🗓️ 일정 : 8/24(목) 14:00~17:00
📖 주제 : Redis 운영중에 발생할 수 있는 여러 가지 장애 Deep Dive
👩🏫 강사 : 강대명 / 레몬트리 CTO
📌 목차
- Redis 특성
- Redis 자료구조
- Redis 장애 Case
- Redis 운영 방법
Redis 특성
Redis 란?
- Open Source (BSD 3 License)
- In-memory Key-Value NoSQL 으로, 다양한 자료구조를 제공
- https://github.com/redis/redis
- 최초에 @antirez(Salvatore Sanfilippo)에 의해서 개발되었으며, 현재는 Redis 회사에 소유권이 넘어감
Redis 를 사용하는 이유
1️⃣ 디스크 접근보다 훨씬 빠른 메모리 접근
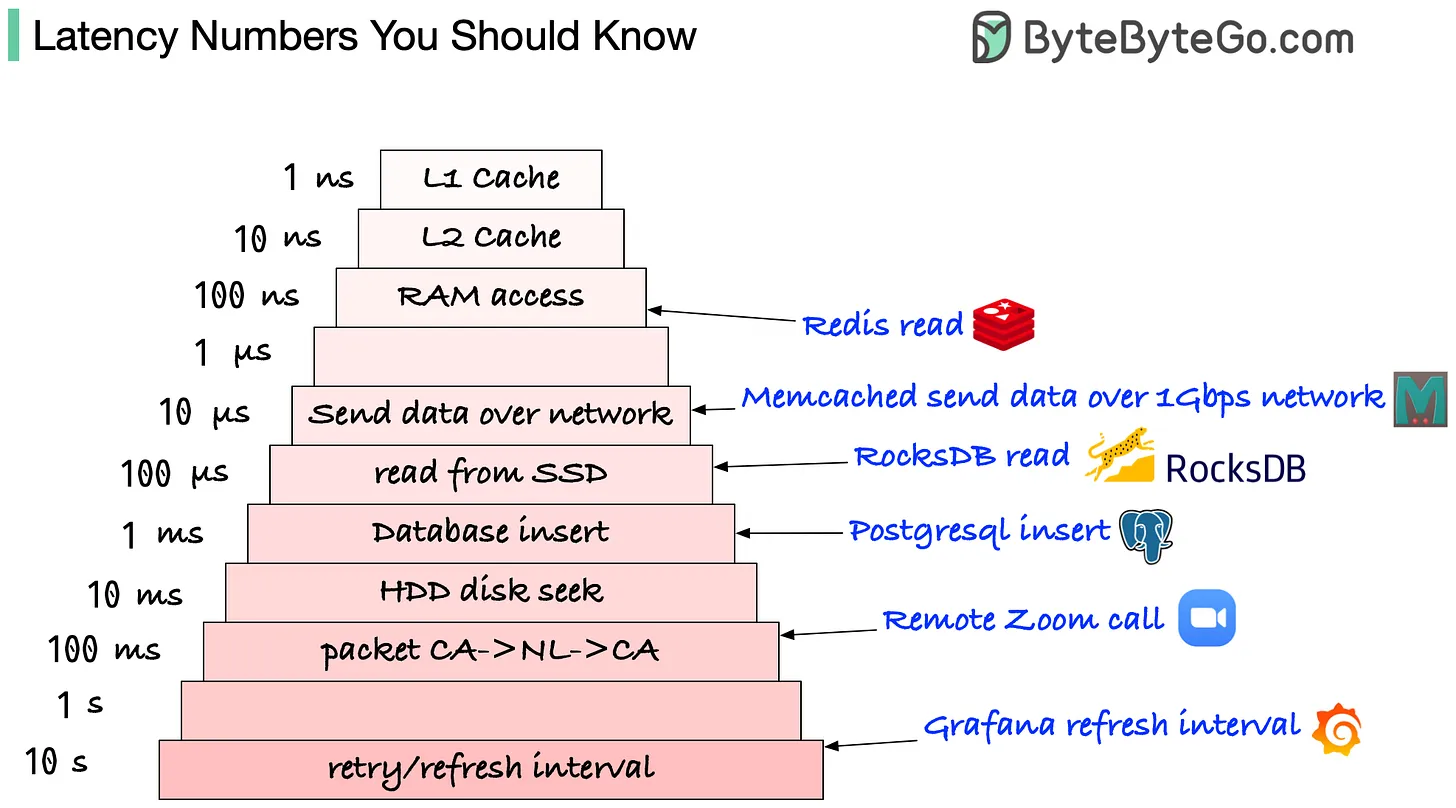
https://blog.bytebytego.com/p/ep22-latency-numbers-you-should-know
- Redis는 In-memory 솔루션이므로 접근 속도가 100ns
- 최대 초당 10만회 처리 가능
- DB 솔루션과 거의 1,000배 가량 차이가 남
2️⃣ 다양한 자료구조 제공 / 다양한 사용 분야
참고) Memcached와 Redis 비교
- Memcached에 비해 Redis는 기본적으로 String, Bitmap, Hash, List, Set, Sorted Set, Stream, Hyperloglog, geospatial index 등의 다양한 자료구조를 제공
- Memcached는 Slab 메모리를 사용하여 속도에 안정성이 있고, Redis는 jemalloc을 사용하여 메모리를 할당/해제하여 속도가 변하지만 사실상 큰 차이는 없음
- Redis가 Memcached 보다 메모리 파편화 현상이 심함
- Redis에 모듈 기능을 구현하여 추가 가능
-
Cache
- Data Entity를 DB에서 가져가는 것이 아닌 더 빠른 저장 매체인 Redis에 1차적으로 저장해두는 것
- 다양한 타입에 다양한 정보를 필요에 따라 저장 가능
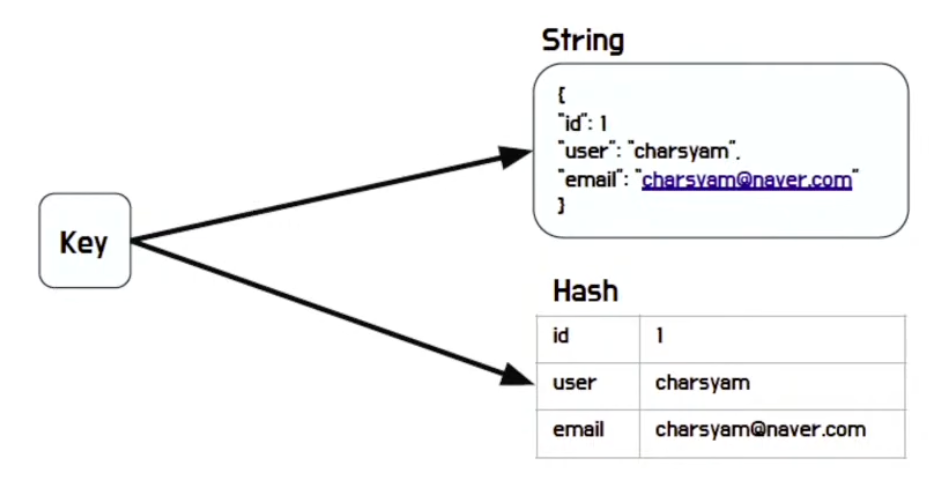
-
Distributed Cache
- 데이터가 많다면 하나의 Cache Server가 아닌 여러 캐시 서버 구성 가능
- Redis 특성 상 Swap 발생 시 프로세서가 죽을 때까지 그 Swap에 접근할 때마다 디스크에 계속 접근하게 됨 → 메모리 관리에 주의 필요
- Redis with Range
- 특정 Key의 Range로 구분
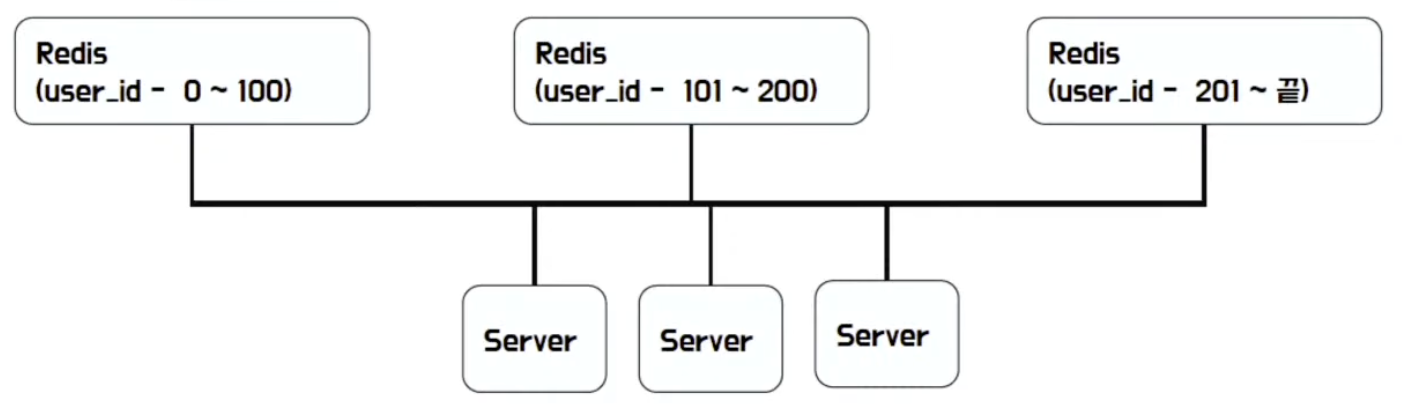
- 특정 Key의 Range로 구분
- Redis with PreShard
- hash slot을 16384 등으로 미리 나눠두고 해당 서버에 저장
- Redis Cluster 도 일종의 PreShard 구조 (crc16으로 hash)
- hash(key) % 16384
- 데이터가 잘 나눠지지만, 새로운 데이터가 추가된 경우 어떻게 데이터 분배에 대한 문제 발생 → Slot 마이그레이션, PreShard 시 재분배 등 필요
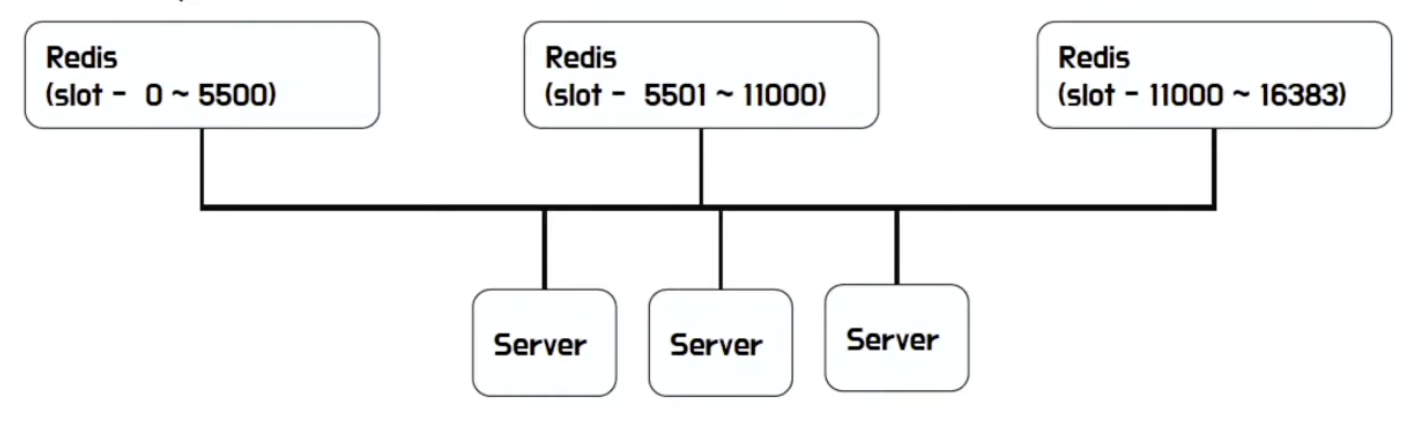
- Redis with Consistent Hashing
- Consistent Hashing을 통해 key 분할
- 특정 노드가 나가도 재분배가 일어나는 것이 아닌 그 노드에 영향을 받는 Key만 없어지는 것
- 없어져도 다시 만들 수 있는 Cache 형태에 적합
- twemproxy 등의 툴을 사용하여 Consistent Hashing을 Redis가 아닌 다른 툴에서 수행하도록 할 수도 있음
- HashRing을 균등하게 구성하더라도 부하는 균등하게 몰리지 않는 문제
- Hot Key 문제
- 필요한 개수보다 더 많은 노드가 필요할 수 있음
-
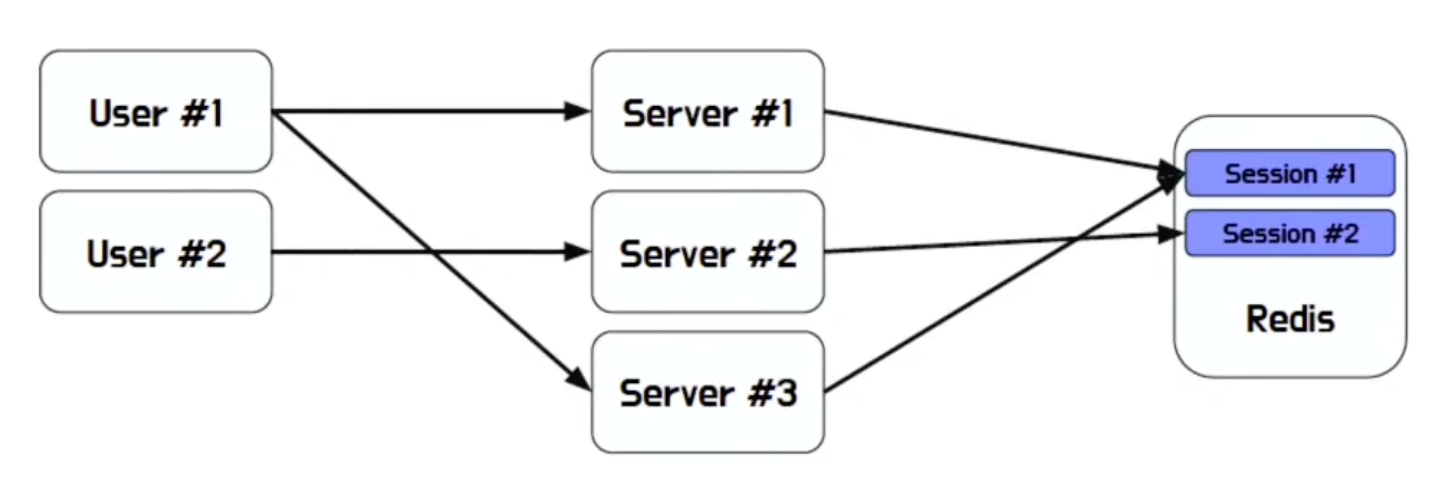
Session Store
- Session을 개별서버나 클러스터링이 아닌 외부 스토리지(Redis)에 저장
- Session Store 사용 시 서버는 Stateless 구조가 됨
-
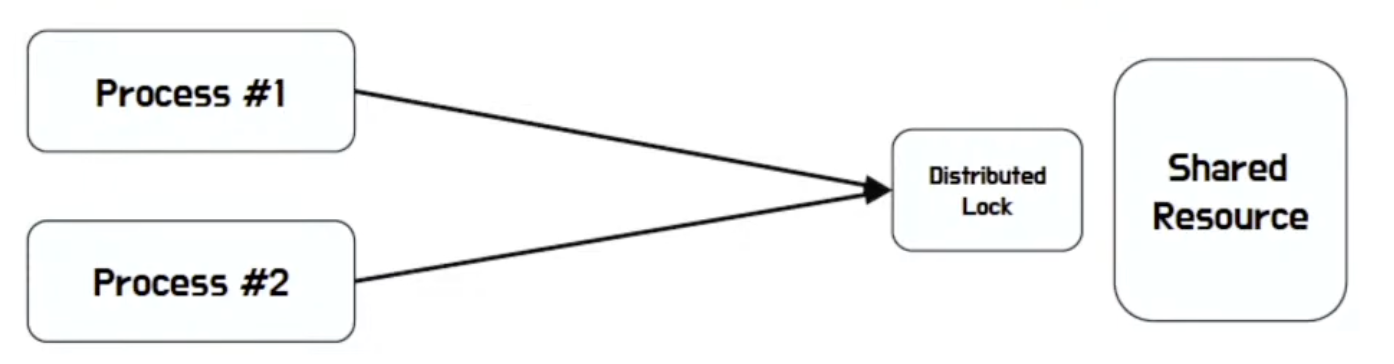
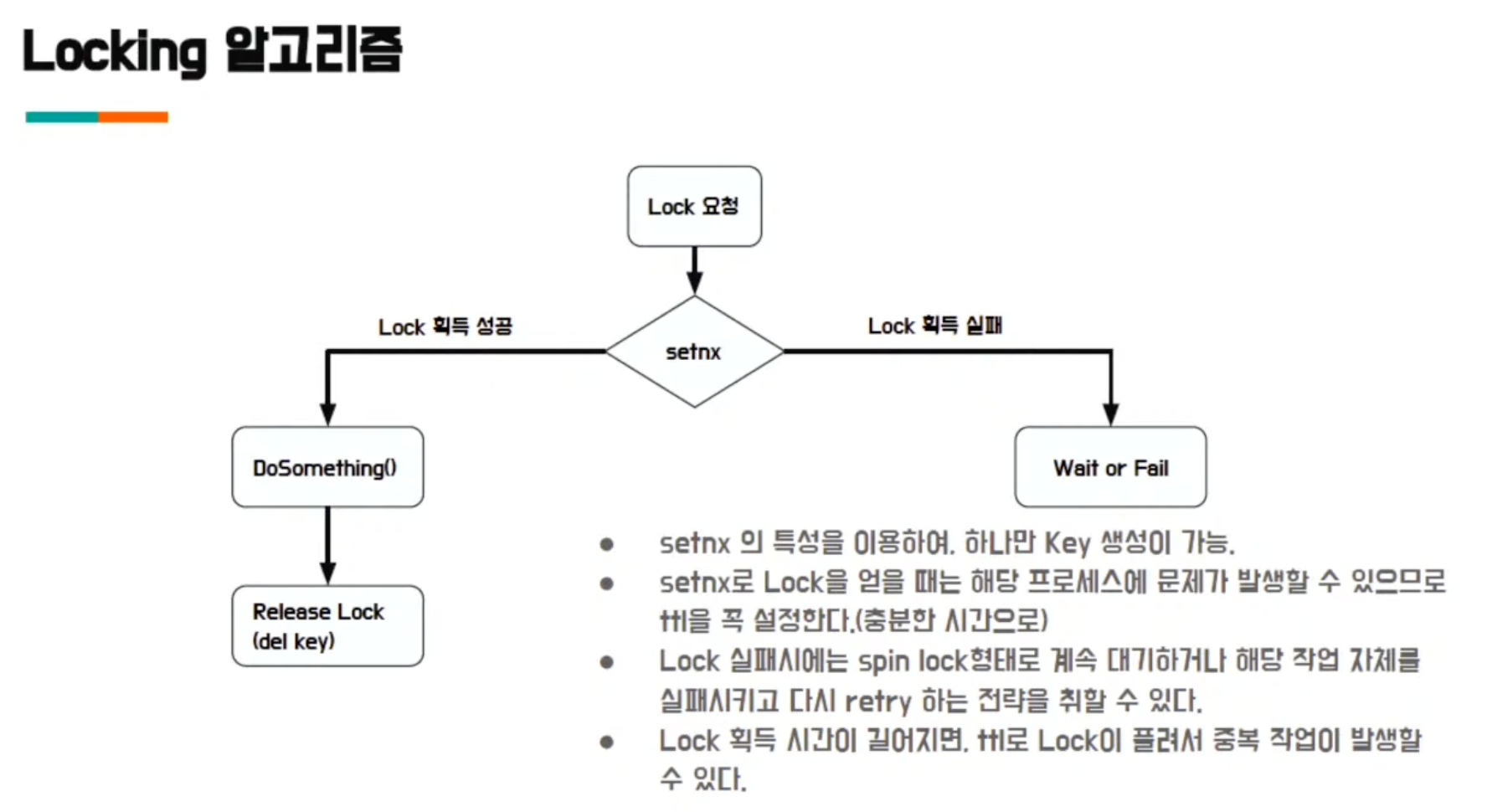
Distributed Lock (분산 락)
- 서버간 동기화를 위해 필요
- Optimistic Lock 으로 동작
- Key 가 존재하면 대기하는 형태
- Key 를 생성하고 프로세서가 죽은 경우 문제가 되므로 Redis Key에 Expire를 설정
- 바로 실패로 구성할 지, Spinlock 형태로 동작할 지(Redisson 구현체) 등 고민 필요
-
Rate Limiter
- 잦은 업데이트가 필요한 경우 저장소로 사용되는 케이스
- 일종의 Write back 형태 or 전용 저장소로 동작
- ex) 과금 관리
- Rate Limiter 이외에 View Count 등을 저장할 때에도 사용
- https://www/mimul.com/blog/about-rate-limit-algorithm/
-
LeaderBoard
- Sorted Set(zset)이 score로 저장할 수 있음
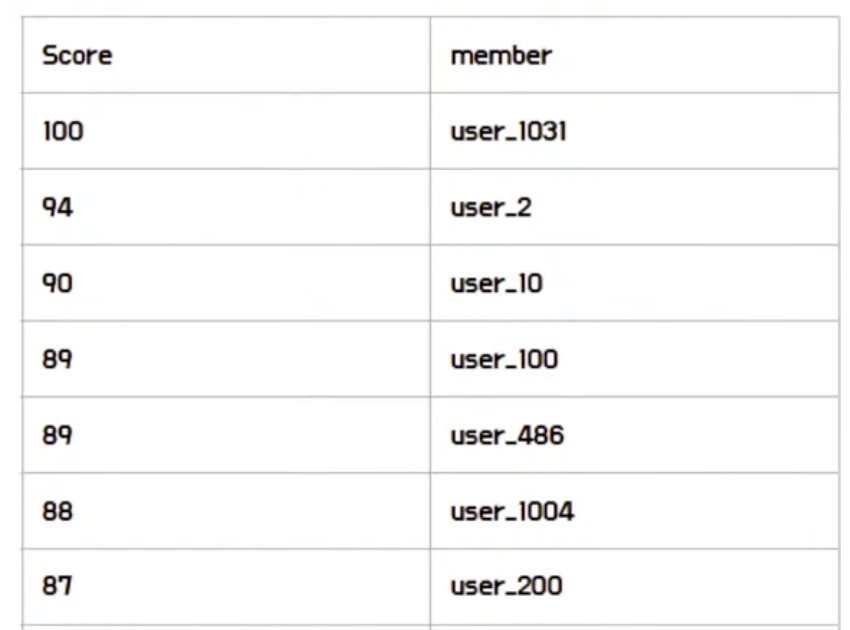
- Sorted Set(zset)이 score로 저장할 수 있음
-
Queue
-
Pub/Sub
Redis 기본 구조
Hash Table
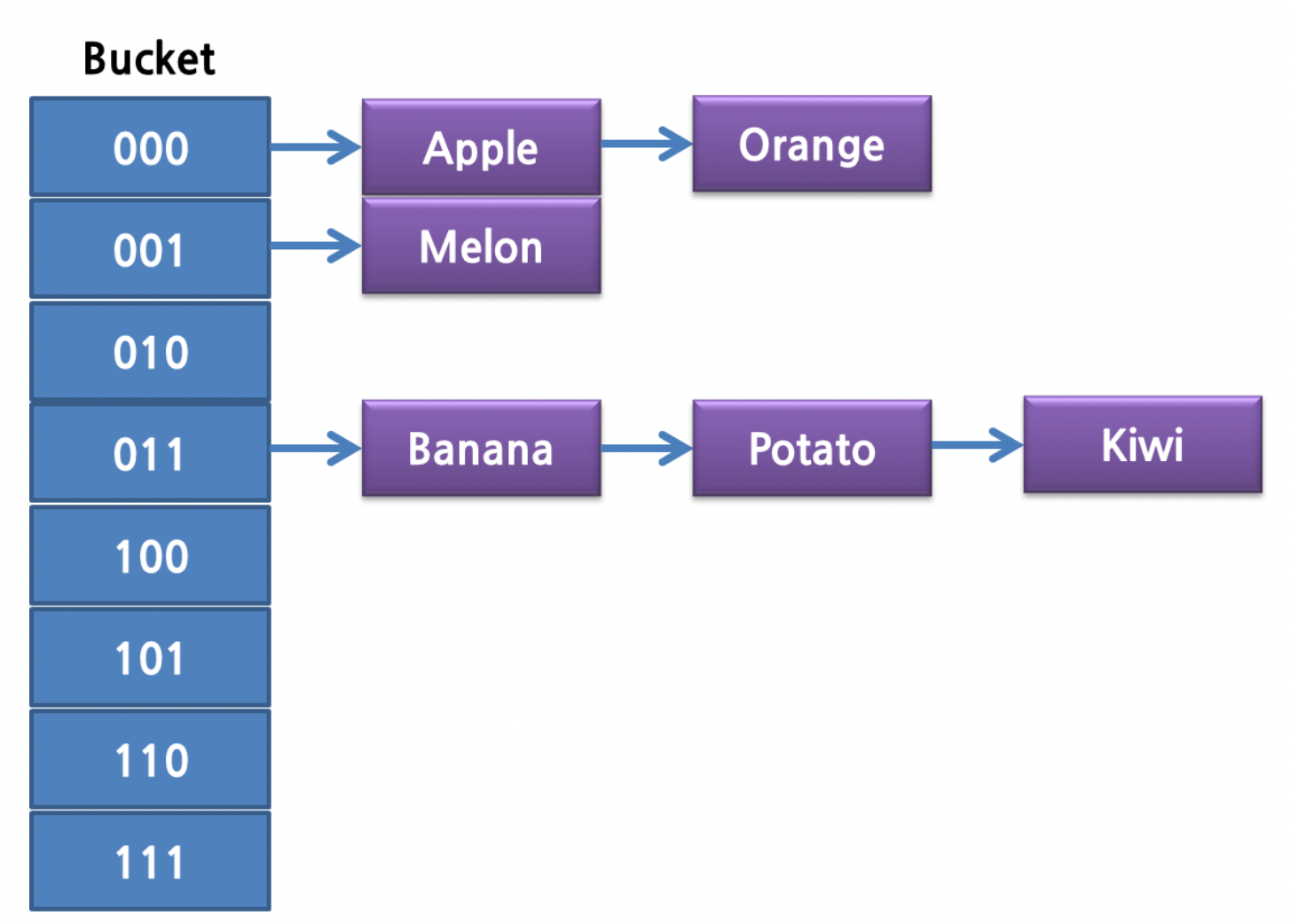
- Java의 HashMap과 동일한 구조
- 데이터양이 많아지면 Bucket을 늘려 확장
SipHash
- Redis 4.x 부터는 Hash Table 대신 SipHash를 사용
- Redis Dict 에서 Hash로 사용
- 일반 Hash는 언제나 같은 key에 대해 동일한 결과를 줌
- 어떤 서버에서 동작하든 같은 결과를 가지므로 데이터 DDos의 원인이 될 수 있음
- 특정 버킷으로만 key가 들어가도록 호출 가능
- SipHash는 서버가 시작하는 시점마다 seed를 이용하여 다른 결과가 나옴
- hash 알고리즘은 같고 해당 프로세서 내에서는 매번 같은 Hash 결과를 주지만, 다른 서버나 재시작시에는 다른 Hash 값을 주므로 추측하기 어렵게 함
String (Key/Value)
- Key/Value 구조
- get/set 커맨드
- O(1)
- mget/mset 커맨드
- O(1) * N
- mget/mset의 경우는 너무 많은 item을 요청하면 전체 응답이 느려짐
- 키가 N만개인 경우 mget/mset을 수행하면 싱글스레드이기 때문에 프리징 발생 가능
- cluster 에서 mget은 여러 서버의 응답을 모아야 하므로 더 느려짐
- cluster에서 사용하려면 Hash를 파악해야하지만 쉽지 않으므로 사용하지 않는 것을 추천
- get/set 커맨드
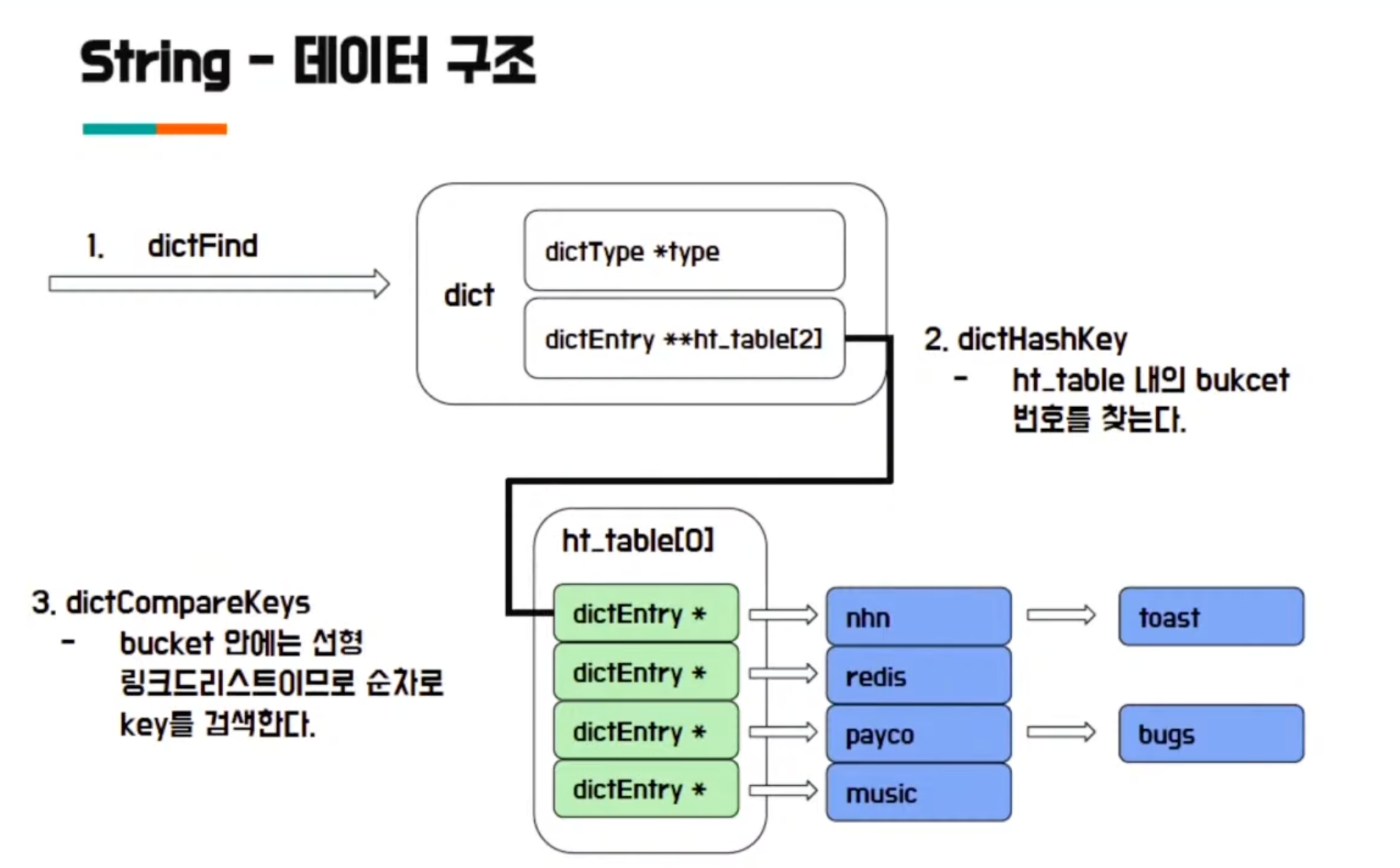
Hash 테이블 ht_table[0] 을 사용하다가 어느 시점에서 선형 리스트의 크기가 너무 커졌다고 판단되는 경우 bucket을 2개로 늘리고 데이터를 rehashing하여 ht_table[1] 을 추가로 사용하게 됨
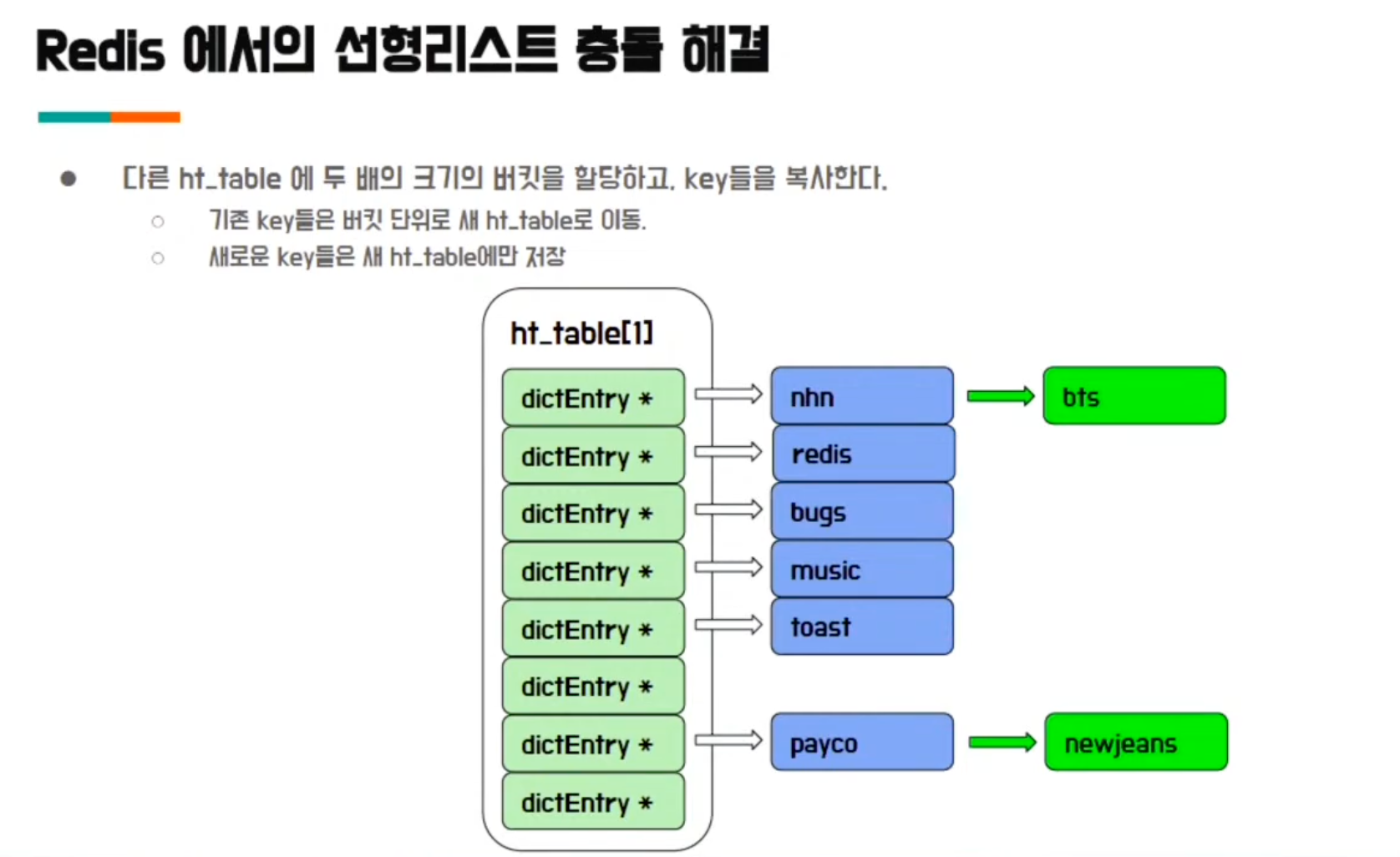
한 번에 작업하지 않고 조금씩 작업하여 Redis가 여전히 빠르게 동작할 수 있도록 처리
- main key 관리
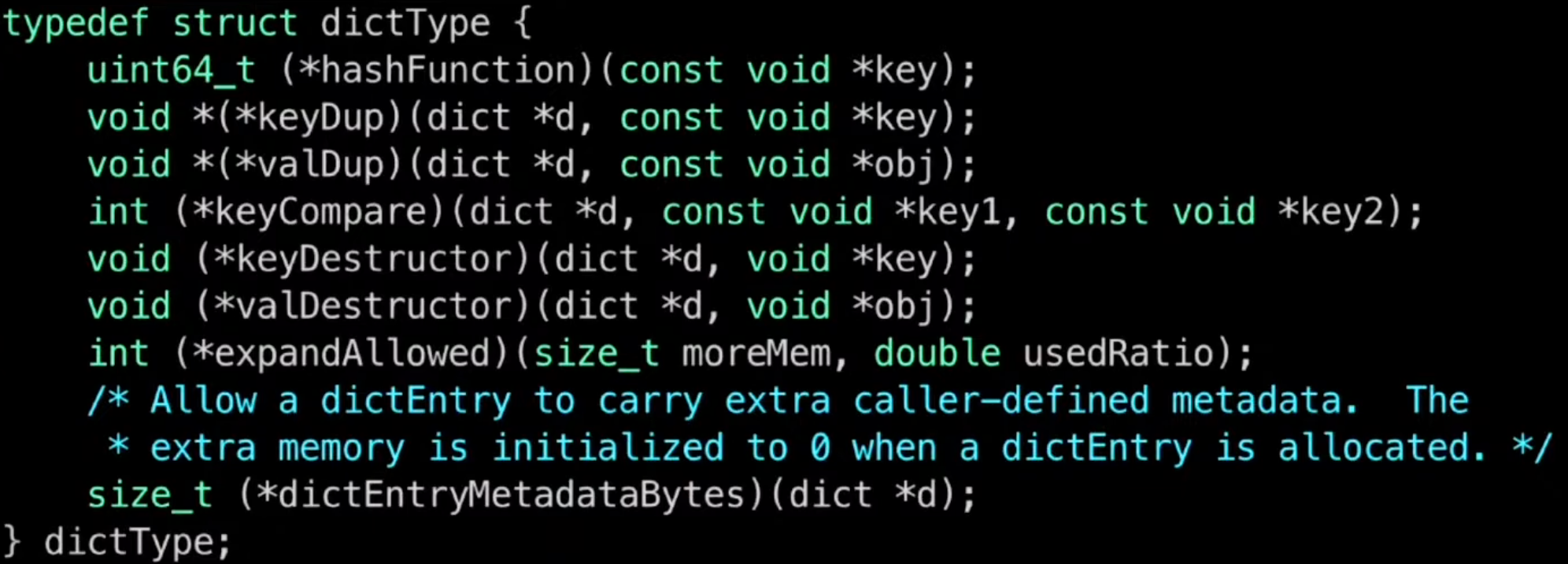
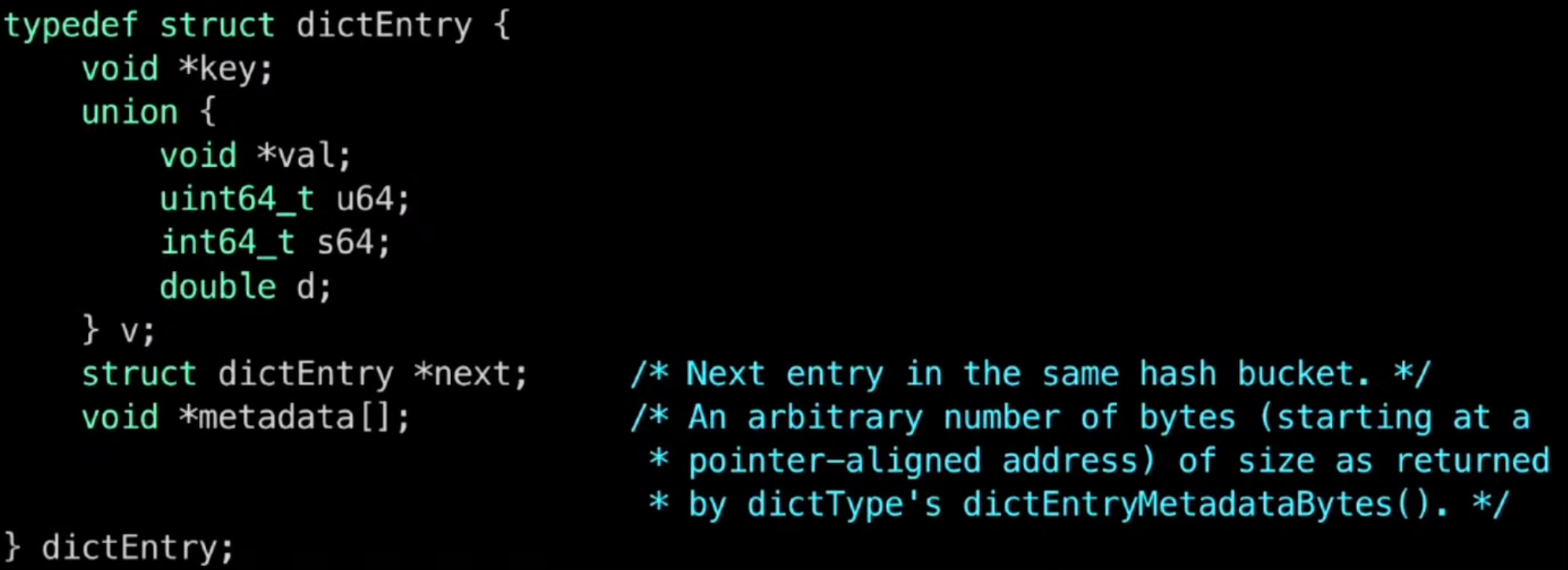
- Redis Dict
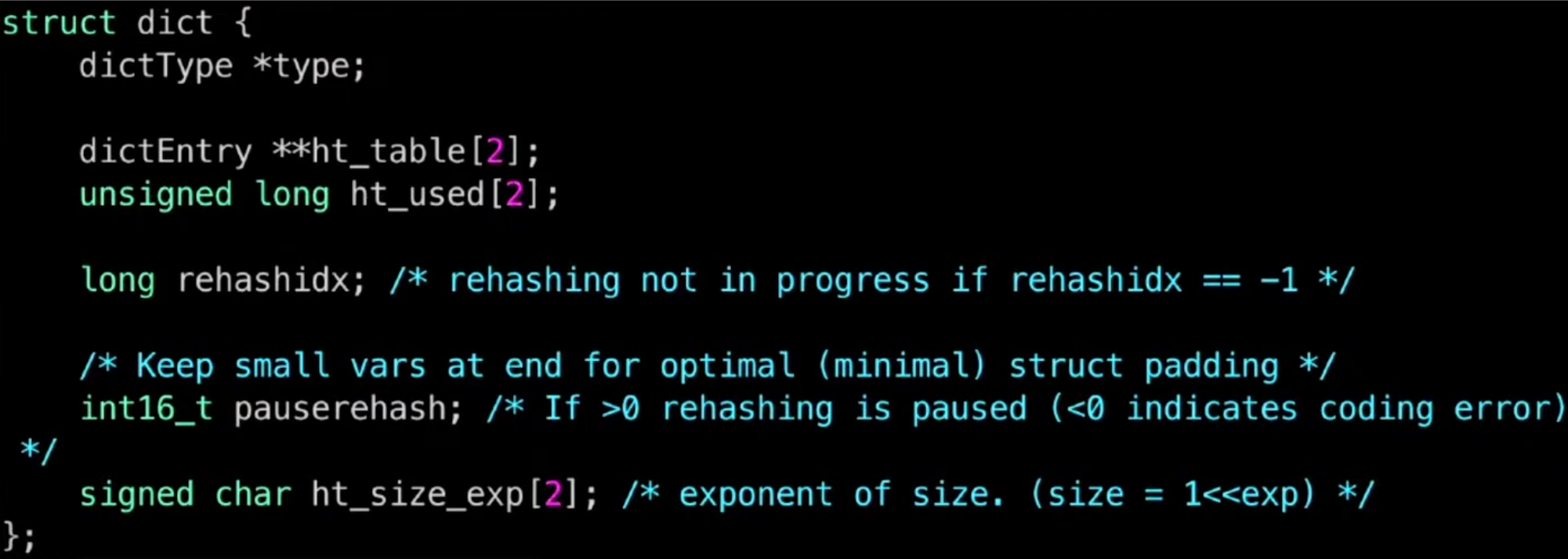
- Redis dictType
- Redis dictEntry
- Redis Dict
참고)
- Memcached는 Key와 Value가 붙어서 저장됨
- Redis는 Key와 Value가 따로 저장됨
- 최적화가 힘들다
- Key의 정보는 모두 메모리에 저장해두고 Hot Key의 Value만 메모리에 올려두도록 최적화가 가능하다
👉 Redis 에서 모든 Key는 기본적으로 string 구조로 저장됨 (value가 다르게 동작) ⭐️
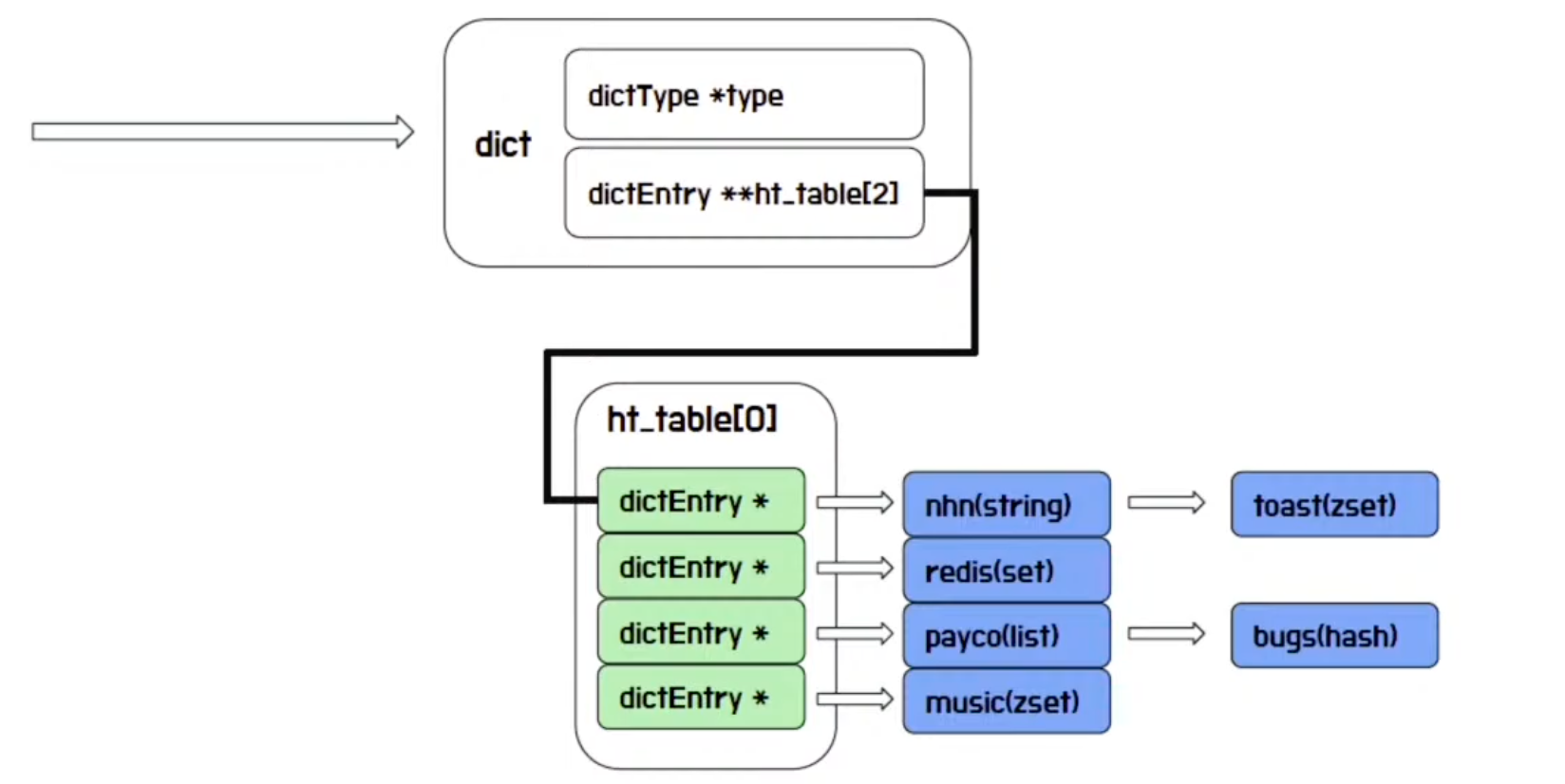
Redis Internal - key/value
Redis를 사용하는 이유는 빠른 속도도 있지만, 다양한 자료구조를 통해 원하는 서비스를 만들 때 도움이 되기 때문
- String 에서 사용되는 기본 구조는 HashTable
- 모든 다른 자료구조는 Main HashTable에 Main Key가 저장되는 형태
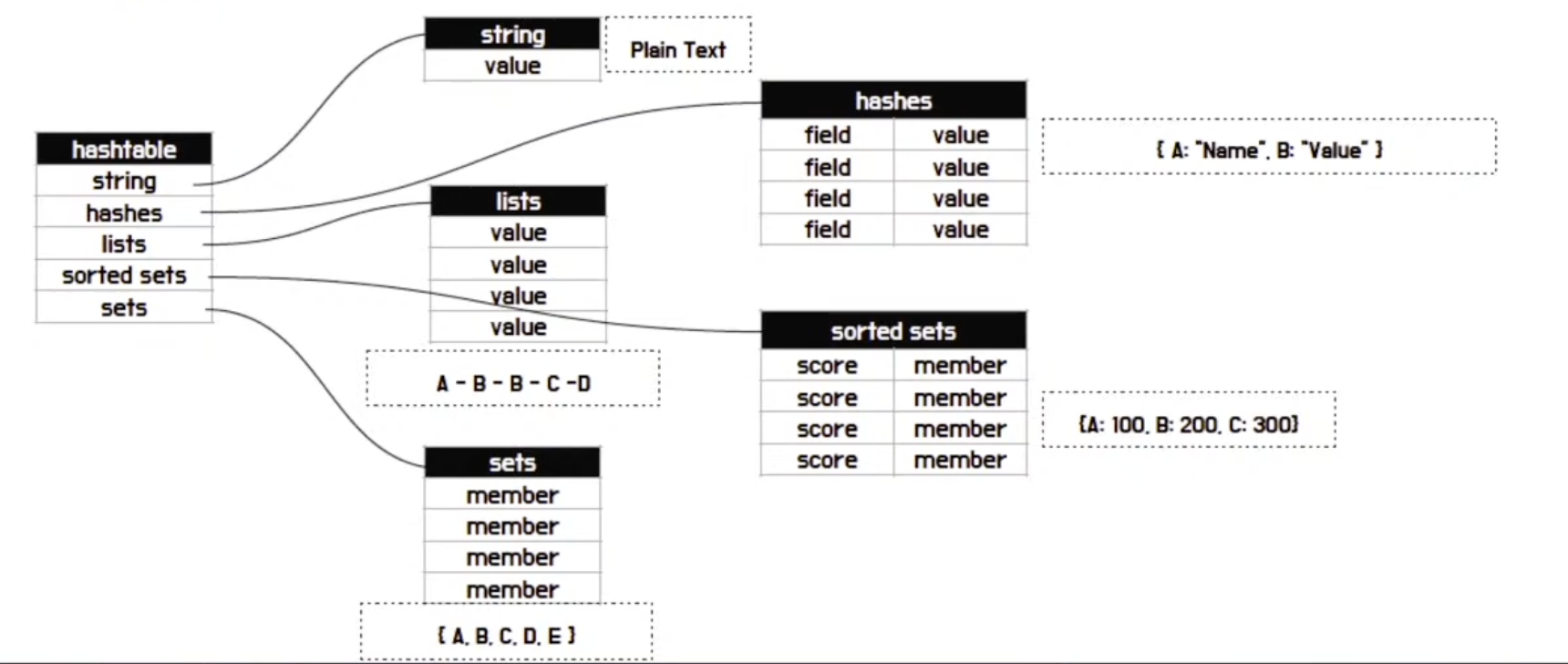
- List
- Job queue로 많이 활용됨
- 순차적으로 들어간 데이터를 순차적으로 꺼내감
- 다른 쪽에서는 볼 수 없음
- Stream
- 최근 List 대신 Job queue로 많이 활용됨
- 한 명이 꺼내가고 있어도 Consumer 그룹이 다르면 볼 수 있음
- String의 value는 Plain Text
- Hash의 value는 value 안에 또 다시 key/value가 있음
- Set은 유일한 값만 들어가는 집합
- ex. 유저 존재여부 확인
- Sorted Set은 정렬된 Set
- ex.유저 친밀도 랭킹 확인
Set
- 유일한 데이터를 저장하는 (Unique 집합) 자료구조
- encoding 타입이
OBJ_ENCODING_HT인 경우- 내부적으로 HashTable이 존재 (dict 하나 더 존재)
- 메모리를 매우 많이 사용함
- encoding 타입이
OBJ_ENCODING_INSET인 경우- HashTable은 메모리 사용량이 크므로, 정수 배열을 사용하면 메모리 사용량을 훨씬 줄일 수 있음
- 정수 타입만 들어있을 경우 정수의 배열을 만들어서 사용
- 2바이트, 4바이트, 8바이트 크기로 값에 따라 다르게 구성
- 정렬된 배열로 저장되어 찾을 때는 바이너리 서치를 사용함
Sorted Set
- 우선순위를 가지는 Set 자료구조
- 랭킹에 많이 사용 됨
- encoding 타입이
OBJ_ENCODING_SKIPLIST인 경우- 메모리를 매우 많이 사용
- 내부적으로 Skiplist 라는 자료구조를 사용
- O(LogN) 의 속도를 가지는 자료구조
- Skiplist의 Level(높이)는 랜덤하게 결정됨

- zscore 명령을 위해 dict 자료구조 사용
- score 값을 바로 확인하기 위해 내부적으로 hashtable을 하나 더 가지게 됨
- encoding 타입이
OBJ_ENCODING_LISTPACK인 경우- 메모리 사용량을 아끼기 위해 선형 메모리에 저장
- Score는 Integer가 아닌 Double 형태
- 같은 64비트이지만 Double은 소숫점을 사용하므로 표현할 수 있는 값이 더 적음
- Integer라고 생각하고 값을 넣으면 다른 값이 저장되는 버그 발생 가능
Hash
- Hash Table 내에 다시 또 Sub Hash Table을 가지는 구조
- encoding 타입이
OBJ_ENCODING_HT- HashTable: value가 dict
