and are the input speech and output senone at time t, respectively. T is the number of speech frames in an utterance, and N is the number of senones in the network ouput layer.
[Bell et al.,2021] Adaptation Algorithms for Neural Network-Based Speech Recognition: An Overview
논문 읽다가 중요해 보이는데 모르는 단어가 나옴. "senone"...
input speech data 를 Acoustic model에 넣어서 output 를 얻는다고 하는 것을 보면 senone은 predicted ouput phone을 의미하는 것 같은데, 왜 phone이라는 단어를 안쓰고 senone이라고 할까? 그 이유는 다음과 같았다.
"Senones" means states of the HMM or context-depended units.
Phone이라는 것은
In phonetics and linguistics, the word phone may refer to any speech sound or gesture considered as a physical event without regard to its place in the phonology of a language.
However, in Speech Recognition, we often include some context about neighboring phones when modelling a certain phone. This means that our system not only knows phones for A, B and so on, but instead has a concept for E-then-A, O-then-B, X-then-A and so on.
즉, phone은 언어학에서 독립적인 음성 unit을 뜻하는 것이지만 senone은 Acoustic model을 통해서 만들어진(예측된), 주변에 나타난 phone에 의미가 함께 내포된, context dependent한, 음성 unit을 뜻한다.
Acoustic Model
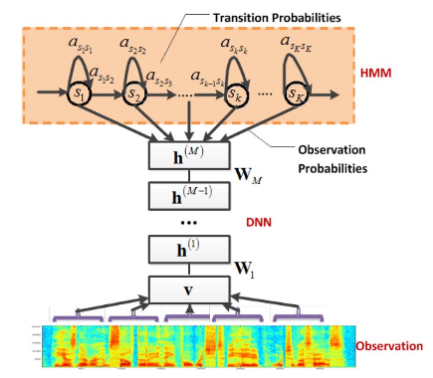
In this architecture the DNN is used to transform the noise into phones.
The last layer of the DNN is formed by all the possibles phones, having one output neuron per phone. The activation of these neurons is the probability of that the input noise corresponding to that phone.
The combination of these activations is the input of the Hidden Markov Model and establishes the senones of the HMM, which obtains a list of candidate texts by means of a dictionary.
