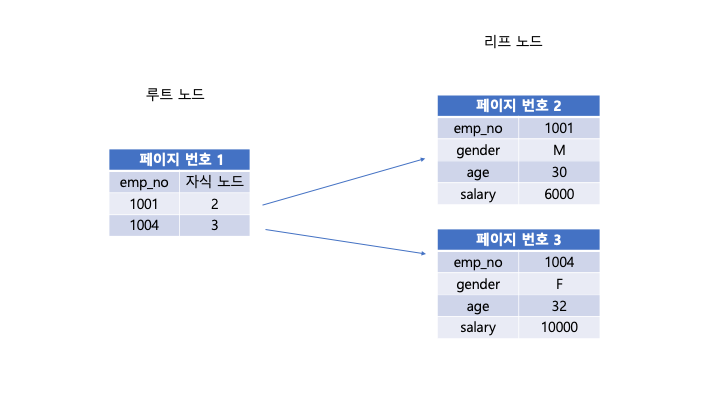
인덱스란?
주변에 보면 정리정돈을 잘 해놓는 사람들이 있다.
무슨 물건을 하나 빌려달라하면 바로 찾아서 준다.
나는 정리정돈을 잘 하지 않는다. 무슨 물건을 찾으려면
다 뒤져봐야 한다. 내가 정리정돈을 하지않는 이유는 물건을
놓을때 '어디다 놔야 할까?'를 생각하는 것이 귀찮기 때문이다.
데이터는 시간이 지날수록 쌓인다. 이때 정리정돈이 귀찮아서 데이터를
그냥 쌓기 시작한다면, 어느 순간 데이터를 찾는데 시간이 오래 걸리게 될 것이다.
시간이 더 걸리더라도 정리정돈을 하면서 자료를 저장하고,
빠른 조회를 할 수 있도록 돕는 것이 데이터베이스의 인덱스다.
B Tree (B+ Tree)
인덱스를 이해하기 위해서는 B Tree(B+ Tree를 가리킨다.)라는 자료구조를 이해해야 한다.
B Tree는 Balanced Tree의 약자로, 양쪽의 서브트리의 높이가 같은 트리를 의미한다.
B Tree의 특징으로는 다음과 같은 것이 있다.
- 모든 데이터는 정렬되어있다.
- 모든 데이터는 leaf node에 나타난다.
- leaf node는 연결되어 있다.
- n차 B Tree는 노드 하나에 최대 n-1개의 데이터를 가질 수 있다.
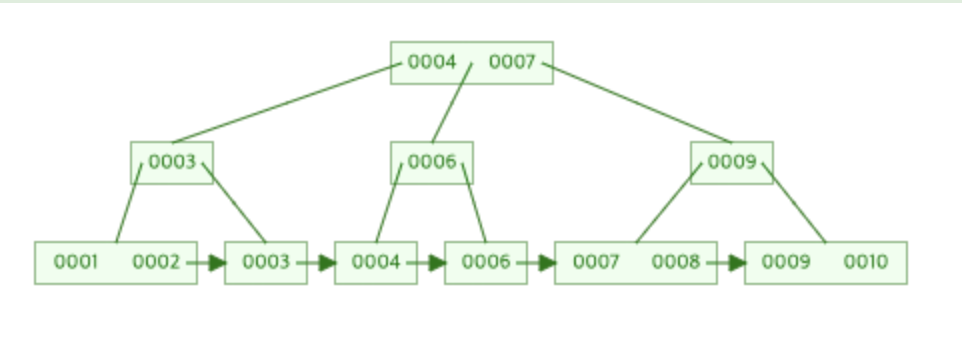
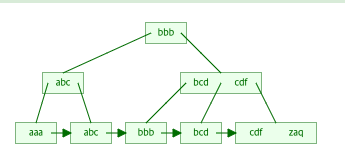
위 그림은 3차 B tree의 예를 보여준다.
각 노드당 최대 2개의 데이터를 가진것을 볼 수 있다.
데이터는 3, 1, 10, 9, 8, 4, 2, 6, 7순으로 삽입되었다.
데이터의 삽입 순서에 따라 모양이 달라진다.
Insert
위에서 시간이 더 걸리는 정리정돈을 얘기했는데, 그 이유가 데이터가 쓰여진 후,
트리의 높이를 조정하는 경우가 발생하기 때문이다.
데이터를 추가하는 로직은 다음과 같다.
1. 해당 데이터가 삽입될 위치(leaf node)를 찾아 삽입한다. 데이터의 수가 '차수'보다 작다면 더이상 작업을 하지 않는다.
2. 데이터의 수가 '차수'와 같다면 데이터를 분할한다.
a. 데이터를 분할할때 현재 위치가 leaf node라면 두 부분으로 나누고 두번째 분할의 최소값을 복사하여 상위노드에 삽입한다.
b. 데이터를 분할할때 현재 위치가 leaf node가 아니라면 중간값을 제외하여 두 부분으로 나누고 중간값을 상위노드에 삽입한다.3차 B tree를 예를들어 3, 1, 10, 9, 8, 4, 2, 6, 7을 추가해보자.
먼저 3과 1을 삽입해보자.

현재까지는 데이터의 수가 차수 미만이므로 추가 후 더이상 작업하지 않는다.
10을 삽입한다.
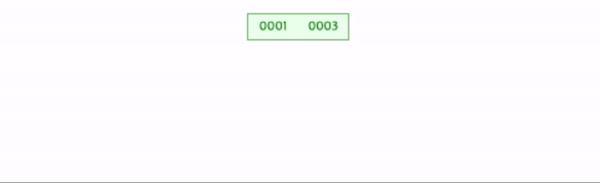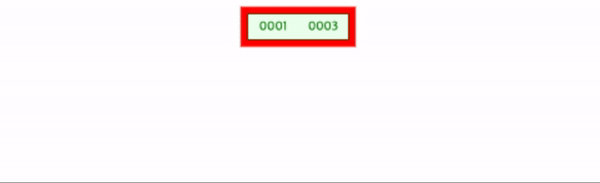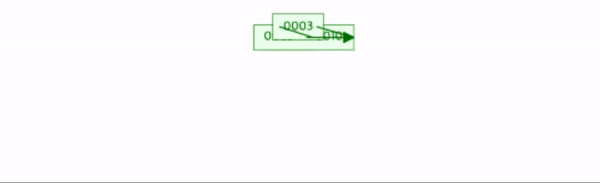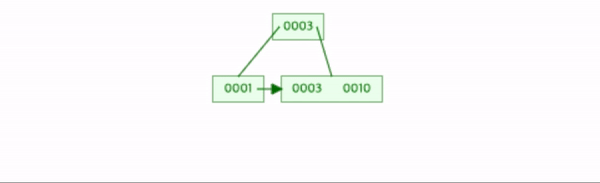
10을 삽입하면 현재 데이터의 수가 차수와 같다. 따라서 분할을 한다.
이때 1, 3, 10이라는 데이터는 leaf node에서 분할한다.
2번의 a 작업을 한다.
데이터가 3개이며 중간 위치는 3 / 2 = 1이다. 1번째 x의 값 3을 복사하여 상위노드 삽입한다.
9를 삽입한다.
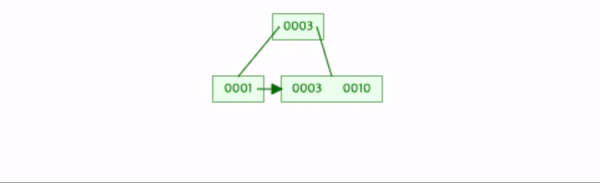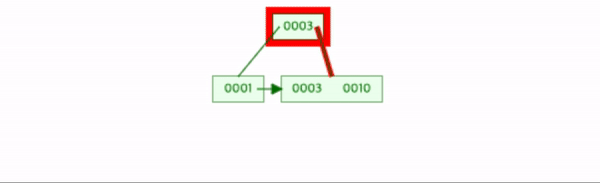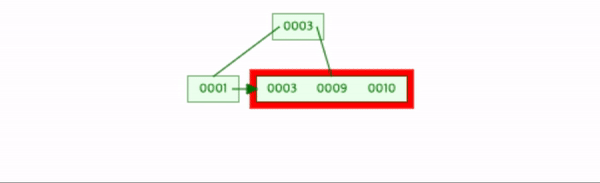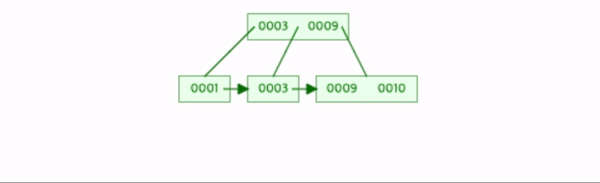
데이터의 수가 차수와 같고, leaf node에서 분할이 생기므로 2-a번 작업을 한다.
8을 삽입한다.
데이터의 수가 차수미만이므로 추가작업을 하지 않는다.
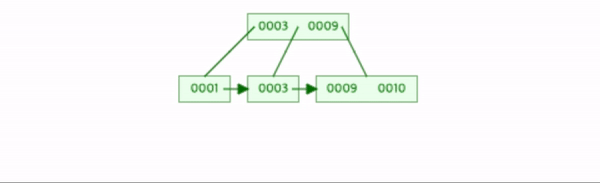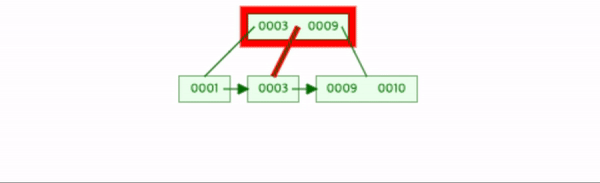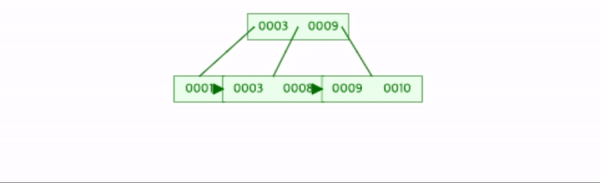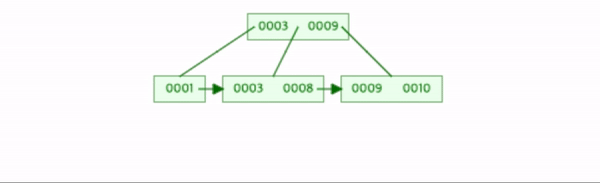
4를 삽입한다.
.gif)
leaf node와 leaf node가 아닌 곳에서 각각 분할이 발생했다.
2-a작업과 2-b작업이 실행된다.
이때 두 작업의 차이는 leaf node에서는 중간값을 복사하여 상위노드로 삽입했고,
leaf node가 아닌 곳에서는 중간값을 제외하고 상위노드로 삽입했다.
나머지 2, 6, 7을 삽입하자.
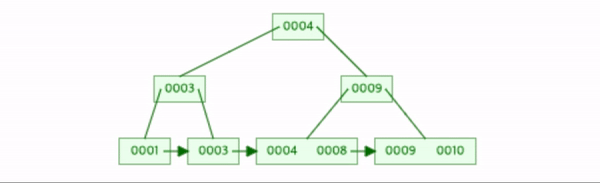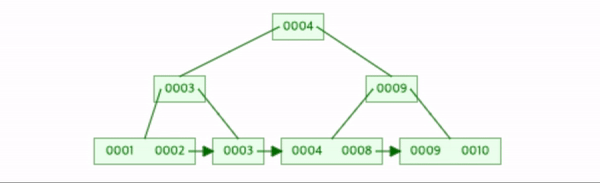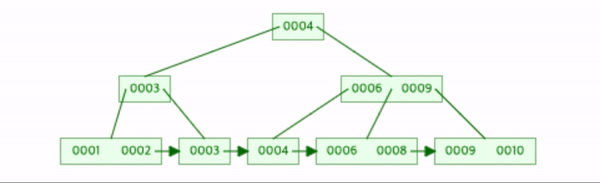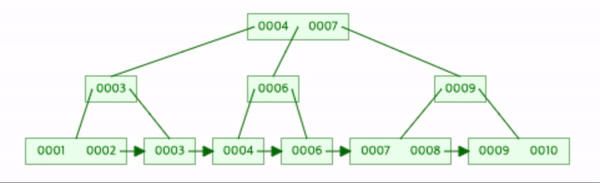
각 상황에 맞춰 1번 2번작업들이 발생했다.
이렇게 인덱스에 데이터 1개를 추가하는 작업의 경우, 단순히 디스크에 데이터 1개를 추가하는 작업에 비해 1.5배정도 시간이 걸린다고 한다.
Delete
데이터를 삭제하는 로직은 다음과 같다.
1. 삭제할 데이터를 찾아 삭제한다.
2. 삭제 후 테이터가 0개인 경우 트리를 재조정한다. 그러나 데이터베이스의 인덱스는 B Tree자료구조로 이루어졌지만, 트리의 재조정작업을 하지 않는다.
대신 삭제할 데이터를 찾아 마킹을 한다.
이러한 방식을 사용하는 이유는 다음과 같다.
- 삭제 후 트리의 재조정작업으로 인한 overhead를 줄일 수 있다.
- 삭제된 데이터가 다시 삽입될 경우 기존에 마킹된 데이터를 재활용할 수 있다.
Update
수정작업은 삭제 후 삽입작업으로 이루어진다.
인덱스는 항상 정렬된 상태를 유지해야 한다.
따라서 인덱스의 수정이 필요하다고 단순히 값을 수정하게 되면 정렬이 깨진다.
Select
인덱스를 사용하는 목적이다.
.gif)
6이라는 데이터를 3번만에 찾을 수 있다.
또한 인덱스는 정렬되어 있기 때문에, 6이상의 데이터와 같이 범위형 조회에도 유용하다.
이와같이 인덱스는 데이터를 1개 쓰기(insert, update, delete)위해 많은 작업을 해야한다.
따라서 무분별하게 인덱스를 사용하게되면 오히려 성능저하를 발생시킨다.
인덱스의 종류
인덱스는 leaf node가 무엇인지에 따라 두 종류로 나누어볼 수 있다.
클러스터링 인덱스 (Primary key, Unique not null key)
leaf node가 실제 디스크의 레코드인 경우를 클러스터링 인덱스라고 한다.
mysql InnoDB 클러스터링 인덱스에는 다음과 같은 특징이 있다.
-
인덱스는 항상 정렬되어있기 때문에 실제 디스크에도 데이터가 정렬되어있다.
: 중간에 클러스터링 인덱스를 변경하면 디스크를 다시 써야한다. -
클러스터링 인덱스는 테이블당 1개만 가질 수 있다.
: 실제 leaf node가 디스크의 데이터이기 때문에 클러스터링 인덱스가 2개 이상이라면, 같은 데이터를 디스크에 중복으로 저장해야하기 때문이다. -
Primary key로 지정된 칼럼은 클러스터링 인덱스가 된다.
-
Unique not null이 설정된 칼럼은 클러스터링 인덱스가 된다.
-
Primary key와 Unique not null이 동시에 존재하면 Primary key가 클러스터링 인덱스가 된다.
-
Primary key, Unique not null을 다 지정하지 않은 경우 InnoDB가 임의로 칼럼을 생성하여
클러스터링 인덱스로 사용한다.
: 따라서 Primary key는 사용자가 직접 지정하는 것이 무조건 좋다.
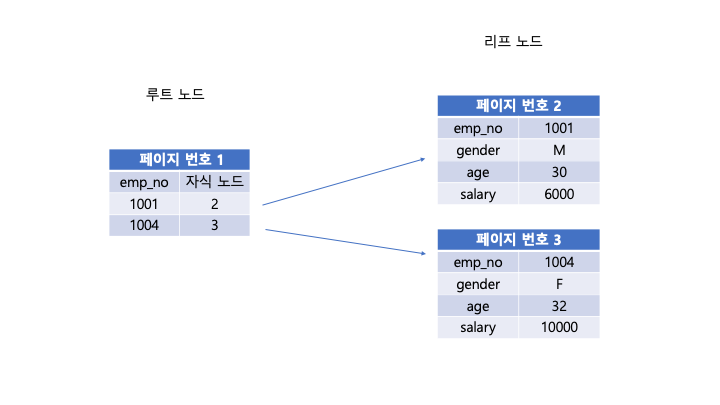
emp_no를 Primary key로 지정한 클러스터링 인덱스의 예이다.
세컨더리 인덱스 (Unique key, 사용자 정의 인덱스)
leaf node가 Primary key(클러스터링 인덱스)값을 가지는 경우 이를 세컨더리 인덱스라고 한다.
일반적으로 사용자가 지정하는 인덱스가 이에 해당된다. Unique칼럼에 대해서도 세컨더리 인덱스가 생성된다.
데이터의 조회는 leaf node까지 내려가서 Primary key를 알아내고, 이를 클러스터링 인덱스를 통하여
찾는 과정으로 이루어진다.
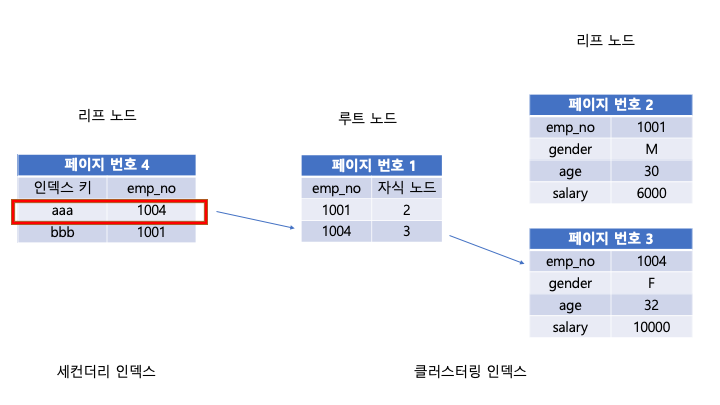
인덱스 설정시 주의사항
키 값의 크기
InnoDB엔진이 디스크에 데이터를 저장하거나 읽어올 때, 레코드 1개씩 가져오지 않는다.
page라는 기본 단위를 사용하며, 보통 16KB(4KB ~ 64KB)정도 된다.
16KB에는 16byte짜리 데이터가 1024개 들어갈 수 있다.
즉, 한번에 16byte데이터 1024개씩 읽어온다는 의미다.
이때, 인덱스의 키 값을 크게하여 데이터의 크기를 32Byte로 만들었다고 생각해보자.
한 page를 읽어올때, 데이터가 512개로 줄어들 것을 생각할 수 있다.
한 page에 존재하는 데이터 수가 적어진다는 의미는 내가 원하는 데이터를 찾기위해
더 많은 page를 읽어야 한다는 뜻이고, 이는 시간이 더 걸린다는 뜻이다.
따라서 불필요하게 인덱스의 칼럼을 많이 설정하는 것은 반드시 피해야 한다.
Cardinality
Cardinality란 중복되지 않은 것이 얼마나 있나를 나타내는 양이다.
성별을 예로들면 남, 여로 Cardinality가 2이다.
주민번호를 예로들면 Cardinality는 5천만이다.
인덱스를 설정할 때, Cardinality를 높은 순으로 설정해야 한다.
대한민국 사람들 중에 남자이며, 주민번호가 123456-1234567인 사람을 찾는경우를 생각해보자.
이때 2가지 인덱스를 사용하는 경우를 비교해보자.
- INDEX ix_gender(성별)
우리가 찾고자 하는 사람은 남자다. 이 인덱스를 사용하여 우리는 찾고자하는 범위를 2500만으로 줄였다.
이제는 2500만명을 다 뒤져서 찾으면 된다.
- INDEX ix_gender(주민번호)
우리가 찾고자 하는 사람은 주민번호가 123456-1234567다. 주민번호는 중복되지 않으므로 인덱스를 이용하여 정확이 1명을 찾아낼 수 있다.
물론 항상 정확히 1명만 찾아내는 인덱스를 만들수는 없다.
그렇지만 Cardinality가 최대한 높아야 마지막에 찾는 범위를 줄일 수 있다.
인덱스 사용시 주의사항
인덱스를 만들었다고 항상 인덱스를 사용하지는 않는다.
인덱스의 정렬된 특성을 이용해야 한다.
그렇지 않으면 데이터를 다 읽어봐야 하고 이는 인덱스를 사용하는 것이 아니다.
왼쪽 값을 기준으로
인덱스는 항상 왼쪽값을 기준으로 정렬되어 있다.
위 그림을 보면 맨 왼쪽값부터 비교하여 정렬되어있는 것을 볼 수 있다.
이때 만약 끝에 문자가 c로 끝나는 것을 찾아줘라는 쿼리는 데이터를
다 읽어봐야 알 수 있고, 이는 인덱스의 정렬된 특성을 전혀 이용하지 못하는 것이다.
왼쪽 칼럼을 기준으로
만약 인덱스에 여러개의 칼럼을 설정했다고 해보자.
이 경우에도 왼쪽컬럼부터 비교하여 정렬한다.
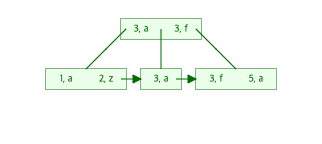
위 그림을 보면 2, z가 3, a앞에 위치하는 것을 볼 수있다.
이때 만약 문자가 a인 컬럼을 찾아줘라는 쿼리는
마찬가지로 인덱스의 정렬된 특성을 이용하지 못하는 쿼리다.
범위 비교는 제일 마지막으로
대한민국 사람을 키와 몸무게로 분류한 인덱스가 있다고 생각해보자.
키는 0cm ~ 300cm 구간으로 10cm씩 나눠서 Cardinality가 30이고,
몸무게는 0kg ~ 150kg으로 5kg씩 나눠서 Cardinality가 30이라고 하자.
아래에 두 경우를 보자.
- case 1
INDEX index_HW(키, 몸무게)
query : 키가 150cm이상이고 몸무게가 80kg인 사람을 찾아줘 - case 2
INDEX index_WH(몸무게, 키)
query : 몸무게가 80kg이고 키가 150cm이상인 사람을 찾아줘
두 경우는 모두 같은 데이터를 조회한다. 하지만 과정은 다르다.
case 1은 인덱스가 키, 몸무게 순으로 되어있다. 키가 150cm이고 몸무게가 80kg인 사람뒤에는
키는 150cm보다 크지만 몸무게가 더 가벼운 사람이 있을 수도 있고, 더 무거운 사람이 있을 수도 있다.
따라서 뒤에 데이터를 다 읽어보고 몸무게가 80kg인 사람만 골라야 한다.
case 2는 인덱스가 몸무게, 키 순으로 되어있다. 몸무게가 80kg이며 키가 150cm사람뒤에는
몸무게가 80kg이고 키가 더 큰 사람만 있다는 것이 보장된다. 따라서 몸무게가 85kg인 사람이 나오기 전까지 데이터를 다 읽기만 하면 된다.
이와같이 범위비교를 필요로하는 칼럼은 인덱스의 뒤쪽으로 보내야 더 효율적으로 사용할 수 있다.
참고자료
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=284710853
https://dichchankinh.com/~galles/visualization/BPlusTree.html
