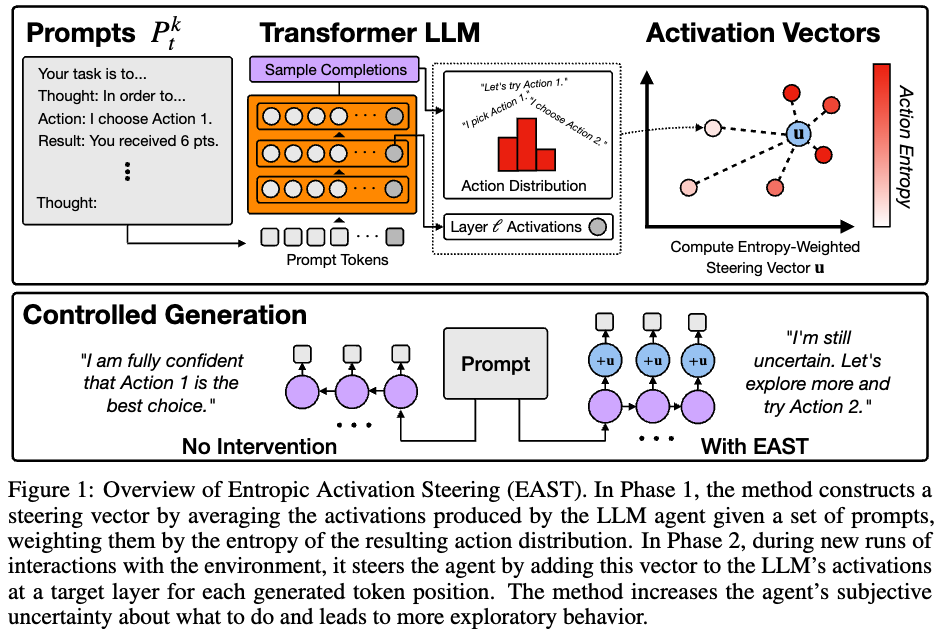
- Keyword: confidence, steering, EAST
- Novelty: Confidence 를 줄이고자하는 노력
- Summary: EAST라는 방식을 통해 LLM이 과하게 자신을 믿는 경향인 overconfidence를 극복하고자함
Paper Motivation: LM은 overconfident로 인해 insufficient evidence를 바탕으로도 답변을 생성하고 이는 incorrect behavior가 를 진행한다. 또한 token-level sampling technique 또한 abstract level의 decision making이 발생하게된다고 주장.
Solution: Entropic Activatrion STeering (EAST) 방식을 제안. in-context에 대한 activation steering 방법이다. 이는 logged dataset을 이용해 env와 LLM의 상호작용을 통해 steering vector를 만드는 과정에서 시작한다. Steering vector는 LLM이 맞게 decision을 생성했었을때 representation 평균을 낸 entropic-weighted average of the representation 으로 만들어진다. → 궁극적인 목표: to make interpretable and controllable LLM agent.
아래는 Token 단위에서 entropy 조작으로 해결할 수 없다는걸 보여주는 내용 (entropy 조작은 overconfidence를 보여주는 부분이기도 하다.)
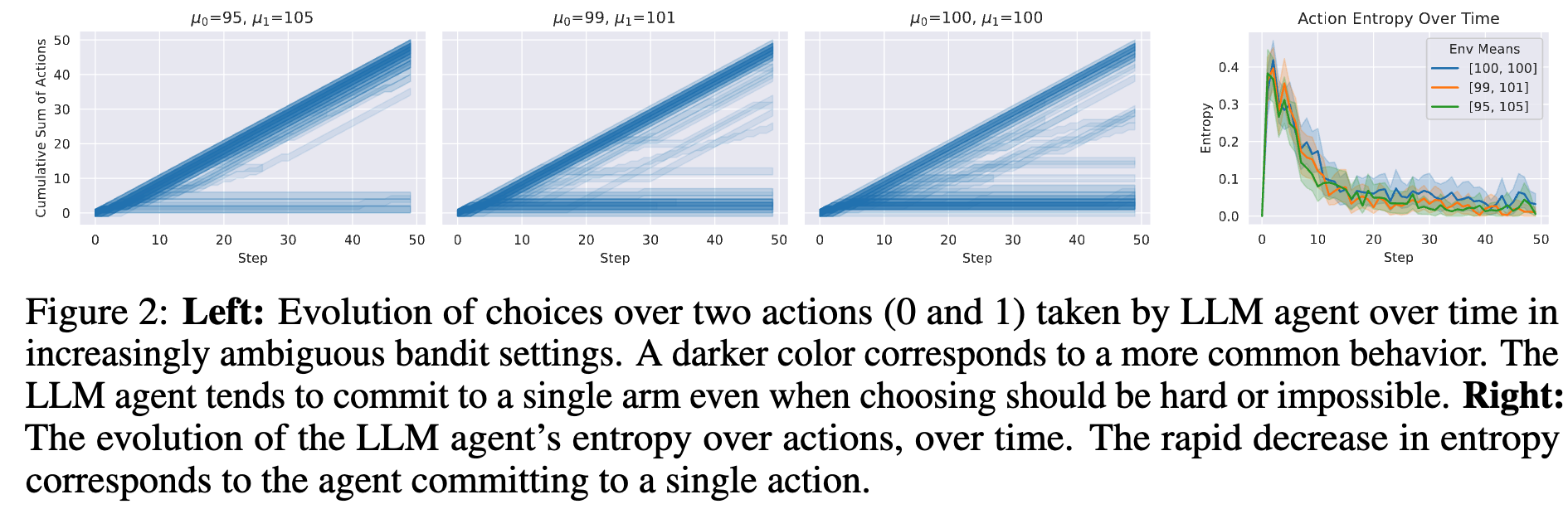
먼저 figure2 왼쪽 그림에서 mean, variance를 다르게 해서 bandit setting을 진행했을 때, 모델은 확신을 가지고 0 or 1중 하나를 선택하는 모습을 보인다. 또한 figure2 오른쪽 그림에서 step이 증가할 수록 오히려 entropy가 감소하는 모습을 보인다. (entropy 감소 = 정보량 낮음 = 불확실성 낮음(=self-confidence 가 높음)) 하지만bandit 환경에서는 정답이 존재하지 않고 이는 모델의 확신도가 낮아야하는 env에서도 자기확신도가 높다는 것을 의미한다.
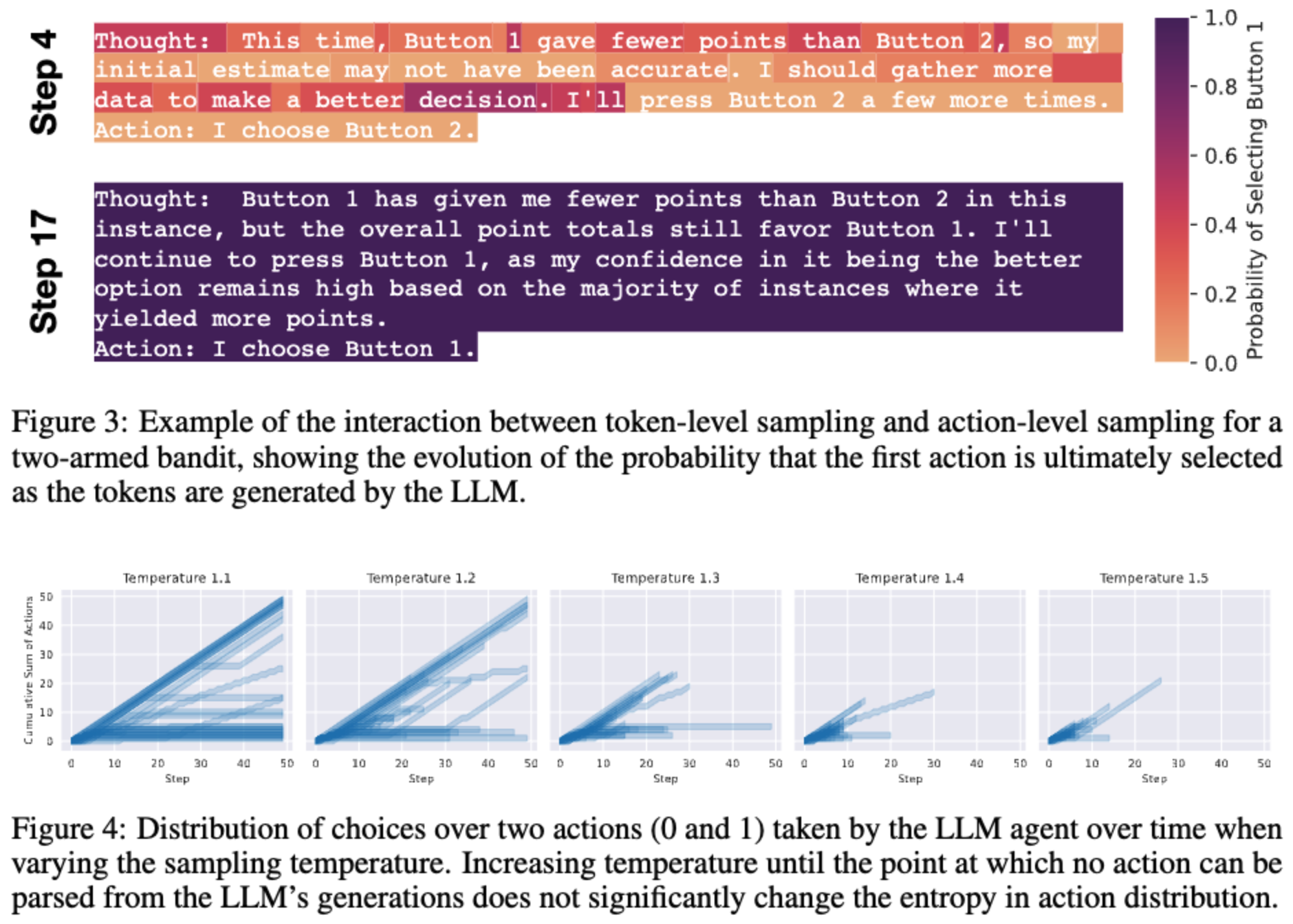
figure3 에서는 step 에 따라 confidence(figure2오른쪽 그림에서 낮은 스텝에서 entropy 가 높은것과 높은 스텝에서 entropy 가 낮은 것을 보여주는 예시)가 달라지는 것을 모델 생성하는 토큰과 같이 보여주는 예시이다.
figure4는 temperature를 조절하면 confidence를 조금은 조절할 수 있음을 보인다. 하지만 상당한 변화를 이끌어내지는 못한다고 말한다.
이런 figure2, 3, 4 는 LLM의 nature of their interaction 때문이라고 말하면서 토큰 생성에서 조절하기 힘들다는 것을 보인다.
Entropic Activation Steering
수식은 강화학습에서 사용하는 Advantage function 과 유사하다. 앞에 Entropy weight를 곱해준다.

이후 를 steering vector로 하고 기존 로 steered representation 을 만들어서 forwarding 을 진행한다.
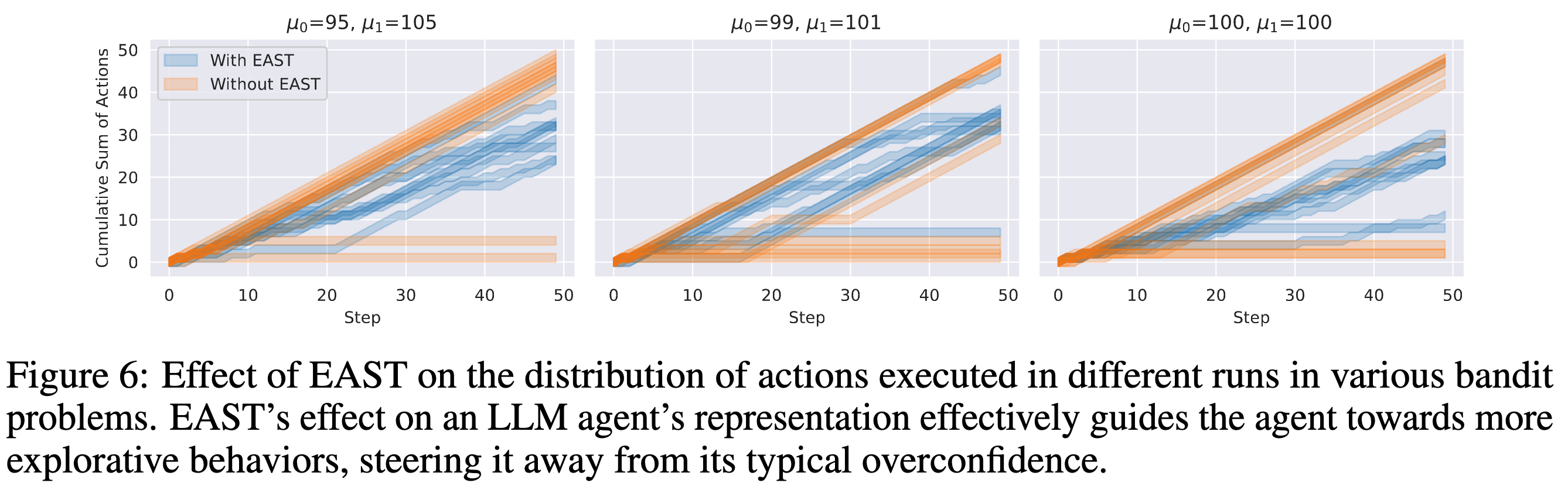
figure2의 왼쪽그림과 비교해보았을 때 figure6은 본인들의 방식으로 진행했을 때 overconfidence가 더 적게 나오고 특히 3번째 figure를 보면 100, 100 평균을 주었을 때는 0과 1 중간으로 action을 생성한다. 이는 LM의 overconfidence문제가 어느정도 완화 되었다는 것을 알 수 있다.
Limitation
discrete action에 대한 env 에서만 실험이 진행됨. → future work로 entropy를 이용한 일반화 시키는 방법을 연구할 수 있다고 말함.
