퍼셉트론(Perceptron)
1. 퍼셉트론의 개념
인지한 정보를 활용해 뉴런처럼 작동하는 인공 세포모델
인공 신경망(Aritificial Neural Network, ANN)의 구성 요소(unit)로서 다수의 값을 입력받아 하나의 값으로 출력하는 알고리즘입니다.
이진분류 모델을 학습하기 위한 지도학습기반의 알고리즘 입니다.
2. 퍼셉트론의 종류
입력층(Input Layer)과 출력층(Output Layer) 사이에 은닉층(Hidden Layer)의 존재 여부에 따라
"단층(Single-Layer) 퍼셉트론"과
"다층(Multi-Layer) 퍼셉트론"으로 나뉩니다
2-1. 단층 퍼셉트론
은닉층 없이 입력층과 출력층만 있는 경우를 단층 퍼셉트론이라 부릅니다.
단층 퍼셉트론은 디지털 논리 회로 개념에서 AND, NAND, OR 게이트를 구현할 수 있지만, XOR 게이트는 구현하지 못한다는 한계가 있습니다.
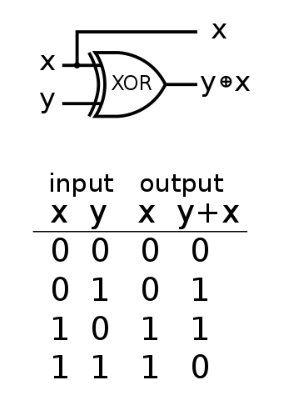
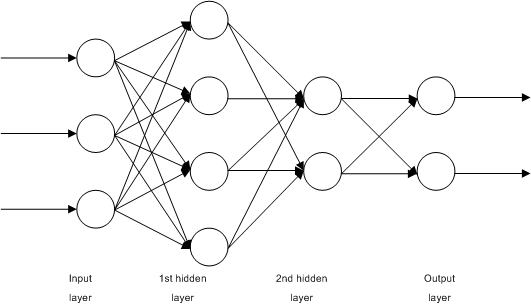
2-2. 다층 퍼셉트론
입력층과 출력층 사이에 1개 이상의 은닉층이 있는 경우를 다층 퍼셉트론(Multi-Layer Perceptron, MLP)이라 부릅니다. 다층 퍼셉트론은 단일 퍼셉트론이 XOR 게이트를 구현하지 못한다는 한계를 보완하기 위해 등장하였습니다. 다층 퍼셉트론은 AND, NAND, OR 게이트를 조합하여 XOR 게이트를 구현합니다. XOR 게이트는 은닉층 1개를 추가하여 구현할 수 있지만, 다층 퍼셉트론은 더욱 복잡한 문제를 해결하기 위해 일반적으로 2개 이상의 은닉층을 추가합니다. 이처럼 2개 이상의 은닉층을 가진 다층 퍼셉트론을 심층신경망(Deep Neural Network, DNN)이라 부릅니다.
우리가 흔히 아는 딥러닝은 이러한 심층신경망을 학습하는 것을 의미하죠.
텐서
텐서(Tensor)는 데이터를 다차원 배열로 일반화한 것입니다. 텐서를 사용하여 스칼라, 벡터, 행렬 등 다양한 차원의 데이터를 표현할 수 있습니다. 기계 학습에서 텐서는 주로 입력 데이터, 모델의 가중치, 출력 데이터 등을 표현하는 데 사용됩니다.
텐서의 "랭크(rank)"는 그 차원의 수를 의미합니다 :
랭크 0: 스칼라(Scalar), 하나의 숫자로 이루어진 텐서 (차원이 없음)
랭크 1: 벡터(Vector), 숫자의 배열로 이루어진 텐서 (1차원)
랭크 2: 행렬(Matrix), 숫자의 2차원 배열 (2차원)
랭크 3 이상: 3차원 이상의 배열로 이루어진 텐서 (다차원)
텐서플로우
텐서플로우(TensorFlow)와 같은 기계 학습 라이브러리에서는 텐서라는 용어를 사용하여 이러한 다차원 배열의 데이터를 조작하고 계산하는 데 필요한 다양한 연산을 제공합니다. 예를 들어, 이미지 처리에서는 종종 랭크-4 텐서를 사용합니다. 이는 (배치 크기, 높이, 너비, 채널)의 4차원 배열로, 여러 이미지 데이터를 배치로 묶어서 한 번에 처리할 수 있도록 합니다.
텐서 참고 API
https://www.tensorflow.org/api_docs/python/tf/constant
활성화 함수(Activation function)
- 인공 신경망에서 각 뉴런의 출력을 결정하는 비선형 함수
- 활성화 함수는 입력 신호의 가중치 합과 편향을 적용한 후, 그 결과에 적용되어 다음 층으로 전달
- 인공 신경망에서 비선형성을 도입하고, 신경망의 복잡한 함수 근사(approximation) 능력을 향상시키는 것
- 인공 신경망은 여러 층의 연속된 선형 변환과 비선형 활성화 함수를 조합하여 복잡한 입력과 출력 관계를 학습
- 주요 활성화 함수
- 시그모이드(Sigmoid) 함수:
- 범위: 0과 1 사이
- 주요 특징: 입력값을 확률로 해석할 수 있으며, 비선형 함수로서 미분 가능
- 단점: 큰 입력값에 대해 그래디언트 소실 문제가 발생할 수 있음
- 하이퍼볼릭 탄젠트(Tanh) 함수:
- 범위: -1과 1 사이
- 주요 특징: 시그모이드와 유사하게 비선형 함수이며, 원점을 중심으로 대칭
- 단점: 여전히 큰 입력값에 대해 그래디언트 소실 문제가 발생할 수 있음
- 렐루(ReLU, Rectified Linear Unit) 함수:
- 범위: 0 이상의 입력에 대해 그대로 출력, 음수 입력에 대해 0 출력
- 주요 특징: 계산이 간단하고 빠르며, 선형 영역으로 쉽게 학습 가능
- 단점: 음수 입력에 대해 출력이 0이 되어 해당 뉴런이 활성화되지 않는 문제가 있음 (죽은 렐루 문제)
- 소프트맥스(Softmax) 함수:
- 범위: 0과 1 사이
- 주요 특징: 다중 클래스 분류에 사용되며, 출력값을 확률 분포로 해석
- 단점: 출력값의 합이 1이 되도록 정규화되어, 다른 출력값에 영향을 받을 수 있음
- 시그모이드(Sigmoid) 함수:
옵티마이저
- 모델의 학습 과정을 통제하고, 모델의 성능을 개선하는 역할
- 손실 함수 (또는 비용 함수)를 최소화하는 파라미터를 찾는 과정이며, 이 과정은 최적화 (Optimization)라고 함
- 옵티마이저
- 확률적 경사 하강법 (SGD): 가장 기본적인 옵티마이저로, 각 훈련 단계에서 하나의 데이터 포인트 (또는 작은 배치)에 대한 그래디언트를 계산하여 모델 파라미터를 업데이트
- 모멘텀: 경사 하강법에 '관성' 개념을 추가하여, 최적화 과정이 수렴을 가속화하고 지역 최솟값에서 벗어나는 데 도움
- AdaGrad: 학습률이 각 파라미터에 따라 다르게 적용되는 적응형 학습률을 사용합니다. 이는 자주 등장하지 않는 피처에 높은 학습률을 할당하는 데 도움
- RMSProp: AdaGrad의 문제점인 학습률이 너무 빨리 감소하는 문제를 해결한 방법
- Adam (Adaptive Moment Estimation): 모멘텀과 RMSProp의 아이디어를 결합한 옵티마이저로, 적응형 학습률과 관성 개념을 모두 사용
가중치 vs 그래디언트
가중치는 신경망의 출력을 결정하는 파라미터이며, 그래디언트는 이러한 가중치를 어떻게 조정할지를 결정하는 방향성을 제공하는 지표
- 가중치는 각 입력 특성이 출력에 미치는 영향의 정도를 나타냅니다. 가중치는 학습 과정에서 최적화되며, 초기에는 일반적으로 임의의 값으로 설정되고, 학습 데이터를 통해 그래디언트를 계산하고 가중치를 업데이트함으로써 점진적으로 개선
- 그래디언트(Gradient): 그래디언트는 가중치가 변할 때 손실 함수가 어떻게 변하는지를 나타내는 지표. 그래디언트는 손실 함수의 편미분으로 계산되며, 이는 각 가중치에 대한 손실의 변화율을 나타낸다. 그래디언트는 가중치를 어떻게 업데이트할지를 결정하는데 사용되며, 손실을 줄이는 방향으로 가중치를 조정하는데 도움이 되며 그래디언트가 0인 경우, 해당 가중치는 손실에 미치는 영향이 없거나, 손실을 최소화하는 최적의 값에 도달했음을 의미
손실 함수 (Loss Function)
- 머신러닝 모델의 예측 출력이 실제 값과 얼마나 잘 일치하는지를 측정하는 방법
- 실 함수는 모델의 성능을 수치화하며, 이를 통해 모델의 파라미터를 최적화하는 데 사용
- 유형
- 평균 제곱 오차 (Mean Squared Error, MSE): 회귀 문제에서 가장 일반적으로 사용되는 손실 함수. 실제 값과 모델의 예측 값 사이의 차이를 제곱한 값의 평균을 계산
- 크로스 엔트로피 (Cross-Entropy): 분류 문제에서 일반적으로 사용되는 손실 함수. 모델의 예측 확률 분포와 실제 값의 분포 사이의 차이를 측정
- sparse_categorical_crossentropy는 크로스 엔트로피 손실 함수의 한 형태로, 다중 클래스 분류 문제에서 주로 사용
- 힌지 손실 (Hinge Loss): 서포트 벡터 머신 (SVM)과 같은 알고리즘에서 사용
- 로그 손실 (Log Loss): 이진 분류 문제에서 사용되며, 예측 확률을 직접적으로 반영
