AI의 핵심 목표 중 하나는 인간의 의도에 맞춰 멀티모달 비전 및 언어 명령을 효과적으로 따를 수 있는 범용적인 어시스턴트를 개발하는 것
범용 비전 어시스턴트를 구축하기 위해 instruction-tuning을 언어-이미지 멀티모달 공간으로 확장하려는 첫 번째 시도인 visual instruction-tuning을 제시
과제는 비전-언어 명령에 따른 데이터가 부족하다는 것 → ChatGPT/GPT-4를 사용하여 이미지-텍스트 쌍을 instruction-following 형식으로 변환하는 데이터 재구성 관점과 파이프라인을 제시
CLIP의 open-set 비전 인코더를 언어 디코더 Vicuna와 연결하고 생성된 데이터에 대해 end-to-end로 fine-tuning하여 large multimodal model (LMM)인 LLaVA (Large Language and Vision Assistant)를 개발
다양한 쌍의 이미지, 명령, 자세한 주석을 선택하여 새로운 벤치마크인 LLaVA-Bench 를 제시한다.
Related Work
Instruction Tuning: FLAN 이란 논문에서 제안한 방식으로, 사람의 지시에 따른 답변의 형태로 말할 수 있도록 학습하는 방법. few-shot을 통해 응답을 받을 필요 없이 Zero-shot learning이 가능하다.
장점
Language Model의 zero-shot 성능을 크게 올릴 수 있다.
Unseen Task 까지 일반화 할 수 있다.
단점
Hallucination, Cost, Preference Mismatch
GPT-assisted Visual Instruction Data Generation

저자들은 널리 존재하는 이미지 쌍 데이터를 기반으로 하는 멀티모달 instruction-following 데이터 수집을 위해 ChatGPT/GPT-4를 활용할 것을 제안. (하지만 chatGPT, GPT-4 가 visual content를 인지할 수 없는 문제를 해결해야함. → symbolic representations 라는 방법론 사용해서 해결함)
symbolic representations
(Language Only Model이 인지할 수 있는 형태로 만들기 위해 캡션과 이에대한 설명이 존재하는 COCO데이터셋을 사용.) 이미지 와 관련 캡션 에 대하여 어시스턴트에게 이미지를 설명하도록 지시할 의도로 일련의 질문 를 만든다. GPT-4 or chatgpt를 teacher모델로 활용해 시각적 콘텐츠가 포함된 instruction-following데이터를 생성한다. 특히 이미지를 시각적 feature로 인코딩하기 위해 두 가지 유형의 표현을 사용한다.
- 캡션. 일반적으로 다양한 관점에서 장면을 설명한다.
- bounding box. 일반적으로 장면의 물체를 localize하고 각 box는 물체의 개념과 공간 위치를 인코딩해 Language Only Model의 input으로 들어간다.
이 표현들을 통해 이미지를 LLM이 인식 가능한 시퀀스로 인코딩할 수 있다. COCO이미지를 사용하여 다음 세가지 유형의 Insturction-following데이터를 생성한다.
Instruction Following Dataset Construction
- Conversation. (”Ask diverse questions and give corresponding answers.”)저자들은 어이스턴트와 사진에 대해 질문하는 사람 사이의 대화를 디자인한다. 답변은 마치 어시스턴트가 이미지를 보고 질문에 답하는 듯한 톤으로 되어 있다. 물체 유형, 갯수, 동작, 위치, 상대적 위치를 포함해 이미지의 시각적 내용에 대해 다양한 질문이 제기된다. 확실한 답이 있는 질문만 고려된다.
- Detailed description. 이미지에 대한 풍부하고 포괄적인 설명을 포함하기 위해 저자들은 질문 목록을 만들었다. 각 이미지에 대하여 목록에서 하나의 질문을 무작위로 샘플링하여 GPT-4에 자세한 설명을 생성하도록 요청한다.
- Complex reasoning. (”Create complex questions beyond describing the scene.”)위 두 가지 유형은 시각적 콘텐츠 자체에 중점을 둔다. 저자들은 이를 기반으로 심층적인 추론 질문을 만들었다. 답변에는 일반적으로 엄격한 논리를 따르는 단계적 추론 프로세스가 필요하다.
저자들은 세가지 유형들에 대해 각각 5.8만, 2.3만, 7.7만 개, 총 15.8만 개의 고유한 언어-이미지 instruction-following 샘플을 수집하였다.
Visual Instruction Tuning
Architecture
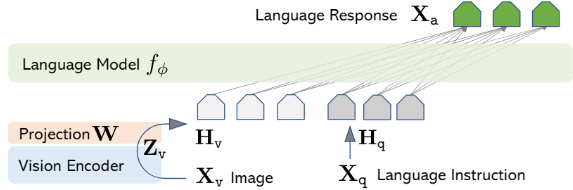
주요 목표는 사전학습된 LLM과 시각적 모델의 feature를 효과적으로 활용하는 것이다. 저자는 vicuna 모델을 LLM으로 사용한다. 이미지 입력 는 CLIP 비전 인코더 ViT-L/14 로 visual feature 를 생성한다. 마지막으로 transformer 레이어 전후의 grid feature가 사용된다. 이미지 feature를 단어 임베딩 공간에 연결하기 위해 간단한 projection matrix ( ) 를 사용해 를 언어모델의 단어 임베딩 공간과 동일한 차원을 갖는 로 변환한다.
Training

각 이미지에 대해 multi-turn 대화 데이터를 생성한다. 여기서 T는 총 턴수이다. Conversation 답변을 Assistant의 답변으로 간주한다.
이는 일관된 형태로 Multimodal Instruction-Following Sequence 형성할 수 있다.
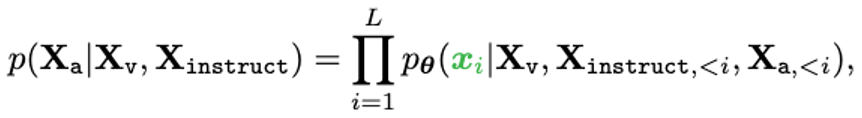
Sequence의 길이가 L일 때, 정답 X_a 에 대한 확률은 위와같이 계산한다. AR Model에서 초록색 부분의 Sequence Tokens만 Loss계산에 사용한다.
Step1: Pre-training
LLava Model Training을 위해, 두 단계의 Instruction-Tuning 절차를 거친다.
Feature Alignment를 위한 Pre-Training: CC3M Dataset을 595,000개의 Image-Text 쌍으로 필터링, Dataset 생성 방법론에 따라 Instruction-Following Dataset으로 변환한다. Image에 대한 간단한 요약을 요청하는 질문 설정을 하고 Ground-Truth Prediction 은 그림의 원래 Caption으로 설정한다.
Pre-Traiing시에는 Visual Encoder와 LLM의 파라미터는 Freeze시키고 Projection Matrix만을 이용하여 학습 진행. → Image feature와 Pre-trained LLM 을 alignment시키는 과정
Step2: Fine-tuning
Visual encoder는 Freeze 시키고, Projection과 LLM 파라미터 업데이트.
앞서 생성한 158K개의 Language-Image Instruction-Following Dataset을 기반으로 Fine-tuning 수행
Science QA 데이터는 과학 관련 내용의 질문과 답변이 있는 Dataset.
Image 혹은 자연어 question을 input으로 받아서 reasoning 과 answer부분을 생성하는 학습을 진행.
동일하게 Visual encoder는 Freeze 시키고, Projection과 LLM 파라미터 업데이트.
Experiment
Llavabenc는 이미지를 바탕으로 Text-Only GPT-4 의 답변을 Ground-Truth로 설정
평가 모델로부터 응답의 종합적인 평가 결과 점수를 제공받음
특히 complex reasoning 부분에서 우수한 성능이 나옴
ScienceQA의 경우
LLaVA 모델만 이용한 결과 SoTA에 근접한 성능이 나온다.
GPT4와 LLaVA 가 서로다른 답변이 나온 경우 GPT-4에게 다시 답변에 대한 평가를 받는 경우 좋은 성능이 나옴.
