Speech Recognition

Speech Recognition 과정에 대해서 다시 살펴보자. 우선 Speech Recognition model의 목표는 observed된 에서 를 찾는 것이다. 그렇다면 이 model은 어떻게 Training 시켰었는가? Speech Recognition을 하기 위해 학습시켜야 하는 두 가지 모델이 있다.
1. GMM
각 state 의 GMM의 parameters 학습(추정)하는 과정이다. 앞에서 배웠던 EM Algorithms을 활용할 수 있다.
2. HMM
Acoustic signal과 Text(graphem -> phoneme)를 가지고 HMM parameters인 A(transition prob), B(emission prob)를 학습시킬 수 있다.
이것이 바로 Acoustic Model의 역할이라고 할 수 있다.
Speech Synthesis
Speech Synthesis는 정반대로 Acoustic Model(HMM-GMM)을 가지고 주어진 에서 를 만들어내는 것이라고 할 수 있다.
(: 사람의 acoustic signal, : states - parts of a phone, diphone, or triphone)

(Each state is associated with an N-dimensional Gaussian mixture model)
Speech Synthesis에서 사용되는 Acoustic Model인 Statistical Parametric Synthesis도 비슷한 과정으로 학습된다. 즉, HMM-GMM을 이용한다.
1. SPSS system

Figure1: A schematic view of an SPSS system
The classical approach to SPSS is based on a combination of a hidden-Markov model Gaussian mixture model (HMM-GMM) architecture for feature generation and a vocoder for waveform generation.
1.1. Text Analysis
1.2. Acoustic Model = Feature Generation
1.3. Vocoder = Waveform Generation
2. SPSS system training
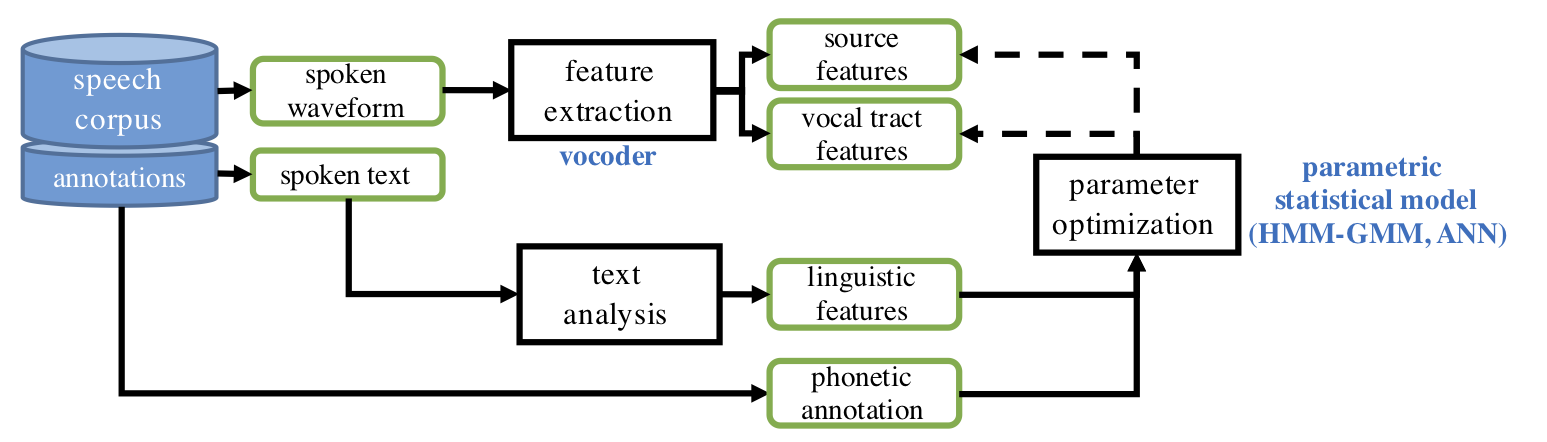
Figure2: A schematic view of SPSS system training

3. Advantages of the HMM-GMM SPSS compared to concatenative systhesis
Since the “instructions” for speech generation are encoded by parameters of the SPSS model, the model can easily be adapted to produce speech with different characteristics. For instance, the vocal tract characteristics of the training speaker are encoded by the means and variances of the Gaussian distributions in each HMM state whereas durational characteristics are encoded by the transition probabilty matrix of the HMM. Therefore, the system can be adapted to other speakers by simply adapting the pre-trained HMM-GMM using speech from a new talkers.
