MySQL vs PostgreSQL: MVCC 비교 분석
데이터베이스에서 동시성을 관리하는 방법은 성능과 데이터 무결성에 큰 영향을 미칩니다. MySQL과 PostgreSQL은 둘 다 MVCC(Multi-Version Concurrency Control)를 지원하지만, 그 구현 방식과 동작 메커니즘이 다릅니다. 이 글에서 두 데이터베이스의 MVCC를 비교하며, 각각의 장단점과 적합한 사용 사례를 살펴보겠습니다.
MVCC란?
구현 방식
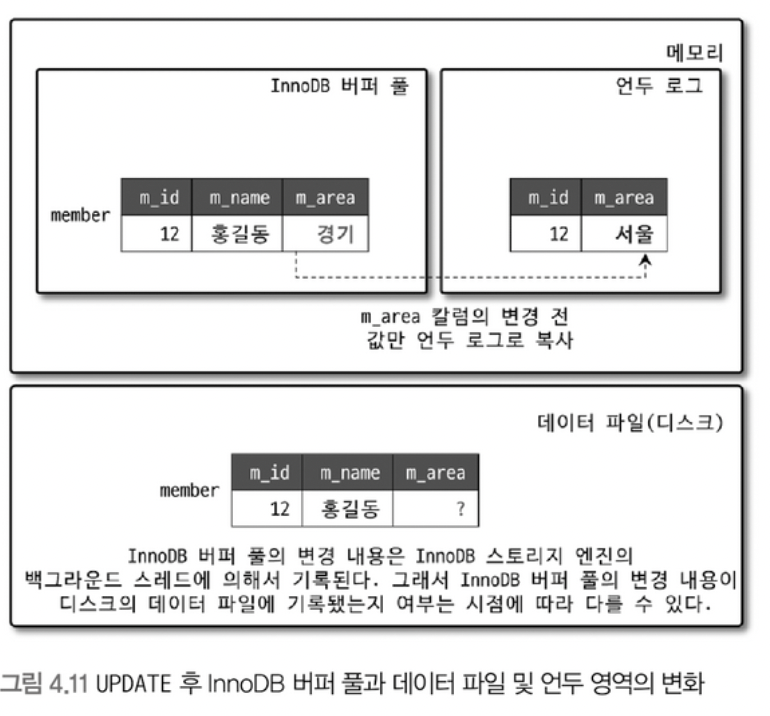
MySQL은 주로 InnoDB 스토리지 엔진에서 MVCC를 구현합니다. InnoDB는 MySQL의 기본 스토리지 엔진으로, 트랜잭션 지원, 외래 키 제약, 그리고 MVCC를 제공하는 강력한 엔진입니다. InnoDB는 Undo Log를 활용해 이전 버전의 데이터를 저장합니다. 트랜잭션이 데이터를 수정하면, 수정 전 데이터는 Undo Log에 기록되고, 다른 트랜잭션은 이 로그를 참조해 일관된 읽기(Consistent Read)를 수행합니다.
- 스냅샷 격리(Snapshot Isolation): READ COMMITTED와 REPEATABLE READ 격리 수준에서 MVCC가 동작합니다. 트랜잭션이 시작될 때 스냅샷을 생성해 해당 시점의 데이터를 읽습니다.
- 행 수준 잠금(Row-Level Locking): 쓰기 작업 시 행 단위로 잠금을 걸어 동시성을 관리합니다.
장점
- 읽기와 쓰기 작업 간의 간섭이 적어, 읽기 중심 워크로드에서 성능이 뛰어납니다.
- Undo Log를 활용하므로 디스크 공간을 효율적으로 사용합니다(일정 조건 하에서).
단점
- Undo Log가 커지면 성능 저하가 발생할 수 있습니다.
- Vacuuming(오래된 데이터 정리) 과정이 없어, 롤백 세그먼트가 비효율적으로 관리될 가능성이 있습니다.
- REPEATABLE READ 수준에서 팬텀 읽기(Phantom Read)가 발생할 수 있습니다.
PostgreSQL의 MVCC
구현 방식
PostgreSQL은 다중 버전 저장 방식을 사용합니다. 데이터가 수정될 때마다 새로운 버전의 튜플(Tuple)을 생성하고, 이전 버전은 그대로 유지됩니다. 각 튜플에는 트랜잭션 ID와 유효성 정보가 포함되어 있어, 트랜잭션이 어떤 버전을 볼지 결정합니다.
- 가시성 체크(Visibility Check): 읽기 작업 시 트랜잭션 ID를 확인해 해당 데이터가 현재 트랜잭션에서 보이는지 판단합니다.
- Vacuum: 오래된 튜플을 정리하기 위해 주기적으로 Vacuum 프로세스를 실행합니다.
장점
- 트랜잭션 격리 수준(Serializable 포함)이 강력하게 보장됩니다.
- 쓰기 작업이 읽기 작업을 차단하지 않아 높은 동시성을 제공합니다.
- 롤백이 간단하고 빠릅니다(새로운 버전만 삭제하면 됨).
단점
- Vacuum 작업이 필요하므로 유지보수 부담이 있습니다.
- 디스크 공간 사용량이 증가할 수 있습니다(특히 업데이트가 빈번한 경우).
- 가시성 체크로 인해 읽기 성능이 약간 저하될 수 있습니다.
주요 차이점 비교
| 특성 | MySQL (InnoDB) | PostgreSQL |
|---|---|---|
| 버전 저장 방식 | Undo Log에 이전 데이터 저장 | 새로운 튜플 생성 |
| 정리 메커니즘 | 자동 롤백 세그먼트 관리 | Vacuum 필요 |
| 격리 수준 | READ COMMITTED, REPEATABLE READ | READ COMMITTED, SERIALIZABLE 등 |
| 디스크 사용 | 상대적으로 효율적 | 업데이트 빈도에 따라 비효율적 가능 |
| 성능 | 읽기 중심 워크로드에 강점 | 복잡한 트랜잭션 처리에 강점 |
어떤 데이터베이스를 선택해야 할까?
MySQL이 적합한 경우
- 읽기 작업이 많고, 간단한 트랜잭션을 처리하는 애플리케이션(예: 웹 애플리케이션, CMS).
- 디스크 공간을 절약하고 유지보수 부담을 줄이고 싶은 경우.
- 기존 MySQL 기반 인프라를 활용해야 할 때.
PostgreSQL이 적합한 경우
- 복잡한 트랜잭션과 높은 데이터 무결성이 필요한 애플리케이션(예: 금융 시스템, 분석 플랫폼).
- SERIALIZABLE 격리 수준 등 강력한 동시성 제어가 필요한 경우.
- JSON, GIS 등 고급 데이터 타입을 활용하려는 경우.
3줄 요약
-
MySQL의 InnoDB는 Undo Log로 MVCC 짜놓고 읽기 퍼포먼스 챙김, PostgreSQL은 튜플 새로 뽑아서 트랜잭션 격리 빡세게 잡음.
-
InnoDB는 정리 자동으로 해줘서 편한데, PostgreSQL은 Vacuum 돌려야 해서 디스크 신경 좀 써야 함.
-
읽기 많으면 MySQL, 트랜잭션 복잡하면 PostgreSQL을 써보자
