
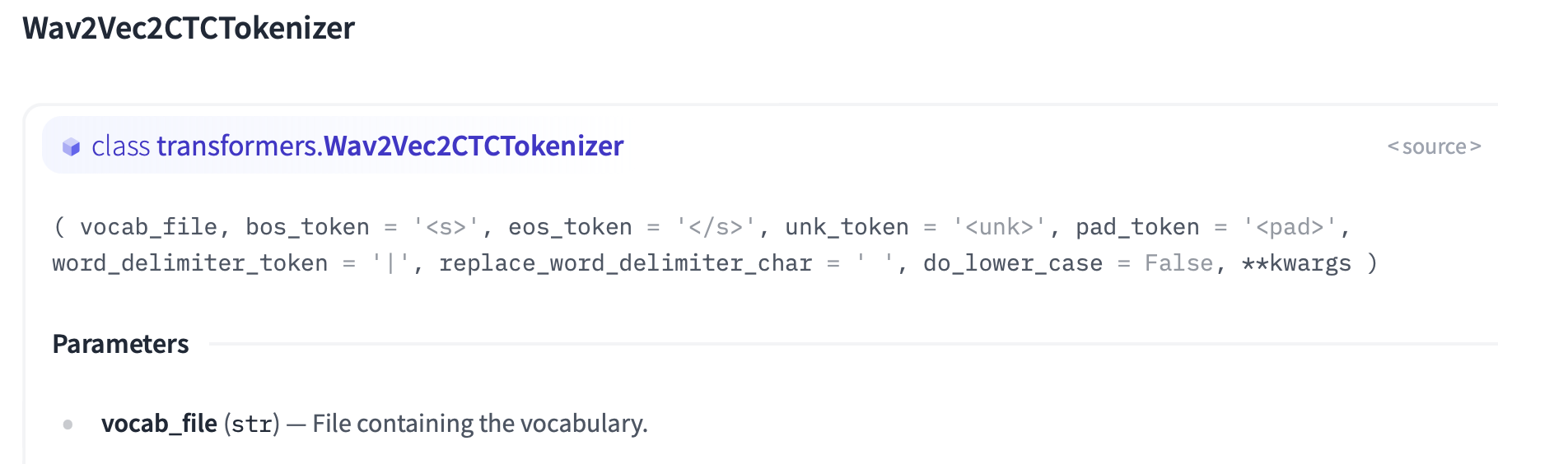
Transformers 기본 설명
-
Architectures: 모델의 뼈대(skeleton)를 의미합니다. 모델 내에서 발생하는 각 레이어(layer)와 오퍼레이션(operation, 연산)등을 정의합니다.
-
Checkpoints: 해당 아키텍처에서 로드될 가중치 값들을 나타냅니다.
-
Model: 이것은 'architecture' 또는 'checkpoint'보다는 덜 명확한 포괄적인 용어입니다. 두 가지 모두를 의미할 수도 있습니다.
예를 들어, BERT는 architecture이고 BERT의 첫 번째 릴리스를 위해 Google팀에서 학습한 가중치 세트(set of weights)인 bert-base-cased는 checkpoint입니다. 하지만, 'BERT'와 'bert-base-cased'도 모델이라고 말할 수도 있습니다. -
configuration: 설정
from transformers import BertConfig, BertModel
# 1. 모델 초기화
# config(설정)을 만듭니다.
config = BertConfig()
# 해당 config에서 모델을 생성합니다.
model = BertModel(config)
# 2. pre-trained 모델 가져오기
model = BertModel.from_pretrained("bert-base-cased")0. 기본 setting
1) import module
import functools
import json
import logging
import os
import re
import sys
import warnings
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Union
import datasets
import evaluate
import numpy as np
import torch
from datasets import DatasetDict, load_dataset
import transformers
from transformers import (
AutoConfig,
AutoFeatureExtractor,
AutoModelForCTC,
AutoProcessor,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
Wav2Vec2Processor,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint, is_main_process
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version2) transformers 버전 확인
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.27.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/putorch/speech-recognition.requirements.txt")3) logging
logger = logging.getLogger(__name__)로깅이란?
현재 우리의 프로그램이 어떤 상태를 가지고 있는지, 외부출력을 하게 만들어서 개발자등이 눈으로 직접 확인하는 것입니다. logging의 기본함수로는 DEBUG, INFO, WARNING, ERROR, CRITICAL의 5가지 등급이 있습니다.
logging.getLogger을 사용해서 자신만의 특정한 logger를 생성할 수 있습니다.
__name__ 라는 특정 logger를 생성하게됩니다.
-출처: https://hamait.tistory.com/880
4) field
def list_field(default=None, metadata=None):
return field(default_factory=lambda: default, metadata=metadata)1. Model parameters setting
1) ModelArguments
mask_time_prob vs mask_feature_prob 차이?
mask_time_length vs mask_feature_length 차이?
@dataclass
class ModelArguments:
"""
Arguments pretaining(적용되다) to which model/config/tokenizer we are going to fine-tune from.
"""- pre-trained model이 올라온 path(인터넷 경로)
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)- pre-trained tokenizer이 올라온 path
tokenizer_name_or_path: Optional[str]= field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)- 가져온 pre-trained 모델을 저장할 cache 저장소 위치
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)- encoder의 freeze 여부? 즉 wav2vec2.0 feature extractor도 fine-tunning 할지 여부
freeze_feature_encoder: bool = field(
default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
)- attention dropout
attention_dropout: float = field(
default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
)- activation dropout
activation_dropout: float = field(
default=0.0, metadata={"help": "The dropout ration for activations inside fully connected layer."}
)- feat_proj dropout
feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features"})- hidden dropout
hidden_dropout: float = field(
default=0.0,
metadata={
"help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
}
)- final_dropout
final_dropout: float = field(
default=0.0,
metadata={"help": "The dropout probability for the final projection layer."}
)time axis vs feature axis??
- 📌 mask_time_prob
mask_time_prob: float = field(
default=0.05,
metadata={
"help": (
"Probability of each feature vector along the time aixs to be chosen as the start of the vector"
"span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature"
"vectors will be masked along the time axis."
)
},
)- 📌 mask_time_length
mask_time_length: int = field(
default=10,
metadata={"help": "Length of vector span to mask along the time axis."},
)- 📌 mask_feature_prob
mask_feature_prob: float = field(
default=0.0,
metadata={
"help": (
"Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
"to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
"bins will be masked along the time axis."
)
},
)- 📌 mask_feature_length
mask_feature_length: int = field(
default=10,
metadata={"help": "Length of vector span to mask along the feature axis"},
)- layerdrop
layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})- 📌 ctc_loss_reduction
ctc_loss_reduction: Optional[str] = field(
default="mean", metadata={"help": "The way the ctc loss sholud be reduced. Should be one of 'mean' or 'sum'."}
)2) DataTrainingArguments
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
Using 'HfArgumentParser' we can turn this class
into argparse arguments to be able to specify tem on
the command line.
"""- 사용할 dataset name
dataset_name: str = field(
metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)- dataset_config_name
dataset_config_name: str = field(
default=None, metadata={"help": "The configuration name of the dataset to use( via the datasets library)."}
)- train_split_name: dataset에서 train data를 뽑기 위한 dataset 구분 name
train_split_name: str = field(
default="train+validation",
metadata={
"help": (
"The name of the training data set split to use (via the datasets library)"
)
},
)- eval_split_name: dataset에서 test data(evaluation data)를 뽑기 위한 dataset 구분 name
eval_split_name: str = field(
default="test",
metadata={
"help": "The name of the evaluation data set split to use (via the datasets library). Defaults to 'test"
},
)- audio_column_name: x(=audio data) column name
audio_column_name: str = field(
default="audio",
metadata={"help": "The name of the dataset column contating the audio data. Defaults to 'audio"}
)- text_column_name: y(=text data) column name
text_coulms_name: str = field(
default="text",
metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
)- overwrite_cache
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
)- preprocessing_num_workers: 사용할 GPU 서버 개수?
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)- max_train_samples
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate((아래나 위를 잘라서)길이를 줄이다, 짧게 하다) the number of training examples to this"
"value if set."
)
},
)- chars_to_ignore
chars_to_ignore: Optional[List[str]] = list_field(
default=None,
metadata={"help": "A list of characters to remove from the transcripts."},
)- eval_metrics
eval_metrics: List[str] = list_field(
default=["wer"],
metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
)- max_duration_in_seconds
max_duration_in_seconds: float = field(
default=20.0,
metadata={
"help": (
"Filter audio files that are longer than `max_duration_in_seconds` seconds to"
" `max_duration_in_seconds`"
)
},
)- min_duration_in_seconds
min_duration_in_seconds: float = field(
default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
)- preprocessing_only: data의 preprocessing 과정만 한 대의 GPU서버에서 실행하고 training 과정은 여러 대의 GPU 서버에서 이루어질 수 있도록 하기 위해서
preprocessing_only: bool = field(
default=False,
metadata={
"help": (
"Whether to only do data preprocessing and skip training. This is expecially useful when data"
" preprocessing errors out in distributed training(분산 학습) due to timeout. In this case, one should run the"
" preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
" can consequently be loaded in distributed training"
)
}
)- unk_token
unk_token: str = field(
default="[UNK]",
metadata={"help": "The unk token for the tokenizer"},
)- pad_token: padding할 때 사용할 token
pad_token: str = field(
default="[PAD]",
metadata={"help": "The padding token for the tokenizer"},
)- word_delimiter_token
word_delimiter_token: str = field(
default="|",
metadata={"help": "The word delimiter(구분 문자) token for the tokenizer"},
)- 📌 phoneme_language
phoneme_language: Optional[str] = field(
default=None,
metadata={
"help": (
"The target language that should be used be"
" passed to the tokenizer for tokenization. Note that"
" this is only relevant if the model classifies the"
" input audio to a sequence of phoneme sequences."
)
}
)3) DataCollatorCTCWithPadding
📌DataCollator
Data collators are objects that will form a batch by using a list of dataset elements as input. To be able to build batches, data collators may apply some processing (like padding).
= 동적 패딩(Dynamic padding)
전체 데이터셋이 아닌 개별 배치(batch)에 대해서 별도로 패딩(padding)을 수행하여 과도한 패딩 작업을 해주는 것을 동적 패딩이라고 합니다. 이를 수행하려면 batch로 분리하려는 데이터셋의 요소 각각에 대해서 정확한 수의 padding을 적용할 수 있도록 도와주는 collate function이 필요합니다. Transformers는 라이브러리 DataCollatorWithPadding을 통해 이러한 기능을 제공합니다.
- 참고: https://huggingface.co/docs/transformers/main_classes/data_collator
- 참고: https://wikidocs.net/166801
📌Preprocess
Before you can train a model on a dataset, it needs to be preprocessed into the expected model input format. Whether your data is text, images, or audio, they need to be converted and assembled into batches of tensors. 🤗 Transformers provides a set of preprocessing classes to help prepare your data for the model. In this tutorial, you’ll learn that for:
- Text, use a Tokenizer to convert text into a sequence of tokens, create a numerical representation of the tokens, and assemble them into tensors.
- Speech and audio, use a Feature extractor to extract sequential features from audio waveforms and convert them into tensors.
- Image inputs use a ImageProcessor to convert images into tensors.
- Multimodal inputs, use a Processor to combine a tokenizer and a feature extractor or image processor.
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.AutoProcessor`)
The processor used for precessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj: `'max_length'`: Pad to a maximun length specified with the argument: obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different lengths).
max_length (:obj: `int`, `optional`):
Maximum length of the ``input_vlaues`` of the returned list and optionally padding length (see above).
max_length_labels (:obj:`int`, `optional`):
Maximum length of the ``labels`` returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volata).
"""- 전처리 모델은 AutoProcessor 사용
processor: AutoProcessor- padding은 longest(정수)로 해줍니다.
padding: Union[bool, str] = "longest"- pad_to_multiple_of: 설정하면 시퀀스를 제공된 값의 배수로 패딩해줍니다. 왜?
- 이것은 컴퓨팅 기능이 >= 7.5(볼타)인 NVIDIA 하드웨어에서 텐서 코어를 사용하는 데 특히 유용합니다.
pad_to_multiple_of: Optional[int] = None- pad_to_multiple_of_labels?
pad_to_multiple_of_labels: Optional[int] = None- 📌
__call__: callable 함수- python에서 ``callable``이란 호출가능한 클래스 인스턴스, 함수, 메서드 등 객체를 의미합니다. 참고로 파이썬에서는 모든 것이 객체이기 때문에, 함수도 하나의 객체입니다. 함수 안에 data variable, 또 다른 함수 등을 가질 수 있고 다른 함수의 argument로 전달될 수도 있습니다.- class가 호출되면,
__init__은 인스턴스를 초기화하고,__call__은 정의된 함수의 역할을 실행합니다. - callable을 정리해보자면,
(1)__call__메서드가 있는 클래스 인스턴스거나
(2) 호출 가능한 메서드나 함수 - 특정 서명의 콜백 함수를 기대하는 프레임워크는
Callable[[Arg1Type, Arg2Type], ReturnType]을 사용하여 형 힌트를 제공할 수 있습니다. - 참고: https://etloveguitar.tistory.com/142
- 참고: https://wjunsea.tistory.com/61
- 참고: https://docs.python.org/ko/3/library/typing.html
- class가 호출되면,
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"] for feature in features}]return_tensors (str): 반환할 tensor의 유형. 허용 가능한 값은 "np"(Numpy), "pt"(PyTorch) 및 "tf"(Tensorflow)입니다.
batch = self.proessor.pad(
input_features,
padding=self.padding,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensor="pt"
)
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensor="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
if "attention_mask" in batch:
batch["attention_mask"] = batch["attention_mask"].to(torch.long)
return batch4) Vocab Dictionary 생성
- vocab.json'파일을 만들기 위해 필요한 함수
- train dataset, evaluation dataset에 있는 text data를 모두 합쳐주고 set해줘 중복되는 문자열을 제거해서 unique한 문자열 모음집을 만들어줍니다.
예를 들면 'hello' -> {'h', 'e', 'l' ,'o'}의 문자열 모음집이 만들어집니다.
def create_vocabulary_from_data(
datasets: DatasetDict,
word_delimiter_token: Optional[str] = None,
unk_token: Optional[str] = None,
pad_token: Optional[str] = None):- 모든 text data 합쳐주기
# Given training and test labels create vocabulary
def extract_all_chars(batch):
all_text = " ".join(batch["target_text"])set()을 이용해 중복된 문자열 제거
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}- dataset에 함수 적용
vocabs = datasets.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=datasets["train"].columns_names,
)- dataset마다(train, evaluation) 생성된 문자열 모음집 합집합(union)해줘서 합쳐주기
# take union of all unique characters in each dataset
vocab_set = functools.reduce(
lambda vocab_1, vocab_2: set(vocab_1["vocab"][0]) | set(vocab_2["vocab"][0]), vocabs.values()
)- vocab에 index(int) 붙여주기
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}- white space?를 delimiter_token으로 대체
# replace white space with delimiter token
if word_delimiter_token is not None:
vocab_dict[word_delimiter_token] = vocab_dict[" "]
del vocab_dict[" "]- unk_token과 pad_token 추가
# add unk and pad token
if unk_token is not None:
vocab_dict[unk_token] = len(vocab_dict)
if pad_token is not None:
vocab_dict[pad_token] = len(vocab_dict)- 최종 vocab_dict 생성 완료
return vocab_dict2. main()
0) train 기본 settings
def main():
# See all possible arguments in scr/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.- 📌
argparse: The argparse module makes it easy to write user-friendly command-line interfaces. HfArgumentParser
- 참고: https://huggingface.co/transformers/v4.2.2/_modules/transformers/hf_argparser.html
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))- 인자값 받기
- 참고: https://needneo.tistory.com/95
파이썬으로 작성된 파일을 실행할 때 인수(argument, 인자값)를 받아서 처리를 해야되는 경우, 이를 sys.argv에 값을 담아 처리를 할 수 있습니다.
예를 들어, command에 hello.py 파일을 실행하면서 "Solee(이름)" 1개의 인자값을 줬습니다. 이 인자값을 어떻게 프로그램이 처리하는지 보면,
ex1.
#hello.py
import sys
print(sys.argv)
>> python hello.py Solee
['hello.py', 'Solee']sys.argv를 프린트할 경우 python 이후에 작성된 인자값들이 모두 출력됩니다. 만약 우리가 hello.py 이후에 나오는 인자값들만 필요하다면,
ex2.
import sys
print(sys.argv[1])
if len(sys.argv) ==2 and sys.argv[1].endwith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.- os.path.abspath(): 절대경로 구하기, 실행 위치와 상관없이 파이썬 파일의 절대경로를 가질 수 있습니다. argument가 기록된 json파일을 불러와 사용합니다.
.parse_args_into_dataclasses(): HfArgumentParser class의 함수, Parse command-line args into instances of the specified dataclass types.
model_args, data_args, training_args = parser.parse_args_into_dataclasses(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()- 중간 학습 결과 출력
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_speech_recognition_ctc", model_args, data_args)- checkpoint: 모델을 학습 중간중간에 저장해주기, 중간에 모델 학습이 끊겨도 다시 이어서 할 수 있도록 도와줍니다.
- 참고: https://tutorials.pytorch.kr/recipes/recipes/saving_and_loading_a_general_checkpoint.html
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.ouput_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty."
"Use --overwrite_output)dir to overcome"
)
elif last_checkpoint is not None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)- logging 설정
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S"
)
logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
f"distributed training: {bool(training_args.local_rank != 1)}, 16-bits training: {training_args.fp16}"
)- seed 설정
# Set seed before initializing model
set_seed(training_args.seed)1) Train
(1) dataset load
- train data load
use_auth_token??
# 1. First, let's load the dataset
raw_datasets = DatasetDict()
if training_args.do_train:
raw_datasets["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=data_args.train_split_name,
use_auth_token=data_args.use_auth_token,
)- dataset에서 가장 중요한 'audio' column! dataset마다 audio데이터 column name이 다를 수 있으니 잘 확인하고 설정해줘야 합니다. 만약 설정해준 audio column명이 잘못 되었을 경우 Error을 띄우며 현재 dataset에 있는 columns 이름을 출력해줍니다.
if data_args.audio_column_name not in raw_datasets["train"].column_names:
raise ValueError(
f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
"Make sure to set '--audio_column_name' to the correct audio column - one of"
f"{', '.join(raw_datasets['train'].column_names)}"
)- 'text' column도 'audio'와 같이 처리해줍니다.
if data_args.text_column_name not in raw_datasets["train"].column_names:
raise ValueError(
f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
"Make sure to set `--text_column_name` to the correct text column - one of "
f"{', '.join(raw_datasets['train'].column_names)}."
).select
if data_args.max_train_samples is not None:
raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))- evaluation dataset load
if training_args.do_eval:
raw_datasets["eval"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=data_args.eval_split_name,
use_auth_token=data_args.use_auth_token,
)
if data_args.max_eval_sample is not None:
raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))(2) 특수 문자 제거
- re.sub(정규 표현식, 치환 문자, 대상 문자열): 정규 표현식(=제거 대상으로 정해준 기호/문자) 문자열 치환
# 2. We remove some special characters from the datasets
# that make training complicated and do not help in trascribing the speech
# E.g. characters, such as, ',' and '.' do not really have an acoustic characteristic
# that could be easily picked up by the model
chars_to_ignore_regex = (
f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
)
text_column_name = data_args.text_column_name
def remove_special_characters(batch):
if chars_to_ignore_regex is not None:
batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
else:
batch["target_text"] = batch[text_column_name].lower() + " "
return batch- 적용
with training_args.main_process_first(desc="dataset map special characters removal"):
raw_datasets = raw_datasets.map(
remove_special_characters,
remove_columns=[text_column_name],
desc="remove special characters from datasets",
)(3) pre-trained model config 설정
- Tokenizer: 모델이 데이터를 처리할 수 있도록 텍스트를 숫자로 바꿔주기 위해 필요. 또한 모델의 출력 형식을 텍스트로 처리하는데 필요.
=> Wav2Vec2Tokenizer - Feature Extractor: Speech Signal을 모델의 입력 형식(feature vector)으로 처리하는데 필요
=> Wav2Vec2FeatureExtractor
# 3. Next, let's load the config as we might need it to create
# the tokenizer
# load config
config = AutoConfig.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_auth_token=data_args.use_auth_token
)Tokenizer?
(4) vocab.json 파일 생성
- train dataset, evaluation dataset에 있는 text data를 가지고
create_vocabulary_from_data함수를 사용해 vocab.json파일 생성. - vocab.json파일을 다운 받아서 사용할 수도 있음.
# 4. Next, if no tokenizer file(=vocab file) is defined,
# we create the vocabulary of the model by extracting all unique characters from
# the training and evaluation datasets
# We need to make sure that only first rank saves vocabulary
# make sure all processes wait until vocab is created
tokenizer_name_or_path = model_args.tokenizer_name_or_path
tokenizer_kwargs = {}- 만약 tokenizer 모델에 넣어줄 tokenizer file(=vocab file)이 없다면 vocab.json파일을 직접 만들어줍니다. 파일의 위치는 output_dir로 둡니다.
if tokenizer_name_or_path is None:
# save vocab in training output dir
tokenizer_name_or_path = training_args.output_dir
vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")- 'vocab.json'이 저장하려는 directory에 이미 있다면 remove해줍니다.
with training_args.main_process_first():
if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
try:
os.remove(vocab_file)
except OSError:
# in shared file-systems it might be the case that
# two processes try to delete the vocab file at the some time
pass- 그리고 나서, 함수
create_vocabulary_from_data을 사용해 vocab.json을 {key(문자열): value(index)}로 채워줍니다.
with training_args.main_process_first(desc="dataset map vocabulary creation"):
if not os.path.isfile(vocab_file):
os.makedirs(tokenizer_name_or_path, exist_ok=True)
vocab_dict = create_vocabulary_from_data(
raw_datasets,
word_delimiter_token=word_delimeter_token,
unk_token=unk_token,
pad_token=pad_token,
)- 만들어진 vocab_dict를 저장해줍니다.
# save vocab dict to be loaded into tokenizer
with open(vocab_file, "w") as file:
json.dump(vocab_dict, file)- keyword argument: {'key':'value'} dictionary 형태로 arguments를 함수에 전달할 수 있음
# if tokenizer has just been created
# it is defined by `tokenizer_class` if present in config else by `model_type`
tokenizer_kwargs = {
"config": config if config.tokenizer_class is not None else None,
"tokenizer_type": config.model_type if config.tokenizer_class is None else None,
"unk_token": unk_token,
"pad_token": pad_token,
"word_delimiter_token": word_delimeter_token,
}(5) model 불러오기
- pre-trained된 Tokenizer model을 불러오면서 위에서 지정해준
**tokenizer_kwargs인자도 넣어줍니다.
# 5. Now we can instantiate the feature extractor, tokenizer and model
# Note for distributed training, the .from_pretrained methods guarantee that only
# one local process can concurrently download model & vocab.
# load feature_extractor and tokenizer
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
use_auth_token=data_args.use_auth_token,
**tokenizer_kwargs, ignore_mismatched_sizes=True
)- pre-trained된 wav2vec2.0 Feature Extractor을 불러옵니다.
feature_extractor = AutoFeatureExtractor.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_auth_token=data_args.use_auth_token, ignore_mismatched_sizes=True
)- finetune.sh에서 직접 설정해준 arguments에 맞게끔 config를 update 해줄 수 있도록 합니다.
# adapt config
config.update(
{
"feat_proj_dropout": model_args.feat_proj_dropout,
"attention_dropout": model_args.attention_dropout,
"hidden_dropout": model_args.hidden_dropout,
"final_dropout": model_args.final_dropout,
"mask_time_prob": model_args.mask_time_prob,
"mask_time_length": model_args.mask_time_length,
"mask_feature_prob": model_args.mask_feature_prob,
"mask_feature_length": model_args.mask_feature_length,
"gradient_checkpointing": training_args.gradient_checkpointing,
"layerdrop": model_args.layerdrop,
"ctc_loss_reduction": model_args.ctc_loss_reduction,
"pad_token_id": tokenizer.pad_token_id,
"vocab_size": len(tokenizer),
"activation_dropout": model_args.activation_dropout,
}
)- pre-trained된 CTC model을 불러옵니다.
# create model
model = AutoModelForCTC.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
config=config
use_auth_token=data_args.use_auth_token, ignore_mismatched_sizes=True
)- pre-trained model을 추가 train 시킬 때, encoder는 학습시키고 시키지 않다면 freeze해줍니다.
# freeze encoder
if model_args.freeze_feature_encoder:
model.freeze_feature_encoder()(6) Preprocessing
# 6. Now we preprocess the datasets including loading the audio, resampling and normalization
# Thankfully, `datasets` takes care of automatically loading and resampling the audio,
# so that we just need to set the correct target sampling rate and normalize the input
# via the `feature_extractor`- dataset의 'audio' sampling rate과 사용하고자 하는 Feature Extractor의 sampling rate 맞춰주기
# make sure that dataset decodes audio with correct sampling rate
dataset_sampling_rate = next(iter(raw_datasets.values())).feature[data_args.audio_column_name].sampling_rate
if dataset_sampling_rate != feature_extractor.sampling_rate:
raw_datasets = raw_datasets.cast_column(
data_args.audio_column_name, datasets.feature.Audio(samplig_rate=feature_extractor.sampling_rate)
)- dataset을 Feature Extractor에 넣는 과정을 보기 전에 Librispeech dataset이 어떻게 구성되어 있는지 보고자 합니다.
- 참고: https://huggingface.co/datasets/librispeech_asr#data-fields
- file: A path to the downloaded audio file in .flac format.
- audio: A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: dataset[0]["audio"] the audio file is automatically decoded and resampled to dataset.features["audio"].sampling_rate. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the "audio" column, i.e. dataset[0]["audio"] should always be preferred over dataset["audio"][0].
- text: the transcription of the audio file.
- id: unique id of the data sample.
- speaker_id: unique id of the speaker. The same speaker id can be found for multiple data samples.
- chapter_id: id of the audiobook chapter which includes the transcription.
{'chapter_id': 141231,
'file': '/home/patrick/.cache/huggingface/datasets/downloads/extracted/b7ded9969e09942ab65313e691e6fc2e12066192ee8527e21d634aca128afbe2/dev_clean/1272/141231/1272-141231-0000.flac',
'audio': {'path': '/home/patrick/.cache/huggingface/datasets/downloads/extracted/b7ded9969e09942ab65313e691e6fc2e12066192ee8527e21d634aca128afbe2/dev_clean/1272/141231/1272-141231-0000.flac',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346,
0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 16000},
'id': '1272-141231-0000',
'speaker_id': 1272,
'text': 'A MAN SAID TO THE UNIVERSE SIR I EXIST'}
# Preprocessing the datasets.
# We need to read the audio files as arrays and tokenize the targets.
def prepare_dataset(batch):
# load audio
sample = batch[audio_column_name] inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])-
feature_extractor를 지난 audio sample을 보면 aduio 데이터가 다음과 같이 tensor에 숫자들의 나열로 표현되어 있는 것을 확인할 수 있습니다.

-
tensor[0]을 input_values로 넣어줍니다. 이 과정은 사실상 tensor를 squeeze해준 것을 input_values로 넣는 것입니다.
batch["input_values"] = inputs.input_values[0]
batch["input_length"] = len(batch["input_values"])- 만약 phoneme_language가 따로 설정되어 있다면 additional_kwargs에 argument로 넣어줍니다.
# encode targets
additional_kwargs = {}
if phoneme_language is not None:
additional_kwargs["phonemizer_lang"] = phoneme_language- text data를 tokenize 해줍니다.
batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
return batch- 위에서 만든
prepare_dataset함수를 raw_dtaasets에 적용해 전처리 해줍니다.
with training_args.main_process_first(desc="dataset map preprocessing"):
vectorized_datasets = raw_datasets.map(
prepare_dataset,
remove_columns=next(iter(raw_datasets.values())).column_names,
num_proc=num_workers,
input_columns=["input_length"],
)- input데이터의 크기가 정해준 min, max length를 넘는지 체크하는 함수를 정의해줍니다.
def is_audio_in_length_range(length):
return length > min_input_length and length < max_input_length- filter() returns rows that match a specified condition
audio의 길이가 너무 짧은 데이터를 학습 데이터에서 제거해줍니다.
- 참고: https://huggingface.co/docs/datasets/process#batch-processing
# filter data that is shorter than min_input_length
vectorized_datasets = vectorized_datasets.filter(
is_audio_in_length_range,
num_proc=num_workers,
input_columns=["input_length"],
)(7) Prepare the training
# 7. Next, we can prepare the training.
# Let's uses word error rate (WER) as our evaluation metric,
# instantiate a data collator and the trainer- evalation metrics 만들기
# Define evaluation metrics during training, *i.e.* word error rate, character error rate
eval_metrics = {metric: evaluate.load(metric) for metric in data_args.eval_metrics}- 데이터 전처리는 하나의 서버에서만, 왜??
# for large datasets it is advised to run the preprocessing on a
# single machine first with ``args.preprocessing_only`` since there will mostly likely
# be a timeout when running the script in distributed mode.
# In a second stop ``args.preprocessing_only`` can then be set to `False` to load the
# cached dataset
if data_args.preprocessing_only:
logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_fiels}")
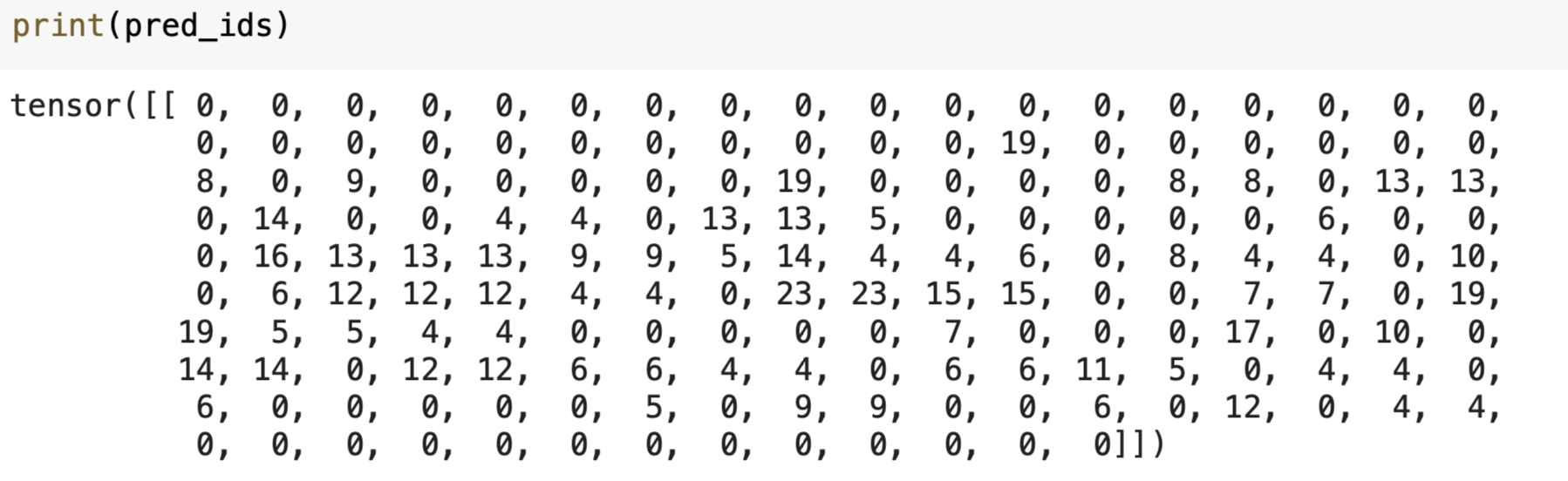
return def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)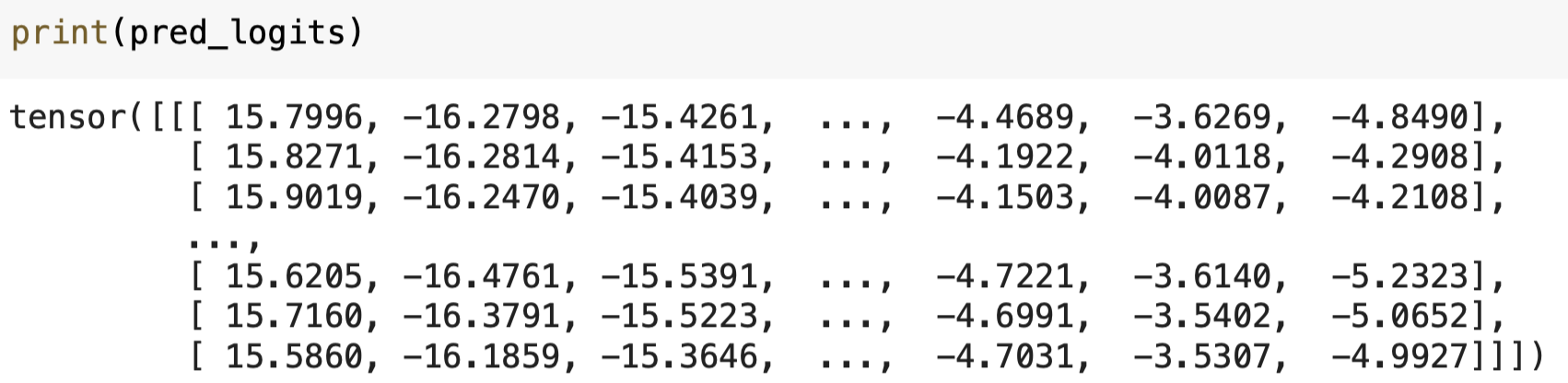


2) Evaluation
WER(Word Error Rate)
