잘못된 내용이 있다면 댓글 부탁드립니다!! 감사합니다 :)
Paper link: https://dl.acm.org/doi/pdf/10.1145/3649450#page=23.46
용어
rationale selector: 텍스트 데이터에서 모델의 예측에 중요한 영향을 미치는 부분(단어나 구절)을 선택하는 모델의 부분 또는 알고리즘
Gradient-based Measures: 모델의 출력에 대한 입력의 기여도를 평가하기 위해 그래디언트를 사용하는 방법. 대표적으로 Saliency Maps, Grad-CAM, Integrated Gradients 등이 있다. + 단어의 중요도를 평가하기위해 단어의 embedding과 the gradient of output 을 dot-product 진행을 통해 중요도를 판별하는 방법. 이 값을 사용하여 각 단어의 중요성을 평가
Gradient Approximation Methods: 그래디언트를 직접 계산하기 어려울 때 근사치를 사용하는 방법. Finite Differences, Sampling-based Approaches 등이 있다.
This survey are only associated with local interpretation and are specifically divided into three categories:
(1) Interpreting the model’s predictions through related input features;
(2) Interpreting through natural language explanation
(3) Probing the hidden states of models and word representations.
Interpretable Methods
Feature Importance
중요한 input features를 확인하는 것은 모델의 예측 결과의 영향도를 직관적으로 파악하기위해 매우 중요하다 (directly linking model outputs to inputs). text 분야에서는 extracting important features에 대한 4가지 방식이 있다. (rationale extraction, input perturbation, attribution methods and attention weight extraction)
- Rationale Extraction
rationale extraction은 NLP에서 모델의 예측을 설명하기 위해 입력 텍스트에서 중요한 부분을 선택하는 기법. 특히 감정 분석 및 문서 분류와 같은 작업에서 사용된다.
- Input Perturbation
input perturbation은 모델 예측에 중요한 입력 특징을 식별하기 위해 입력 데이터를 변형하거나 제거해 모델의 성능 변화를 관찰하는 방법. 모델 구조변경 X, 입력 데이터를 수정하여 중요한 특징 찾음.
LIME: 무작위 선택 후 제거 → 새로운 입력 생성 → 변형된 입력을 사용해 모델 예측 관찰 → 원래 예측과 비교. ⇒ NLP 작업에서 어떤 단어에 가장 많이 의존하는지 식별하는데 사용 (단어수준, 구절 수준으로도 가능)
- Attention Weights
Attention weights는 모델 예측을 설명하고 해석 가능성을 높이기 위해 사용되는 기법으로 모델이 입력 데이터의 특정 부분에 집중하도록 유도해 예측 결과를 도출하는데 중요한 역할을 함. 각 입력요소가 예측에 얼마나 기여하는지 수치화 하여 나타낼 수 있다.
장점: 해석가능성, 직관성.
단점: 신뢰성
21년도 논문에서의 주장이어서 그런지 해당 attention weight를 해석하는것이 가독성이 떨어지고 rationale 방식에 비해 해석 가능성 측면이 낮다고 주장한다.
하지만 최신연구를 바탕으로 볼 필요가 존재함.
- Attribution Methods
Attribution Methods: 딥러닝 모델의 예측 결과를 해석하기 위해 입력 특징의 중요성을 평가하는 기법. 주로 gradient를 사용해 입력 특징이 모델 예측에 얼마나 기여하는지를 측정한다.
DeepLift: 입력 변화와 출력 변화의 비율을 계산해 각 입력 특징의 중요성 평가 (입력과 기준값 사이의 누적 변화량을 사용하여 그라디언트를 계산)
LRP (Layer-wise Relevance Propagation): 예측 값을 입력 특징으로 역전파하여 각 특징의 기여도 평가 (네트워크 각 층에서 계산된 값을 다음 층으로 전파하여 최종 결과를 얻음.)
Guided Backpropagation: 그라디언트 역전파 시 양수 값 만을 사용하여 입력 이미지의 중요 특징을 강조 (전파 과정에서 양수 값만을 전달하여 중요한 특징을 더욱 명확히 시각화)
Integrated Gradients: 입력과 기준값 사이의 모든 포인트에 대해 그라디언트를 누적하여 중요도 평가 (입력에서 기준값까지의 경로를 따라 그라디언트를 계산하여 보다 정확한 기여도를 측정)
Natural Language Explanation
Natural Language Explanation: 예측된 결과를 자연어로 설명해는 방법.
- Multimodal NLE
Multimodal NLE: VQA와 같이 이미지와 질문을 입력으로 받아 모델의 답변을 설명하는 텍스트를 생성하는작업
- Text-only NLE
Text-only NLE: 텍스트 입력만으로 사용하는 NLP 작업에서 예측을 설명하는 자연어 텍스트 생성 (감정 분석이나 자연어 추론 작업에서 모델 예측 설명하는 텍스트 생성, CoT)
- Dialog-based NLE
Dialog-based NLE: 사용자와의 대화를 통해 모델의 예측을 설명하는 방식.
Probing
Probing: 내부 representation (embedding or hidden states)이 담고 있는 언어적 정보와 특성을 분석하는 방법. 작은 분류기를 사용해 모델의 특정 레이어나 노드에서 얻은 표현이 특정 언어적 속성을 얼마나 잘 포착하는지 평가.
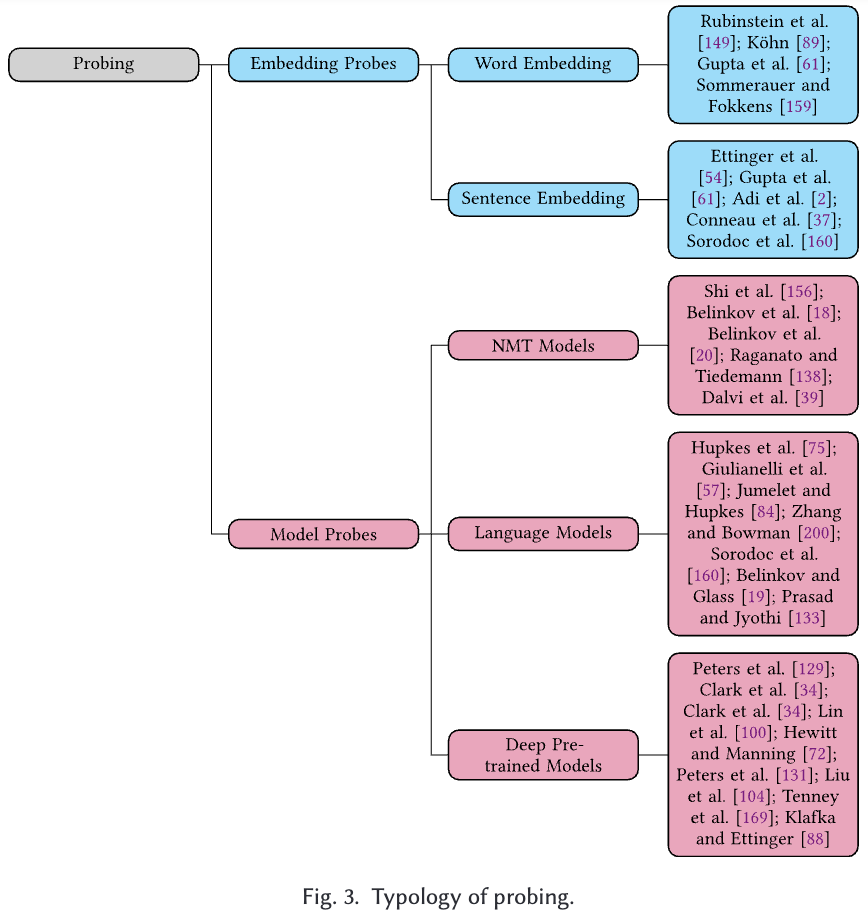
3.3.1 Embedding Probes: NLP의 언어적 특성을 얼마나 잘 포착하는지 평가하기 위한 기법. 임베딩이 다양한 언어적 속성을 얼마나 잘 예측하는지를 평가한다.
3.3.2 Model Probes: NLP모델 hidden state가 언어적 지식을 얼마나 잘 가지고 있는지 포착하기 위한 평가방법. 모델의 특정 레이어나 노드에서 얻은 표현이 다양한 언어적 특성을 얼마나 잘 반영하는지 측정한다. 이는 학습과정에서 어떤 정보가 어떻게 처리되는지를 이해할 수 있다.
probing classifier는 간단한 SVM, logistic regression 등을 사용해 hidden state에서 특정 언어적 속성을 예측한다. classifier의 성능을 통해 hiddenstate가 해당 속성을 얼마나 잘 반영하는지 평가한다.
Shi et al 2016: 본 논문에서는 NMT task 에서 LSTM based로된 모델 아키텍처에서 낮은 layer state는 fine-grained word-level syntatic information을 담고있고, higher-layer에서는 more global and abstarct information을 담고있다고 주장했다.
Clark et al 2019: 본 논문에서는 BERT의 hidden representation에 대해 probing classifier로 실험을 진행했고, 특히 attention에 집중해 dependency information을 확인했다.
Hewitt and Manning: 해당 논문은 주어진 문장의 parsing tree 를 보기위해 ELMO와 BERT에 생성된 representation을 확인했다.
3.3.3 Probe Considerations and Limitations
Probing은 단순한 분류기를 사용하는게 좋다. 복잡한 모델의 경우 표현을 정확한 평가를 하는 결과를 해석하는데 어려울 수 있다.
probe는 과접합 되지 않도록 주의해야한다. 훈련데이터의 특정 패턴을 학습해버릴 수 있다.
정확성 외에도 F1, Precision, Recall등을 사용할 수 있다.
한계: 프로브는 모델의 내부 표현이 언어적 특성을 얼마나 잘 포착하는지를 평가하지만, 이는 모델의 전체적인 언어 이해 능력을 완전히 설명하지는 않습니다. 프로브는 특정 작업에 대해서는 잘 작동할 수 있지만, 다른 작업에 대해서는 유용하지 않을 수 있습니다. 프로브 자체가 모델의 표현에 영향을 미칠 수 있습니다. 예를 들어, 복잡한 프로브는 모델의 표현을 왜곡할 수 있습니다. 다른 연구 결과와 직접적으로 비교하기 어려울 수 있습니다. 이는 실험 설정과 데이터가 다를 수 있기 때문.
최근 연구에서는 probe 복잡성에 관한 가정을 피하는 방법들이 제안되었다 (MDL probing [1], [2]). 단순히 “amount of effort”를 측정하는 방식이다. DirectProbe 방식은 intermediate representations을 바로 확인하는 방식을 제안하였다 (추가 classifier없이). probe를 평가할 때는 지표 선택이 중요하다는 논문도 있다. 그렇게 때문에 성능이 좋은 probe는 명확하지 않다. 모델이 실제로 최종작업에서 사용하지 않은 언어 정보를 인코딩할 수도 있기 때문이다. 이는 언어 정보가 존재한다고 해서 그것이 예측에 사용된다는 것을 의미하지 않는다는 것을 보여준다. 나중에 제안된 방법은 모델 표현에 직접적으로 개입하는 인과적 접근법인 amnesiac probing을 제안했다.
3.3.4 Interpretability of Probes and Future Work
프로브의 해석 가능성:
이해 용이성: 프로브는 주로 연구자가 모델을 조사하기 위한 도구로 사용되며, 최종 사용자를 위한 것이 아닙니다. 프로빙 결과를 이해하려면 프로빙하는 언어적 특성과 사용된 실험 설정에 대한 지식이 필요. 단순한 메트릭(예: 작업 정확도)만으로는 모든 내용을 설명할 수 없다.
충실성: 프로브는 모델의 숨겨진 상태를 직접 사용, 이는 이러한 숨겨진 상태 내에 있는 정보만을 나타내도록 설계되어 있기 때문.
향후 연구 방향:
인지적 측면: 프로빙의 결과는 모델의 예측에 사용되는 정보를 설명할 수 있도록 더 강력한 주장을 하기 위해 인과적 접근 방식과 결합될 수 있다.
안정성: 프로빙 방법은 같은 모델과 속성에 대해 안정적인 경향이 있지만, 다른 모델(예: 다른 데이터로 훈련된 동일한 아키텍처의 모델) 간에는 결과가 크게 다를 수 있다. 이는 주로 기저 모델의 기능 때문이며, 프로빙 결과가 모델과 속성에 매우 구체적임을 나타낸다.
전반적으로, 프로브는 모델의 “내부 작동 방식”을 조사하는 데 매우 유용한 도구. 그러나 다른 설명 방법과 마찬가지로 프로빙 기술의 설정 및 평가를 신중하게 고려해야 한다.
