ACL 2024 main
Dynamic retrieval augmented generation 이 언제 그리고 어떻게 retrieve 할지 선택하는 것이다.
저자는 아래의 2개가 해당 분야의 key elements 라고 말함.
- retrieval module 을 언제 activation 할지 결정하는 것
- retrieval 을 할 때 적절한 query를 crafting 하는 것
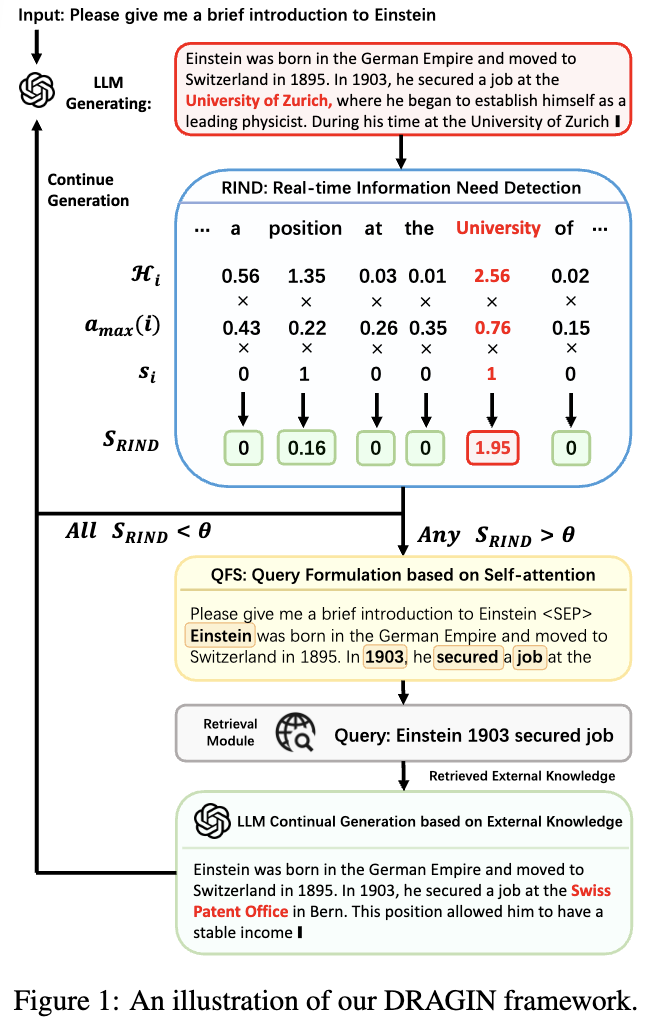
본 논문은 언제 그리고 어떻게 retrieving 할지 결정하는 Dragin 을 제안함. retrieval timing을 잡기위해 RIND (Real-time Information Needs Detection)을 제안한다. 해당 RIND 는 LLM’s 생성하는 각 token uncertainty를 바탕으로 진행하고 semantic significant를 고려한다. 그리고 retrieval qeury를 formulate 하기 위해 QFS (Query Formulation based on Self-attention)를 제안한다. QFS는 전체 context에 대해 Self attention를 진행해 query를 만드는 작업을 한다.
Method
RIND (Real-time Information Needs Detection)
RIND 는 각 토큰에 대해 entropy를 측정한다. 는 확률을 의미. 이를 uncertainty 로 사용해 retrieval 진행 여부를 결정한다. 또 한 RIND 는 attention activation을 이용해 토큰이 이후 context에 주는 영향도를 본다. 이를 로 두고 이를 maximum attention value 로 사용한다.
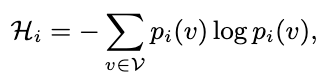
. 는 attention score, (i < j, token position).
또한 stopwods 를 설정해 해당 부분에는 0 을 곱해서 영향도를 없애준다.
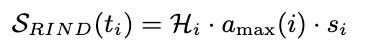
해당 값이 일정 threshold 를 넘어갈 때 retrieval module 이 활성화 되게 한다.
→ 정리: 이전 토큰 (i)가 있을 때 (j)에 대한 attention score의 max 값(이것도 i에서의 attention score max 값)을 가져오면서 하면서 i 토큰 entropy랑 곱한다. 이때 중요도가 높은 token이 entropy가 threshold보다 높은경우 retireval point를 잡는다는 뜻
QFS (Query Formulation based on Self-attention)
이전까지 나온 문장으로 retrieval을 진행할 경우 정보가 충분하지 않음. (아직 완전히 문장이 끝난 상태가 아니기 때문) 이때 attention based reformulation을 진행한다 (이게 전체 context 를 이해하는데 좋다고 주장).
먼저 retrieval 하는 신호가 나오면 i 번째 이전 토큰에 대해 마지막 레이어에서 attention weights를 측정한다. 여기서 top n 개의 token을 뽑고 이 단어들을 바탕으로 reformulation을 한다고 함. → (Figure 1에서 Einstein, 1903, secured, job 이라는 토큰이 뽑혀서 query가 Einstein 1903 secured job이라는 query를 생성함.)
Continue Generation after Retrieval
: truncated output
: original sequence generated by the LLM
: the token at which the need for external knowledge was identified by RIND
.
여기서 retrieved docs 를 이라고 할 때 다음과 같은 프롬프트로 이후 답변을 계속 생성하게 한다.

짤린 output과 doc를 기반으로 생성한다. 생성된 contents와 turncated point를 통합한 이후 LLM은 다시 생성작업을 진행한다.
Experiment