현재 내용은 페이징 기법을 기준으로 합니다.
1. 논리 메모리와 Demand Paging
1.1 페이징 기법의 장점
- 페이징 기법은 필요할 때 필요한 만큼의 페이지를 물리 메모리에 적재하는 방식이다. 이를 통한 장점으로는...
-> I/O 양의 감소
-> Memory 사용량 감소
-> 빠른 응답 시간
-> 더 많은 사용자 수용
1.2 Demand Paging
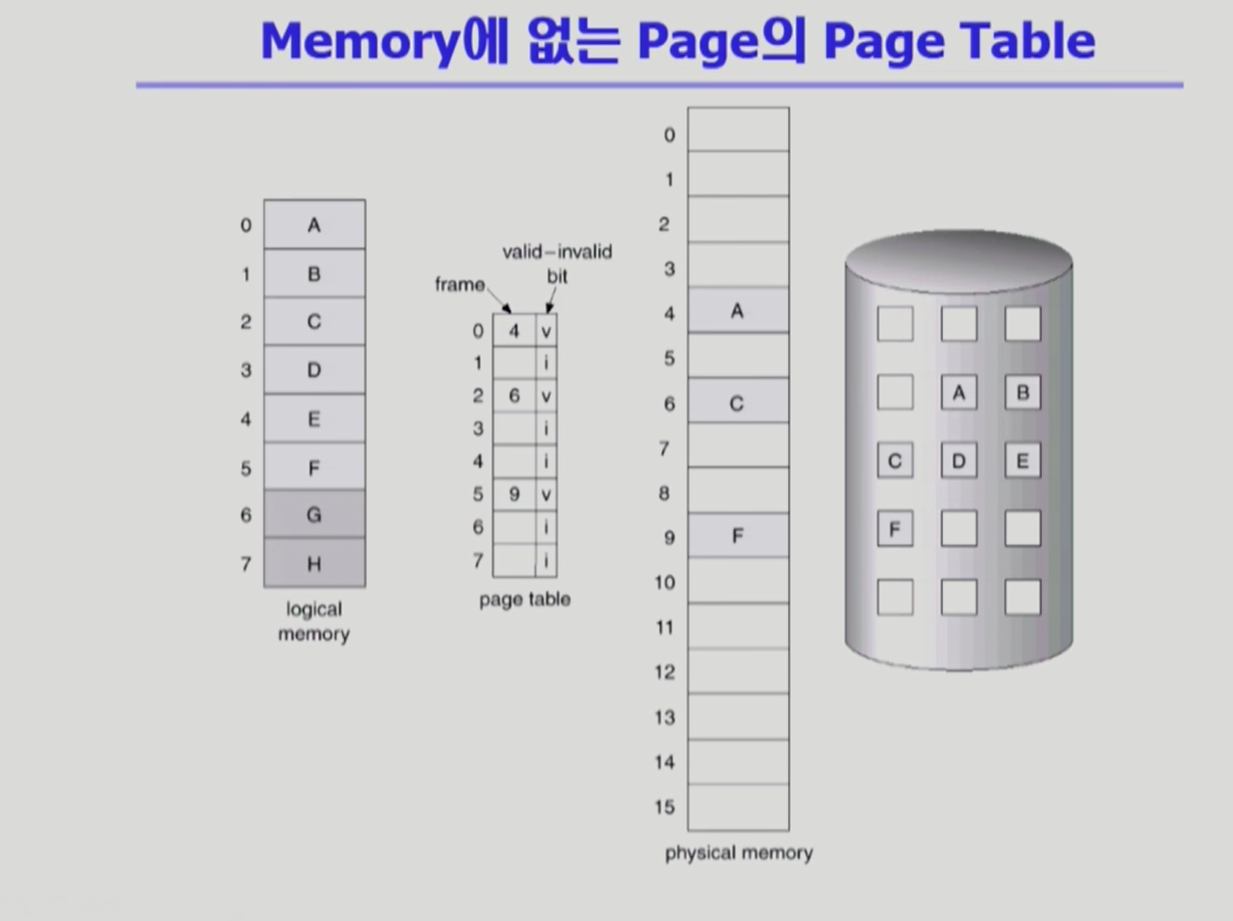
- 물리 메모리에 없는 페이지를 호출할 때 관리 기법을 필요로 한다.
- swap out된 페이지는 Backing store란 디스크의 별도의 공간에 있으며, 출력되지 않은 페이지는 디스크에 존재한다. 두 개의 페이지에 접근하기 위해서 프로세스는 trap을 하며 커널 모드로 변경된다.
- 페이지 테이블을 기준으로 본다면, cpu가 필요로 한 페이지에 접근할 때, 해당 페이지가 invalid일 경우에 해당한다. 이러한 상황을 page falut라고 한다.
2. 페이지 폴드 Page Fault
2.1 페이지 폴트의 과정
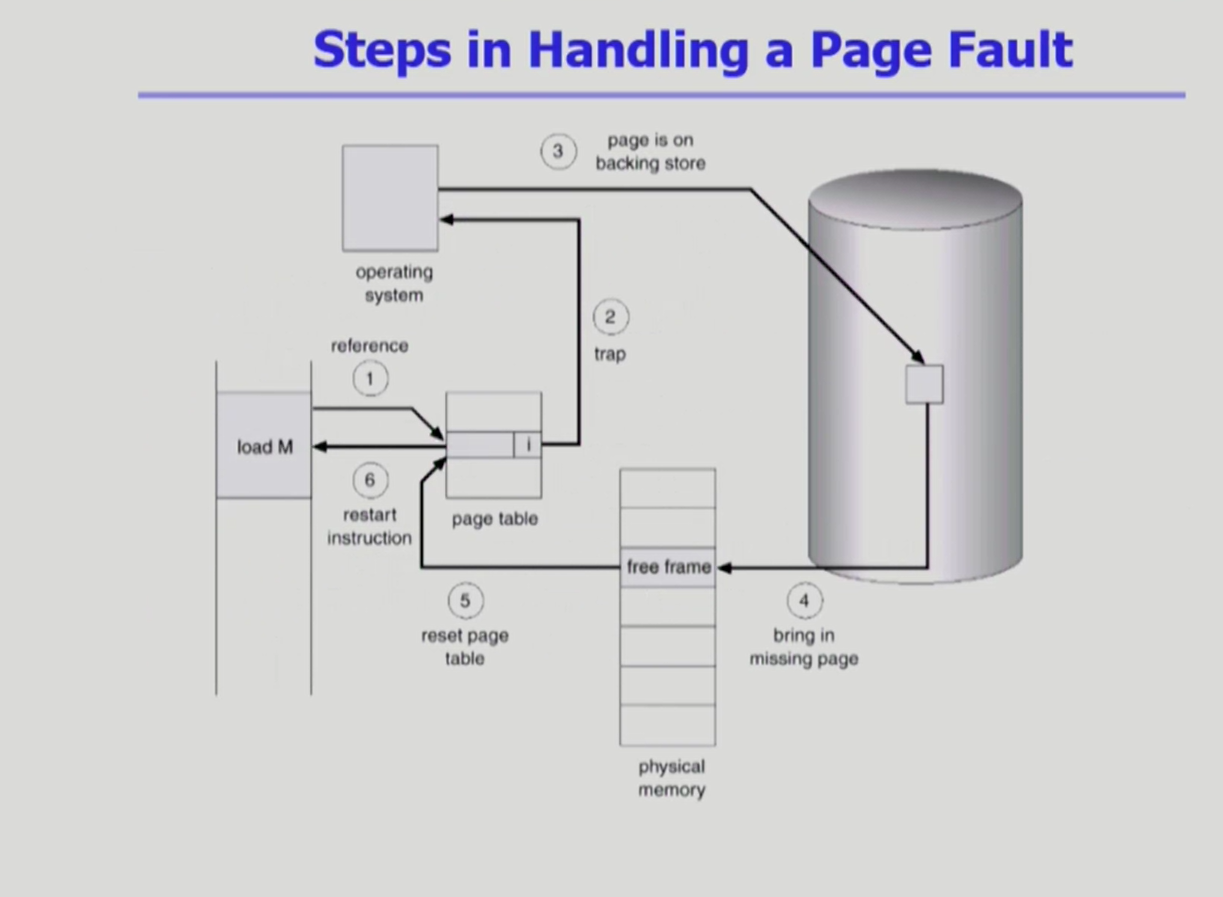
- invalid page를 접근하면 MMU가 trap을 발생
- 커널 모드에서 page fault handler가 invoke 됨.
-> invalid referece (잘못된 주소, 잘못된 접근) 의 경우 abort 됨.
-> 페이지 폴트 : 1) 가용 공간이 없는 경우, 하나의 페이지를 쫓아내고 해당 페이지를 replace 를 한다. 2) 가용 공간이 있는 경우, 가용 공간에 페이지를 넣는다.
-> disk I/O 작동. 프로세스는 선점되어 block됨.
-> disk read가 끝나면 page table의 entry가 갱신 되며 valid 됨.
-> 해당 프로세스는 ready queue에 대기
2.2 Page Fault rate
- 페이지 폴트가 발생하지 않을 수록 메모리 관리가 잘 되는 것임.
- 페이지 폴트가 항상 일어나면 1에 가깝고, 발생하지 않으면 0에 가까움. 대체로 메모리 관리는 0.0X에 수렴한다고 함.
- 만약 페이지 폴트가 발생하면 기본적인 페이징 접근에 더하여, 1) OS/HW의 작동, (replace의 경우) swap out, swap in 등의 오버헤드 발생.
- 만약 swap out 되는 페이지가 새롭게 갱신된 내용이 있으면, 해당 값을 I/O disk에 갱신하는 오버헤드도 발생.
3. 가용 공간이 없는 경우, Page replacement
- 메모리 가용공간이 있을 경우 해당 공간에 페이지를 적재하면 됨.
- 반대로 가용공간이 없을 경우, 어떤 페이지를 쫓아내야함(victim).
- page fault rate를 최소화 하는 알고리즘을 필요로 함.
3.1 Optimal Algorithm

- 가상 이상적인 형태.
- 가장 먼 미래에 참조되는 page를 replace.
- offline algorith으로 모든 입력 정보를 미리 알고 있는 경우. 다음 부터 설명하는 예시는 online algorith으로 입력 정보를 모르는 상태를 전제하는 알고리즘.
3.2 FIFO Algorithm First in first out
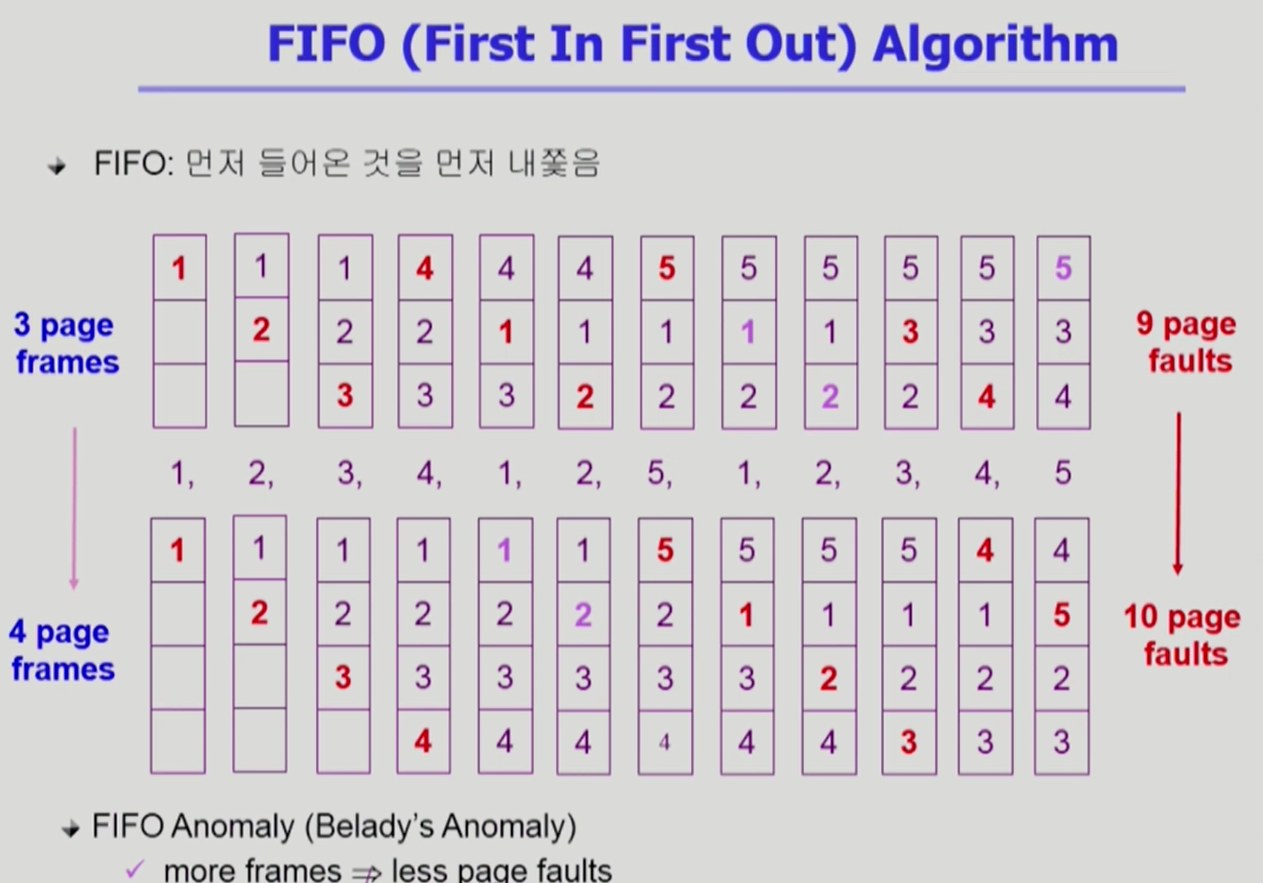
- 먼저 들어온 페이지를 가장 먼저 제거.
- 메모리 공간이 늘어나는데 페이지 폴트가 늘어나는 이상한 현상이 발생하기도 함.
3.3 LRU Algorithm Least Recently Used
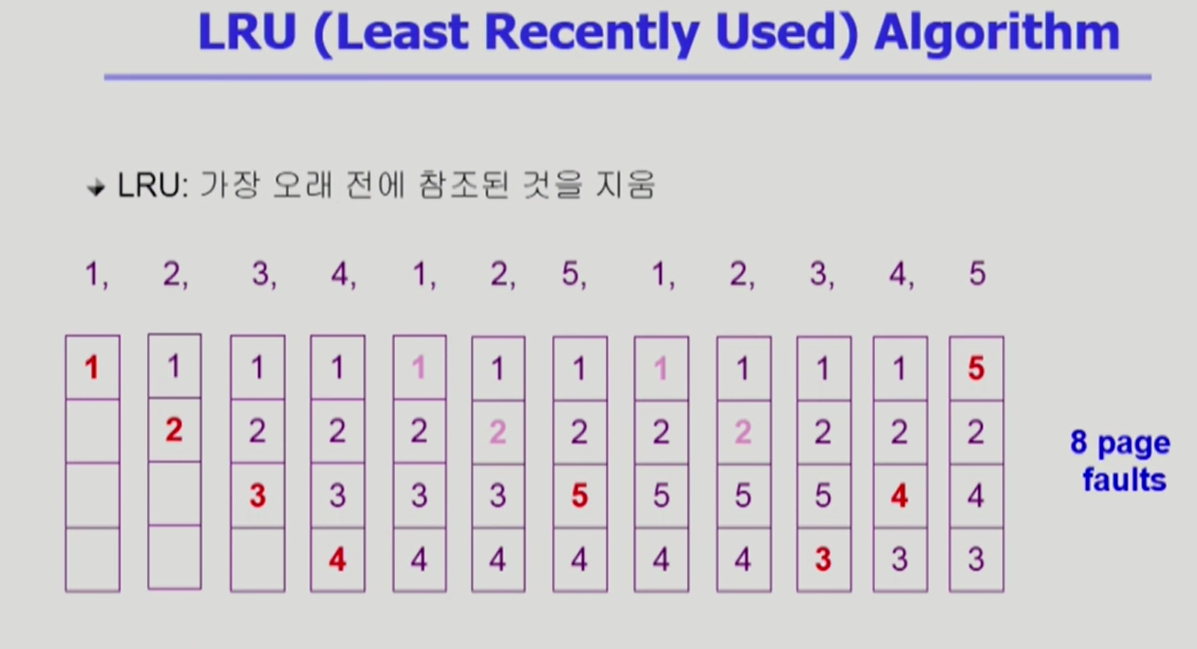
- 최근으로부터 가장 오래 전에 사용한 페이지를 제거.
3.4 LFL Algorithm Least Frequently Used

- 참조 횟수가 가장 적은 페이지를 제거.
- 최저 참조 횟수 페이지가 여러 개일 경우, 기본적으로 알고리즘이 임의대로 선정. 개중에 LRU 알고리즘을 따를 수 있음.
- 장기간의 인기를 참고할 수 있지만, 최근성을 반영하지 못함.
- LRU보다 구현이 어려움.
3.5 LRU와 LFL의 비교

- LRU와 LFU는 각각 페이지 1과 페이지 4를 삭제. 자주 사용한 것과 최근에 사용하는 것 중 무잇이 효과적일지는 상황마다 다름.
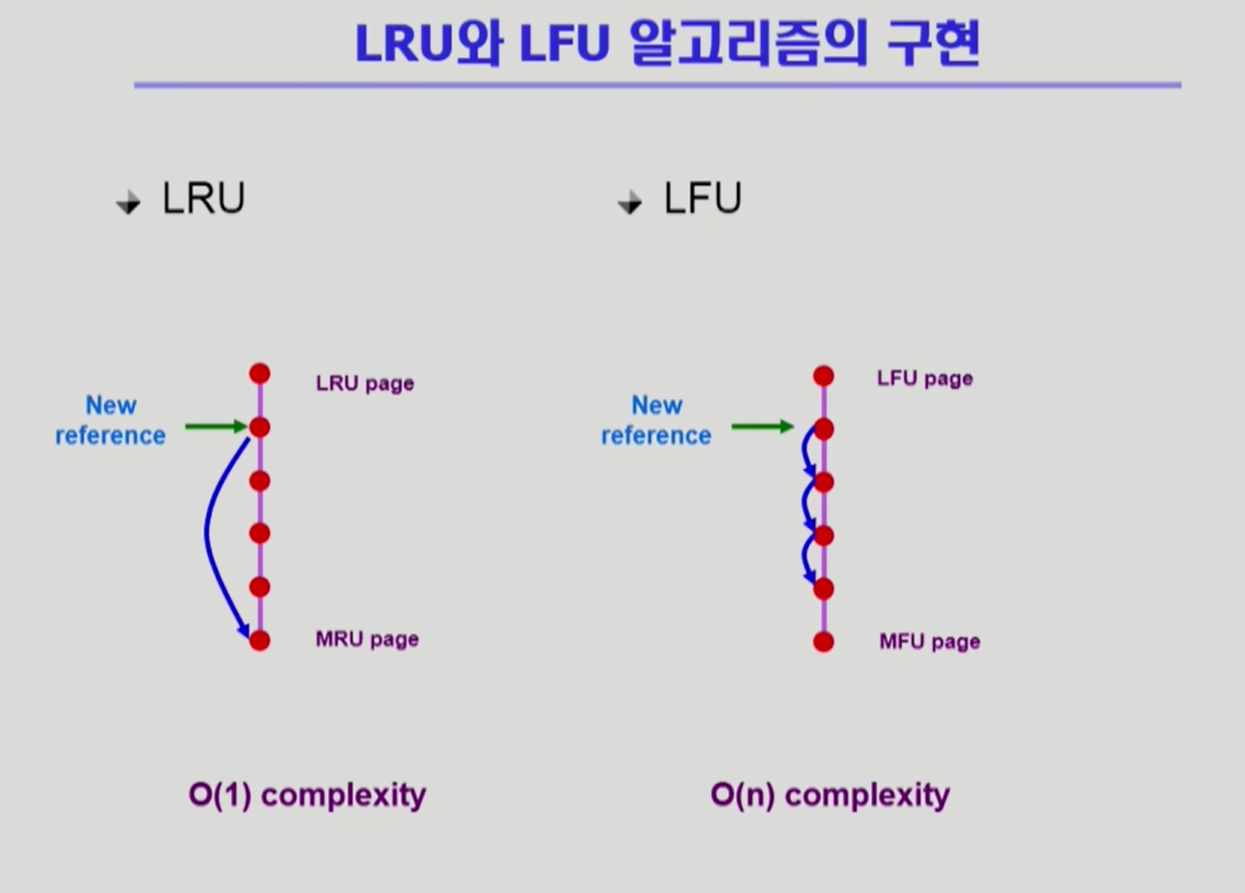
- 알고리즘은 위와 같은 방식으로 구현. 두 개 모두 자료 구조 형태로 모든 페이지를 관리.
-LRU의 경우 어느 위치에 있든 참조한 값은 가장 최근에 참조한 값이 되기 때문에 우선순위의 마지막에 배치. 그러므로 복잡도가 O(1)로 사실상 없음.
-LFU의 경우 자신이 참조된 갯수가 리스트의 어디에 위치해 있는지를 모르기 때문에 하나 하나씩 비교를 해야함. 그러므로 복잡도가 O(n)에 위치.
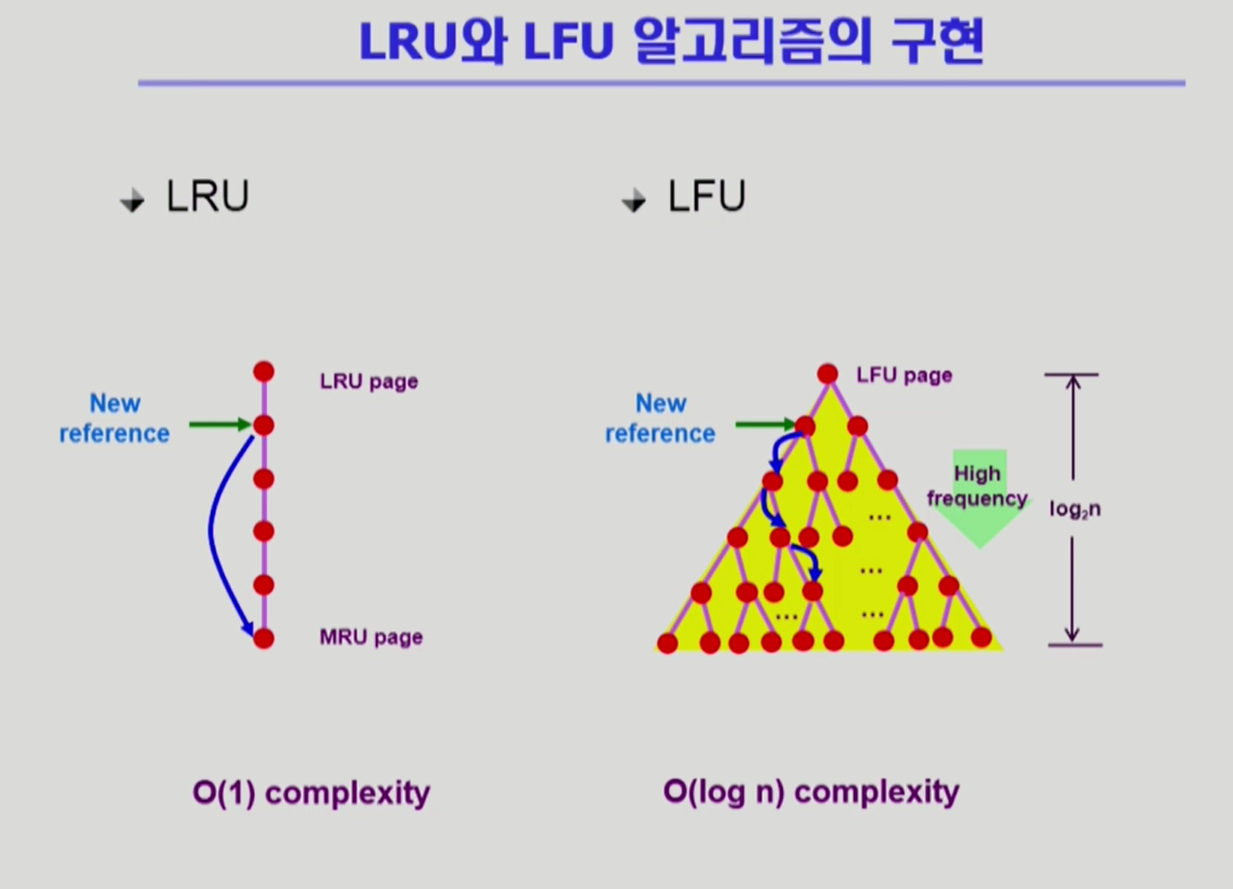
- 그러므로 LFU는 heap 형태로 자료구조를 구성. O(log n) 수준으로 복잡도가 줄어듦.
4. 페이지 폴트를 위한 전략을 유저 모드(mode bit:1)에서 실행할 수 있는가?
- 프로세스가 cpu를 점유하고, MMU를 통해 논리 주소와 물리 주소를 번역하여, cpu가 필요로 한 프로세스의 물리 주소의 코드를 읽어 instruction을 실행한다. 그리고 cpu가 참조하고자 하는 코드가 물리 메모리에 없을 경우, 페이지 폴트가 발생하며 트랩이 된다. 트랩이 발생하기 직전까지는 운영체제 없이 유저모드에서 작동한다.
- 페이지 폴트가 발생하여 페이지를 교체해야 할 때, 효과적인 victim을 정하기 위해 이론적으로는 LRU, LFU 등의 알고리즘을 활용한다. 페이지의 참조 시간이나 참조 횟수를 자료구조화 한다.
- 하지만 LRU, LFU를 위한 자료구조 생성 및 조작 자체가 운영체제를 필요로 한다. 운영체제에서 페이지를 물리 메모리에 호출할 때의 I/O 접근 시간을 확인할 수 있다.
- 그러므로 페이징 시스템을 위한 새로운 레지스터와 알고리즘을 필요로 한다.
5. Clock Algorithm
- LRU 근사 알고리즘
- Second Chance Algorithm, NUR(Not Used Recently), NRU(Not Recently Used) 등으로 불림.
- Reference bit을 하드웨어로 가짐. 각 페이지는 최근에 사용된 경우 0에서 1이 됨. 알고리즘이 작동하면, 해당 페이지가 1인 경우 0을 만들고, 0인 경우 교체할 페이지로 선정.
- LRU와 같이, 최근에 사용된 페이지의 경우, 알고리즘이 작동하여 1이 0이 되더라도, 해당 알고리즘이 다시 작동하기 전까지는 1이 될 것이며 기회를 얻음(second chance).
- 알고리즘을 개선하여 modified bit(dirty bit)을 함께 사용. modified bit이 1이 되었다는 의미는 최근에 값이 변경됨을 의미. 해당 페이지를 교체 할 경우 I/O 디바이스의 write 기능을 수반하기 때문에, 페이지 교체의 대상으로서 우선순위가 낮아짐.

JAVA web developer