transformer - 2017 구글이 제안한 시퀀스-투-시쿼스(sequence-to-sequence)모델이다. 최근 자연어 처리에서는 BERT, GPT와 같은 트랜스포터 기반 언어모델이 각광받고 있다.
대표적인 기계번역은 어떤 언어(source language)에서 다른 대상 언어(target language)의 단어 시퀀스로 변환하는 과제이다. 여기서 scource language 와 target language의 길이는 다르게 출력되는게 가능하다.
transformer은 seq2seq에 특화된 모델이다. 기계번역 뿐만아니라 다양한 분야에서 사용이 가능하다.
먼저 seq2seq의 구조는 인코더(encoder)와 디코더(decoder) 두 개 파트로 구성된다.
- encoder : 소스 시퀀스 압출, scoure sequence 정보를 압출해 decoder로 보내주는 역할을 한다. 인코더가 scoure seq 정보 압출하는 과정을 encoding이라고 한다.
- decoder : 타켓 시퀀스 생성, Encoding 과정에서 나온 정보를 바탕으로 target seq을 생성하는 과정을 decoding이라고한다.
ex) 기계번역에서 인코터가 한국어 문장을 압축해 decoder로 보내면 decoder는 이것을 받아 영어로 번역한다.
아래의 그림은 transformer의 인코터와 디코더의 구조이다.
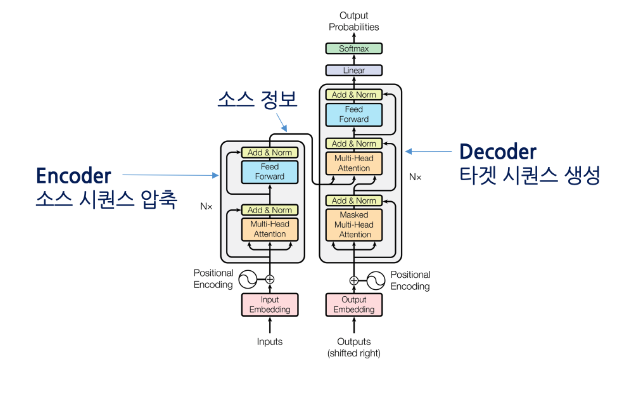
transformer block - encoder
- 멀티 헤드 어텐션(Multi-Head Attention) : Self Attention
- 피드포원드 뉴럴네트워크(FeedForward)
- 잔차 연결 및 레이어 정규화(Add & Norm)
transformer block - decoder
- 마스크를 적용한 멀티 헤드 어텐션(Masked Mutil-Head Attention)
- 멀티 헤드 어텐션(Multi-Head Attention) : Self Attention
- 피드포원드 뉴럴네트워크(FeedForward)
- 잔차 연결 및 레이어 정규화(Add & Norm)
Attention : 시퀀스 입력에 수행하는 기계학습 방법의 일종. 시퀀스 요소 가운데 테스크 수행에 중요한 요소에 집중하고 그렇지 않은 요소는 무시해 테스크 성능을 올린다.
Self Attention : 멀티 헤드 어텐션이라고도 부른다. 말 그대로 자기 자신에 수행하는 Attention 기법이다. 입력 시퀀스 가운데 테스크 수행에 의미 있는 요소들 위주로 정보를 추출한다.
기존 RNN과 CNN을 통한 문장 변역에서는 문장의 길어길 수록 예전 단어의 정보 손실이 발생한다 이를 극복해서 해당 아래의 그림과 같이 Attention모델은 오래전 단어에 대한 번역 품질이 떨어지는 것을 막을 수 있다.

Self Attention 특징 및 장점 :
개별 단어와 전체 입력 스퀀스를 대상으로 Attention 계산을 수행해 문맥 전체를 고려하기 때문에 지역적인 문맥만 보는 CNN대비 강점이 있다. 아울러 모든 경우의 수를 고려하기 떄문에 시퀀스 기링가 길어지더라도 정보를 잊거나 왜곡할 염려가 없다. 이는 RNN의 단점은 극복한 지점
- Attention은 소스 시퀀스 전체 단어를 타켓 시퀀스 단어 하나사이를 연결하는데 쓰인다. 반면 Self Attention은 입력 시퀀스 전체 단어들 사이를 연결한다.
- 어텐션은 RNN 구조 위에서 동작하지만 Self Attention은 RNN없이 동작한다.
- 타깃 언어의 단어를 1개 생성할 때 Attention은 1회 수행하지만 셀프어텐션은 인코더, 디코더블록의 개수만큼 반복수행한다.
계산 예시)
Self Attention은 쿼리(query), 키(key), 벨류(value) 세 가지 요소가 서로 영향을 주고 받는 구조이다. transformer블록에서는 문장내 각 단어가 vector형태로 입력된다. 여기서 각 단어 벡터는 블록 내에서 쿼리, 키, 벨류 세가지로 변환된다.
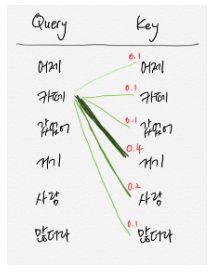
Self Attention 모듈 벨류 벡터들을 가중합(weighted sum)하는 방식으로 계산을 마무리하낟.
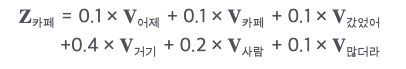
여기서는 카페에 대해서만 계산 예를 들었지만 이러한 방식으로 나머지 단어들도 셀프 어텐션을 각각 수행한다. 모드 시퀀스를 대상으로 셀프 어텐션 계산이 끝나면 그 결과를 다음 블록으로 넘긴다. transformer모델은 셀프 어텐션을 블록(layer) 수만큼 반복한다.
트렌스포머에 적용된 기술
Transformer에서는 크게 멀티 헤트 어텐션(Self-Attention), 피드포워드 뉴럴 네트워크, 잔차연결 및 레이어 정규화 세 가지 구성 요소를 기본으로 한다.
- 피드 포워드 뉴럴 네트워크(Feed Forward) : 멀티 헤드 어탠셩의 출력은 입력 단어들에 대응하는 vector sequence이다. 이를 각각의 Feed Forward뉴럴 네트워크에 입력한다.
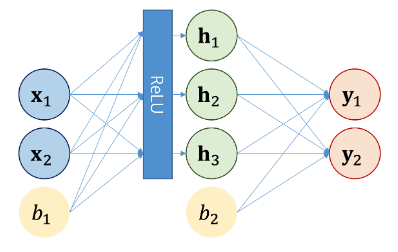
뉴런들의 계산과정은 선형계층의 연산과 동일하게 된다. - Add : 잔차연결 (residual connection, skip connection)
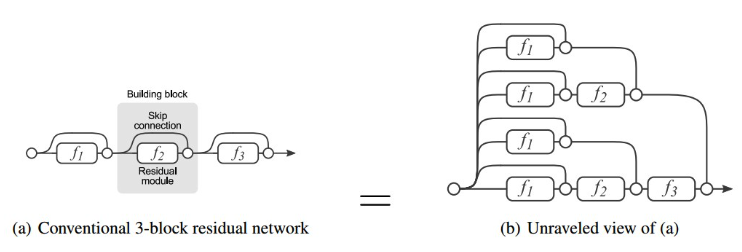
잔차 연결은 동일한 블록 계산이 계속될 때 효과가 있다. 모델이 다양한 관점에서 블록 계산을 수행하게 된다는 말이다. 딥러닝 모델에서 레이어가 많아지면 학습이 어려워 지는 경향이 있다(그래디언트 경로 증가). 잔차 연결은 모델 중간에 블록을 건너 뛰는 경로를 설정함으로써 학습을 용이하게 하는 효과가 있다.
- Norm(레이어 정규화, layer normalization) : 미니 배치의 인스턴스(x)별로 평균을 빼주고 표준편차로 나눠줘 정규화(normalization)을 수행하는 기법이다. 레이어 정규화는 학습이 안정되게 만들며 속도가 빨라지는 효과가 있다.
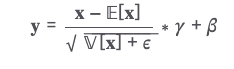
베타와 감마는 학습 과정에서 업데이트되는 가중치이며, 입실론은 분모가 0이 되는 것을 방지해주기 위해 더해주는 고정값(주로 1e-5설정)이다.
레이어 정규화는 미니배치의 인스턴스별로 수행한다. - 배치 크기가 3이면 3개에 대한 평균 분산을 구한 후 위의 식에 적용.
