10장. (부록) 성능을 생각하자 - 성능 향상을 위해
성능 측정 지표
처리 시간 (Processing Time) 또는 응답 시간 (Response Time)
- 특정 처리의 시작부터 종료까지 걸린 시간
- 사용자에 대한 영향이 가시적
처리율 (Throughput)
- 단위 시간당 처리 가능한 트랜잭션. 시간 단위의 지표
- 초당 50건의 트랜잭션 처리 = 50 TPS(Transaction Per Second)
- 시스템의 자원 용량(Resource Capacity)을 결정하는 요인
- 필요한 자원의 양은 동시에 실행된 처리량에 비례함
정점과 한계점
병목 (Bottleneck)
- 한 가지 자원이라도 한계에 이른 시점부터 성능 저하 발생 ➡️ 병목 발생. 응답 시간 상승, 처리율 하락
- Bottleneck: 동시에 실행되는 처리가 많아지는 순간에 대비하여 자원을 준비해두지 않으면 Peak에서 극단적인 지연 발생
- Bottleneck Point: 최초로 한계에 이른 자원
- Breaking Point: 처리율과 응답시간이 극단적으로 나빠지기 시작하는 처리량
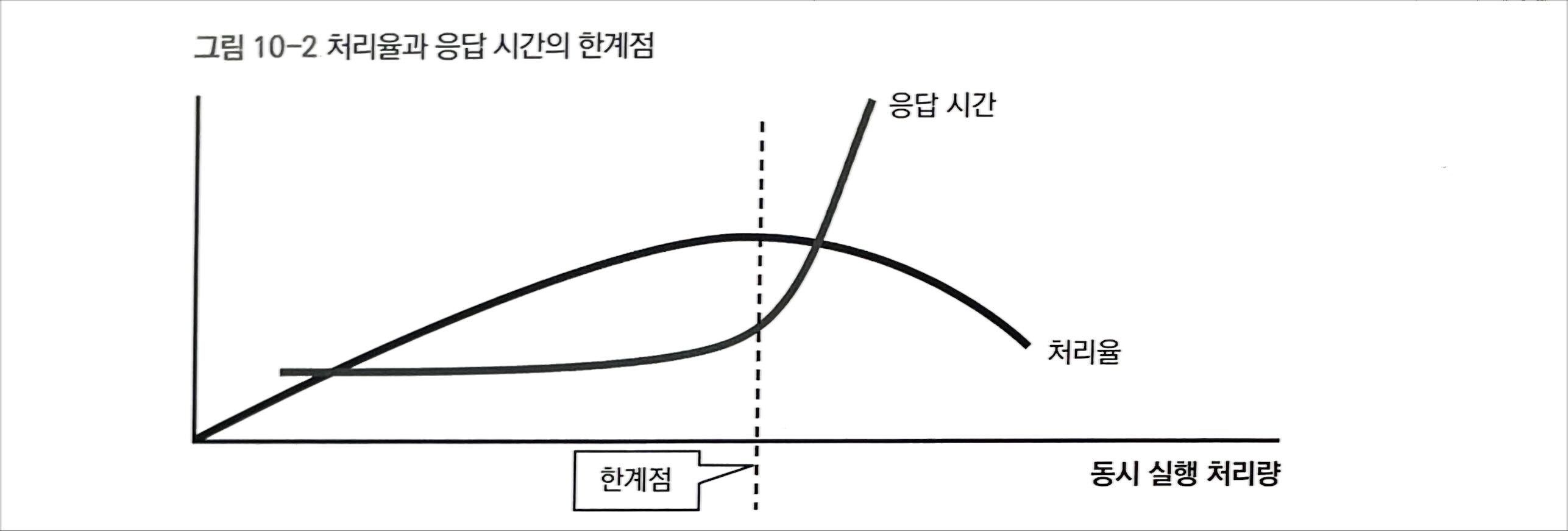
- Sizing 또는 Capacity Planning: 정점을 상정한 자원을 확보하는 것
주기형과 돌발형
- 업무 시스템과 같은 주기형의 경우 과거 실적을 조사하여 성장률을 추가하면 어느정도 액세스 집중도 파악 가능
- ex) 아침 출근시간에 직원이 일제히 로그인
- 온라인 상거래 사이트와 같은 돌발형의 경우 사용자가 정해져있지 않고 세일이나 이벤트에 따라 다르므로 액세스 집중 발생 예측이 어려움
- 정점이 아닌 경우와 정점인 경우에 필요한 자원량 차이가 크므로 자원 낭비 발생 가능
- 돌발형 액세스 집중에 대응하기 위해 클라우드(Cloud)를 통해 동적 자원 관리 가능
- 가상화를 기반으로 자원량을 유연하게 변동할 수 있는 기술. 물리 자원의 임대 모델
- Scale Up(고성능 장비 도입), Scale Out(장비 추가 도입)이 쉬움
데이터베이스와 병목
데이터베이스 병목 이유
- 취급하는 데이터양이 가장 많음
- 최근 데이터가 폭발적으로 증가
- 저장소 자원에서 병목이 많이 발생
- SQL문의 응답시간 증가, 데이터베이스 처리율 감소 등의 문제 발생
- 자원 증가를 통한 해결이 어려움
- 데이터베이스의 경우 동적 자원 관리가 어려움
- 데이터베이스의 병목 지점은 CPU나 메모리가 아닌 저장소. 즉, 하드디스크 ➡️ Scale Out이 어려움
- 주어진 자원 범위 내에서 융통성 있게 처리하기 위해 튜닝 기술 사용
- 튜닝: 애플리케이션을 효율화하여 같은 양의 자원이라도 성능을 향상하게 하는 기술
SQL 실행 과정
Parse ➡️ Execution Plan 작성 (통계 정보 사용) ➡️ Execution Plan 평가 ➡️ 데이터 액세스
Parse
- Parser 프로그램이 데이터베이스가 받은 SQL문에 문법적으로 잘못된 부분이 없는지 점검
- 구문 오류 발견 시 SQL문과 오류메세지를 사용자에게 반환
Execution Plan과 Optimizer
-
Parse 후 SQL문에 필요한 데이터에 어떤 경로로 접근할 지 플랜을 세움
-
Optimizer 프로그램이 통계정보를 참고하여 여러 가능한 플랜 중 어떤 플랜이 가장 효율적인지 계산하여 Execution Plan을 결정
💡 Optimizer란? 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심 엔진 네비게이션의 최단거리 찾기와 같음 Rule-Based Optimizer와 Cost-Based Optimizer가 있음 대부분 옵티마이저가 가장 효율적인 실행 계획을 알려주지만, SQL이 복잡한 경우 실수할 가능성이 큼 실제 운영자가 업무 특성을 고려하여 더 효율적인 액세스 경로를 찾아낼 수도 있음 이때 옵티마이저 힌트를 사용하여 데이터 액세스 경로 변경 가능 ex) SELECT /*+ INDEX(A 이름_PK) */참고자료 : 친절한 SQL 튜닝, 조시형 지음
통계 정보(Statistics)
- 통계정보에 포함되는 내용
- 테이블의 (대략적인) 행수, 열수
- 각 열의 길이와 데이터 타입
- 테이블의 크기
- 열에 대한 기본키나 NOT NULL 제약 정보
- 열 값의 분산과 편향 등
- 정확한 정보가 아닌 데이터를 샘플링 추출하여 계산한 결과
- 정확한 정보 참조를 위해 모든 데이터를 분석하면 너무 많은 시간이 소요되어 Execution Plan을 세우는 의미가 없어짐
- 통계 정보 확인
mysql> show table status; mysql> show index from 테이블명; - 통계정보는 대부분 자동으로 수집되며 대부분 대량의 데이터가 변경될 때 수집됨
- 필요한 경우 정기적으로 통계정보를 수집하도록 수동 설정 명령어 사용 가능
mysql> analyze table 테이블명;
실행 계획 (Execution Plan)
실행 계획 확인하기
- SQL문 앞에
EXPLAIN명령어를 사용mysql> EXPLAIN SELECT ~ ;
table은 데이터를 취득하려는 대상인 테이블type은 테이블에 대한 액세스 방법rows는 select 문이 액세스한 레코드의 행 수
Full Scan과 Range Scan
-
테이블 액세스 방법으로 Full Scan(
ALL)과 Range Scan(range)이 있음
-
Full Scan
- 테이블에 포함된 레코드를 처음부터 끝까지 전부 읽어 들이는 방법
-
Range Scan
- 테이블의 일부 레코드에만 액세스하는 방법
- SQL 문에 WHERE 절로 검색 범위를 제한하는 경우 Range Scan이 선택됨

Index
-
Range Scan을 위해서는 Index가 필요
-
적절한 Index가 없다면 Full Scan을 하여야 함
-
실행 계획에서
possible_keys와key의PRIMARY는 Primary Key의 Index를 사용하였음을 나타냄 -
기본키 구성 열에는 반드시 인덱스가 생성됨
-
인덱스 목록 확인
mysql> show index from 테이블명;
- Primary Key인 id에 대한 인덱스와 Unique Key인 email에 대한 인덱스로 총 2개의 인덱스가 존재함
-
인덱스 생성하기
mysql> create index 인덱스명 on 테이블명(열명); -
인덱스는 데이터베이스의 성능 향상 수단의 가장 일반적인 방법
- SQL문 변경 없이 성능 개선 가능
- 테이블의 데이터에 영향을 주지 않음
- 일정한 (때로는 극적인) 효과 기대 가능
-
인덱스를 적절히 생성하여 풀 스캔을 회피하고 일부 레코드만 스캔하여 성능을 향상 시킬 수 있음
- 인덱스를 적절히 생성해두면 인덱스 사용을 지시하지 않아도 옵티마이저가 인덱스를 사용하도록 설정함
- 옵티마이저가 인덱스 사용보다 풀 스캔이 더 빠르다고 판단하는 경우에는 인덱스를 사용하지 않음
Index 구조 B-tree
-
B-tree 인덱스 외에도 비트맵 인덱스, REVERSE KEY 인덱스 등이 존재하지만, 대부분 B-tree 인덱스가 사용됨
-
B-tree 인덱스의 구조
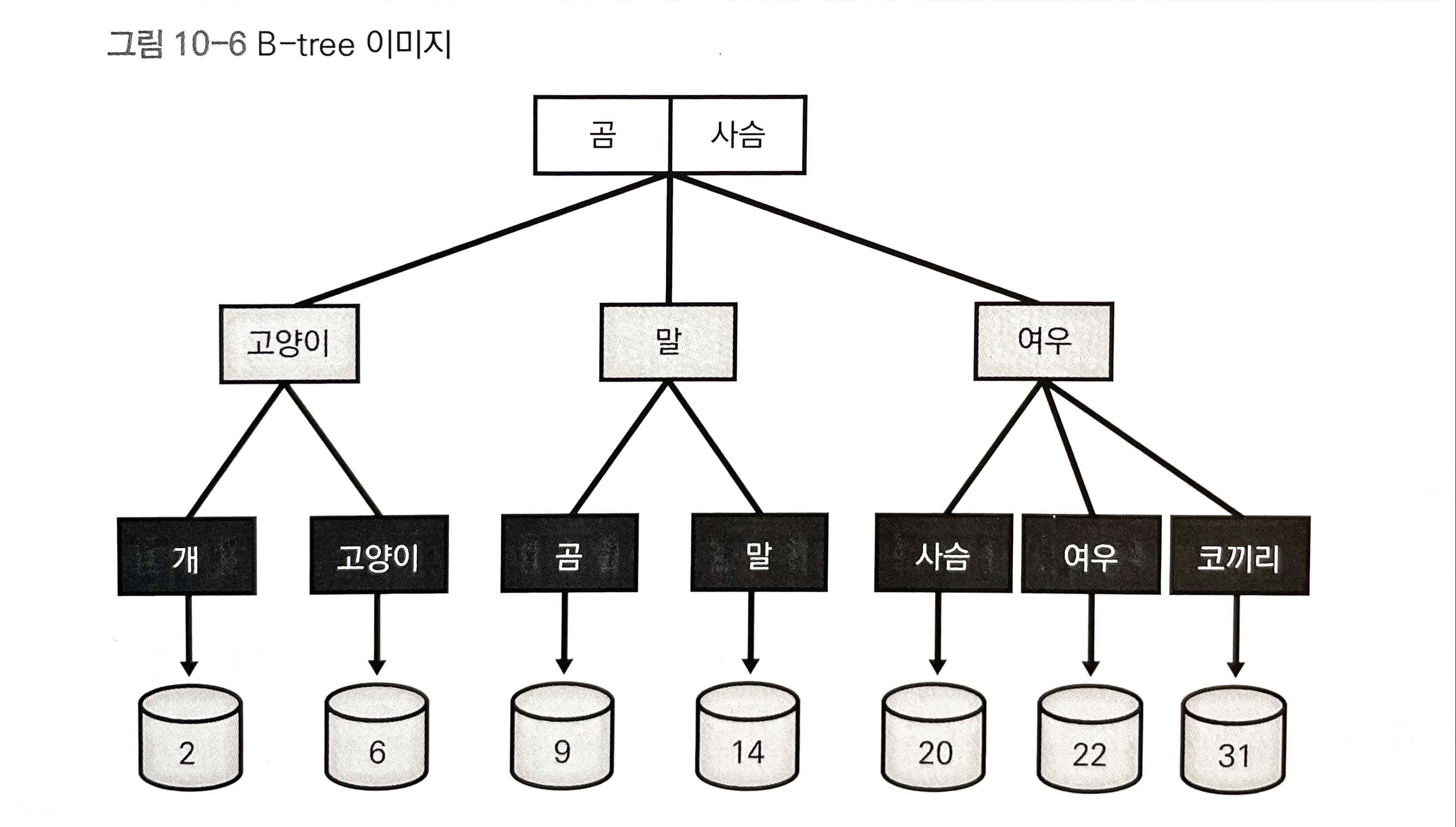
- 각각의 데이터는 Node
- 가장 상위의 노드는 Root Node, 가장 아래의 노드는 Leaf Node, 중간 노드는 Branch Node
- 리프 노드 아래의 숫자는 데이터가 포함된 테이블의 페이지 수
-
B-tree 인덱스는 반드시 데이터를 정렬된 상태로 유지
-
특정 데이터를 찾을 때 루트 노드에서 탐색을 시작하여 데이터의 대소를 비교하고 한 단계씩 아래로 진행해나가며 리프 노드에 도달
-
이진 탐색을 수행하는 균형 트리이므로 성능이 우수하며 데이터양이 커질수록 성능 개선 효과가 큼

- 균형 트리(Balanced-tree): 루트로부터 리프까지의 거리가 일정
- 다만 처음 B-tree 생성 시에는 균형 트리지만, 갱신이 반복될수록 균형이 서서히 깨져가므로 정기적으로 인덱스 재구성 필요
Index가 특히 유용한 경우
- 실제 SQL 문 실행 시 백그라운드로 임시 영역에 정렬을 수행하는 경우 존재 ➡️ 성능 저하의 원인이 될 수 있음
GROUP BY, 집약 함수(COUNT/SUM/AVG등), 집합 연산(UNION/INTERSECT/EXCEPT)
- 해당 키 열에 인덱스가 존재하면 옵티마이저가 정렬 과정을 건너뛰도록 효율화 작업 수행
Index 작성이 역효과가 나는 경우
- 과한 인덱스 생성은 성능 개선에 효과가 없을 뿐더러 악영향을 미칠 수 있음
- 갱신이 빈번한 열에 인덱스를 생성하는 경우
- 기존 데이터에 대한 갱신, 제거가 실행되면 자동으로 인덱스도 갱신됨
- 인덱스 갱신으로 인한 오버헤드로 갱신 처리의 성능이 떨어지게 됨
- SELECT 문을 고속화하는 것은 갱신 SQL을 늦추는 Trade off를 가짐
- 의도와 다른 인덱스가 사용되는 경우
- 한 개의 테이블에 복수의 인덱스를 작성한 경우에 발생 가능
- 옵티마이저가 만능은 아니기 때문에 때때로 예측을 빗나가기도 함
- 인덱스를 생성하는 만큼 저장소의 용량을 소비
- 인덱스가 백업 대상에 포함되는 경우 백업 시간이 길어짐
Index 생성 기준
- 크기가 큰 테이블에만 인덱스 생성
- 크기가 작은 테이블은 풀 스캔과 별 차이가 나지 않음
- PK 제약이나 Unique 제약이 있는 열에는 불필요
- PK 제약과 Unique 제약이 있는 열에는 암묵적으로 인덱스가 생성됨
- 값의 중복 체크를 위한 데이터 정렬이 발생하는데, 이를 줄이기 위해 인덱스가 자동 생성됨
- Cardinality가 높은 열에 인덱스 생성
- Cardinality: 값의 분산도. Cardinality가 높을수록 값의 종류가 많음
- Cardinality가 낮은 열에서는 인덱스 트리를 따라가는 조작이 증가할수록 오버헤드 증가
주의 사항
아무리 옵티마이저가 플랜을 잘 세워주더라도 갱신되지 않은 낮은 정밀도의 통계 정보가 사용된다면 최적의 액세스 경로를 선택할 수 없음
- 결과 정보 갱신이 OFF 되어있지는 않은가?
- 통계 정보의 갱신 방법을 OFF로 설정한 경우 테이블의 데이터가 아무리 변경되어도 통계 정보가 갱신되지 않음
- 정기 갱신을 설정한 후로 데이터가 대량으로 변경되었는가?
- 정기 갱신 이후 데이터가 급격하게 변한 경우 다음 갱신 시점까지 이전의 통계 정보가 사용됨
- 이를 위해 통계 정보 자동 수집 설정이 가능하지만 이는 오히려 인덱스 갱신 오버헤드와 유사한 문제를 발생시키기도 함
통계 정보를 올바르게 수집하도록 명심하여야 함
예외적인 경우에는 옵티마이저 힌트, DBMS 파라미터를 이용한 실행 계획 명시적 제한, 통계 정보 처리 일시 보류 등의 대책을 사용하여야 함
