Factorizaed Embedding Parameterization, Cross Layer parameter sharing, SOP, Encoder 모델은 hid_size, Layer 계속 늘린다고 성능이 좋아지지 않는다.
ALBERT에서 제시
Factorized Embedding Parameterization
BERT 에서는 input token emb size(E)와 hid size(H)가 같다. ALBERT에서는 E를 H보다 작게 설정하여 Parameter 수를 줄인다. E < H
E는 각 토큰의 정보를 담고있는 vector를 생성한다. 이에 반해 Transformer는 각Layer에서의 output은 해당 Token과 주변 Token 간의 관계까지 반영한 Contextualized Representation 이다. → 따라서 담고 있는 정보량 자체가 다르기 때문에 E가 H보다 비교적 작아도 될 것이다.
하지만 input dim이 맞지 않는 것을 factorization emb parameter를 이용함

기존 BERT : Vocab emb X Hid 의 2가지 Matrix로 decomposing을 진행
ALBERT 에서는 Input Emb를 h 보다 작게 설정
Input Emb는 token정보담고 있음
Hidden output은 transformer에서 학습된 contextualized representation결과
Cross layer parameter sharing
Transformer layer끼리 parameter 공유
layer 간 파라미터 공유 했을 때 성능이 크게 떨어지지 않는다. 다만 (Forward Network = FFN)은 공유시 성능이 다소 떨어진다.
공유시 성능의 큰 변화가 없다는 점에 대한 설명은 없다. 하지만, Layer 간 Parameter를 공유 한다고 하더라도 크게 성능이 떨어지지 않는 다는 결과는 큰 의미가 있습니다. 따라서, ALBERT는 BERT와 같은 layer 수, Hidden Size일지라도 모델의 크기가 훨씬 작습니다

Shared-attention, all-shared등의 방법
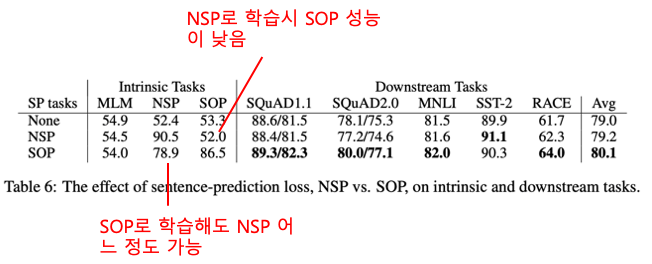
Sentence Order Prediction(SOP)
BERT에서는 Next Sentence Prediction(NSP)
너무쉬움
Sentence간에 연관관계를 학습하는 것이 아닌 같은 topic인지 보는 topic prediction에 가깝다.
이를 보완하기 위해 SOP 도입
SOP의 학습 데이터는 실제 연속인 두 문장(Positive Example)과 두 문장의 순서를 앞뒤로 바꾼 것(Negative Example)으로 구성되고 문장의 순서가 옳은지 여부를 예측하는 방식으로 학습 → SOP로 학습 시 두 문장의 연관 관계를 보다 잘 학습할 것이라고 기대

항상 좋은 글 감사합니다.