자바스크립트의 Buffer
특정 크기의 메모리 공간에 바이너리 데이터를 저장해두는 객체
기존의 자바스크립트는 메모리에 접근을 허용
ArrayBuffer
개발자가 지정한 메모리 크기만큼의 바이너리 데이터를 저장하는 객체
메모리를 확보해 바이너리 데이터를 0으로 저장해두는 역할만을 하며 실제 데이터 접근은 별도로 제공되는 ArrayBufferView 를 통해서만 가능하다
- ArrayBuffer : 메모리 확보 및 데이터 생성 ( 00000000….)
- ArrayBufferView : 데이터 접근 ( 읽기, 수정 )
- TypedArray : Uint8Array, Uint16Array, Float32Array, ….
- DataView
생성 방법
💩 생성자 : new ArrayBuffer(byte) 인자 : binary data 를 지정할 memory 크기 ( byte ) 반환 : binary data ( 0 ) 이 저장된 ArrayBuffer 객체그런데 한가지 궁금점이 생긴다 왜 굳이 이렇게 데이터 저장과 접근 객체를 구분지어 관리를 할까?
데이터의 저장과 접근을 수행하는 객체를 분리한 이유는 크게
Efficiency ( 효율성 )와 Flexibility ( 유연성 ) 2가지이다
예를 들면
new ArrayBuffer(4) 로 생성한 공간은
00000000 00000000 0000000 0000000
으로 초기화되는데 이를
4byte 로 인식하면 0 ~ 4294967296 가지의 다양한 표현 방법이 있지만
1byte 로 인식하면 0 ~ 255, 0 ~ 255, 0 ~ 255, 0 ~ 255 로 4가지로 나눠 인식이 가능하다
즉 이미지와 같은 비트맵처리를 할 때는 더 적은 byte로 인식하면 효율적일 것이라 생각한다
또는 어떠한 구조에서는 접근할 때 인식되는 bit 수를 늘리는 것도 효율적일 수도 있다
즉 이러한 환경을 개발자가 직접 효율적 ( Efficiency ) 이고 유연 ( Flexibility ) 하게 조절하도록 한 것이다
TypedArray
ArrayBufferView 의 하나로 ArrayBuffer 에 저장된 바이너리 데이터를 원하는 형태로 인식
구분 기준
- 요소의 타입 : Int, UnsignedInt, BigInt, Float
- 요소의 크기 : 8, 16, 32, 64 bit
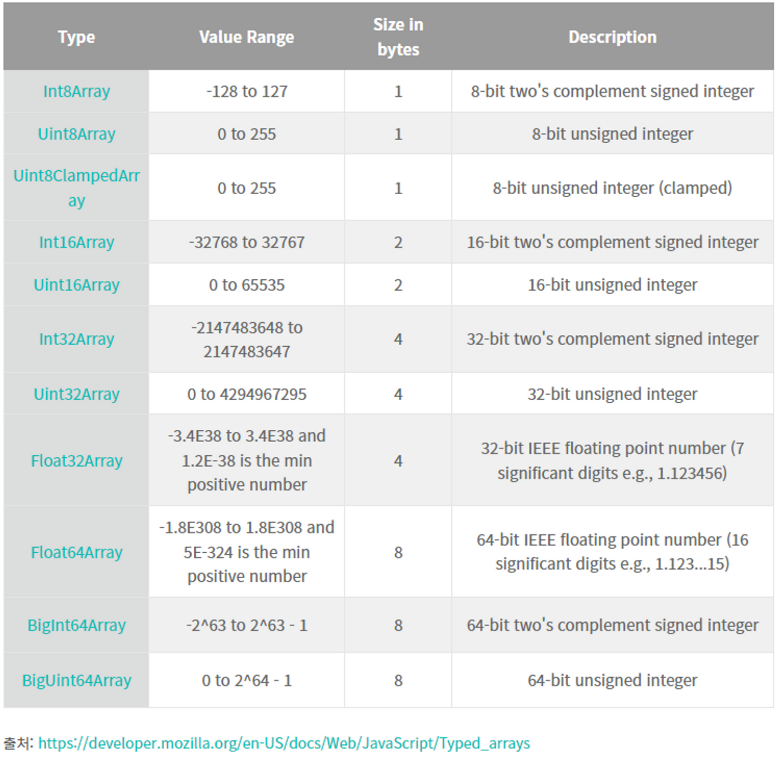
Ex )
// 4Byte의 ArrayBuffer(바이너리 데이터) 생성
const arrayBuffer = new ArrayBuffer(4);
// [00000000 00000000 00000000 00000000]
// Uint8Array: 1Byte(8bit)짜리 unsigned Int 요소 4개를 갖는 배열
const uint8Array = new Uint8Array(arrayBuffer);
// [0~255, 0~255, 0~255, 0~255]
// Uint16Array: 2Byte(16bit)짜리 unsigned Int 요소 2개를 갖는 배열
const uint16Array = new Uint16Array(arrayBuffer);
// [0~65536, 0~65536]
// UInt32Array: 4Byte(32bit)짜리 unsigned Int 요소 1개를 갖는 배열
const uint32Array = new Uint32Array(arrayBuffer);
// [0~4294967296]현재 진행중인 프로젝트에 webcam 을 다루는 기능들이 필요해져서 찾아보니 비디오 혹은 오디오 데이터를 다루는 과정에서 이러한 Buffer 를 사용하여 데이터관리를 할 수 있다는 것을 발견했다
이런 멀티미디어 데이터를 서버에서 관리하게 할 경우 이용자 수가 늘어날 시 서버에 부하가 발생해 기능 지연이 심해질 것이라 생각했다
그리하여 클라이언트측에서 데이터를 관리할 수 있다면 클라이언트 측에서 처리할 수 있게 하면 유지보수 측면에서도 훨씬 용이할 것이란 점을 쉽게 생각할 수 있다 즉 이러한 Buffer 관리 방법을 알아두면 후에 웹 개발에 유용하게 사용될 거라 생각했다

안녕하세요 언어에 구애 받지 않는 개발자가 되고 싶은 박준성입니다