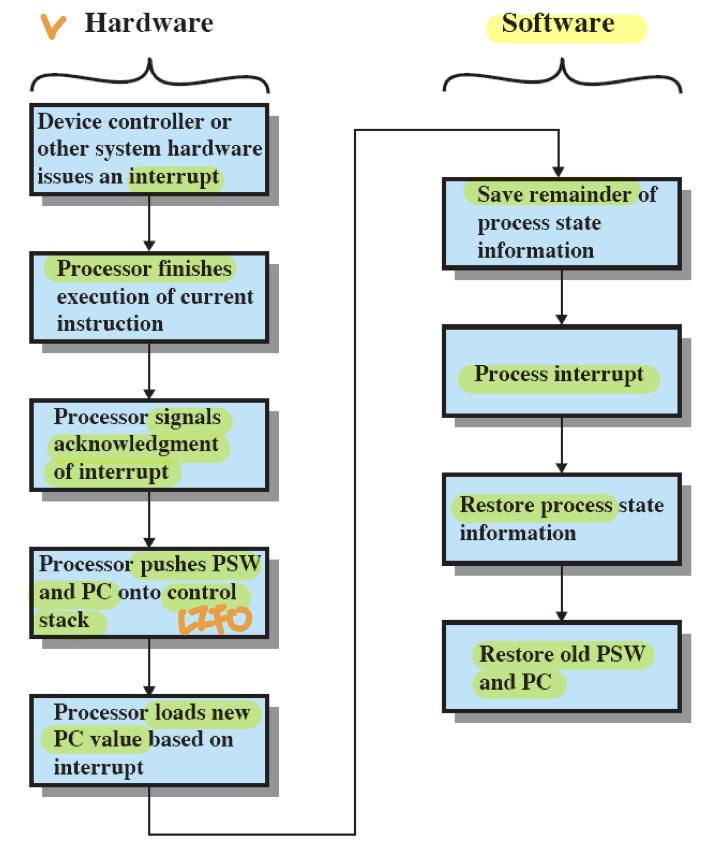
- 입출력 장치가 프로세서로 인터럽트 신호를 보낸다.
- 프로세서는 현재 처리중인 명령을 완료한 뒤 다음 명령을 불러오기 전에 인터럽트 핸들러에 의해 인터럽트 신호를 검사한다.
- 인터럽트 핸들러는 인터럽트 신호를 확인하고 입출력 장치에게 수신확인 신호를 보내 장치가 인터럽트 신호를 제거할 수 있도록 한다.
- 프로세서가 인터럽트 핸들러로 제어권을 넘기기 위해 현재 프로그램을 재개하는데 필요한 정보(PSW, PC등)를 컨트롤 스택에 저장한다.
- 프로세서는 PC에 ISR의 진입점을 저장하여 인터럽트 핸들러 프로그램이 수행되도록 한다.
- 인터럽트 핸들러는 프로세서의 레지스터를 사용하기 위해 현재 레지스터의 값들을 컨트롤 스택에 보관한다.
- 인터럽트를 처리한다.
- 인터럽트 처리가 완료되면 레지스터와 PSW, PC의 값을 복구하여 제어를 넘긴다.
중첩 인터럽트
하나의 인터럽트를 처리하는 동안 다른 장치에서 인터럽트 신호가 들어올 수 있는데, 이 경우 나중에 들어온 인터럽트를 처리하는 방법은 인터럽트의 처리순서에 따라 두가지로 나눌 수 있다.
- Sequential : 인터럽트를 처리하는 도중에는 다른 인터럽트를 금지하는 방법
- 인터럽트가 순차적으로 처리된다
- 단점 : 긴급한 인터럽트를 처리할 수 없다
- Nested : 인터럽트 사이의 우선순위를 설정하여 인터럽트를 처리하는 도중 우선순위가 높은 인터럽트가 들어오면 우선적으로 처리할 수 있도록 하는 방법
- 우선순위에 따라 인터럽트의 순서가 결정됨
1.4 메모리 계층구조
메모리의 특성
컴퓨터 메모리를 설계할 때 제약조건은 용량, 속도, 비용 3가지로 요약할 수 있다. 그런데 이 세가지 특성은 상호 절충적인 관계를 보인다.
- 메모리의 접근속도가 빠를수록 비트당 비용이 비싸고,
- 메모리의 용량이 클수록 비트당 비용이 저렴하며,
- 메모리의 용량이 클수록 접근속도가 느려진다.
이러한 딜레마를 벗어나기 위해 메모리는 계층구조를 채택하였다.
메모리 계층구조
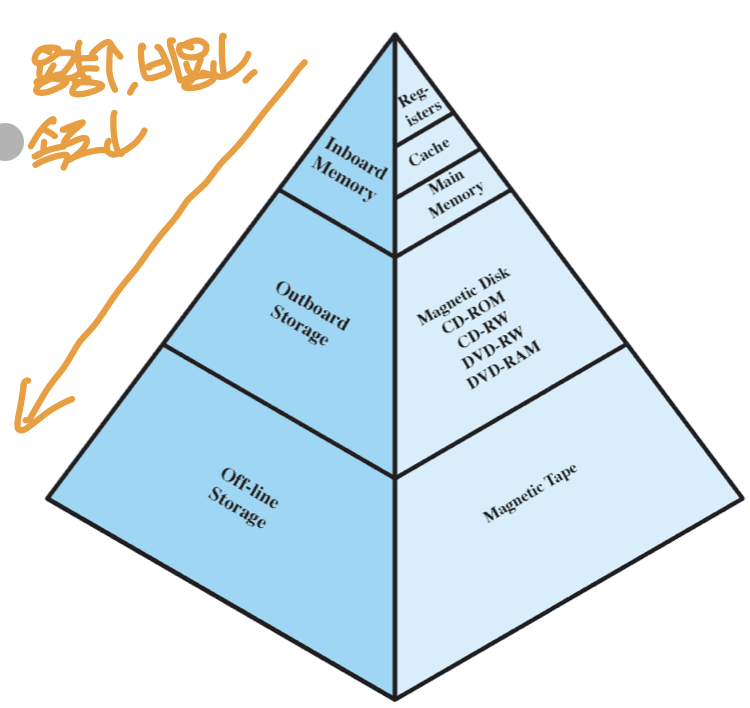
메모리 계층구조에서는 하위계층으로 내려갈수록 아래의 특징을 보인다.
- 비트당 비용 감소
- 용량 증가
- 접근 시간 증가
- 프로세서에 의한 접근 횟수 감소
메모리를 계층구조의 핵심은 더 느린 메모리에 대한 프로세서의 접근횟수를 줄여, 상위 메모리에서의 hit ratio를 높이는 것이다. 이를 위해서 여러가지 메모리 관리 기법이 존재하는데, 이들의 이론적 기반은 참조지역성(locality of reference)의 원리에 있다.
참조지역성
참조지역성이란, 프로그램이 수행되는 동안 명령어와 데이터에 대한 프로세서의 메모리참조는 인접한 지역으로 몰리는 경향이 있다는 원리이다. 프로그램에는 일반적으로 많은 반복루프와 서브루틴이 존재하고, 테이블이나 배열같은 데이터들의 경우에도 메모리의 인접한 지역에 밀집되어 분포한다. 따라서 하위메모리의 참조가 일어날 때, 그 데이터 뿐만 아니라 인접한 데이터까지 상위 메모리로 올린다면 상위 메모리에서의 hit ratio를 높일 수 있다.
보조기억장치
메모리는 휘발성에 따라 휘발성 메모리(레지스터, 캐시, 주기억장치)와 비휘발성 메모리(보조기억장치)로 나눌 수 있다. 휘발성 메모리는 말 그대로 전원의 공급이 차단되면 데이터가 날아가버리지만, 비휘발성 메모리는 전력의 공급이 중단되어도 데이터가 유지된다.
보조기억장치의 예로는 대표적으로 디스크(HDD, SDD)를 들 수 있다. 디스크는 주기억장치에 비해 느리지만 훨씬 많은 용량을 가지고있어 프로그램과 데이터파일이 저장된다. 또한 디스크는 메모리를 확장하기 위해 가상메모리로 사용될 수 있다.
1.5 캐시 메모리
캐시의 정의, 목적, 원리
캐시는 프로세서의 성능향상을 위해 레지스터와 주기억장치사이의 데이터 이동시 사용되는 저장장치로, 주기억장치보다 빠르지만 더 적은 용량을 가진 메모리이다.
캐시의 목적은 빠른 속도의 대용량 메모리를 제공하는 것이다. 캐시에는 주기억장치의 일부 복사본이 저장되어있는데, 프로세서가 메모리에 접근하려 할 때 먼저 캐시를 확인하여 캐시에 찾으려는 데이터가 있으면 메모리까지 가지 않고 캐시의 데이터를 사용한다. 만약 캐시에 원하는 데이터가 없으면 메모리에 접근하여 데이터를 불러오는데, 이때 인접한 데이터를 캐시로 복사하여 지역성의 원리에 따라 이후에 데이터를 찾을 때 캐시에서 찾을 확률을 높인다.
캐시의 구조
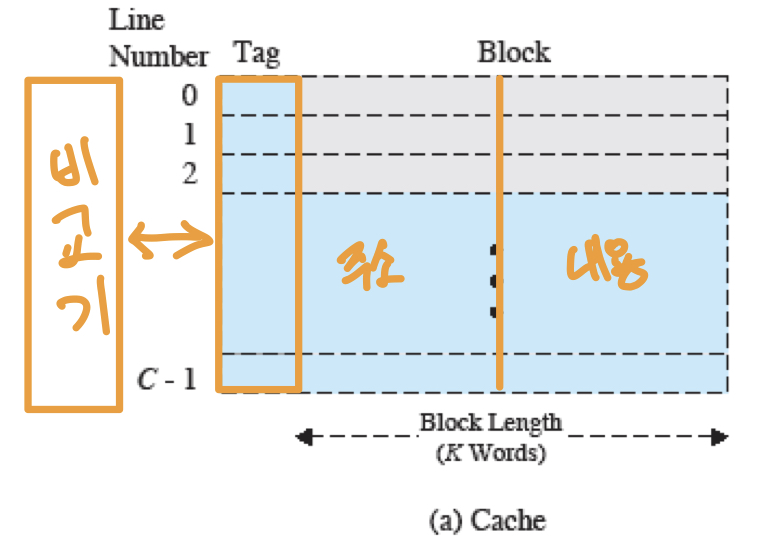
주기억장치의 각 주소에는 하나의 워드가 저장되고, 몇개의 워드가 모여 고정된 길이의 블록을 구성한다. 캐시는 이 블럭과 태그를 매핑한 슬롯의 집합으로 구성되어 있다. 태그는 현재 슬롯에 어떤 블록을 저장하고 있는지를 나타내는 정보이다.
캐시를 설계할 때 캐시의 성능에 영향을 주는 여러가지 요인들이 있다.
- 캐시 크기 : 캐시의 크기가 클수록 성능은 향상되지만 비용이 증가한다
- 블록 크기 : 블록의 크기가 너무 작으면 지역성을 살리지 못하고, 너무 크면 캐시에 저장되는 블록의 수가 적어 hit ratio가 감소한다
- 매핑 함수 : 메모리 블록이 캐시의 어느 위치에 저장될지를 결정하는 함수이다
- 교체 알고리즘 : 모든 캐시슬롯이 채워져있어 블록의 교체가 발생한다면 어떤 블록을 내보낼지 결정하는 알고리즘이다. 일반적으로 가장 오래 참조되지 않은 블록을 교체하는 LRU 알고리즘을 사용한다.
- 쓰기 정책 : 메모리에 데이터를 언제 쓸지 결정하는 정책이다. 블록이 갱신될때마다 메모리에 쓰거나 블록이 교체될 때에만 메모리에 쓰는 방법을 채택할 수 있다
- 캐시 레벨 : 프로세서와 가까운 정도로 캐시의 레벨을 나누어 여러개의 캐시를 둘 수 있다.
1.6 I/O와 DMA
I/O연산은 크게 3가지 방법으로 구현된다.
-
Programmed I/O : 프로그램 수행 도중 I/O연산 명령어가 수행되면 프로세서는 I/O모듈에 작업을 요청한 뒤, I/O모듈이 작업을 마쳐 I/O상태 레지스터의 값을 변경하면 프로세서가 다음 명령을 이어가는 방식으로, 프로세서는 I/O모듈의 상태를 주기적으로 확인해야 하고, I/O작업이 끝날때까지 프로세서가 기다려야하는 단점이 있다.
-
Interrupt-driven I/O : 프로그램 수행 도중 I/O연산 명령어가 수행되면 프로세서는 I/O모듈에 작업을 요청한 뒤 프로그램을 계속 수행한다. I/O모듈은 작업이 끝나면 프로세서에게 인터럽트 신호를 보내고, 인터럽트 신호를 받은 프로세서는 실행중인 프로그램을 중단한 뒤 인터럽트를 처리하고 다시 프로그램을 재개한다. 이 방법은 위의 방식보다는 효율적이지만 I/O작업을 위해 프로세서가 적극적으로 간섭해야 하는 문제가 있다.
-
Direct Memory Access (DMA) : 프로그램 수행 도중 I/O연산 명령어가 수행되면 프로세서는 DMA모듈에 I/O연산을 위임하고 프로그램을 계속 수행한다. 주로 대량의 데이터를 읽거나 쓰는 연산에 사용되며, DMA모듈은 데이터를 블럭단위로 메모리에 쓰거나 읽어들인다. 모든 I/O연산이 종료되면 DMA는 프로세서에게 인터럽트 신호를 보낸다. 이 방법은 프로세서와 DMA모듈이 시스템버스를 두고 경쟁해야 하기 때문에 I/O작업중 프로세서의 속도가 느려질 수 있지만 대용량의 I/O전송상황에서 위의 두 방법보다 효율적이다.
1.7 멀티프로세서, 멀티코어
기술의 발전과 하드웨어 가격의 하락에 따라 컴퓨터의 성능을 향상하고 신뢰성을 증가시키기 위해 병렬처리를 도입했다. 병렬성의 적용을 위한 구조로 대표적으로 멀티 프로세서와 멀티코어를 들 수 있다.
대칭형 멀티프로세서(SMP)
SMP의 특징은 다음과 같다
- 두개 이상의 프로세서로 구성
- 모든 프로세서는 시스템 버스를 통해 메모리와 I/O장치를 공유
- 모든 프로세서는 동일한 기능을 수행할 수 있다
- 시스템은 프로그램의 상호작용을 제공하는 하나의 운영체제에 의해 제어된다
SMP의 잠재적 장점은 아래와 같다. 잠재적이라는 뜻은 SMP시스템의 병렬성을 위해서는 운영체제가 이에 필요한 도구와 기능을 제공할 수 있어야 한다는 의미이다.
- 병렬처리를 통한 성능향상
- 가용성 : 모든 프로세서가 동일한 기능을 수행할 수 있기 때문에 하나의 프로세서가 고정나더라도 동작이 가능하다
- 사용자는 성능향상을 위해 프로세서를 추가할 수 있다
SMP에서 각 프로세서들은 메모리를 통해 서로 통신할 수 있다. 또한 각 프로세서는 최소 하나 이상의 캐시를 가지고 있는데 캐시에는 메모리 블록의 복사본이 저장되어있기 때문에 멀티 프로세서 환경에서 한 프로세서의 캐시의 상태가 변경되면 이 상태가 다른 프로세서의 캐시에 반영이 되어야 한다.
멀티코어
멀티코어 컴퓨터는 두 개 이상의 프로세서가 하나의 칩 안에 결합되어있는 형태의 칩을 사용하는 컴퓨터로 기술의 발전에 따라 프로세서의 성능을 극대화시키기 위해, 캐시와 프로세서의 물리적 거리를 극단적으로 줄여 여러 프로세서와 캐시를 하나의 칩에 넣은것이다.
참고자료
- Operating Systems : Internas and Design Principles - William Stallings
