4. Loss(손실 계산)
- torch.nn.[다양한 Loss Function]
- ex) L1loss, MSELoss, CrossEntropyLoss, BCELoss...
- Loss는 어디서 생기나?
input(입력) = x
output(출력) = y
label(정답) = d
우리는 입력과 정답만을 가지고 있다.
모델은 입력을 받아서 출력을 만든다.
y = Wx + b
우리는 d-y가 0이길 희망한다.
d-y != 0이면 문제가 있다고 봐도 되겠군요? => Error(=Loss) - Error(=Loss)를 어떻게 계산?
| Type(문제의 유형) | 출력층에 쓰이는 활성화 함수 | Error Function(=Loss Function) |
|---|---|---|
| 회귀(Regression) | 항등사항(=나오는대로 쓴다) | 제곱오차(Squared Error) |
| 이진분류(Binary Classification) | Logistic Function | BCELoss |
| 다 클래스 분류(Multi class Classfication) | Softmax Function | CrossEntropy |
*softmax: 출력이 10개 나오면 출력의 합이 1이 되도록 만들어줌 -> cross-entropy 계산
5. Back propagation(역전파)
- Gradient Descent Method(경사하강법): w가 w1일 때, E(w)가 E(w1)이다. wk일 때, E(w)가 최소값이다.
- dE = dE/dw
- w(t+1) = w(t) - αdE(n) (α: 기울기에서 얼만큼 뛸건지, learning rate)
- w는 Error을 최소화하는 방향으로 간다.
6. Update
- 신경망을 구성하는 parameter<weight, bias 등>의 업데이트
- torch.optim.[다양한 optimizer]
- ex) Adagrad, Adam, RMSprop, SGD...
순서
- Import~~~(import torch, torch.nn, torchvision)
- Dataset 만들기(torchvision, torch.utils.data.Dataset)
- Model 만들기(class MyNetwork(nn.Module):~~)//지난 시간
- Optim과 loss계산 함수 결정하기
- 학습을 위한 반복문 작성하기
- 평가 //이번 시간
및 모델 저장//다음 시간
[example]
-
Loss function -> CrossEntropyLoss
class torch.nn.CrossEntropyLoss(weight=None, size_average=True. ignore_index=-100, reduce=True) -
Optimizer -> SGD
-
📌params(=my_model.parameters(): class my_model(nn.Module): def init(self) 여기서 선언된 parameters을 넣어줘야함
class torch.optim.SGD(params, lr=<object object>, momentum=0, dampening=0, weight_decay=0, nesterov=False) -
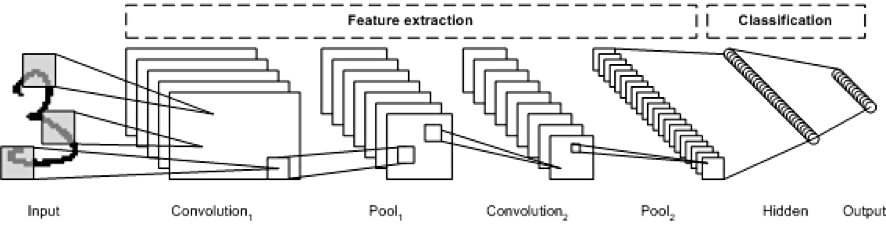
CNN 예시
CNN 용어 정리
[Convolutional Neural Network]
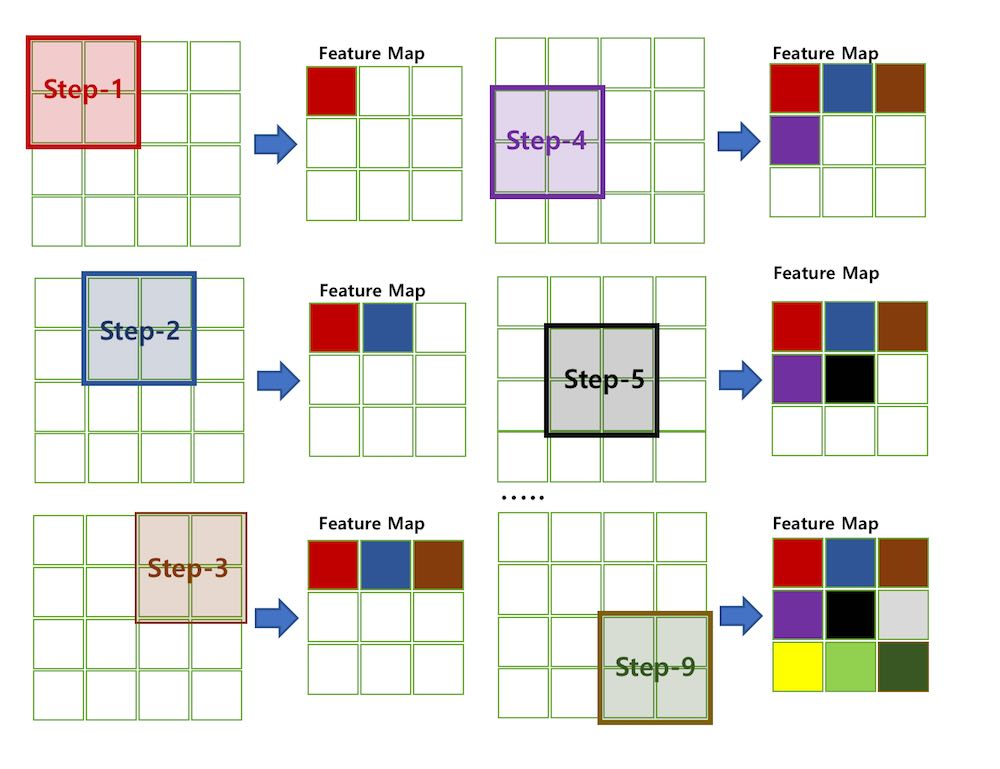
[필터 순회와 합성곱(Convolution) 계산]
💡 Convolutional Layer: 입력 데이터로부터 중요한 정보를 추출해내는 필터의 역할을 수행
💡 n개의 filter = n개의 channel
💡 Feature Map:Convolutional Layer의 입력 데이터를필터가 순회하며 합성곱을 통해서 만든 출력, 즉 합성곱 계산으로 만들어진 행렬
💡 Activation Map: Feature Map 행렬에 활성 함수를 적용한 결과, 즉 최종 Convolutional Layer의 최종 출력 결과
💡 Stride: 필터를 순회하는 간격, 즉 몇 칸씩 필터를 이동시키면서 합성곱을 계산하는지
💡 Padding: 입력 데이터의 외각에 지정된 pixel만큼 특정 값(0)으로 채워 넣는 것, convolutional layer의 출력 데이터가 줄어드는 것을 방지
💡 Pooling Layer: Convolutional Layer의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄이거나 특정 데이터를 강조하는 용도, Max/Average/Min Pooling이 있음.
💡 Flatten Layer: CNN의 데이터 타입을 Fully Connected Neural Network의 형태로 변경하는 레이어. 파리미터가 따로 존재하지 않고, 입력 데이터의 Shape 변경만을 수행
💡 fully connected layer: 모든 뉴런들이 연결되어 있는 형태, 모든 뉴런들이 연결되어 있기 때문에 뉴런의 수가 증가할수록 뉴런을 연결하는 시냅스(가중치, weight)가 증가, affine layer 형태(=벡터(행렬)의 내적 형태), Convolutional Layer에서 추출된 특징 벡터를 FC Layer의 입력으로 사용하여 분류를 진행. 비선형 공간에서의 분류를 수행할 수 있게 됨.
1) 2차원 배열 형태의 이미지를 1차원 배열로 flatten(평탄화)
2) 활성화 함수(Relu, Leaky Relu, Tanh 등)로 뉴런을 활성화
3) 분류기(Softmax)함수로 분류
optim = torch.optim.SGD(Net.parameters(), lr=0.001, momentum=0.9, loss_function=nn.CrossEntropyLoss())
for epoch in range(num_epoch):
for i, data in enumerate(train_loader, 0):
optim.zero_grad() #network가 가지고 있는 params는 각자의 gradient값을 가지고 있음, 학습 시작 전 gradient값을 0으로 초기화
input, labels = data
input, labels = Variable(input.cuda()), Variable(labels.cuda())
out = Net(input)
loss = loss_function(out, labels) #loss 계산
loss.backward() #각 params가 gradient값을 가지게됨
optim.step() #params 값을 가지고 weight를 update[example2]
class my_network(nn.Module):
def __init__(self):
super(my_network, self)__init__()
self.conv1 = nn.Conv2d(3,64,5) #5:kernel_size(filter_size)
self.conv2 = nn.Conv2d(64,30,5)
self.fc1 = nn.Linear(30*5*5, 128) #30*5*5 이미지(=최종 Activation Map)를 flatten시켜 128개의 fully connected layer로 out
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.conv1(x), inplace=True)
x = F.max_pool2d(x, (2,2))
x = F.relu(self.conv2(x), inplace=True)
x = F.max_pool2d(x, (2,2))
x = x.view(x.shape[0], -1)
x = F.relu(self.fc1(x), inplace=True)
x = F.relu(self.fc2(x), inplace=True)
return x