db 설계 기획에서 배운 내용에 대한 정리 글입니다. 아직 초보 개발자라 정답이라기보다, 이런 방식으로 했구나 정도로만 읽어주시면 감사하겠습니다.
안녕하세요. Inhu 프로젝트의 백엔드 개발자 이수인이라고 합니다. 오늘은 RDB 설계를 하면서 여러 가지 고민했던 부분들을 얘기해보려고 합니다.
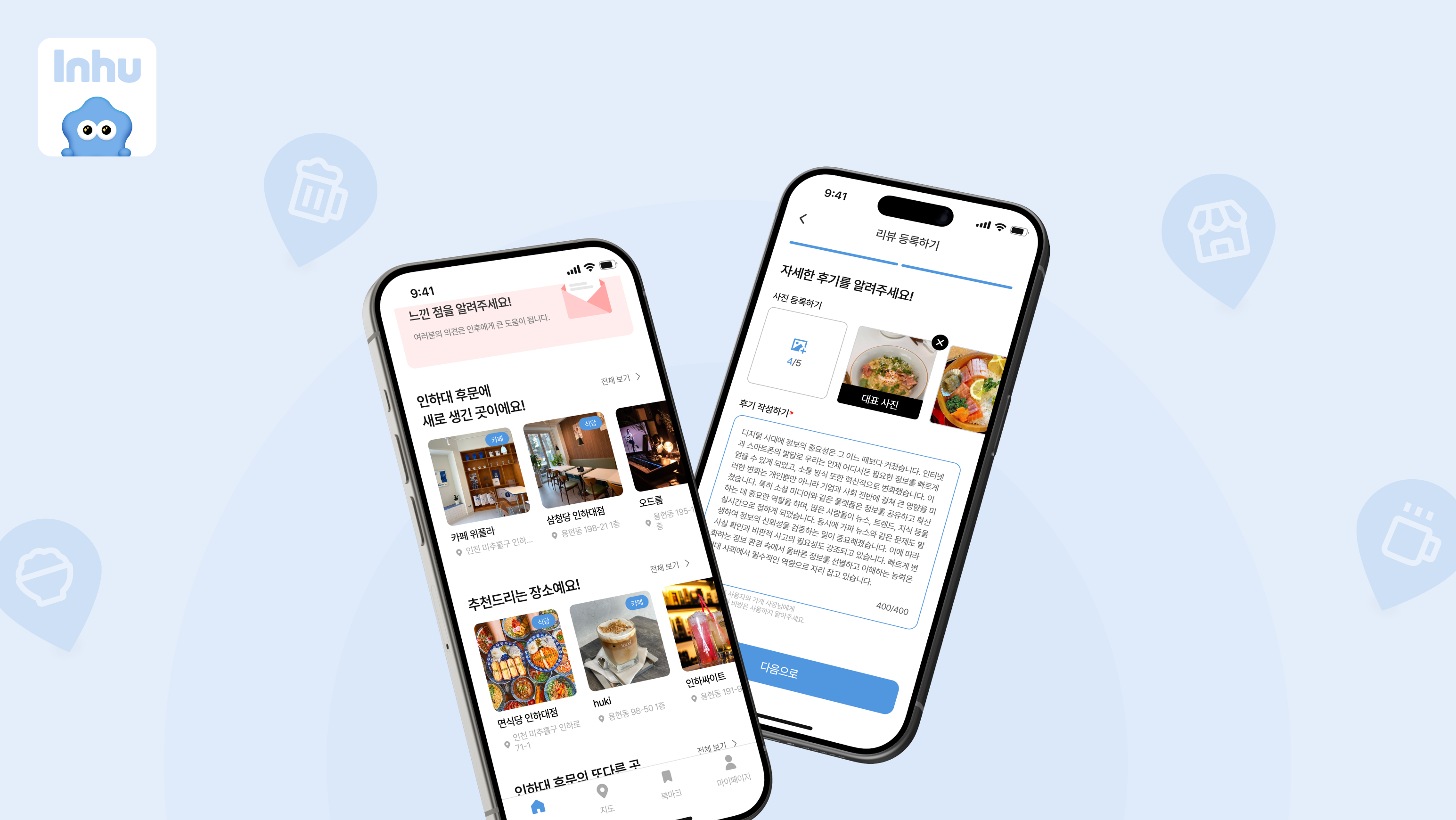
얘기하기 전에 이번에 하는 프로젝트에 대한 첫 글이라 가볍게 프로젝트 소개부터 해보겠습니다.
서론

프로젝트 소개
Inhu는 인하대학교 후문에 카페, 술집, 식당들을 소개해주는 어플입니다. 각 장소마다 후기를 볼 수 있기도 하고 자기가 발견한 새로운 카페나 술집, 식당이 있다면 제보도 할 수 있습니다.
테이블 소개
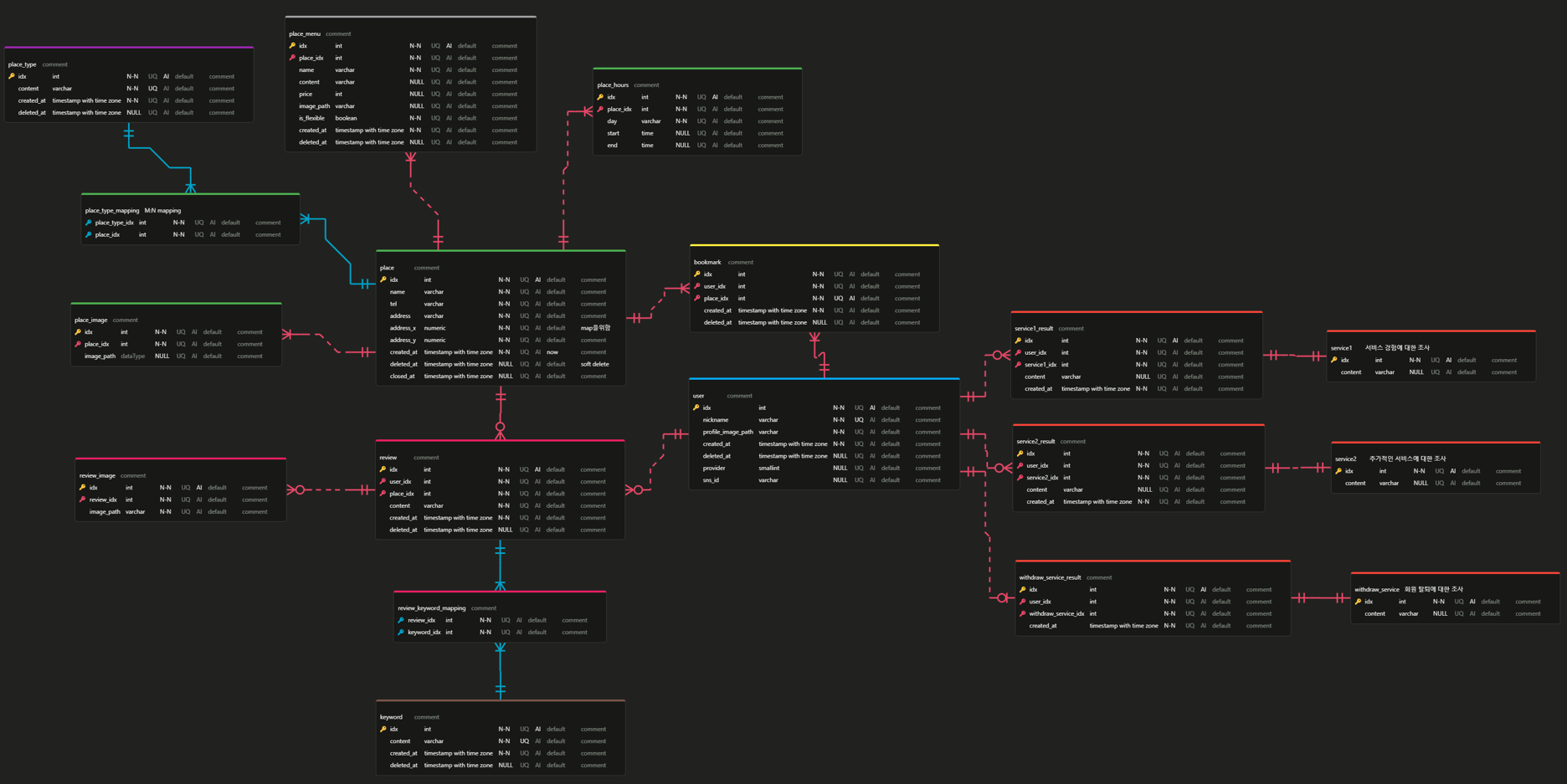
주요 테이블
- place: 장소 정보를 저장하는 테이블
- user: 사용자 정보를 관리하는 테이블
- review: 사용자가 남긴 리뷰를 저장하는 테이블
- place_type: 장소의 유형을 저장하는 테이블 (ex 식당, 카페, 술집 ...)
- place_type_mapping: 장소와 타입 간의 관계를 관리하는 매핑 테이블
- bookmark: 사용자가 설정한 북마크를 저장하는 테이블
테이블이 생각보다 많아서 사진에 담기 어렵더라고요. 그래서 주요 테이블 몇 개를 적어보았습니다. 이후 자세히 얘기할 것들은 확대해서 붙일 겁니다. 그럼 저희의 고민의 흔적들을 살펴보시죠.
본론
1. hard delete vs soft delete 어떤 것이 더 좋을까?
저는 soft delete는 사용자 정보처럼 혹시 모르는 것들이나, 댓글처럼 나중에 문제됐을 때 확인하기 위한 정보들만 soft delete 방식을 채택하는 줄 알았습니다. 그런데 생각보다 soft delete를 생각해봐야 할 상황들이 많더라고요?
history로써 가치가 있나?
먼저 고민을 했던 부분입니다. 테이블의 정보가 나중에 유의미한 데이터로 남을 수 있는가를 계속 고민했었습니다.
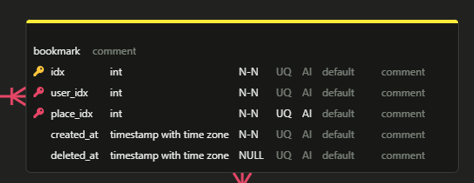
예를 들어 bookmark 테이블이 그렇습니다. 처음에 bookmark를 저장하고 삭제한 데이터는 특별한 가치가 없다고 생각했습니다. 그래서 hard delete를 하려고 했죠. 하지만, '나중에 사용자가 저장하고 삭제한 bookmark로 선호도의 흐름을 파악하고 싶으면 어떻게 할 것인가?' 라는 관점으로 바라봤을 때는 달랐습니다. 이때는 bookmark의 데이터가 history로써 가치가 있기 때문에 soft delete 방식을 사용했습니다.
hard delete를 해서 얻는 이점이 뭔데?
사실 bookmark가 history로써 가치가 있기 때문에 soft delete를 사용하기로 결정이 났는데도 마음 한구석에서는 찝찝한 게 있었습니다. '사용자가 실수로 저장하거나 삭제할 수도 있고, 정말 관심없어서 삭제한 건데 굳이 데이터로 남겨야 되나?' 이런 제 의문에 얻은 답변이 'hard delete를 해서 얻는 이점이 무엇인가?' 였습니다.
어차피 timestamp wit time zone 으로 저장하면 8byte이고 1억개 정도 모여야 1GB인데, 굳이 이거를 포기하면서까지 hard delete를 사용하는 이유가 무엇인가? 나중에 정말 유의미한 데이터로 남을 수 있고 끽해야 8byte인데 왜 hard delete를 쓰는가? 를 고민할 필요가 있었습니다.
그럼 혹시 매핑 테이블도 soft delete?
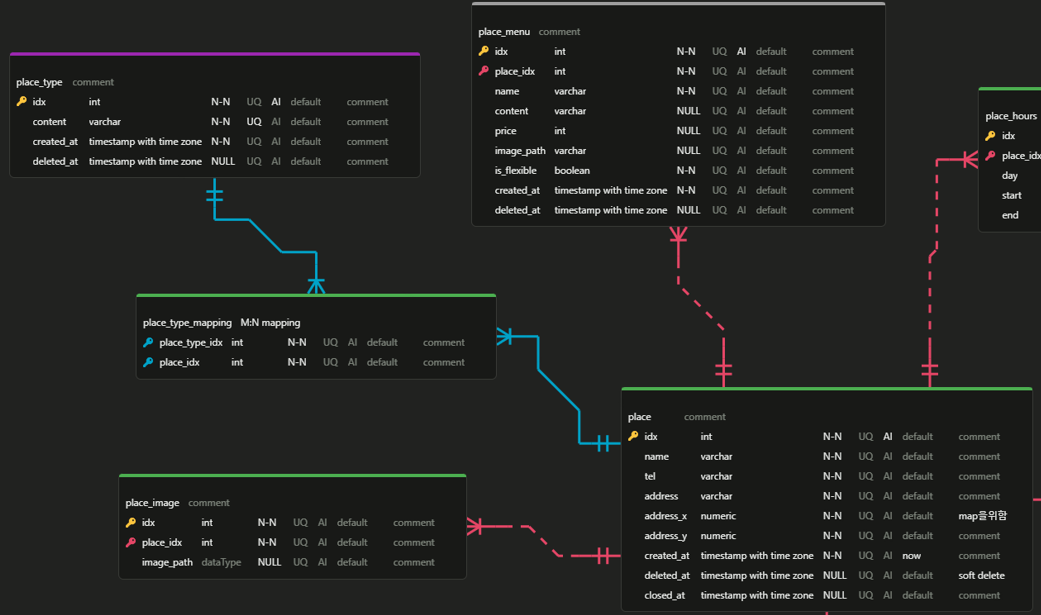
왼쪽에 보이는 place_type_mapping 테이블에서는 soft delete가 아닌 hard delete를 사용한 것을 볼 수 있습니다. 앞에서 얘기했던 두 가지 논리대로면 soft delete를 사용하는 게 맞는데 저희는 hard delete를 사용했습니다. 왜냐하면 이 테이블의 역할은 단순히 매핑만 하는 것입니다. 그 외에 어떤 역할도 없기 때문에 hard delete를 사용했습니다. 특별한 역할이 있었더라면 soft delete를 사용했을 것입니다. 대신에 place_type_mapping 테이블이 매핑하는 place_type 테이블과 과 place 테이블은 soft delete를 사용했습니다.
2. varchar vs varchar(10)
user 테이블의 nickname 컬럼으로 예를 들어보겠습니다. 저희는 닉네임 최대 글자를 10글자로 제한하기로 했습니다. 그런데 varchar(10) 으로 안 하고 그냥 varchar 로 설계했습니다. 왜일까요?
유연성 good!
가장 큰 이유는 유연성때문입니다. 나중에 닉네임 최대 글자가 10글자가 아닌 12글자로 바뀌었다고 가정해보겠습니다. 이때 varchar(10) 으로 설정했다면 db에서 제약이 걸리게 되고, db 수정을 다 해줘야 됩니다. 벌써 피곤하고 곤란하기도 하고 여러 문제가 생길 수 있겠죠. 하지만 그냥 varchar 로 했다면? db에서 제약이 안 걸리기 때문에 쉽게 변경이 가능합니다.
이런 이유때문에 그냥 varchar 로 설계했습니다. 대신에 코드적으로 제한을 걸면 유연하게 대처가 가능하겠죠?
3. table 네이밍
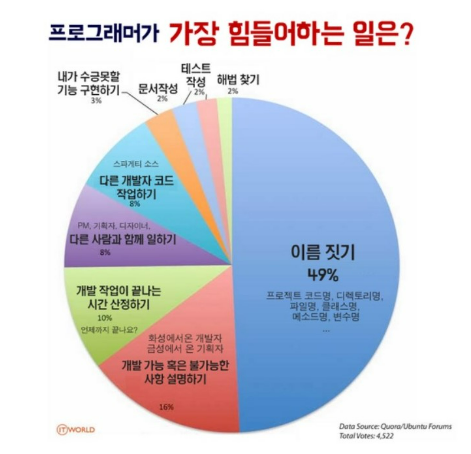
개발에서 무언가의 이름을 짓는다는 것은 참 어려운 것 같습니다. 어떤 역할이고 무슨 의미인지는 알지만 박수치는 이름을 짓기란 참 어렵죠. 특히 관련 컨벤션이 있다면 그것도 고려해야 돼서 어려운 것 같습니다. 저희도 이름을 짓는 부분에서 고민을 많이 했습니다. 제일 마음에 안 들었던 부분은 mapping 테이블입니다.
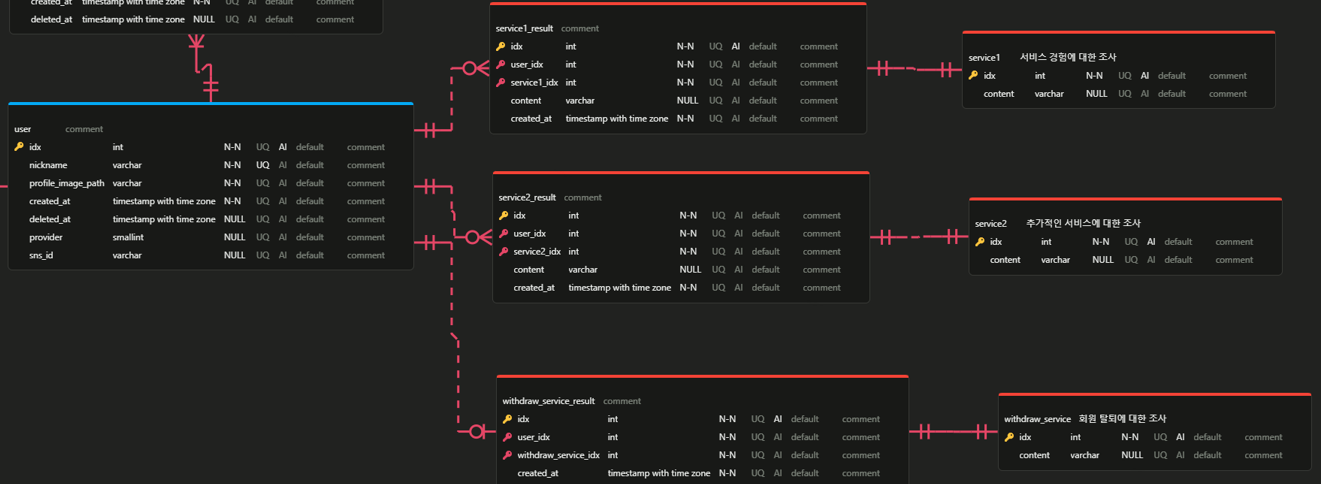
지금 사진에 보이는 테이블에 대한 설명이 없어서 가볍게 설명하겠습니다.

위 사진처럼 사용자한테 서비스 만족 조사를 받습니다. '매우 만족했어요', '만족스러웠어요' 와 같은 서비스 항목들이 service1 테이블에 들어갑니다. 다음으로 어떤 사용자가 어떤 서비스 항목을 선택했는가는 service1_result 테이블에 들어갑니다. 즉 service1_result 는 mapping 테이블입니다. 이전에 erd 사진에 보이는 다른 테이블도 같은 맥락입니다.
저희가 처음에 mapping 테이블의 이름을 정할 때 table1_table2_mapping 과 같은 방식으로 정했습니다. 그래서 처음에 정한 이름은 user_service1_mapping 이었죠. 그런데 이름만 길고 그렇게 확 와닿지도 않더라고요.
의미적으로 해결
mapping 이라는 단어가 괜히 헷갈리기만 한 것 같아서 의미적으로 해결할 수 있으면 굳이 mapping 이라는 단어를 안 쓰기로 했습니다. 그래서 나온 결과가 service1_result 입니다. service1 과 user 테이블을 mapping 해주는 것은 맞지만 결국에는 service1 에 대한 결과를 담은 테이블인 거잖아요? 그래서 service1_result 처럼 의미가 와닿게 작성해봤습니다.
예외
의미적으로 해결할 수 있으면 그렇게 했겠지만 그게 잘 적용되지 않았던 것도 있었습니다.
위에서 보여줬던 place_type_mapping 은 의미적으로 해결되지 않았기 때문에 mapping 이라는 단어를 썼습니다. 게다가 table1_table2_mapping 형식으로 작성해야 되는데 place_type 과 place 는 place 라는 단어가 겹칩니다. 그래서 mapping 하는 주체는 place_type 테이블이기 때문에 place_type_mapping 이라고 적어봤습니다.
결론
RDB 설계를 하면서 많은 부분을 고민해봤고 그 과정에서 많은 것들을 배우면서 완성했습니다. RDB 설계에서 가장 중요한 것은 확장성과 유연성을 고려하며 설계하는 것이라고 생각합니다. 이전 프로젝트 때 DB 설계 잘못 했다가 프로젝트 끝날 때까지 발목을 잡혔던 경험이 있어서 이번 설계에 집중할 수 있었고 많이 배울 수 있었던 것 같습니다. 긴 글 읽어주셔서 감사합니다!

