용어:
Jointly Train: retriever과 LLM 통합적으로 학습. 단일 학습과정에 동시에 학습되는 특징. 학습 데이터가 많은 양을 필요로한다는 단점이 존재. IR 시스템이나 LLM 변경시 전체 모델을 다시 학습시켜야함. 장점은 최적화되면 성능이 매우 높음
LLM-centric: LLM이 주요역할을 수행하며 IR은 plug-in 형태로 사용. retriever은 학습하지 않기 떄문에 통합이 쉽고 retriever 교체 혹은 제거에 자유로움.
Intro, Abstract
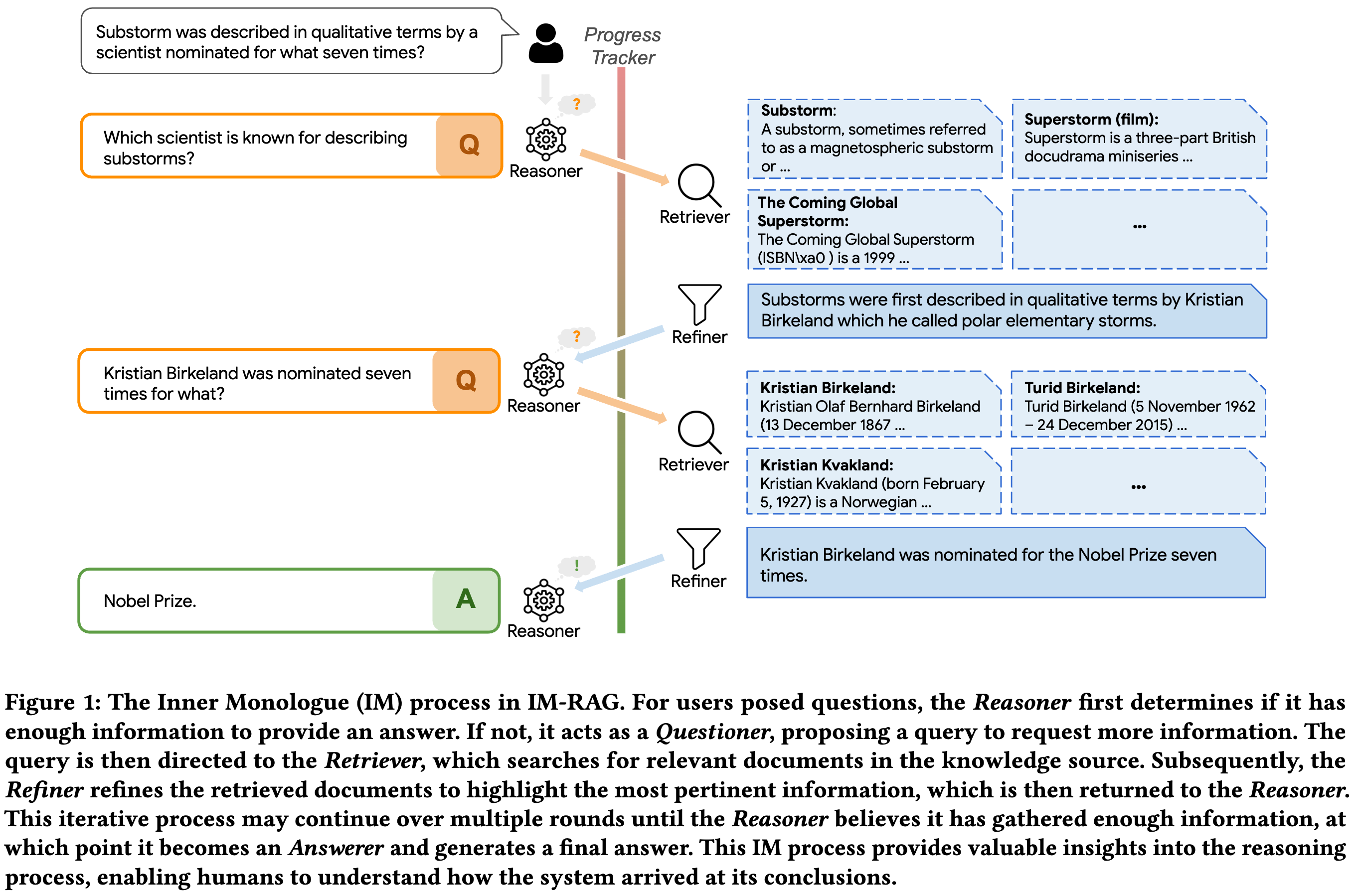
본 논문은 기존 LLM의 static knowledge (지식 업데이트 문제) 그리고 hallucination 한계를 가진다는 것에 주목한다. RAG는 이러한 문제를 해결하기 위해 정보 검색을 통해 사실 기반 응답 생성이 가능하다는 장점이 존재한다. 하지만 기존 RAG는 IR 시스템과 LLM 이 통합되지 않아 검색과 응답 생성 과정간의 최적화가 단절되어 있으며, multi-step retrieval 을 진행할 때 해석 가능성이 부족하다는 문제가 존재한다. 본 논문은 위 문제를 해결하고자 하며 Inner Monologue (IM) 개념을 통해 논리적 사고와 정보탐색 그리고 multi-step 최적 답변을 생성하고자한다.
Method
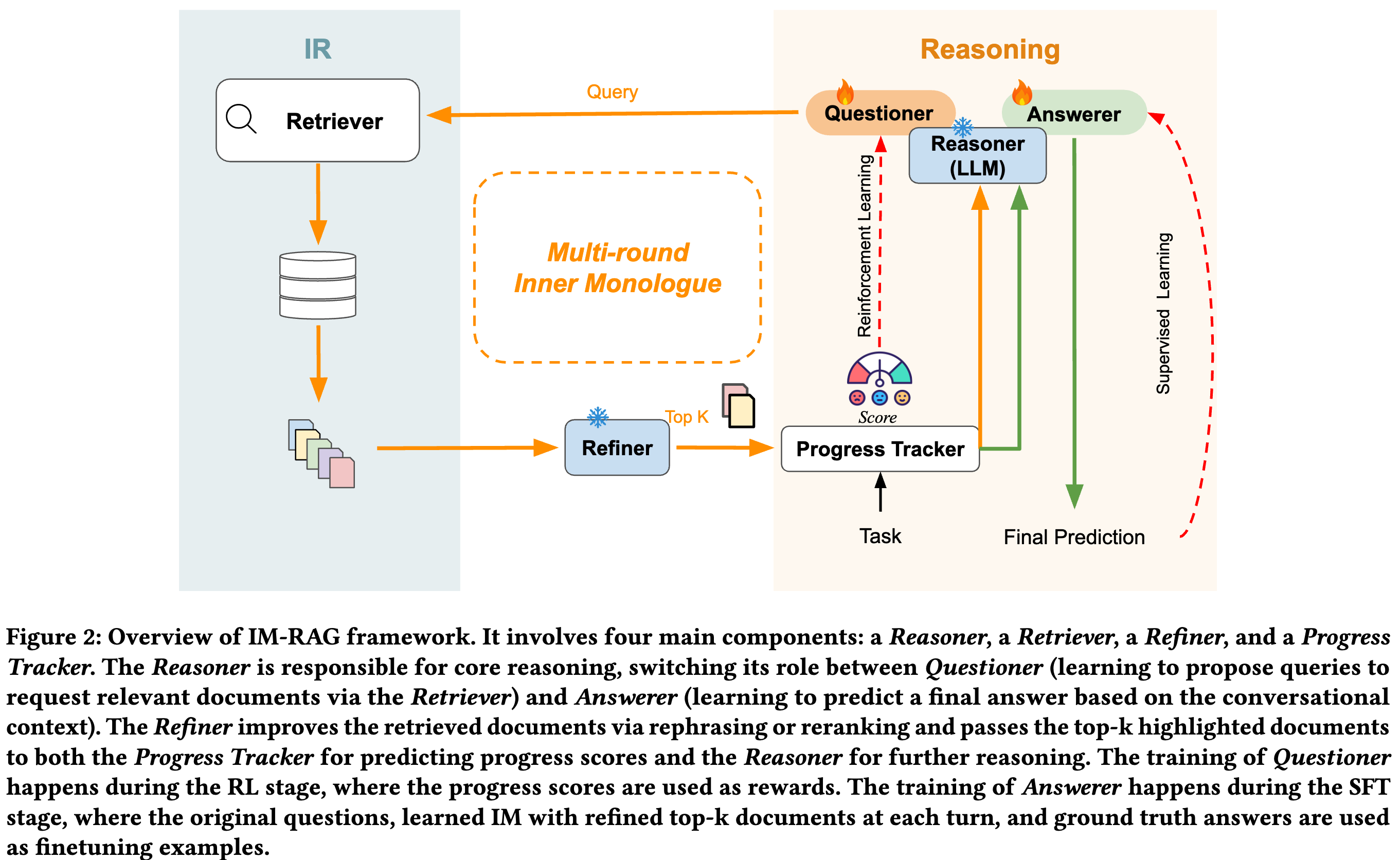
IM-RAG 에는 4가지 요소가 존재한다. 1. Reasoner (Questioner, Answerer 역할 각각 lora fine-tuning). 2. Retriever: 검색엔진. 3. Refiner: 검색된 문서를 재구성해 LLM이 이해할 수 있도록 변환. 4. Progress Tracker: multi-step retrieval 과정을 추적하고 학습 보상신호를 제공함
Reasoner 의 경우 Questioner 에서 복잡한 질문을 하위query로 나누는 고자ㅓㅇ을 진행한다. 이전 검색 결과와 대화 문맥을 바탕으로 새로운 쿼리 생성. RL을 통해 학습. Progress Tracker로부터 중간 단계 보상을 ㅂ다아 쿼리 생성 능력 최적화 시킨다. Answer의 경우 multi-step retrieval 후 최정 답변을 생성하는 역할. SFT 만 진행한다.
Retriever: 검색
Refiner: 검색된 문서 형식을 LLM이 처리하기 쉽도록 수정하는 과정. 불필요한 정보 제거 등 처리 진행
Progress Tracker: multi-step retrieval 를 평가하고 보상 제공. 각 단계에서 정답 문서와의 유사도를 계산해 distance score를 산출함. multi-step retrieval이 완료되었는지 판단함. distance score가 threshold 를 초과하거나 최대 retrieval call 횟수에 도달하면 검색 종료하고 answerer로 진행.
Experiment
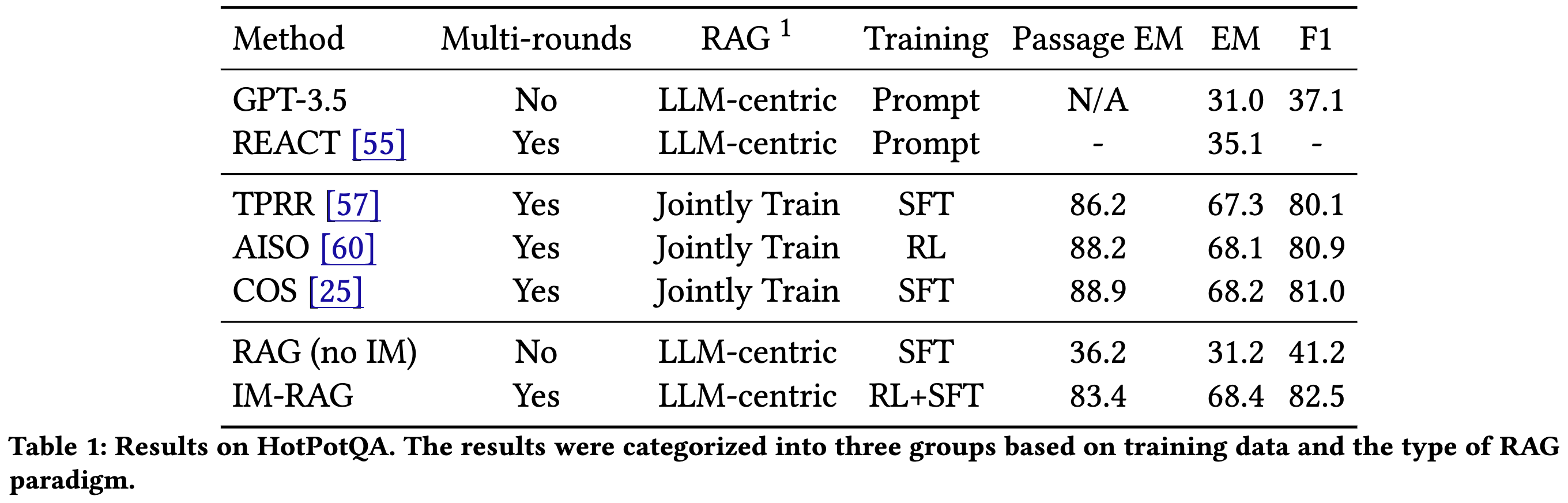
매우 코스트 집약적인 방식인데 다른방식과 비교했을 때 성능향상은 크지 않다. 또한 HotPotQA 에 대해서만 평가를 진행해 다른 RAG or IR dataset 에 대한 평가를 진행 하지않음. 하지만 저자들은 SOTA 성능 달성했다고 주장함.
