
용어
on-the-fly computational reasoning : 새로운 테스크에 대한 빠르고 효율적인 적응성,
PTB(Penn Tree Bank) : Zero-shot PPL of LM 이 PTB dataset에서 계산됨
novel symbolic manipulations : 왜곡된 단어 → 복원하는 과정의 데이터셋
spurious correlations : 허위상관, 통계적으로 상관되어 있지만 인과관계가 없는 관계를 말한다
중요내용 요약
gpt3 - 175B parameters
bert나 gpt같은 transformer 형태의 LM의경우에 finetuning 을 통해 task specific 한 모델 아키택처가 필요했다.
만약 task-agnostic하게 만들었다고 해도 task-specific dataset과 task-specific fine-tuning이 필요하다.
또한 새로운 테스크를 위해서는 큰 라벨링된 데이터셋이 필요하게된다.
META-learning : 모델학습과정에서 다양한 스킬과 패턴 인식하는 능력을 발전시키고자함
incontext learning 를통해 많은 언어적 스킬이나 task를 잘 흡수할 수 있게 만들어냄
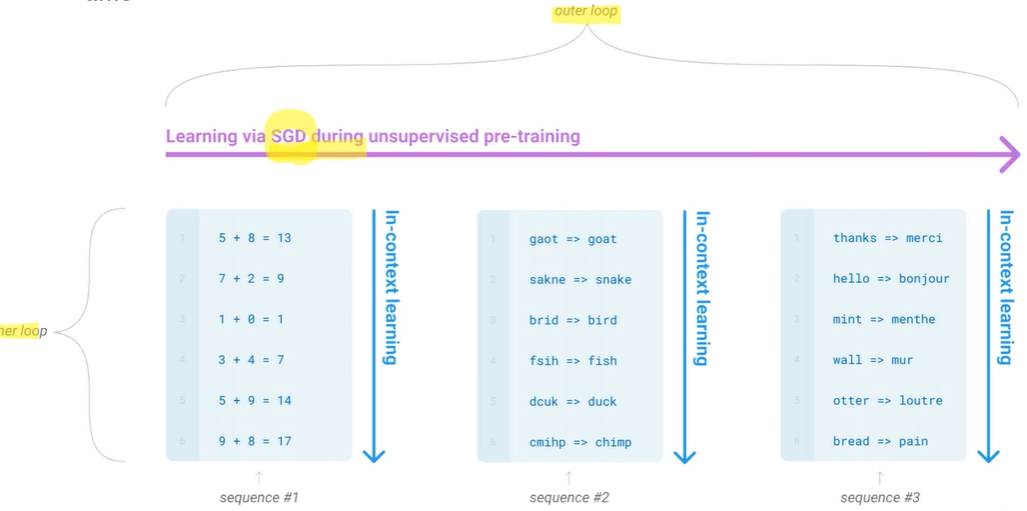
gpt3 에서는 모델의 사이즈를 엄청나게 키웠는데 이를 transformer 아키텍처에서는 모델의 사이즈가 커질수록 더 좋은 성능(Log loss follows a smooth trand of improvement with scale)을 낼 수 있다. 라고 실험적인 결과를 통해 주장. + incontext learning 또한 모델 스케일이 커짐에 따라 효과가 좋아진다. 라고 주장함

GPT3는 zero-shot and one-shot 셋팅에도 SOTA를 찍는 데이터 셋은 존재한다. 또한 unscrambling words, performing arithmetic, using novel words in a sentence 작업은 잘 수행하는 것으로 보이지만 NLI task 나 MRC dataset에서는 어려워하는 부분이 존재한다.
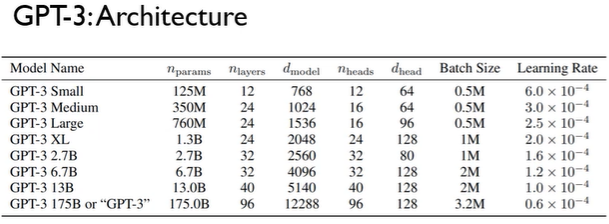
맨 아래 GPT-3 175B의 경우 의경우 12288 이고 FFN 에 들어가는 행렬은 12288 * 4 를 사용한다. (대부분 GPT 아키텍처의 FFN 에 들어가는건 4배 시켜놓음) + token = 2048
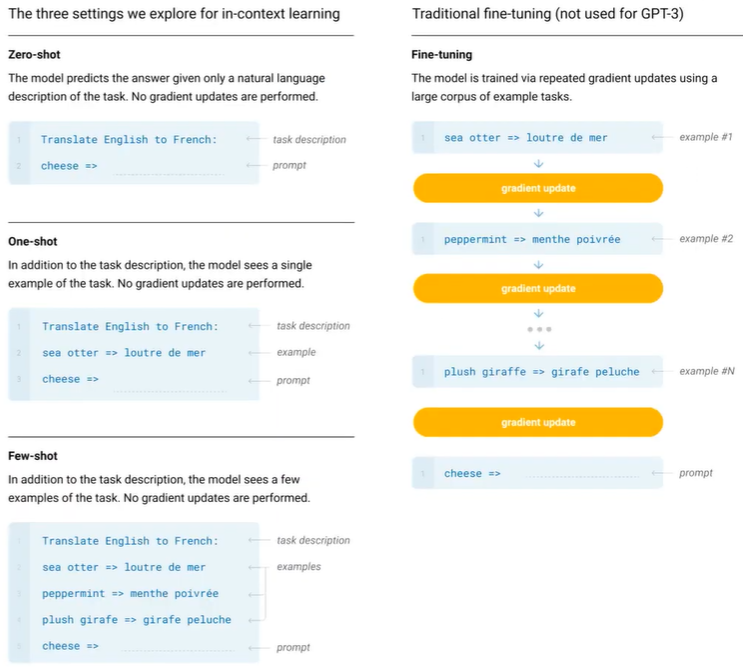
논문에서 가장 강조하는 것은 zero shot이나 few shot 는 finetuning 방식들과는 다르게 추가적인 gradient update를 수행하지 않는다(inference시 example 에 대해서는 ).
FT fine-tuning:
장점 : 많은 벤치마크에서 강한 성능을 보인다.
단점 : OOD, large dataset, to exploit spurious features of the training data(과적합)
FS few shot:
장점 : task specific data 사용할 필요가 없어짐.
단점 : 상대적으로 sota 보다 성능이 떨어짐, 소량은 데이터는 여전히 필요함
어텐션 연산을 진행할 때 모두 연산하는 것이 아니라 sparse attention 을 사용한다.
strided와 fixed 방식 2가지가 존재
strided : 입력 시퀀스를 일정한 간격으로 샘플링하여 참조하는 방식 모든 위치를 참조하지 않고, 일정한 stride(step) 값으로 떨어진 위치만을 참조
fixed : 입력 시퀀스를 고정된 위치로 참조하는 방식, 고정된 위치 집합을 사용해 참조하는 위치를 결정함.

학습데이터의 경우 필터링된 Common Crawl dataset(410B)을 기본적으로 사용하고, deduplication을 사용해 validation set 과 데이터셋이 겹치는 것을 피했다. 또한 reference 높이기위해 webText(19B), book1(12B), book2(55B), wikipedia(3B) 데이터셋도 함께 학습에 사용했다. 1epoch도 학습시키지 않은 데이터도 존재함.
training cost
학습시에 data의 ovelaps 이 존재하는데 학습비용으로 인해 재학습시키지 못했다고 한다. 약 model 하나 학습시키는데 50 억이라고 한다.
Limitation
- text형성(문장생성에서 모순이 발생함), 몇몇 NLP task 에서 학습능력이 뒷쳐지는 부분이 존재한다.
- 물리적인 지문에 약한 모습을 모임, 같은지문인지 비교하는 task에 약함
- 구조적인 문제 : 대부분 SOTA를 달성한 모델들은 bidirection형태를 취하고 있지만 GPT3 는 해당 형태가 아닌 AR 구조임
- dataset spectrum이 다양하기 때문에 few shot learning으로 진행되는지 안되는지 모호성이 존재함
- 모델이 너무 커 경량화가 필요하다 + billion parameter에 대한 경량화 실험이 존재하지 않는다.
- 모델의 결정에 쉽게 해석할 수 없다. + 일반적인 benchmark task 에 잘 보정되지 않았다.
- 모델이 편향되거나 고정관념있게 학습되면 그것들을 반영해 생성해버린다. → 사회적관점과 같은 것(인종, 성별, 종교 등등…)
open ai 논문 중 인간선호에 따른 feedback을 받은 fintuning 논문이 존재하는데 이를 reinforcement를 이용한 finetuning은 new task adaptation에 강하다는 점을 보고 미래 방향성을 암시함.

많은 도움이 되었습니다, 감사합니다.