<목차>
1. Conventional ASR
2. End-to-end ASR
2.1) Explicit Alignment
(1) CTC
(2) RNN-T
(3) RNA
2.2) Implicit Alignment
- AED
2.3) Pros and Cons
- Solution
[Shinji Watanabe et al., 2017]Hybrid CTC/Attention Architecture for End-to-end Speech Recognition, Shinji Watanabe, Senior Member, IEEE, Takaaki Hori, Senior Member, IEEE, Suyoun Kim, Student Member, IEEE, John R. Hershey, Senior Member, IEEE, and Tomoki Hayashi, Student Member, IEEE, 2017
1. Conventional ASR
All ASR models aime to elucidate the posterior distribution, , of a word sequence, W, given a speech feature sequence X. End-to-end methods directly carry this out wheras conventional models factorize into modules such as the language model, , which can be trained on pure language data, and an acoustic model likelihood, , which is trained on acoustic data with the corresponding language labels.
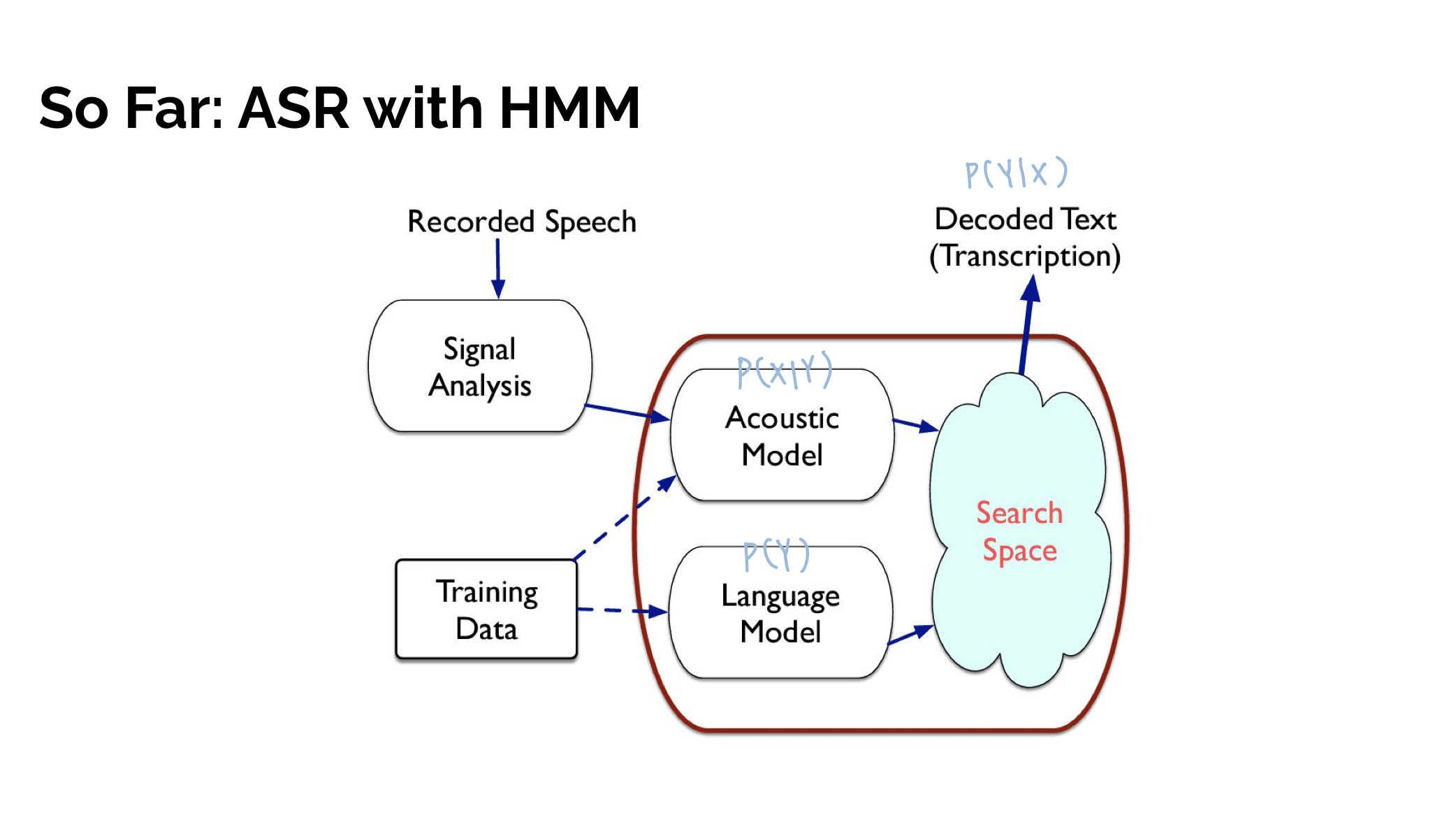

HMM/DNN
: T-length speech feature sequence
: N - length word sequence
여기서 는 D-dimensional speech feature vector at time frame t이고, 은 a word at position n in the Vocabualry, V이다.
ASR에서는 HMM을 이용해 X가 input으로 들어왔을 때 the most probable word sequence, 을 찾고자 한다.
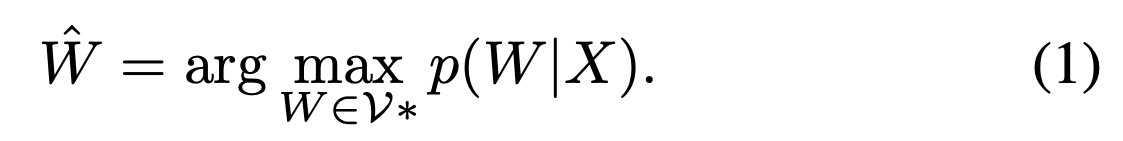
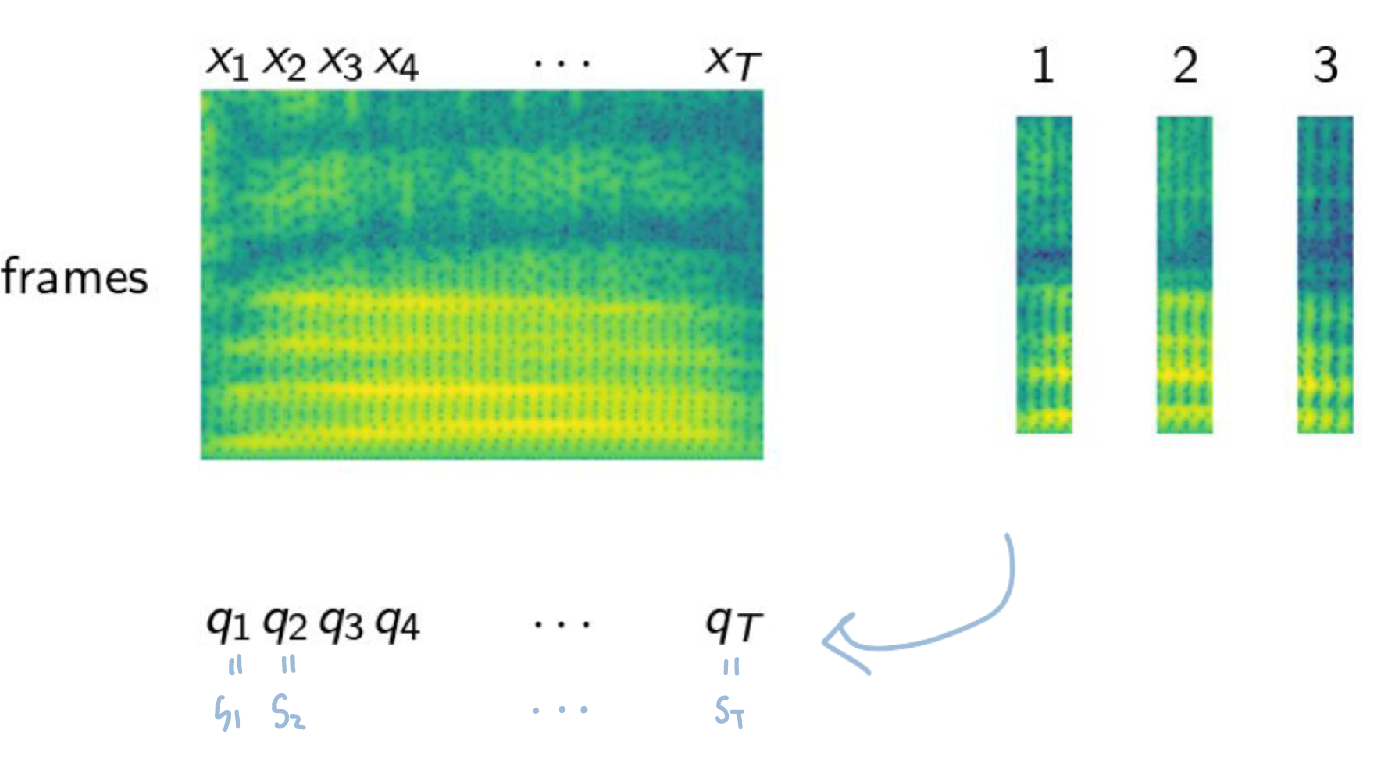
posterior 을 찾기 위해서 HMM은 관측치 X뒤에 숨어있는 hidden state S(possible phone states)에 대해서 주목한다.
Posterior = Prior * Likelihood Bayesian Theorem에 따라 을 구하는 공식은 다음과 같다.

2. End-to-end
Alignment
We define multimodal alignment as finding relationships and correspondences between sub-components of instances from two or more modalities.
음성 인식 모델을 학습하려면 음성(feature) frame 각각에 label 정보가 있어야 한다. 음성 frame 각각이 어떤 음소인지 정답이 주어져 있어야 한다는 것이다. MFCC 같은 음성 feature는 짧은 시간 단위(대게 25ms)로 잘게 쪼개서 만들게 되는데, 음성 frame 각각에 label(음소)을 직접 달아줘야 하기 때문에 다량의 labeling을 해야하고(고비용) 인간은 이같이 짧은 구간의 음성을 분간하기 어려워 labeling 정확도가 떨어진다.
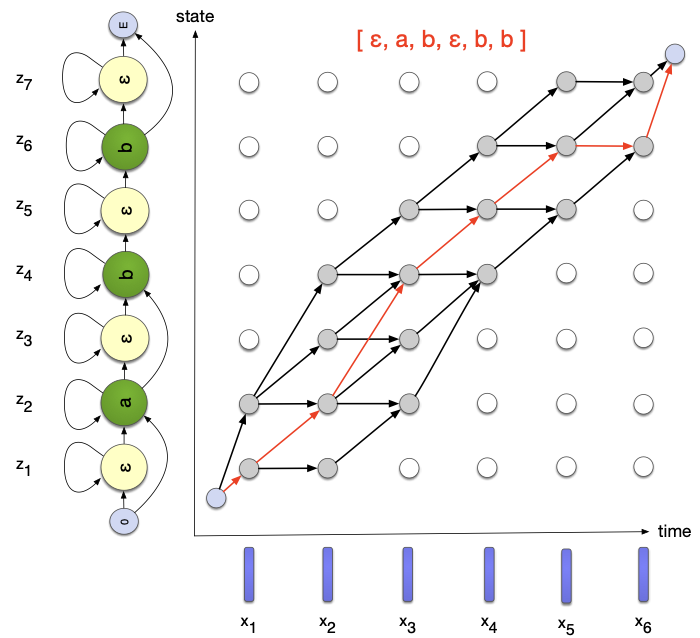
하지만 CTC와 같은 End-to-end ASR에서 사용되는 Explicit Alignment는 입력 음성 frame sequence와 타켓 단어/음소 sequence 간에 명시적인 alignment 정보 없이도 음성 인식 모델을 학습할 수 있도록 고안되었다. 다시 말해 입력 frame 각각에 label을 달아놓지 않아도 음성 인식 모델을 학습할 수 있다는 것이다.
CTC(Explicit Alignment)는 additional blank를 도입하여 이를 가능하게 하였다.
A common feature of all explicit alignment models is that they introduce an additional blank symbol, denoted <\b>, and define an output probability distribution over symbols in the set {<\b>}. The interpretation of the <\b> symbol varies slightly between each of these models.

Explicit Alignment
- 명백하게(explicitly) 표현되는 lattice paths로 characters alignment를 찾을 수 있다.
- 여기서 명백하게란 음성 프레임과 charcter label간의 명시적인 관계를 표현한다는 뜻이 아니다. - CTC doesn't find a single alignment: it sums over all possible alignments
Implicit Alignment = Attention-based Model
- Directly predicts output subwords, just one possible alignments
- No explicit alignment like CTC: attention probabilities are interpreted as "soft" alignments
1) Explicit Alignment E2E Approaches
The neural network used to generate encoder features H(X) can produce encoded frames based on only the sequence of previous acousitc features with limited look-ahead, then the models can output hypotheses as speech is input to the system.
즉, t시점까지 얻을 수 있는 previous information만을 가지고 output_t를 예측한다.
(1) CTC(Connetionist Temporal Classfication)
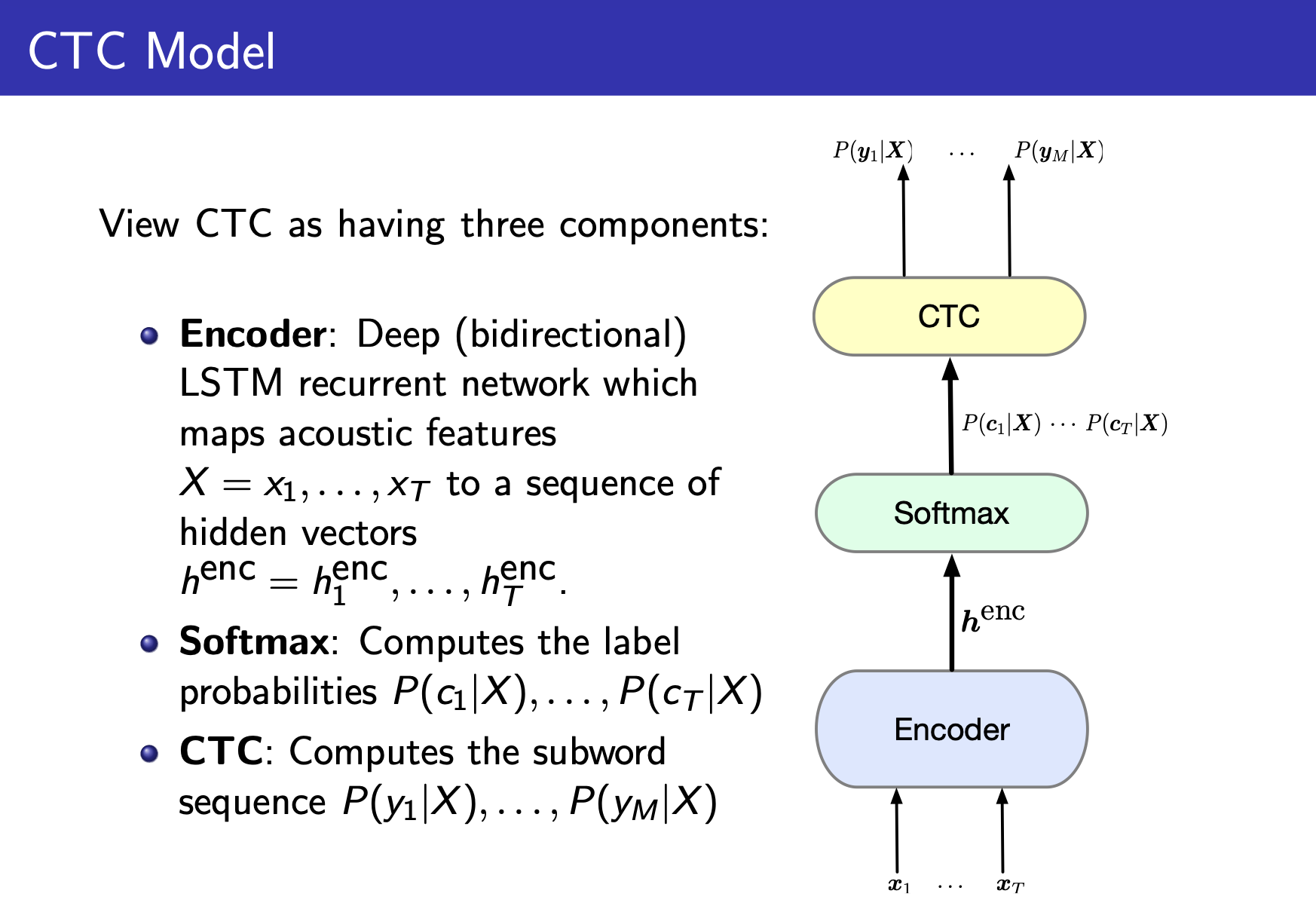
CTC like models
(2) RNN-T(Recurrent Neural Network Transducer)

(3) RNA(Recurrent Neural Aligner)

2) Implicit Alignment E2E Approaches
The model learns a correspondence between the entire acousitc sequence and the individual labels.
Implicit Alignment는 t=1번째 output을 구할 때도 전체 input data을 동시에 고려하여 input data 자체에 내재된 context를 반영하여 output(alignment)을 구하고자 한다.
이러한 점 때문에, streaming이 불가능하다. 왜냐하면 The models must process all acoustic frames before they can generate any output hypotheses.
AED(Attention-based Encoder-Decoder)
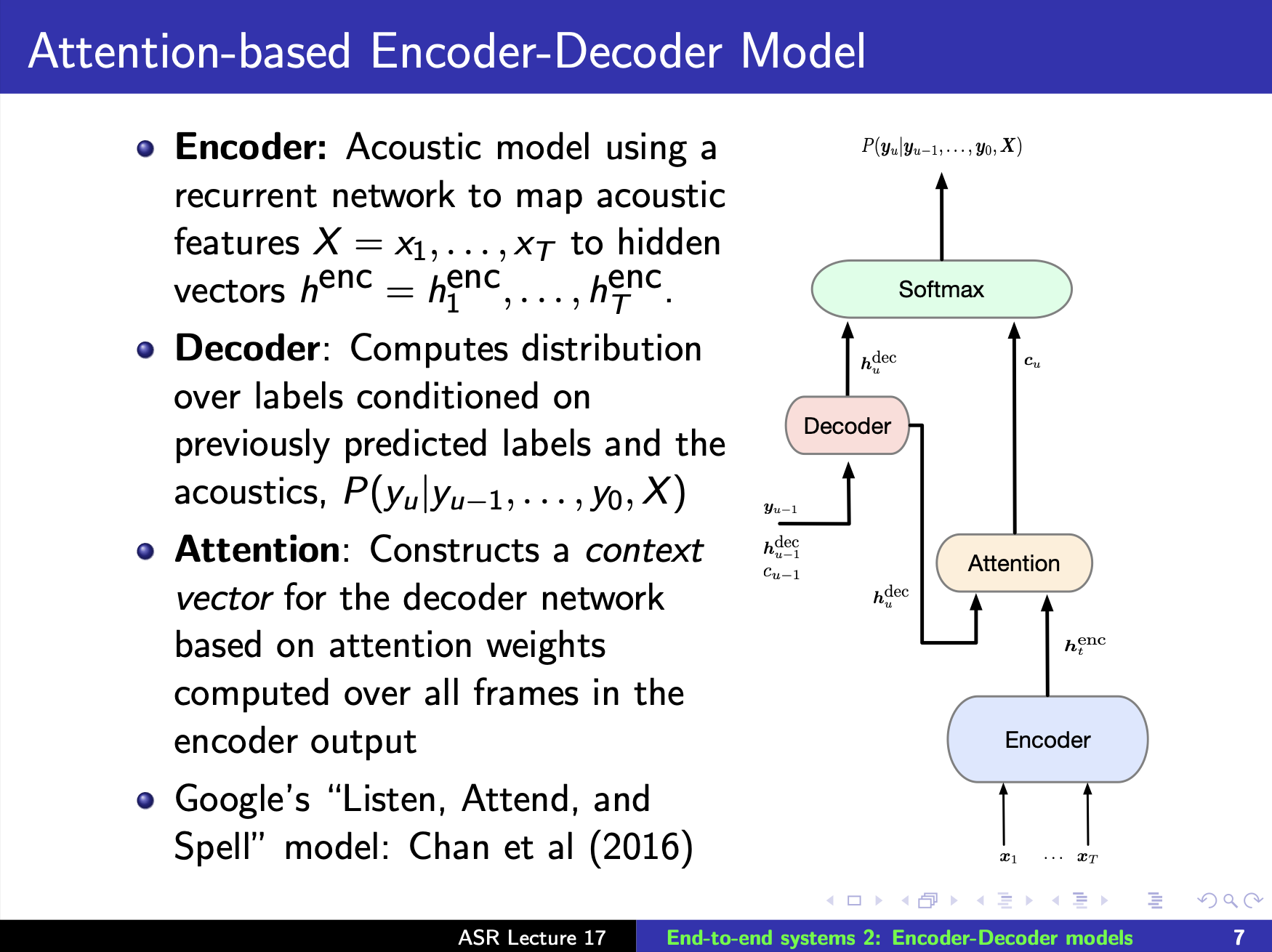
Attention Distribution
1) : a state vector, which summarizes the previously decoded symobols, .
2) : a context vector, which summarizes the encoder output based on the decoder state.
The weight of represents the relevance of a particular encoded frame when outputting the next symbol , after the model has already output symbols .
즉, 는 the current decoder hidden state 와 the sequence of encoder hidden states 와의 similarity를 weights로 나타낸 것이다.
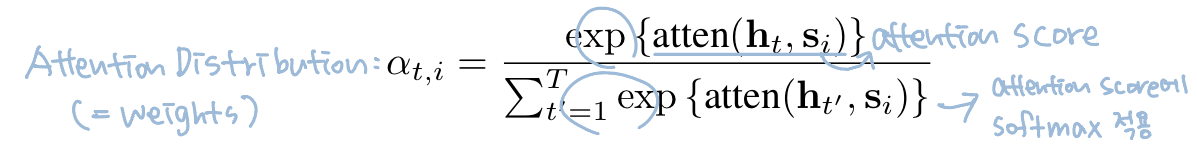
i시점에서의 output을 구하고자 할 때, 계산된 weights를 input sequence에 적용해 이전 output과 가장 similarity가 높은 input을 attention해서 context vector 를 구해준다.

3) Pros and Cons
(1) CTC
Pros
- End-to-end training with sum over alignments
- Monotonic constraints in alignments
📌monotonic: left-to-right, no reodering (unlike translation)
Cons
- Conditional independence of output labels
- External LM: not entirely end-to-end anymore
(2) Attention-based Model
Cons
- Attention is very flexible-does not constrain relationship between acoustics and labels to monotonic
- more problematic when huge amounts of training data not available
Solution
- Windowed attention: attention is restricted to a set of encoder hidden states
- Hybrid CTC/Attention model: use CTC and attention jointly during training and recognition-regularizes the system to favor monotonic alignments
<참고>
-
[Shinji Watanabe et al., 2017]Hybrid CTC/Attention Architecture for End-to-end Speech Recognition, Shinji Watanabe, Senior Member, IEEE, Takaaki Hori, Senior Member, IEEE, Suyoun Kim, Student Member, IEEE, John R. Hershey, Senior Member, IEEE, and Tomoki Hayashi, Student Member, IEEE, 2017
-
https://www.inf.ed.ac.uk/teaching/courses/asr/2022-23/asr17-e2e.pdf
-
음성인식과 합성.2023
