ASR의 최신 모델 architecture을 살펴보면 self-supervised된 pre-trained wav2vec2.0, whisper로 음성 데이터의 feature를 extract하고 여기에 CTC와 seq2seq 로 unsegmented data를 labelling 해주는 구조로 이루어져있다.
ASR이란 음성 데이터를 text로 transcribe해주는 것을 말한다.
wav2vec2.0 + CTC 논문 흐름 ~>
whisper + seq2seq 논문 흐름 ~>
0. Unsupervised Learning이란?
📌Unsupervised Learning이란?
비지도학습(Unsupervised Learning)이란 지도학습(Supervised Learning)과 달리 정답(label, target)이 없는 데이터를 학습하는 방법을 의미합니다. 모델이 스스로 주어진 데이터셋의 feature와 pattern을 찾아내고 이를 기반으로 스스로 판단할 수 있는 능력을 가지게 됩니다.
Vision 분야에서의 활용방식을 살펴보면,
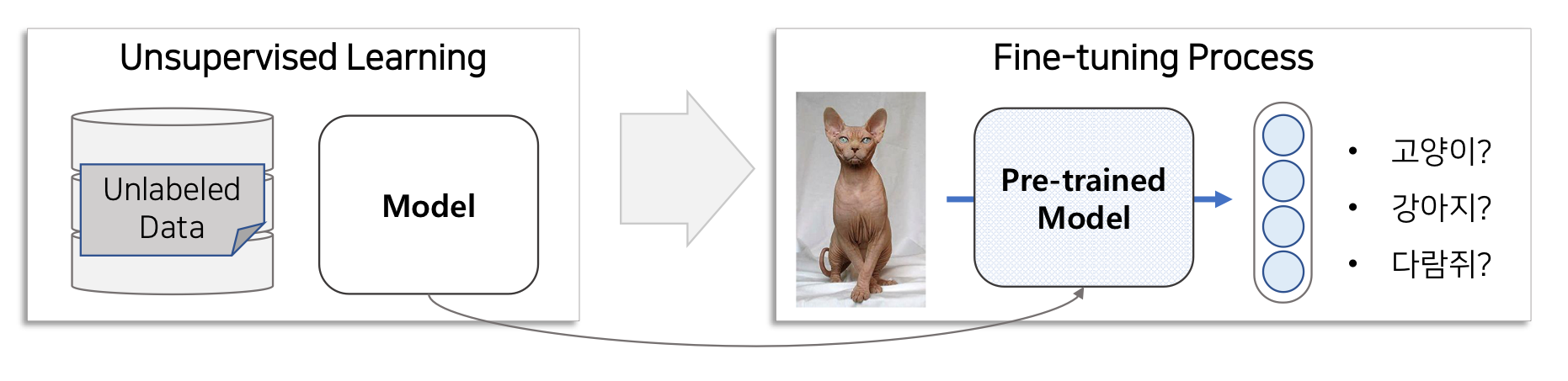 수백만개의 unlabeled된 고양이 사진, 강아진 사진,,을 학습해서 각각의 동물들의 feature와 pattern을 학습합니다. 그리고나서 fine-tunning을 통해 pre-trained model이 찾은 unlabeled feature 그룹에 class를 부여해줍니다. 모델은 이제 이 특성을 가진 동물은 '고양이 이다'라고 판별할 수 있게 됩니다.
수백만개의 unlabeled된 고양이 사진, 강아진 사진,,을 학습해서 각각의 동물들의 feature와 pattern을 학습합니다. 그리고나서 fine-tunning을 통해 pre-trained model이 찾은 unlabeled feature 그룹에 class를 부여해줍니다. 모델은 이제 이 특성을 가진 동물은 '고양이 이다'라고 판별할 수 있게 됩니다.
📌Unsupervised Learning의 목표는 무엇일까요?
feature와 pattern을 잘 찾아내는 것입니다. 즉, Unlabeled Data를 이용하여 좋은 Representation Vector를 생성하는 pre-trained모델을 만드는 것입니다.
📌좋은 Representation Vector는 무엇일까요?
High-Level Information을 의미합니다. High-Level Information은 그림 데이터의 객체정보, 음성데이터의 대화주제, 감성분석 등을 포함합니다. 반대로 Low-Level Information은 데이터의 Detail한 정보인 노이즈 등을 포합합니다.
앞으로 배울 Speech 분야의 예로 자세히 살펴보면 아래와 같습니다.
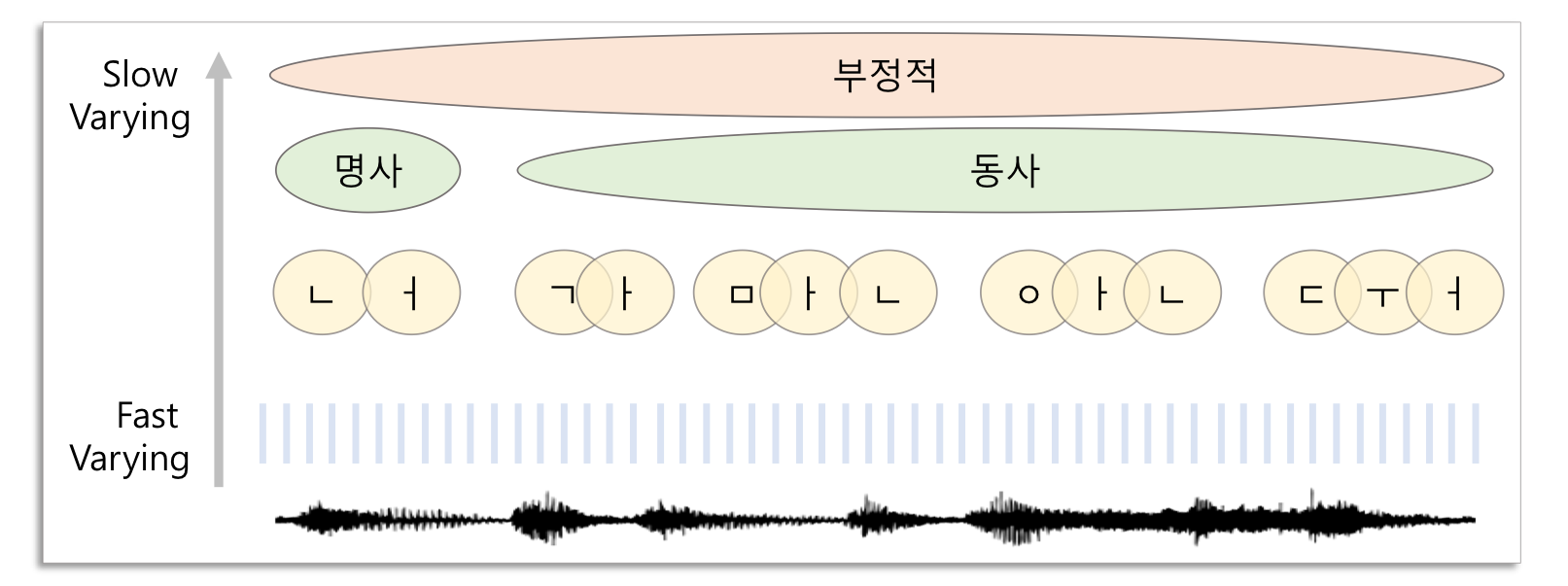
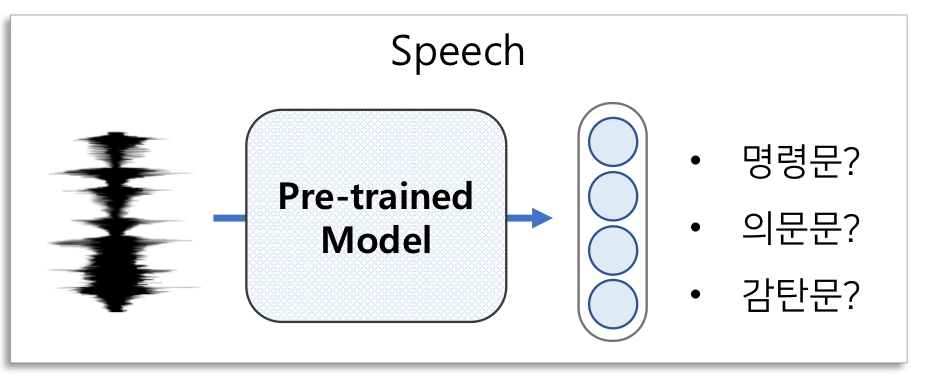
📌Unsupervised Learning 방법이 필요한 이유는?
Target Task의 한정된 Labeled Data 때문에 Supervised 방법론은 한계가 존재합니다. 인터넷에 존재하는 수백, 수천만개의 Unlabeled Data로부터 패턴을 파악하는 Pre-trained 모델을 만들고 Fine-tunning을 해서 사용한다면 Target Task 성능을 크게 향상시킬 수 있습니다. 앞으로의 딥러닝 연구에서 Unsupervised Learning이 가지는 의미는 더욱더 커질 것입니다.
- high demensional vector를 잘 뽑아낸다는 것의 의미는?
- 잘 뽑아낸다면 그것을 원하는 것을 예측(labeling)하는데 어떻게 작용하는가?
- general한 정보는 그 전체 데이터의 의미를 잘 represent한다는 장점도 있지만 모든 데이터의 detail을 담지 못할텐데 어떻게 각각의 데이터마다 labeling할 수 있는 것인가?
1. CPC(Contrastive Prediction Coding)
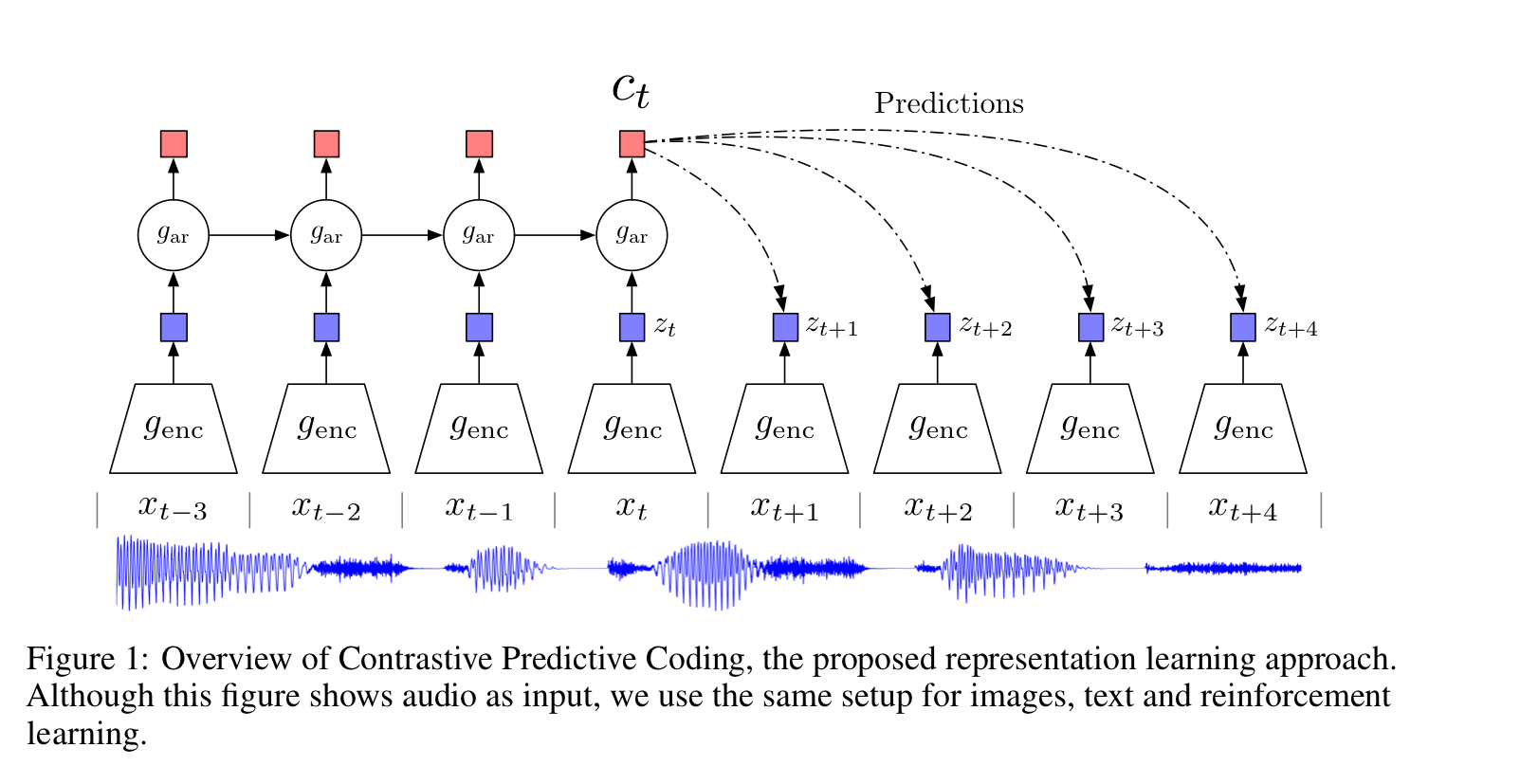
0) Overview
1) What?
high-dimensional 데이터에서 '유용한 Representation Vector'를 추출하기 위한 unsupervised leraning 기법
2) Why?
기존 Unsupervised Learning의 한 방법론인 Direct Predictive Coding은 High-Level Information을 추출하는데 문제점이 많음. 이를 해결한 Unsupervised Learning 방법론인 CPC.
Direct Predictive Coding 문제점
2.1) Cross Entropy, MSE Loss 등을 이용하여 Target 위치(=먼 미래의 시점)의 class를 예측(direct predict).
=> Class에는 매우 적은 정보가 담겨 있기 때문에 비효울적
2.2) 미래의 정보를 예측함으로써 Shared Information에 집중하도록함
=> Shared Information을 추출하는 직접적인 또는 최적의 방법이 아님
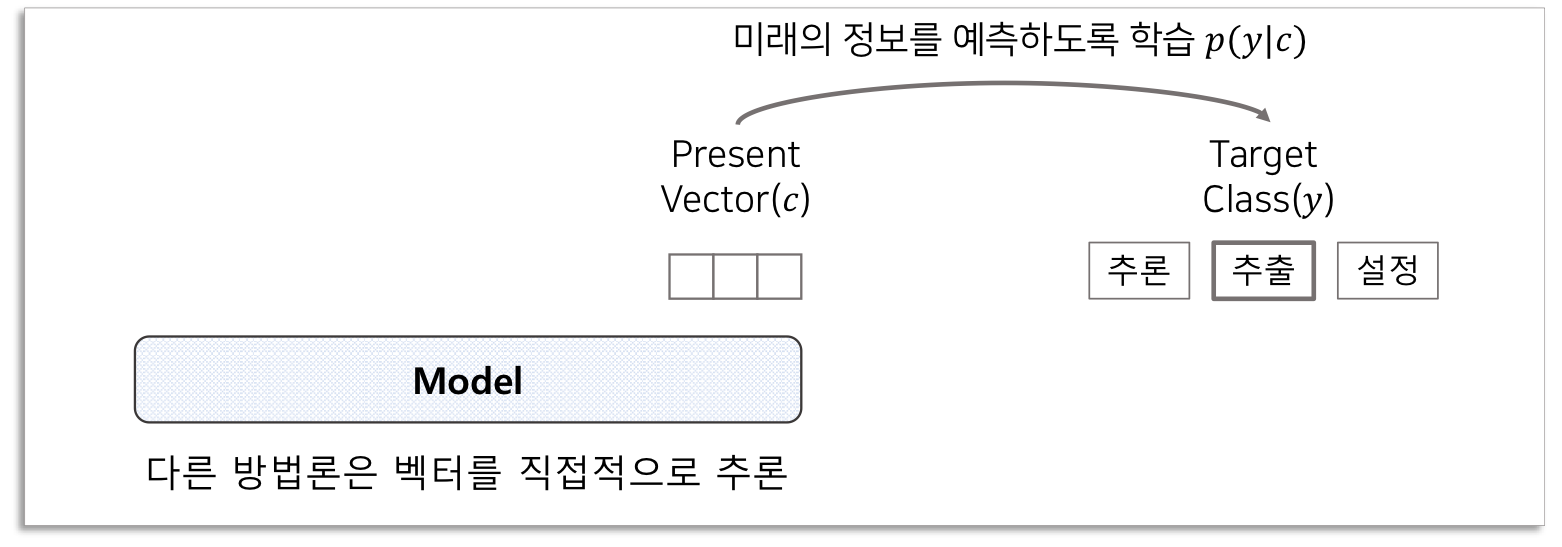
3) How?
'Contrastive Predictive Coding'
3.1) Target위치의 벡터와 다른 위치의 벡터를 비교하는 Contractive 방법을 적용
3.2) Shared Information을 추정하는 함수를 만들고 최대화 하는 Loss를 적용
2) Contrastive Predicting Coding
2.1) Motivation and Intuitions
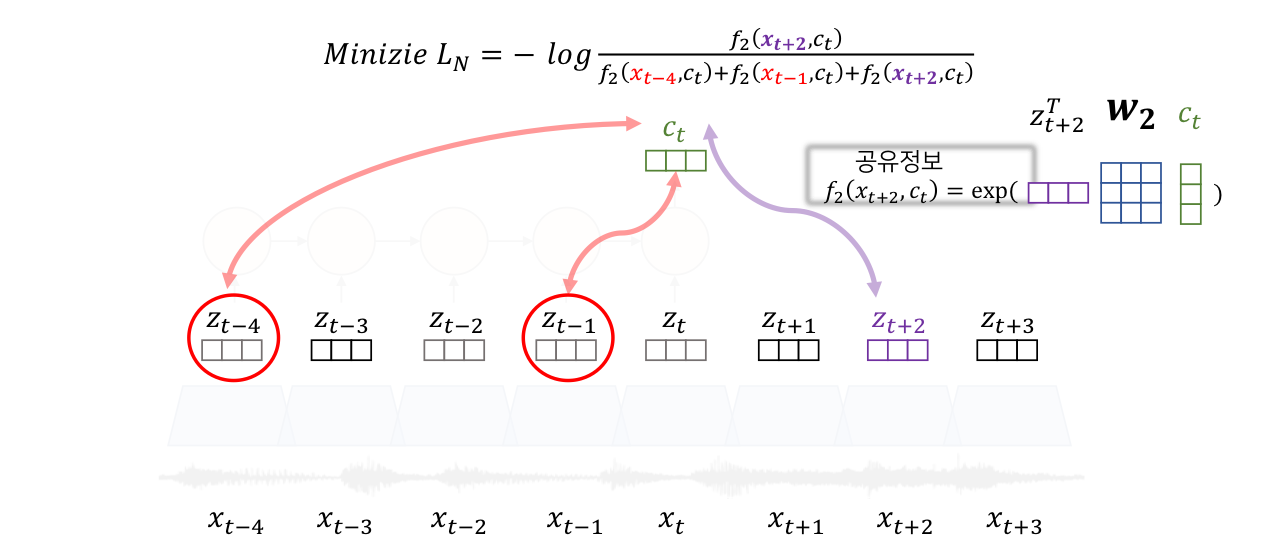
Shared Information(공유정보)
Unsupervised Learning의 목표가 무엇이었나 위에서 다시 살펴보면 결국은 각 데이터의 features를 잘 추출할 수 있는 pre-trained 모델을 만드는 것입니다. 그리고 특히 각 특성벡터들이 High-Level Information을 잘 포함하고 있다면 더 좋겠죠. 여기서는 각 특성벡터들이 공유하는 High-Level Information을 공유정보, Shared Information이라고 합니다.
input data: {}를 -> 특성 벡터(latent vector): {}로 encoding, noise를 제거하고 압축하는 역할
latent space의 현재 시간 t를 포함한 이전의 모든 값들인 에 대해 요약, 이후 context latent representation인 를 생성
와 사이의 mutual information을 보존하는 식을 활용하여
context vector이 공유정보를 잘 담은 vector이 되도록 을 학습시킨다.
2.2) Contractive Predictive Coding**
 다음 중 어떠한 학습이 컴퓨터가 '고양이'의 특성(features)을 배우는데 더 효과적일까?
다음 중 어떠한 학습이 컴퓨터가 '고양이'의 특성(features)을 배우는데 더 효과적일까?
단순히 하나의 클래스를 지정하고 '이 사진 속 동물은 고양이 이다'라고 하는 것과
'이 사진 속 동물은 사자갈기를 뒤집어쓴 고양이와는 비슷한 특성을 공유하고 있고 강아지와는 다르다'라고 가르치는 것 중에 어떠한 방식이 컴퓨터가 고양이 특성을 더 많이 배울 수 있을까요?
비교를 이용한 학습 방식이 더 효율적입니다.
사자갈기를 뒤집어쓴 고양이와 공유하고 있는 특성인 공유정보를 최대한으로 추출하고 강아지가 가진 특성을 최대한 배제하는 것이 학습의 목표입니다.
여기서 '사자갈기를 뒤집어쓴 고양이'가 positive sample이고 '강아지'가 negative sample입니다.
즉, 음성간의 거리(k)차에 따른 공유정보를 유지함으로써 최적의 를 만드는 를 학습시키고자 하는 것입니다.
When predicting future information we instead encode the target x(future) and context c(present) into a compact distributed vector representations (via non-linear learned mappings) in a way that maximally preserves the mutual information of the original signasl x and c.
Q. 라는 데이터 feature를 가지고 라는 class를 예측한다.
저는 이 부분을 배울 때, '왜 도 input data인데 왜 y를 예측하는게 아니라 input data를 예측하는 거지?'하고 잘 이해가 안되었습니다. 앞에서 그렇게 Unsupervised Learning에 대해 배웠는데도 막상 실제로 적용해보니 지금껏 익숙하게 배워왔던 Supervised Learning의 방식인 '데이터()에 따른 정답()을 학습한다'라는 틀에서 쉽게 벗어나기 힘들었기 때문입니다. 하지만 Unsupervised Learning의 학습 목표는 을 가지고 를 예측할 수 있는 모델을 만드는 것입니다. 데이터간의 패턴과 특성을 배우는 것 즉, x데이터 그 자체를 학습하는 것입니다. 따라서 의 정답이 가 아니라 인 것이죠.
k거리 간 공통된 공유정보 =를 잘 추출할 수 있을까?
negative sampling
True의 값을 높이고, False의 값을 낮추는 방식으로 학습시키기
=> 가 잘 학습되었다면,, 이걸로 어떻게 을 연달아 학습시킬 수 있을까?
-> 거리에 따른 공유정보를 잘 유추하도록 학습
-> 데이터에 있는 Shared Information을 잘 추출하여 context vector를 생성할 수 있어야함, 최대한 시점 전체에 대한 공유정보를 생성할 수 있도록 학습
2.3) InfoNCELoss and Mutual Information Estimation
Both the encoder and autoregressive model are trained to jointly optimize a loss based on NCE, which we will call InfoNCE.
4.1) Pretraining: Unlabeled 데이터로 하여 모델()을 학습
4.2) Fine-tuning: Linear Layer를 상단에 추가하고 Labeled Data를 이용하여 Phone Classification 학습
- 장점
-음성 데이터만으로 음성 안에 공유정보를 추출할 수 있는 방법 제시
-음성뿐만 아니라 다양한 Task에 해당 방법론을 적용- 단점
-(속도) Aggregator가 RNN 계열이기 때문에 병렬처리가 안됨.
-(성능) 음성 Task에서 다소 아쉬운 성능을 보였음.
-(실험) 음성만 다룬 논문이 아니므로 음성관련 실험 내용이 부족함.
2. wav2vec
wav2vec은 CPC모델을 음성인식을 위한 용도로 업데이트한 모델이다.
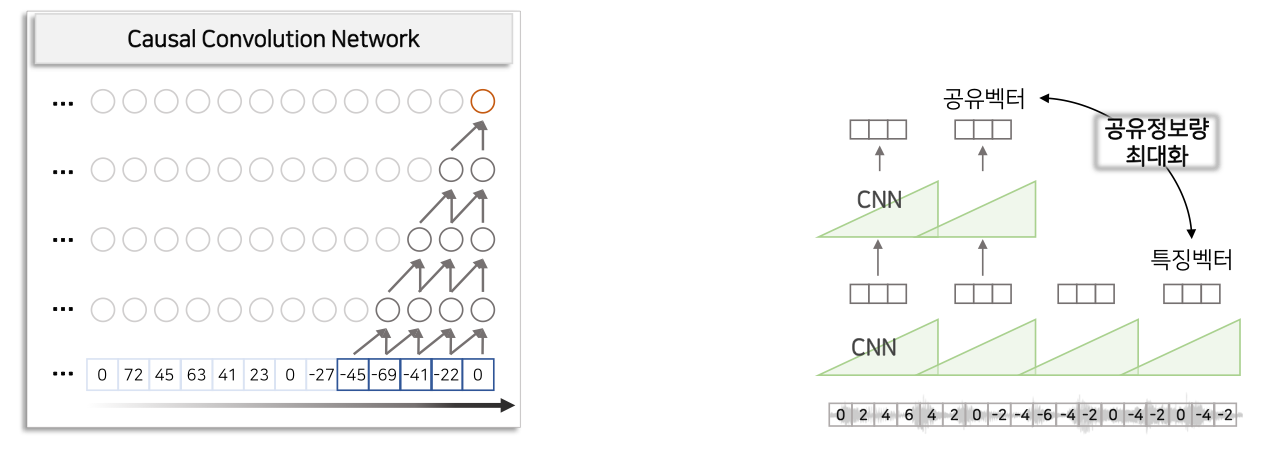
1) What?
-Aggregator 아키텍처를 RNN 계열 모델에서 Casual CNN으로 변경
-Language Model 추가
2) Why?
2.1) (속도)CNN모델은 병렬처리가 가능하기 때문에 RNN보다 빠름
2.2) (성능)Language Model로 이후 나올 단어를 예측 방법 추가
3) How?
3.1) Casual CNN은 특정 시점 이전의 정보만을 참조하여 CNN을 적용한다. 를 만들기 위하여 t이전 시점의 latent vector()을 입력으로 활용
3.2) Acoustic Model + Language Model로 부터 특정 단어가 도출 될 확률을 구해 더해서 가장 높은 확률의 단어 벡터를 선택
3. VQ-wav2vec
1) What?
:Quantization 모듈을 추가하여 BERT의 MLM pre-training을 음성에 도입
2) Why?
: BERT MLM을 통한 Sequence 패턴 학습을 음성에 적용하여 ASR 성능을 향상
3) How?
3.1) VQ-Wav2vec학습 & 이산형 Sequence 추출
3.2) BERT MLM 적용
3.3) Acoustic Model & Language Model 적용
4. wav2vec2.0
MLM + CPC
.
.
.
.
.
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
tokenizer_name_or_path: Optional[str] = field(
default=None,
metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
freeze_feature_encoder: bool = field(
default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
)
attention_dropout: float = field(
default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
)
activation_dropout: float = field(
default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
)
feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
hidden_dropout: float = field(
default=0.0,
metadata={
"help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
},
)
final_dropout: float = field(
default=0.0,
metadata={"help": "The dropout probability for the final projection layer."},
)
mask_time_prob: float = field(
default=0.05,
metadata={
"help": (
"Probability of each feature vector along the time axis to be chosen as the start of the vector"
"span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature"
"vectors will be masked along the time axis."
)
},
)
mask_time_length: int = field(
default=10,
metadata={"help": "Length of vector span to mask along the time axis."},
)
mask_feature_prob: float = field(
default=0.0,
metadata={
"help": (
"Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
" to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
" bins will be masked along the time axis."
)
},
)
mask_feature_length: int = field(
default=10,
metadata={"help": "Length of vector span to mask along the feature axis."},
)
layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
ctc_loss_reduction: Optional[str] = field(
default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
)음성 인식 모델을 학습하려면 음성 프리엠 각각에 레이블 정보가 있어야 한다. 음성 프레임 각각이 어떤 음소인지 정답이 주어져 있어야 한다는 이야기이다. 그런데 MFCC같은 음성 피처는 짧은 시간 단위(대게 25ms)로 잘게 쪼개서 만든다. 음성 프레임 각각에 레이블(음소)을 달아줘야 하기 때문에 다량의 레이블링을 해야하고(고비용) 인간은 이같이 짧은 구간의 음성을 분간하기 어려워 레이블링 정확도가 떨어진다.
CTC는 입력 음성 프레임 시퀀스와 타켓 단어/음소 시퀀스 간에 명시적인 alignment 정보 없이도 음성 인식 모델을 학습할 수 있도록 고안되었다. 다시 말해 입력 프레임 각각에 레이블을 달아놓지 않아도 음성 인식 모델을 학습할 수 있다는 것이다.
