Multiscale Positive-Unlabeled Detection of AI-Generated Texts
git : https://github.com/yuchuantian/aigc_text_detector
서론
짧은 문장들에 대해서는 인공지능이 분류하기 어려운 문제가 존재 -> 이를 해결하기 위해 MPU(Multiscale Positive-Unlabeles) 를 사용해서 해결하고자함 + MPU라는 argument를 이용해 긴문장 부터 짧은 문장 detection성능이 증가하게 되었음.
최근 가짜뉴스 tweets 등에서 생성되는 뉴스가 LLM에 의해서 생성되며, 해당 글은 상대적인 기사보다 짧은 경향이 있는데 이런경우 detection하기 어렵다는 특징이 있음.
원래 기존 이진분류 라벨을 지정하지만, 지정하지 않는 방식을 제안 -> 긴 text분류 가능 하지만, 짧은경우 사람이 작성한 것과 큰 차이가 존재하지 않게 된다. -> 텍스트가 짧다는 점은 감안해서 라벨을 지정하지 않는 방식을 제안함.
partical PU problem으로 지정해 보겠다. + 길이를 다양화 (Multiscale PU)
PU & MPU
PU : two step approach
step1 : realiable negative 추출 -> k-means, PGPU 등
step2 : cls 알고리즘 반복적으로 사용해 classifier만들어낸다. -> SVM, RESVM 등
이걸 왜 쓰냐? 단뇨병 진단받은 사람 -> label 이 존재
하지만 당뇨병진단받지 않았다고 해서 이 사람이 당뇨병 증상이 없는 것 아니며, 당뇨병으로 진행될 가능성이 있을 수 있음. 다시 말해 환자가 정상인 상태는 아니라는 것 -> 이런경우를 unlabeled 데이터셋으로 들어가며 이들을 분류하기 위한 목적으로 (unlabeled도 positive 쪽으로 들어갈 수 있음) 해당 학습방식을 사용함
해당 논문에서는 two-step learning + bias learning을 사용함
bias learning이란 unlabeled data를 negative sample(class-labeled noise)로 취급해버리는 것
MPU

- 해당 방식을 이용해 다중 스케일링이 가능하게 했다.
- EDA(Easy Data Augmentation)
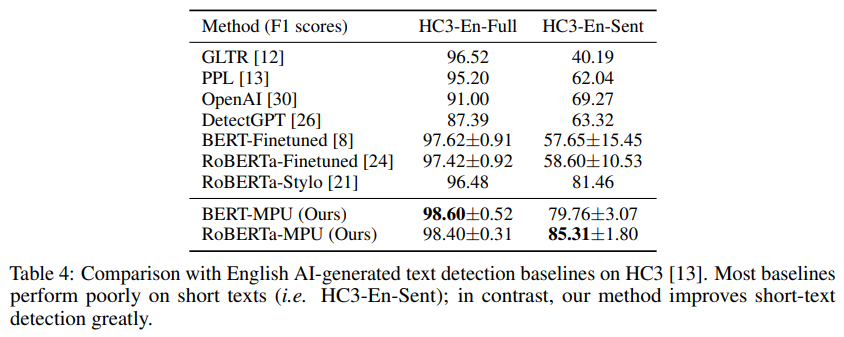
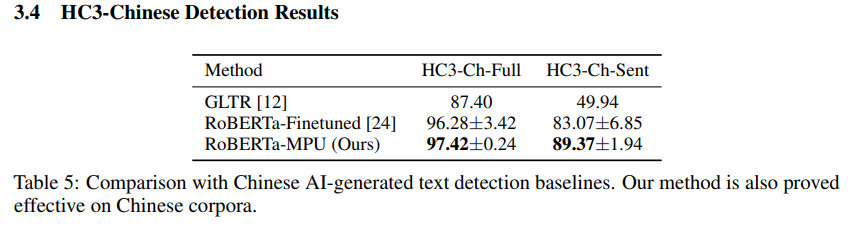
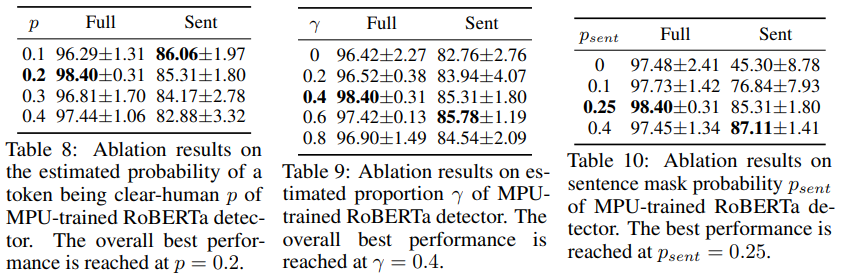
실험결과