May 24, 2023
Moduler, query rewritting RAG 에 속함 (Survey 기준)
ITER-RETGEN(retrieval-augmented generation and generation-augmented retrieval) - 반복적인 방식을 사용함,
Introduction
최근 연구에서 LLM이 관련된 정보를 찾고 생성관련 가이드하는데 많이 사용된다.
evaluation에서 multi-hop QA, fact verification, commonsense reasoning으로 진행
단점은 약간의 overhead가 발생할 수 있다.
LLM 문제: open domain QA 에서 모델들은 hallucination을 내보낼 수 있다. 또한 학습된 데이터가 부족할 수 있는 문제가 존재. ← 해결하기위해 외부데이터 사용 (RAG)
최근 연구에서는 복잡한 information 을 해결하기위해 데이터 생성을 multiple times 진행 후 생성하도록 한다.
이런 연구들은 interleaving사용한다. → inverleaving의 문제: 1. 검색된 모든 지식을 전체적으로 처리하지 못한다. 2. 포괄적인 지식 세트를 수집하려면 다단계 검색이 필요하며, 새로 검색된 지식을 업데이트하여 프롬프트를 자주 변경하면 오버헤드를 증가시킬 수 있다. ex) Active Retrieval Augmented Generation(논문)
retrieval된 정보를 바탕으로 생성을 진행하고, 생성된 문장과 기존 question을 함께 retrieval을 진행한 후에 retrieval로 나온 정보를 바탕으로 generation을 진행

저자는 generation을 반복할 수록 더 좋은 결과가 나온다고 함. 또한 generation-augmented retrieval adaptation이라는 방법으로 반복횟수를 줄이거나, performance를 더 상승시킬 수 있다고 주장.
위와같은 방식을 이용해서 Self-Ask 방식을 outperform 할 수 있다고 주장함.
Related Work
LLM 의 고질적인 문제 - hallucination, new data 에 약하다는 점을 개선하기위해 search enghine을 사용한다던가 RAG방식 등 다양한 방식들이 존재. 여기서 RAG의 고전적인 방식들은 수동적으로 지식을 받고 생성하는 방식을 주로 사용함.
zero-shot 상황에서는 retrieval로는 관련성을 캡처하기 어렵다는 점이 있다. 최근에는 LLM을 active 하게 검색하는 과정에 포함시켜 modeling 관련성을 증가시키려는 시도들이 존재한다. (e.g., generated seqrch queries, partial generation, or forward-looking sentences(Active Retrieval Augmented Generation)) 또한 DSP 방식의 프레임워크가 다양한 retrieval-augmented methods에 도움이 된다고 한다.
또한 최근 연구동향은 generation이 끝난 output을 interleave하는 방식이 존재한다. 하지만 이 방식은 생성 시 flexibility를 감소시킬 수 있다. (ReAct: Synergizing Reasoning and Acting in Language Models 논문 비판)
전반적으로 생성을 반복하는 작업들은 performance가 증가하는 것이 사실이다.
본 논문이 제안하는 방식은 간단하고, 이식성이 좋으며 multi-hop question answering, fact verification, and commonsense reasoning 테스크에 잘 작동한다고 주장한다.
GAR논문: augments queries with generated background information
HyDE논문: zero-shot을 기반으로한다. LLM에게 hypothetical paragraphs를 생산하도록 해서 QA를 진행
HyDE논문은 문서 임베딩 벡터가 잘못된 세부정보가 포함될 수 있으므로, 인코더의 병목 현상을 통해 잘못된 세부정보가 필터링된다.
RepoCoder논문: repository-level code 완성을 제안, 두번의 반복을 통해서 생성하는 작업을 수행
본 저자는 ITER-RETGEN 의 방식으로 retrieval과 generation을 합성하는 방식을 제한
Iterative Retrieval-Generation Synergy
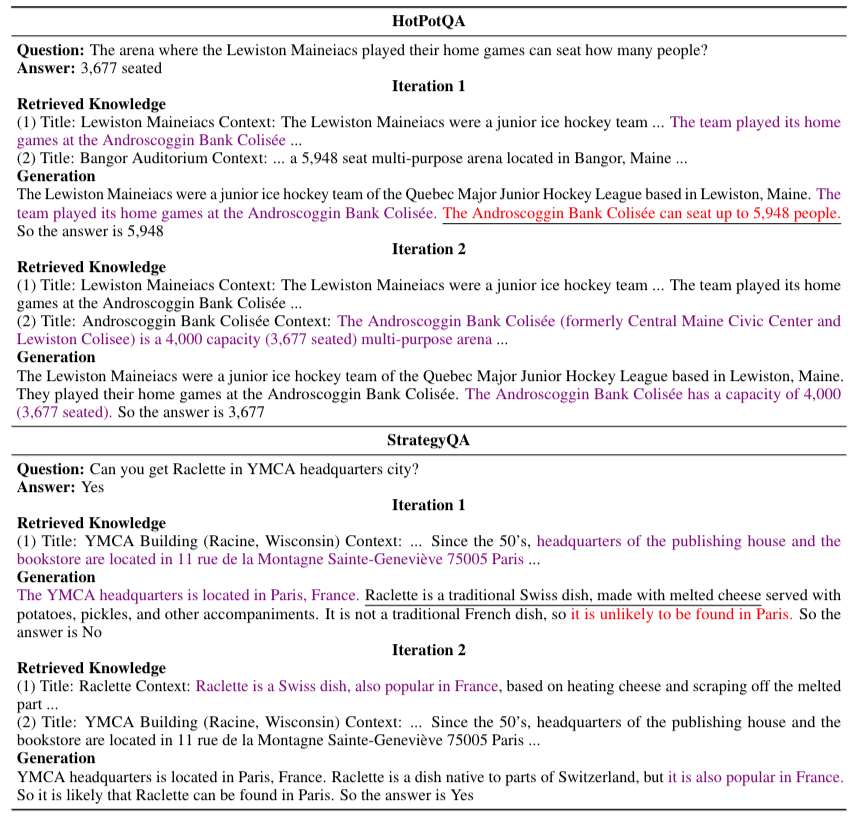
위의 figure1과정 진행 아래는 그에따른 식으로 표현. 해당과정을 반복해서 시점까지 반복.
해당과정을 반복하는 이유는 original question 와 supporting knowledge간의 gap이 존재하고, 이를 완화하기위해 iteration과정을 통해 정확성을 높일 수 있다고 주장한다.
Retrieval-Augmented Generation과정에서는 CoT를 사용해 output을 생성하였다. 더 좋은 프롬프트가 있는지는 future work로 남겨둠..
Generation-Augmented Retrieval Adaptation과정에서는 retrieval을 위한 특정 컨텍스트를 준다.
Dense Retriever과정에서는 각 인코더마다 embedding을 구하고 내적을 통해 유사도를 구한다.
Re-ranker과정에서는 paragraph와 query와 관련도를 측정한다.
Distillation: Re-ranker를 통해서 관련도를 더 잘잡을 수 있게 되고, 이로인해 distill knowledge가 발생한다. 해당과정을 통해 retrieval에 적합한 질문 형식을 만들 수 있다고 주장함.
Experiments
실험결과 Self-Ask보다 좋다고 주장하는데 Self-Ask는 긴 QA에서 실험하도록 셋팅되어 있는 모델이기 때문에 적절한 비교가 아니라고 생각된다.
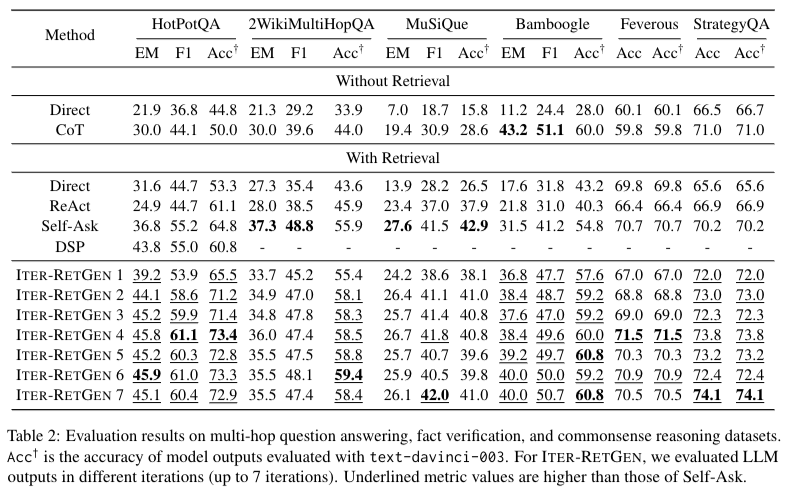
1) Multi-hop question answering: HotPotQA, 2WikiMultiHopQa, MusiQue
2) Fact Verification: Feverous
3) Commonsense reasoning: Strategy Qa
모든 방법들은 3-shot setting을 진행함. prompt는 모두 동일하게 설정,
metrics는 EM, F1(Multi-hop QA datasets), accuracy(fact verification and common sense reasoning)
Limitation
저자들은 model을 text-davinci003 을 사용해 실험을 진행했는데 이때 prompt를 이용해 fix를 시킨 모델로 실험을 진행. 또한 long-form을 커버하고있지 못하다고 말함.
